







目录
前言
学习爬虫你完全可以理解为找辣条君借钱(借100万),首先如果想找辣条借钱那首先需要知道我的居住地址,然后想办法去到辣条的所在的(可以走路可以坐车),然后辣条身上的东西比较多,有100万,打火机,烟,手机衣服,需要从这些东西里面筛选出你需要的东西,拿到你想要的东西之后我们就可以去存钱,我们通过一个图片来理解爬虫的运行流程:
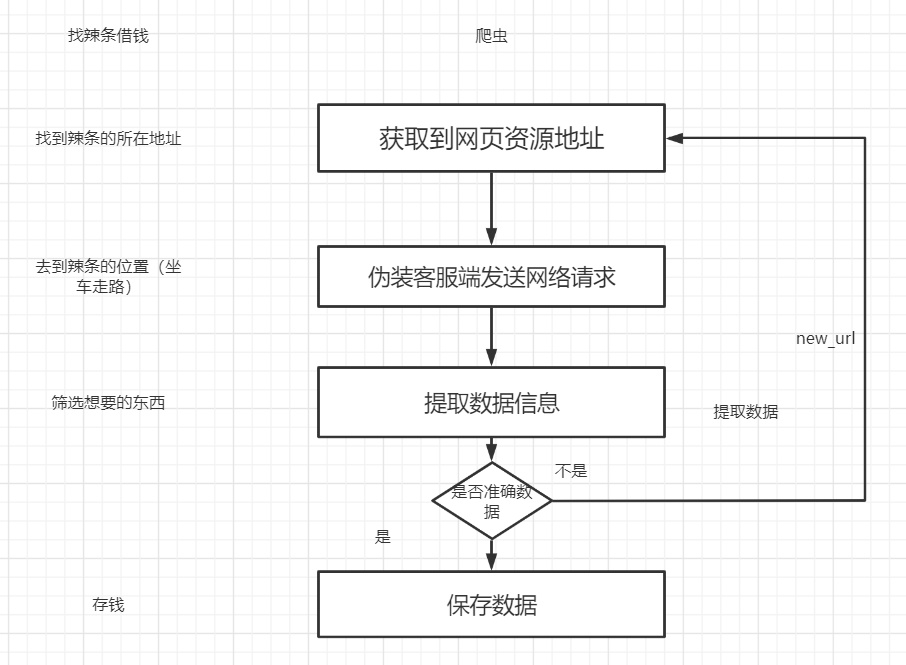
爬虫的流程至关重要,要是能把这个流程搞定那么爬虫的过程在你的脑海里就有基本的认知,可以说你的爬虫就已经学会20%了

一、获取数据地址信息
认识网址
首先我们先来认识所谓的网址,网址的高端叫法叫做‘统一资源定位符’,在互联网里面如果获取到数据都是通过网址来定位到的(就跟你找辣条借钱首先需要知道辣条目前所在的地址)那么每天都在用的网址到底是有什么特殊的含义呢?
网址有包含:协议部分、域名部分、文件名部分、参数部分
1、协议比较常见的就是http以及hettps
2、域名部分也就是我们说的服务器地址
3、文件名部分就是我们所需要的数据所在的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1459
1459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









