







- 构建本地Caffeine缓存
private final Cache<String, String> LOCAL_CACHE = Caffeine.newBuilder()
.initialCapacity(1024)
.maximumSize(10_000L) // 最大 10000 条
// 缓存 5 分钟后移除
.expireAfterWrite(Duration.ofMinutes(5))
.build();
Caffeine 简介
Caffeine 是一个高性能、轻量级的本地缓存库,主要用于 Java 应用中,用来替代像 Guava Cache 更高效的实现。下面是对 Caffeine 及其用法的快速概述:
-
基本概念
- Caffeine 通过构建器模式(Caffeine.newBuilder())来创建缓存实例。
- 支持多种缓存失效策略,比如大小限制、自动过期、弱/软引用等。
-
常用配置参数
- initialCapacity(int capacity):设置缓存容器的初始容量,优化内存分配。
- maximumSize(long size):限定缓存中条目的最大数量。当缓存达到这个上限时,会根据使用频率(LRU-like 策略)将部分条目驱逐。
- expireAfterWrite(Duration duration):设置一个条目在写入缓存后多长时间失效,比如上面例子中设置了 5 分钟后自动移除。
- 另外还有 expireAfterAccess(Duration duration)(根据访问时间失效)、refreshAfterWrite(Duration duration)(定时刷新)、以及基于引用的弱引用和软引用策略等,可以根据需求配置。
-
使用示例
在代码片段中,构建了一个字符串键值的缓存实例,设置了初始容量为 1024 条、最大存储条数为 10,000 条,并且在写入后 5 分钟会自动过期:
使用时,只需要调用 LOCAL_CACHE.get(key, mappingFunction) 来获得缓存中的数据(如果数据不存在,可以通过 mappingFunction 计算后添加到缓存中),或是使用 put(key, value) 手动存放数据。例如:
// 存数据
LOCAL_CACHE.put("user:1", "Alice");
// 取数据
String value = LOCAL_CACHE.getIfPresent("user:1");
-
高级功能
- LoadingCache:如果你希望缓存在缺失某个 key 时自动加载数据,可以使用 Caffeine.build(CacheLoader) 来构建一个 LoadingCache。
- 监听器:Caffeine 还支持在缓存条目被移除时触发特定的回调(removalListener)。
- 异步缓存:可以用到 Caffeine 的 AsyncCache,解决异步加载场景。
-
性能优势
- Caffeine 采用了各种高效的策略进行缓存存储和驱逐,能够在并发场景下保持高效性和低延时。
- 其设计使得 GC 开销较低,并支持自定义缓存策略,能满足多种业务需求。
/**
* 分页获取图片列表(封装类,有缓存)
*/
@Deprecated
@PostMapping("/list/page/vo/cache")
public BaseResponse<Page<PictureVO>> listPictureVOByPageWithCache(@RequestBody PictureQueryRequest pictureQueryRequest,HttpServletRequest request) {
long current = pictureQueryRequest.getCurrent();
long size = pictureQueryRequest.getPageSize();
// 限制爬虫
ThrowUtils.throwIf(size > 20, ErrorCode.PARAMS_ERROR);
// 普通用户默认只能看到审核通过的数据
pictureQueryRequest.setReviewStatus(PictureReviewStatusEnum.PASS.getValue());
// 查询缓存,缓存中没有,再查询数据库
// 构建缓存的 key
String queryCondition = JSONUtil.toJsonStr(pictureQueryRequest);
String hashKey = DigestUtils.md5DigestAsHex(queryCondition.getBytes());
String cacheKey = String.format("listPictureVOByPage:%s", hashKey);
// 1. 先从本地缓存中查询
String cachedValue = LOCAL_CACHE.getIfPresent(cacheKey);
if (cachedValue != null) {
// 如果缓存命中,返回结果
Page<PictureVO> cachedPage = JSONUtil.toBean(cachedValue, Page.class);
return ResultUtils.success(cachedPage);
}
// 2. 本地缓存未命中,查询 Redis 分布式缓存
ValueOperations<String, String> opsForValue = stringRedisTemplate.opsForValue();
cachedValue = opsForValue.get(cacheKey);
if (cachedValue != null) {
// 如果缓存命中,更新本地缓存,返回结果
LOCAL_CACHE.put(cacheKey, cachedValue);
Page<PictureVO> cachedPage = JSONUtil.toBean(cachedValue, Page.class);
return ResultUtils.success(cachedPage);
}
// 3. 查询数据库
Page<Picture> picturePage = pictureApplicationService.page(new Page<>(current, size),
pictureApplicationService.getQueryWrapper(pictureQueryRequest));
Page<PictureVO> pictureVOPage = pictureApplicationService.getPictureVOPage(picturePage, request);
// 4. 更新缓存
// 更新 Redis 缓存
String cacheValue = JSONUtil.toJsonStr(pictureVOPage);
// 设置缓存的过期时间,5 - 10 分钟过期,防止缓存雪崩
int cacheExpireTime = 300 + RandomUtil.randomInt(0, 300);
opsForValue.set(cacheKey, cacheValue, cacheExpireTime, TimeUnit.SECONDS);
// 写入本地缓存
LOCAL_CACHE.put(cacheKey, cacheValue);
// 获取封装类
return ResultUtils.success(pictureVOPage);
}
下面是对该代码中采用缓存策略的详细阐述:
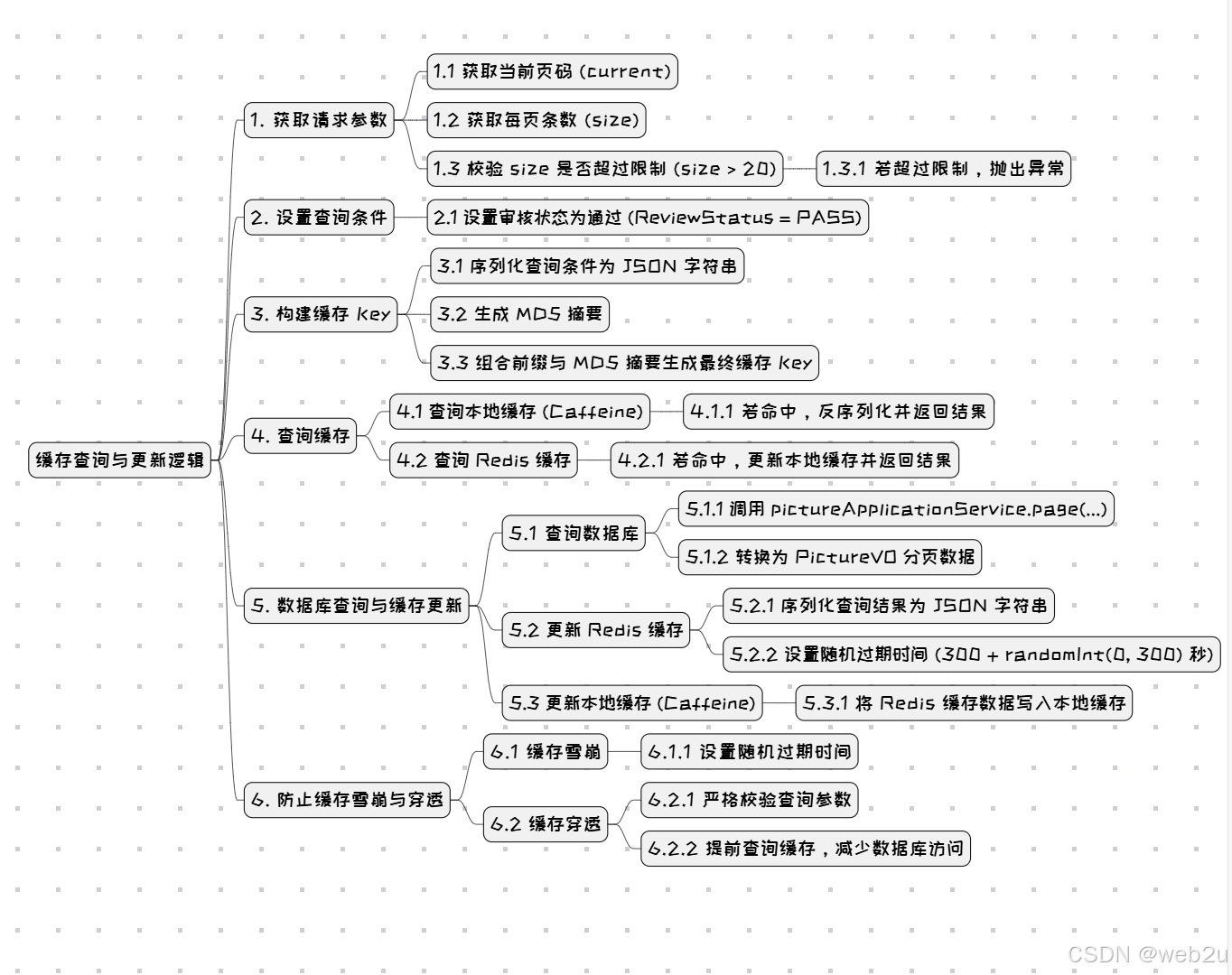
1. 方法的基本职责
该方法主要用于分页获取图片列表,并对查询结果进行缓存。返回结果为一个封装了分页数据(PictureVO 对象列表)的响应。
2. 参数及校验
-
分页参数获取与限制
- 从请求中获取当前页码(current)和每页条数(size)。
- 为防止爬虫或恶意请求,方法内部对每页返回的数据量做了限制:若 size 大于 20,则抛出异常(通过
ThrowUtils.throwIf方法)。
-
设置查询条件
- 普通用户只能获取审核通过的数据,因此会预先设置
pictureQueryRequest.setReviewStatus(PictureReviewStatusEnum.PASS.getValue()),确保返回的图片已通过审核。
- 普通用户只能获取审核通过的数据,因此会预先设置
3. 构建缓存 Key
-
查询条件的序列化
- 将 pictureQueryRequest 对象序列化为 JSON 字符串,这样能确保所有参数都参与缓存 key 的生成,保证不同的查询条件对应不同的缓存数据。
-
生成 MD5 摘要
- 利用 MD5 算法(
DigestUtils.md5DigestAsHex)对 JSON 字符串进行摘要,生成一个固定长度的散列值,作为缓存 key 的一部分。
- 利用 MD5 算法(
-
最终缓存 Key 格式
- 组合散列值和前缀(例如 “listPictureVOByPage:”),形成最终缓存 key。这样做不仅便于区分缓存数据的来源,同时也确保 key 的唯一性。
4. 两级缓存策略
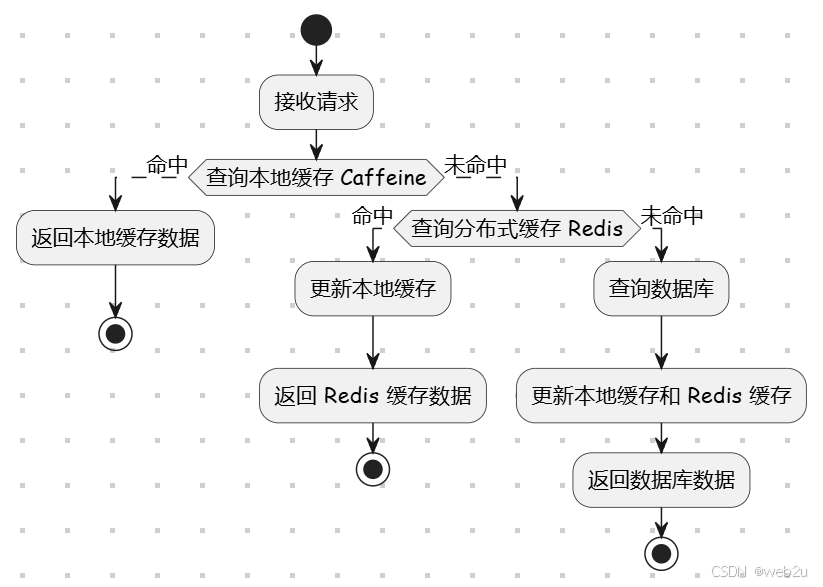
- 在每次返回缓存/数据之前,先更新缓存
4.1. 一级缓存——本地缓存(Caffeine)
-
操作方式
- 通过
LOCAL_CACHE.getIfPresent(cacheKey)先查询本地缓存(由 Caffeine 实现)是否存在缓存数据。 - 如果缓存命中,则直接将 JSON 字符串反序列化成 Page 对象并返回响应。
- 通过
-
优点
- 本地缓存数据访问速度非常快,能够有效降低延迟。
- 适用于单机环境下的高并发场景,有效减少对分布式缓存或数据库的访问次数。
4.2. 二级缓存——Redis 分布式缓存
-
操作方式
- 若本地缓存未命中,再到 Redis 中查找(通过
stringRedisTemplate.opsForValue().get(cacheKey))。 - 如果 Redis 命中,则:
- 更新本地缓存(保证本地缓存与 Redis 数据一致)。
- 反序列化返回数据,并构造响应。
- 若本地缓存未命中,再到 Redis 中查找(通过
-
优点
- Redis 作为分布式缓存,能够在多机环境下共享缓存数据。
- 对于跨进程或跨实例的缓存访问,Redis 提供了较好的性能及数据一致性。
5. 数据库查询与缓存更新
当两级缓存都未命中时,执行数据库查询并更新缓存:
-
数据库查询
- 调用
pictureApplicationService.page(...)查询数据库,获取 Picture 数据分页结果。 - 使用
pictureApplicationService.getPictureVOPage(...)方法将数据库查询结果转换为展示页面所需的 PictureVO 分页数据。
- 调用
-
缓存更新策略
-
Redis 缓存更新
- 将查询结果转换为 JSON 字符串存入 Redis。
- 缓存过期时间设置为 5 至 10 分钟之间(300 + randomInt(0, 300) 秒),这种随机策略有助于防止缓存雪崩,即避免大量缓存同时失效带来的数据库压力。
-
本地缓存更新
- 同步将 Redis 缓存中的数据写入 Caffeine 本地缓存,保证后续对该 key 的调用首先命中本地缓存。
-
6. 防止缓存雪崩与缓存穿透
-
缓存雪崩
- 通过为 Redis 缓存设置随机过期时间,使得缓存的数据不会在同一时间大面积失效,从而分散对数据库的瞬时压力。
-
缓存穿透
- 通过在本地及 Redis 层都提前查询缓存,尽可能减少对数据库的直接访问,同时结合查询参数限制和数据一致性的设计,也能降低缓存穿透的风险。
7. 总结
- 使用 MD5 对查询参数进行 hash 化,确保缓存 key 唯一性;
- 实现了两级缓存(本地缓存 + Redis 分布式缓存),提高数据查询速度并降低数据库压力;
- 设置适当的缓存过期时间和随机化TTL,防止缓存雪崩;
- 对查询参数进行严格校验,既保护系统资源,又确保用户只能获取符合审核要求的数据。
这种双缓存策略属于常见的“先查询本地缓存,再查询分布式缓存,最后查询数据库,更新缓存”的应用场景,适用于高并发系统中对响应时间和数据一致性要求较高的场景。
注意
缓存中存储的是通过 JSONUtil.toJsonStr(pictureVOPage) 序列化后的 JSON 字符串,而这个过程往往会将对象中默认值、null 值或者部分未被标记为需要序列化的数据过滤掉,从而使数据量变小。
而直接从数据库查询得到的对象(或经过业务转换的对象)可能包含更多的字段(比如额外的分页元数据、内部状态或调试信息等),这些数据在序列化时如果不做处理,可能会被完整返回。

















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









