




 本文介绍了实时变声的技术实现,包括传统音效算法的困境和基于AI的ASR+TTS方法。文章指出,传统算法通过变调和均衡器调整音色,但效果有限。而基于AI的实时变声利用ASR和TTS,通过语音识别和语音合成实现声音转换,有望实现Any-to-any的变声。目前,实时变声系统的挑战在于算力需求、实时性和变声效果的稳定性。作者还探讨了端侧和云端部署的优缺点以及应用场景,并分享了未来优化方向和学习资源。
本文介绍了实时变声的技术实现,包括传统音效算法的困境和基于AI的ASR+TTS方法。文章指出,传统算法通过变调和均衡器调整音色,但效果有限。而基于AI的实时变声利用ASR和TTS,通过语音识别和语音合成实现声音转换,有望实现Any-to-any的变声。目前,实时变声系统的挑战在于算力需求、实时性和变声效果的稳定性。作者还探讨了端侧和云端部署的优缺点以及应用场景,并分享了未来优化方向和学习资源。
01 基于传统音效的实时变声算法的困境
1、变声改变的是什么
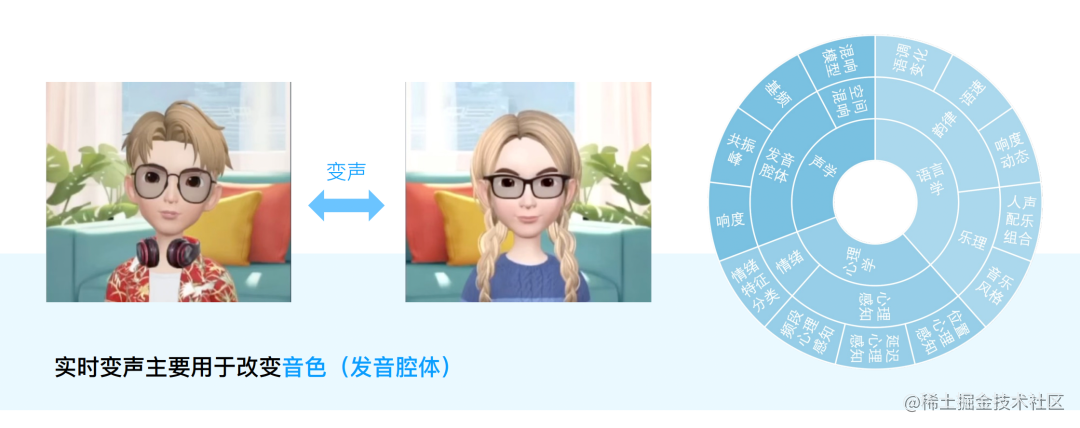
■图 1
要通过发音来识别一个人,有很多维度需要考虑。
首先,每个人的发音腔体各有不同,口腔的张合以及喉部的声带震动,都可能有个体声学方面的区别,这导致由于每个人的发音有不同的音色,在此基础上运用语言进行表达,就可能产生不同的韵律;其次,每个人所处的房间不同,也可能会伴有不同的混响,对识别造成影响;此外,有时通过变声唱歌,可能还需要乐器配合以及一些乐理知识。
而且,我们在感知声音的时候,也会受心理影响,同一个声音,有的人可能会觉得有磁性,但有些人可能会觉得比较粗糙。心理感知根据个人经历的不同,也会有些区别。
2、人为什么会有不同的音色
那么在实时场景下,如何实时变化声音呢?当韵律较长时,虽然我们无法改变遣词造句,但可以改变发音腔体的音色,因为它对实时性的要求比较高。
举例来说,比如“今天是几号”这样一句话,可以把这些字拆成一些音素,比如“今”可以拆成 “J” 和“in” 这两个音素,它是一个浊音,可以由声带震动发出声音,此时每个人的音色区别比较大;而“是”是一个清音,通过唇齿的气流形式实现,对于这个字来说,每个人的音色区别比较小。这是为什么呢?
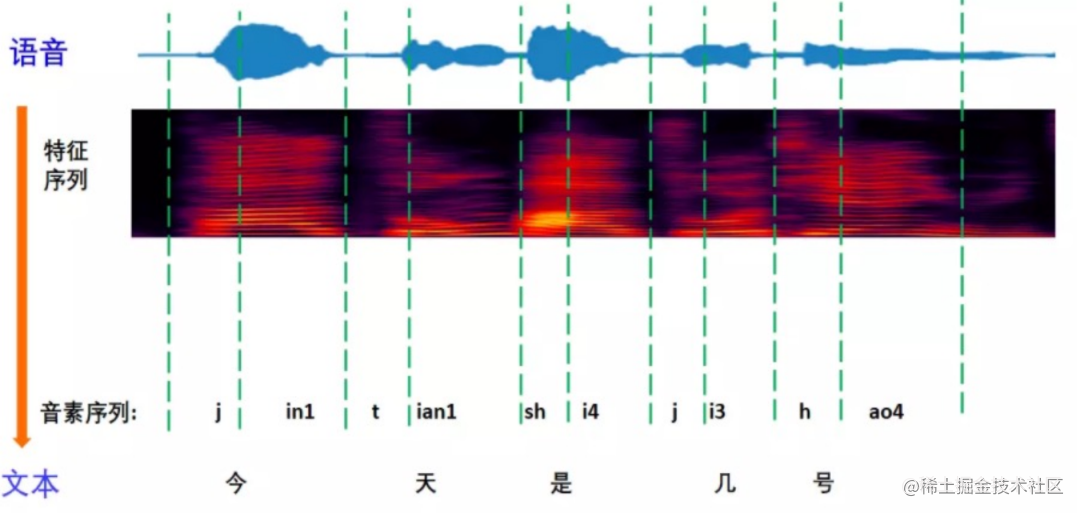
■图 2
本质上来说,声带的震动频率决定了发音的音调高低。不同的人通过不同的声带震动频率发同样一个音,其音色在浊音上会有很大的不同。比如上面的例子,“今天几号”这几个字,不同的人发音可能会有比较大的区别,而“是”这个字可能区别就比较小。
传统的变身算法也是从这个角度来考虑,不同的人有不同的基频,根据声带振动频率不同,可以调整基频的分布。不同的基频会有不同的谐波,谐波就是基频的倍数。这样就可以通过变调方式来改变声音。
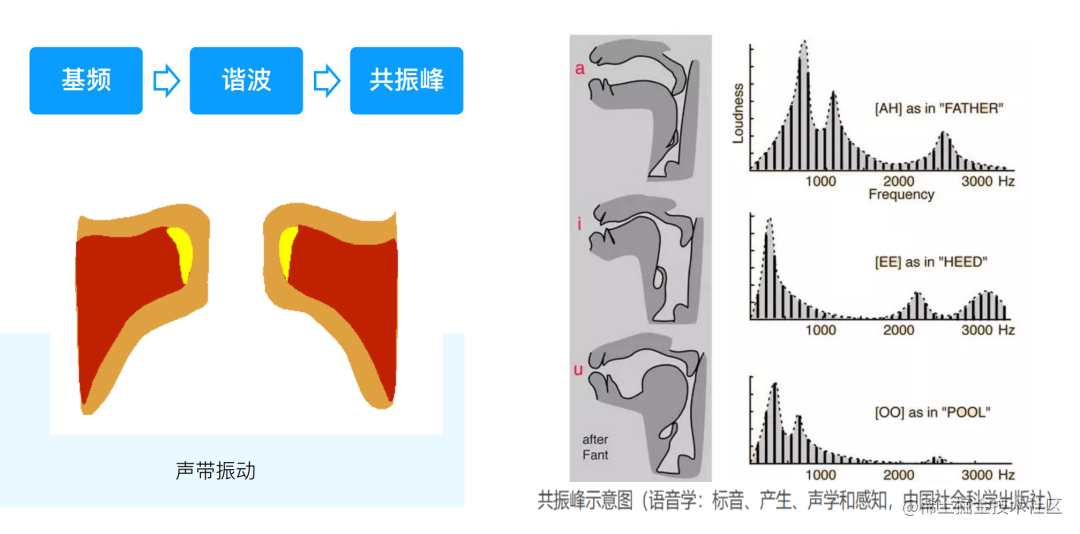
■图 3
在发不同的音时,嘴巴的开合程度决定了发音腔体的共振情况,开合程度的不同会导致不同频响的增强或削弱,如果和口腔的共振频率达到同一频率,频段就会被增强,不同则会被削弱。这就是共振峰的原理。从浊音的角度来说,声带震动产生基频,基频会有相应的谐波,谐波在不同频率的分布由腔体的开合来决定。这样,改变基频和频响的分布就可以对音色有所调整。
3、基于传统音效的变声
传统算法其实就是通过不同的效果器对不同的发音维度进行调整,图 4 所示为传统算法常用的效果器,比如变调,现在变调的算法大部分都是通过 pitch shifting 把基频和谐波向上或者向下扩展。在这种情况下,shift 操作会同时改变共振峰,使声音都根据频谱的能量向上或者向下移动,从而改变人的基频发声。
女生的基频比较高,而男生的基频比较低,通过这个方法就可以使两者的基频方向一致。但是男女发音时的口腔开合也会随字的变化而变化,仅仅改变基频不能做到完美的声音转变。比如电影《神偷奶爸》,其中的小黄人说的是西班牙语,由于基频提高它变成了小孩子的声音,但是这并不自然,还需要均衡器进行调节。
前面的例子在变调的时候只改变了基频,其实共振峰和频响可以通过均衡器或者共振峰滤波器来进行调整,这些也是调整音色的关键模块。另外,经过美声训练的人在唱歌或者说话的时候,高频音较多,发音比较饱满,从这个角度来说,可以通过激励器对其谐波进行增强。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









