







继续接着https://www.cnblogs.com/webor2006/p/14092866.html来体系学习数据结构,这次将学习全新的两个线性数据结构---栈和队列,也是人人皆知的,当然也是非常非常重要的两个数据结构,很多一些复杂的算法都得借助它们的特性来进行实现。
栈【Stack】:
- 栈也是一种线性的结构。
- 相比数组,栈对应的操作是数组的子集。
- 只能从一端添加元素,也只能从一端取出元素【而数组木有这个限制,也能体会到第二点说的“栈操作是数组的子集”。】
- 其中这里所说的一端俗称为“栈顶”。用图来表示就是:

只有一个入口和出口,很显然要放东西则就是这样了,这里不厌其烦地再重温一下入栈的过程:

再添加一个元素此栈就满了,如下:
而如果要拿东东,则只能从最后一个元素4开始拿起,如下:
-
从上面也可以看出,栈是一种后进先出【Last In First Out(LIFO)】的数据结构。
- 在计算机的世界里,栈拥有着不可思议的作用,在未来的学习中可以深刻体会到它的重要性。
栈的应用:撤销操作和系统栈:
既然栈是如此重要的一个数据结构,下面以实际场景来举例说明一下它的应用场景。
无处不在的Undo操作(撤销):
平常咱们在编辑文字时如果输写错误了,常用的就是"command+z【mac】或ctrl+z【windows】"来进行撤销对吧,其实对于编辑器来说这个撤销的功能就是借助于栈来实现的,如何理解,比如咱们输入一个“沉迷”,此时这个词就会入栈记录一下,如下:
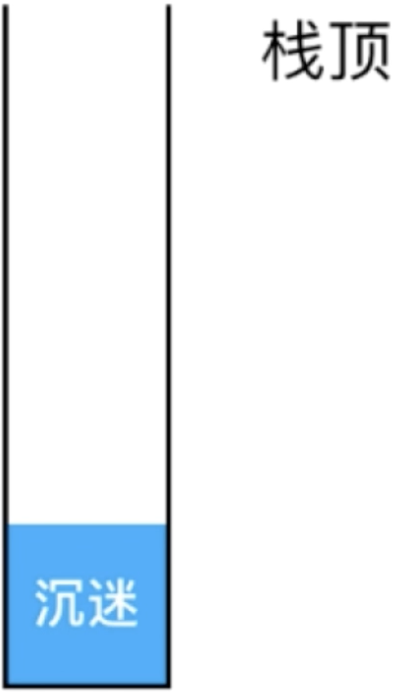
接下来再输入一个词“学习”,同样的:

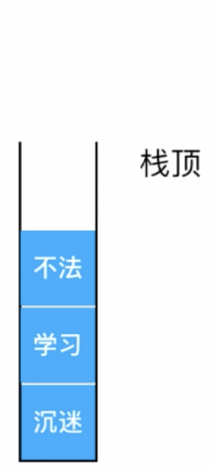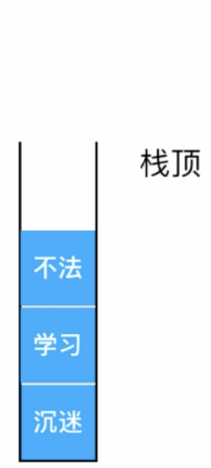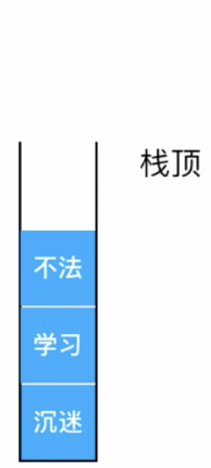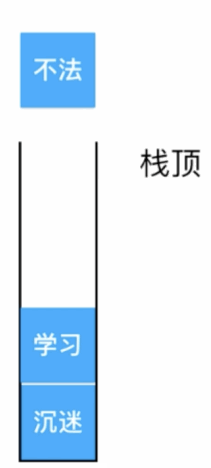
接下来本来是要输入“无法”的,但是呢手误打成了“不法”了,此时栈中记录的就是:

于是乎按键进行撤销,此时编辑器的做法就是先拿出栈顶的元素:
然后此时撤销动作执行其实就是将“不法”给删掉了:

对应的此时“不法”也成功出栈了,此时栈的元素就为:

然后重新更正为“无法”:
入栈:

然后再输入“自拔”:

从这个例子是不是能够直观的感受到栈的魅力。
程序调用的系统栈:
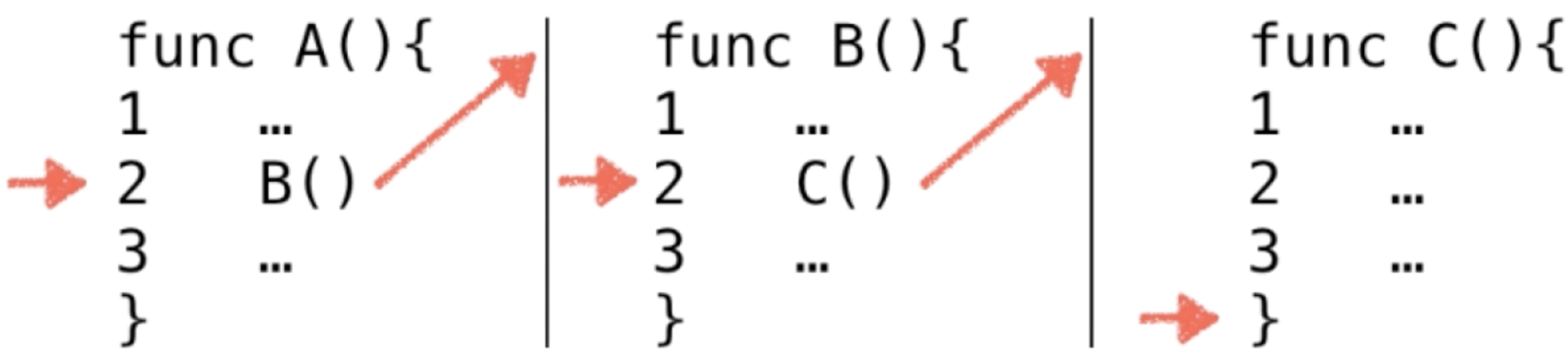
对于函数或方法的调用咱们其实通常都知道它是一个调用栈的过程,其实它就需要使用一个叫“系统栈”的东东,其它本质它就是一个栈的数据结构来记录我们程序的调用过程,所以要举例的第二个场景就是咱们熟知的程序调用了,比如有这么个程序:

也就是函数A中调用函数B,函数B中再调用C,这是咱们实际代码中常见的一个调用形式,那对于计算机来说,当执行到A时会发生什么呢?如下:

按顺序执行,此时执行到第二行时,此时需要执行子函数B了【注意:此时A函数会中断】,所以需要进行一个跳转了:

而栈中会记录此时函数A中断的状态为:
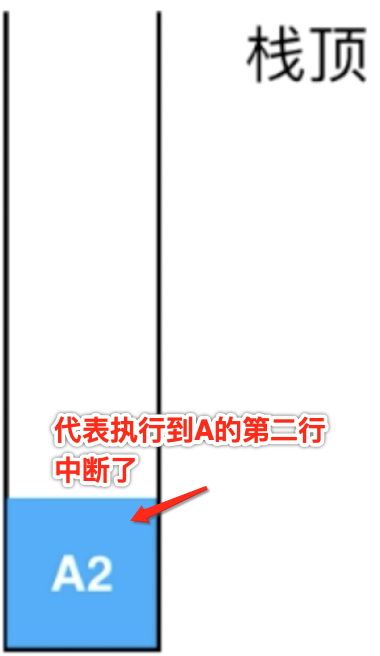
接下来则来按顺序执行B函数了,如下:

同样当执行到第2行时,此时B函数是需要中断的,同样此时会在栈中形成一个记录:

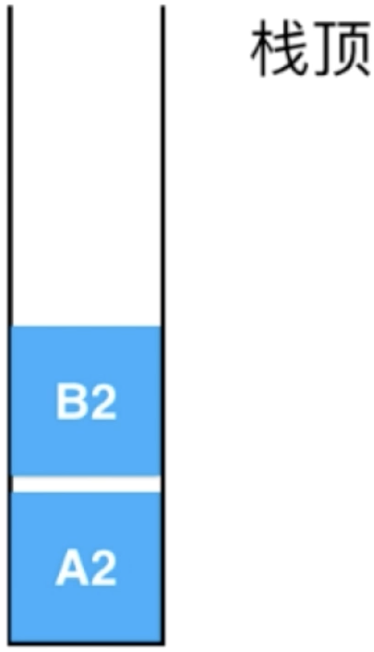
此时C函数就直接按顺序执行了:
当执行完函数C时,此时计算机就会遇到一个问题了,接下来该执行谁了呢?答案就是此时需要看一下系统栈了,拿出栈顶的元素:

此时计算机就知道了,原来我是在执行到B函数的第2行中断的,此时就可以跳回到B函数在第二行继续往下执行了:

此时B2这个栈中的元素就可以出栈了,因为计算机已经通过B2成功的找到继续执行的点了,所以此时栈中的状态为:
此时B函数就可以继续往下执行了:

此时计算机又蒙圈了,B执行完了,接下来又执行谁呢?此时又得回到系统栈来进行参考了,看一下栈顶的元素:

哦,此时计算机一下就回忆起来了,哦,原来我之前是在A函数的第二行中断的,嗯,知道了,接下来就恢复A函数的第二行继续往下执行:

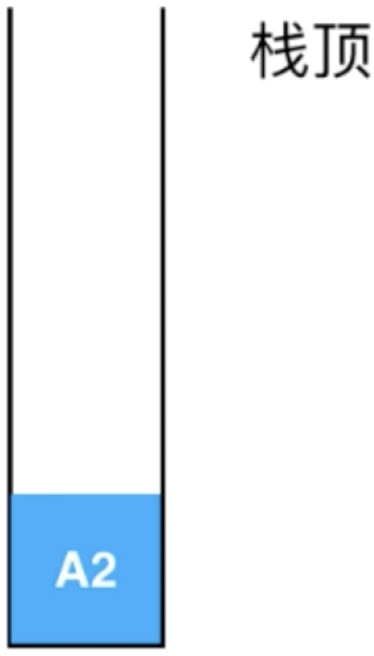
此时栈中的A2信息就可以出栈了,现在栈就为空的了:

接着就把A函数执行完:

此时计算机发现系统栈已经木有记录了,整个调用过程就结束了,熟悉了这个程序调用背后的原理之后,对于未来学习递归算法是非常有帮助的,到时再说。

栈的基本实现:
概述:
接下来则准备来手动实现一个栈,由于它是一个非常常见的一个数据结构,所以实现也比较简单,实现前先来简单梳理一下,对于一个栈它需要支持如下几个方法:

通常要实现这么一个栈:
- 从用户的角度来看,支持这些操作就好;
- 具体底层实现,用户不关心;
- 实际底层有多种实现方式【这个在后续会看到的】
在实现上,为了让程序的逻辑更加的清晰,也为了支持面向对象的多态性,代码设计上打算采用如下方式:

将Stack抽象成一个接口,里面定义了5种操作,然后目前的实现是基于上一次https://www.cnblogs.com/webor2006/p/14092866.html学习的动态数组来实现的一个栈,叫做ArrayStack,对于之后如果还有其它底层的实现再进行相应子类的扩展既可。
实现:
新建工程:
将Array拷过来:
由于底层打算是采用动态数组来实现,这里就将上一次学习中自己实现的Array拷工程:
创建Stack接口:
如上面设计思想所说,先来创建Stack所需要的接口方法:
public interface Stack<E> {
int getSize();
boolean isEmpty();
void push(E e);
E pop();//栈中弹出元素
E peek();//查看栈顶元素
}
创建ArrayStack:
接下来则创建具体的子类,底层打算采用Array动态数组来实现:

public class ArrayStack<E> implements Stack<E> {
@Override
public int getSize() {
return 0;
}
@Override
public boolean isEmpty() {
return false;
}
@Override
public void push(E e) {
}
@Override
public E pop() {
return null;
}
@Override
public E peek() {
return null;
}
}
实现构造:
如咱们实现的Array构造一样:

这里也定义两个:

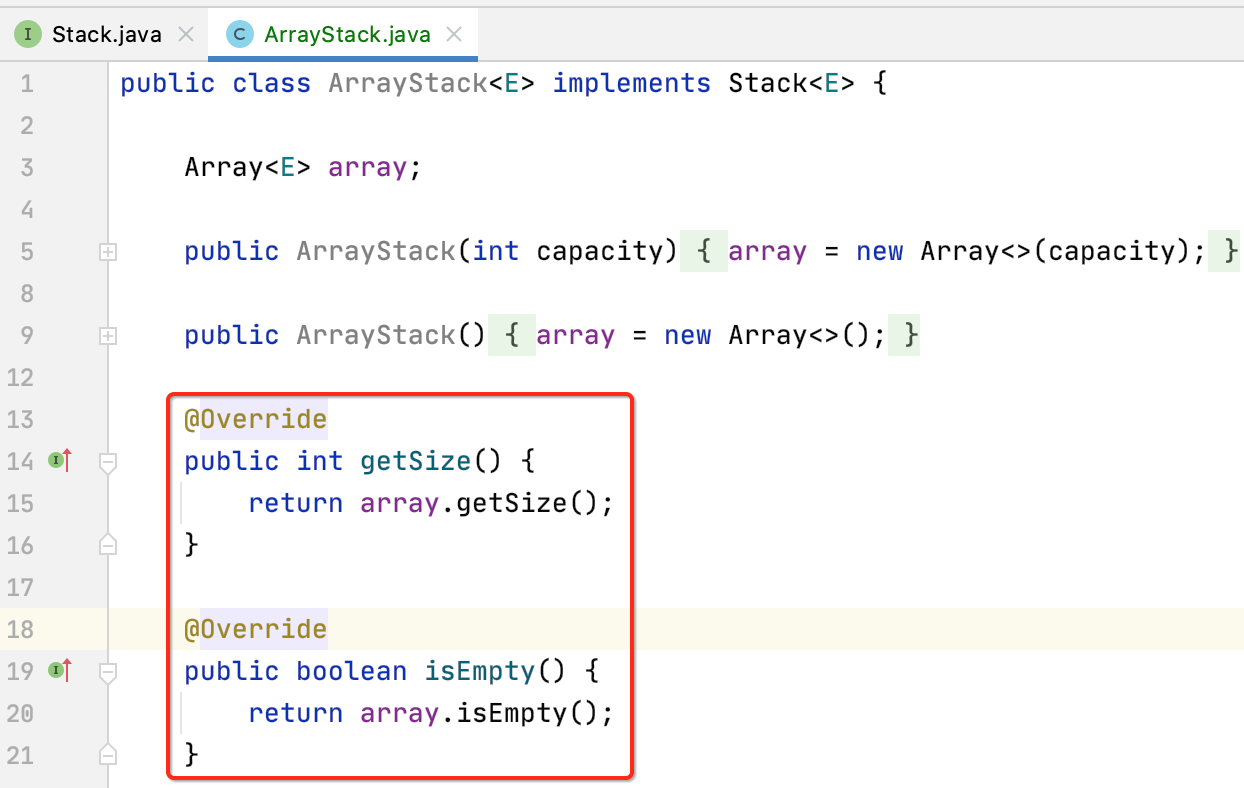
getSize()、isEmpty():
这俩比较简单:
getCapacity():获得栈中的容量
有时可能想查看栈中的容量,所以扩展一个方法:
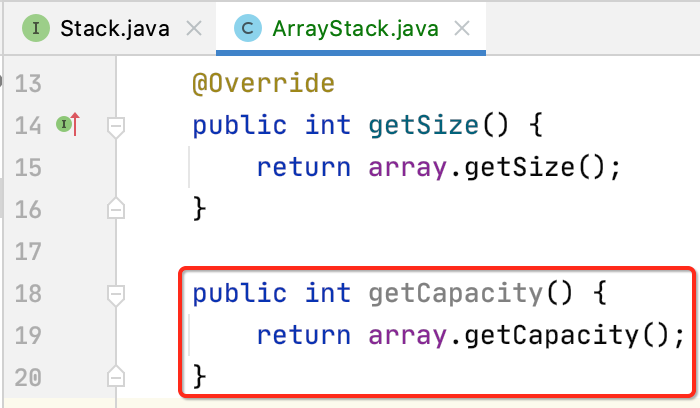
而为啥该方法木有定义到Stack接口中呢?因为它只是特定于Array这个底层实现的栈才会有,所以就定义在具体的子类了。
push():
直接往元素末尾进行添加:
@Override
public void push(E e) {
array.addLast(e);
}
pop():弹出栈顶元素
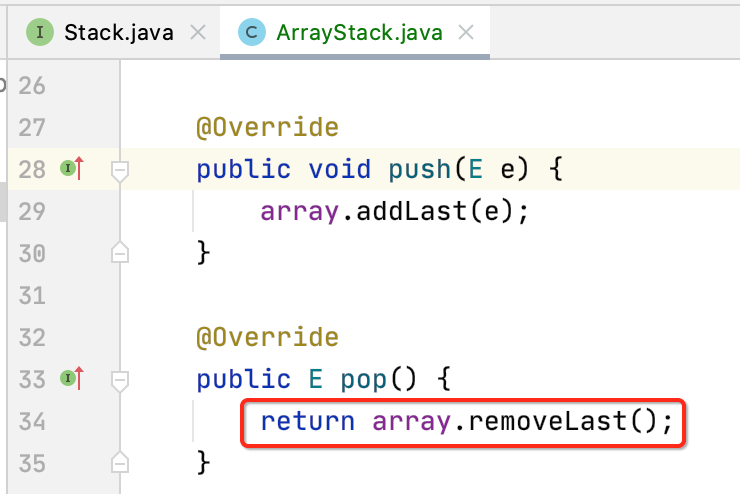
很显然,由于是用的动态数组,所以对于ArrayStack而言不用担心空间是否够的问题,可以动态进行扩容和缩容的。
peek():取出栈顶元素
很明显这个方法是要取出Array的最后一个元素,为了方便调用,这里先对Array类进行一个扩展,目前只有一个传索引的get方法:
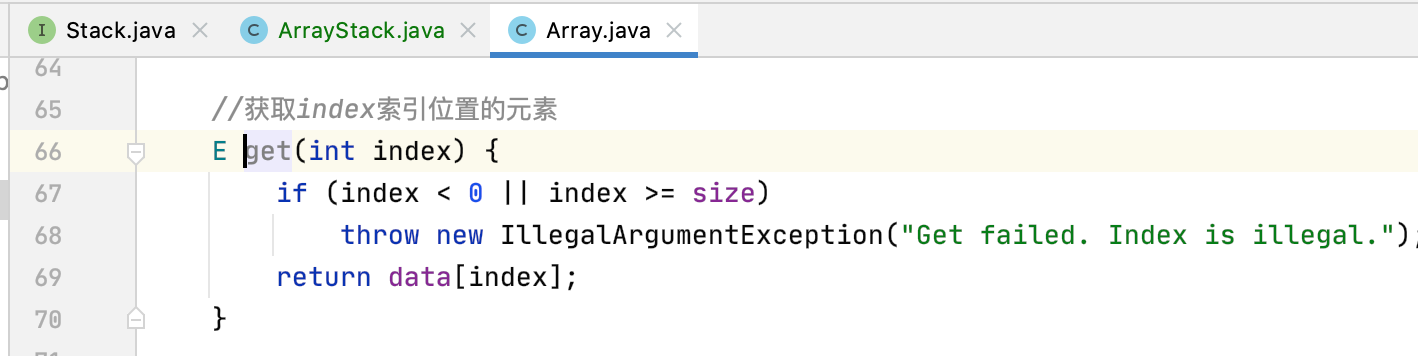

此时就可以这样轻松的实现peek()方法了:
@Override
public E peek() {
return array.getLast();
}
toString():
为了测试方便,对toString()进行一个重写,这里不用IDE的智能生成方式,因为要加一些可视化的信息,具体如下:
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append("Stack: ");
res.append('[');
for (int i = 0; i < array.getSize(); i++) {
res.append(array.get(i));
if (i != array.getSize() - 1)
res.append(", ");
}
res.append("] top");
return res.toString();
}
其中在字符串的最后加了一个“top”关键字,是可以清晰的知识栈顶在哪,对于咱们这个很显然就是在数组的最末尾,因为咱们添加元素是往后添加的:

其中再多说一句:貌似这里面没有提供对栈中间元素的操作的方法,其实这也是符合栈这样的数据结构的一个特点, 因为对于用户使用时是不需要知道栈中间的元素的,如果能操作栈中间的元素那么就破坏了整个栈这个数据结构了,所以中间的元素对于用户来说就应该不可见。
测试:
接下来则来调用测试一下:
public class Main {
public static void main(String[] args) {
ArrayStack<Integer> stack = new ArrayStack<>();
for (int i = 0; i < 5; i++) {
stack.push(i);
System.out.println(stack);
}
stack.pop();
System.out.println(stack);
}
}
运行:
/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/bin/java -Dfile.encoding=UTF-8 -classpath /Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/charsets.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/deploy.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/cldrdata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/dnsns.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/jaccess.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/jfxrt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/localedata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/nashorn.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunec.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunjce_provider.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunpkcs11.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/zipfs.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/javaws.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jce.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jfr.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jfxswt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jsse.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/management-agent.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/plugin.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/resources.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/rt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/ant-javafx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/dt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/javafx-mx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/jconsole.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/packager.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/sa-jdi.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/tools.jar:/Users/xiongwei/Documents/workspace/IntelliJSpace/algorithm_system_sudy/Stack/out/production/Stack Main
Stack: [0] top
Stack: [0, 1] top
Stack: [0, 1, 2] top
Stack: [0, 1, 2, 3] top
Stack: [0, 1, 2, 3, 4] top
Stack: [0, 1, 2, 3] top
Process finished with exit code 0
时间复杂度分析:
最后再来对咱们实现的栈中的各种方法进行一个复杂度的分析,其实比较简单,直接给出结论:

都是非常快的,其中对于push()和pop()都涉及到均摊复杂度的问题,因为会涉及到元素的扩容和缩容,但是不影响最终O(1)的结论,关于均摊的详细说明可以参考https://www.cnblogs.com/webor2006/p/14092866.html,这里就不过多说明了。
栈的另一个应用:括号匹配:
概述:
在上面已经理论介绍的关于栈的两个应用:

这里再来以实际落地的角度来看待另一个关于栈的典型应用:括号匹配-编译器,这个对于咱们编写程序的小伙伴来说很容易理解, 比如写表达式中的小括号、写数组的中括号、还有大括号(类、方法等)等,就会有括号匹配的问题出现,如果在输写时发现括号不匹配时编译器是会给咱们报错的对吧,那么编译器是如何来做这个括号匹配的检测的呢?其实也是利用栈,关于这个括号匹配的问题准备从Leetcode上来解决这么个问题,说实话对于Leetcode我还木注册过,平常也只是听说面试时可以刷刷它,正好利用此机会来解锁一下Leetcode,先给注册个账号。
Leetcode了解:
在正式注册账号之前,先对它有一个简单的了解,百度百科:
它的官网:https://leetcode.com/【英文】,https://leetcode-cn.com/【中文】,关于中文版和英文版的,目前是存在区别的,总言之官方英文版的肯定是最全的,中文的次之 ,不过对于咱们的学习来说,中文足够了,具体选中英版的自行选择。
账号注册:
由于我是第一次使用Leetcode,打开中文版的网站很显然需要注册账号:
这里我用邮箱注册,注册完成之后登录就可以看题了。
找到对应的题:
这道题就是咱们所要用栈来解决的,点击打开看一下题目的描述:
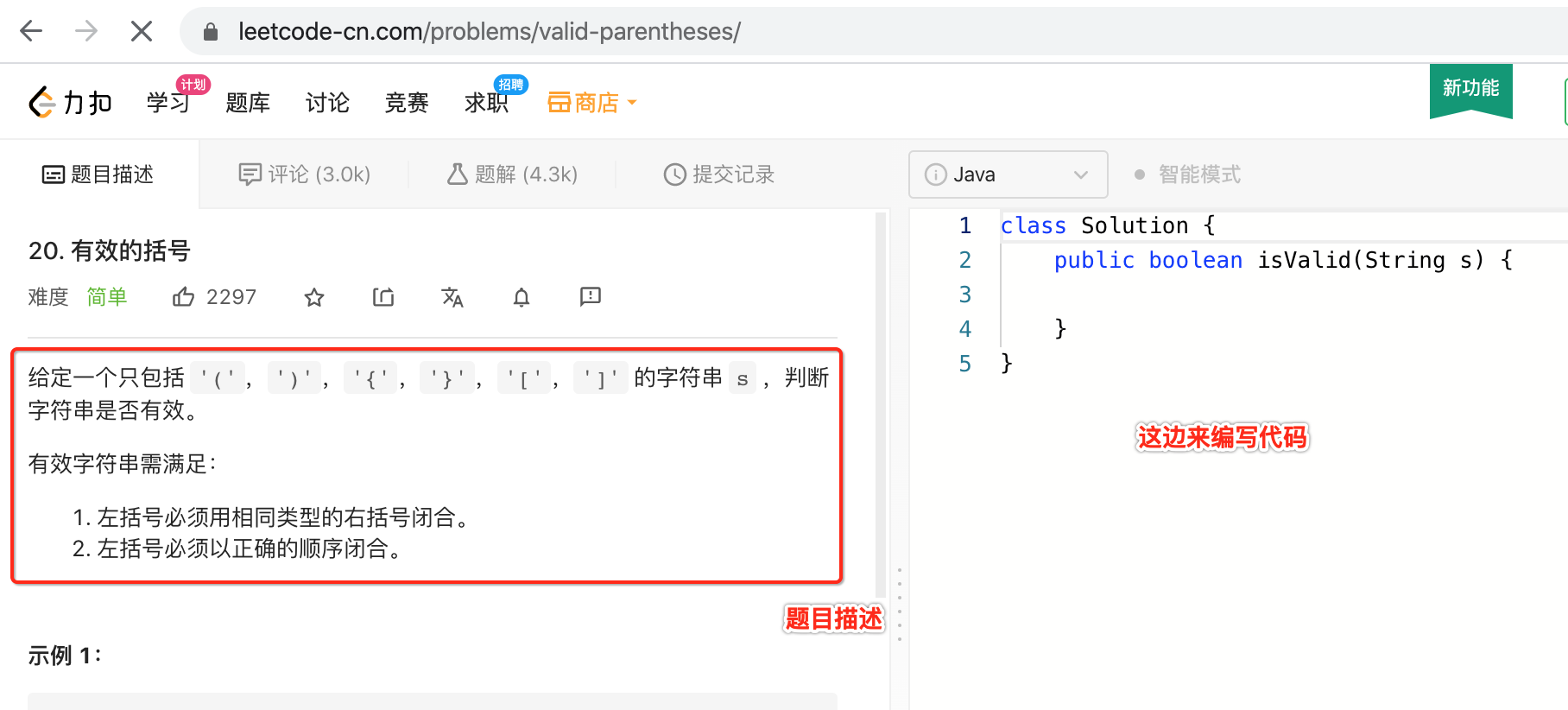
用栈来实现扩号匹配:
接下来则打算来实现这么一道LeetCode题,先将原题copy下来瞅一下整个的要求:
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
示例 1:
输入:s = "()"
输出:true
示例 2:
输入:s = "()[]{}"
输出:true
示例 3:
输入:s = "(]"
输出:false
示例 4:
输入:s = "([)]"
输出:false
示例 5:
输入:s = "{[]}"
输出:true
提示:
1 <= s.length <= 104
s 仅由括号 '()[]{}' 组成
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/valid-parentheses
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解题思路:
既然是用栈来解题,那具体要怎么弄呢?下面先来对其思路进行一个梳理,下面以两种场景的字符串来进行分解,一个是能匹配的,一个是不能匹配的。
能匹配字符串场景:
然后准备一个栈:
接下来则对字符串进行逐一遍历,整体思路就是如果字符是左括号则压入栈,而如果字符是右扩号,则拿栈顶的元素跟它进行匹配,如果刚好有对应的左扩号则就将栈中的这个左括号给出栈,否则不出,这样描述有点生涩,下面结合图来阐述整个匹配的过程:
1、“{”入栈:
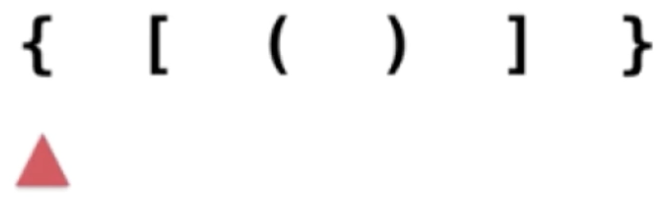
它是左括号对吧,将此字符入栈:

2、“[”入栈:
接下来处理下一个字符:
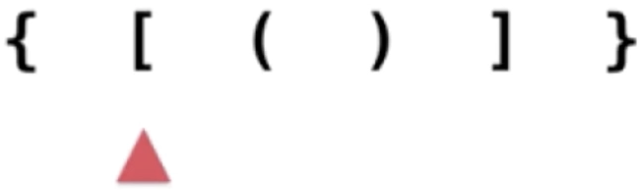
依然是左括号,入栈:

3、“(”入栈:
同样的,对于第三个字符:
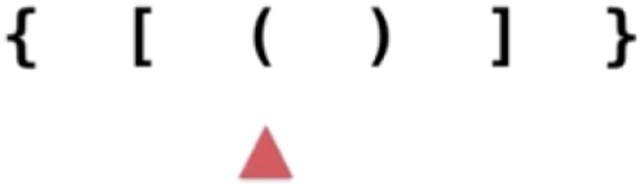
将其压入栈:

4、“)”跟栈顶的元素进行匹配:
由于此次要处理的元素是一个右括号,如开头所述的规则,这时就不把它入栈了,而是让它跟栈顶的元素进行匹配,如果有匹配的左括号则就出栈,很显然“(”跟“)”刚好匹配,那栈顶的元素“(”出栈,此时栈中的情况就为:
5、“]”跟栈顶的元素进行匹配:
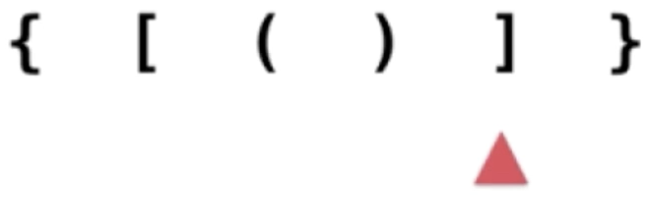
它跟栈顶也能匹配,因为栈顶是“[”,所以,栈顶元素出栈:

6、“}”跟栈顶的元素进行匹配:
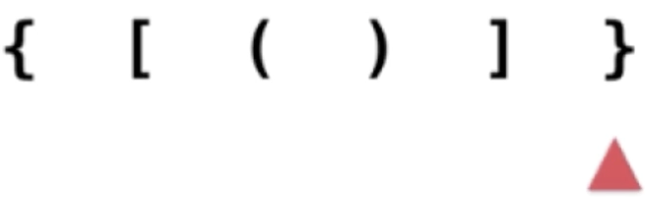
同样跟栈顶进行匹配,能匹配上,因为栈顶是“{”,出栈:

7、结果判定:
整个元素都遍历完之后,先来看栈中是否是空的,如果是空的则说明这个字符串是合法的扩号匹配,否则不是。
不能匹配字符串场景:
1、“{”入栈:
遇左括号入栈:
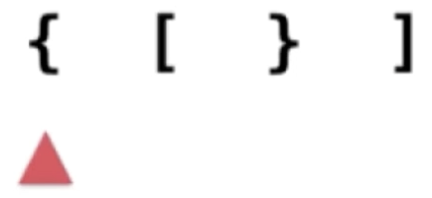

2、“[”入栈:
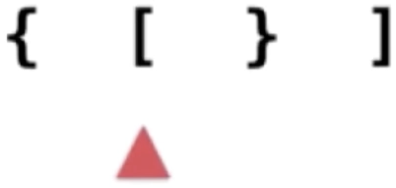

3、“}”跟栈顶的元素进行匹配:

跟栈顶元素匹配不上,所以此时结果就可以返回了,说明整个字符串不是括号匹配的。
总结:
通过上面的拆解过程,可以发现栈顶元素反映的是在嵌套的层次关系中,最近的需要匹配的元素。
IDE中实现:
1、新建包名:
2、将leetcode代码模板拷过来:
由于最终咱们实现的代码是要拷到Leetcode中来验证正确性的,所以这里用Leetcode提供的代码模板:
拷过来:
3、循环遍历字符:
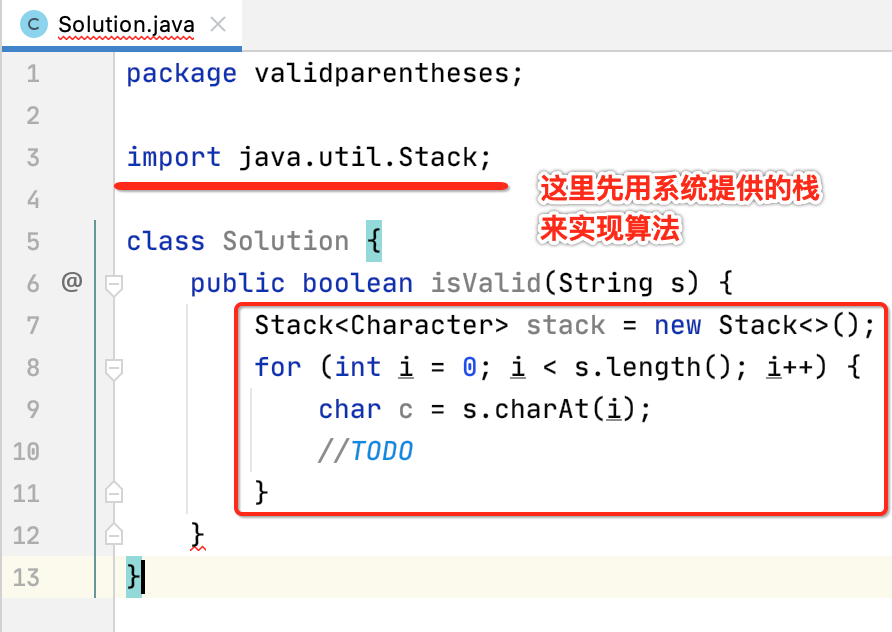
4、遇到左括号,则入栈:
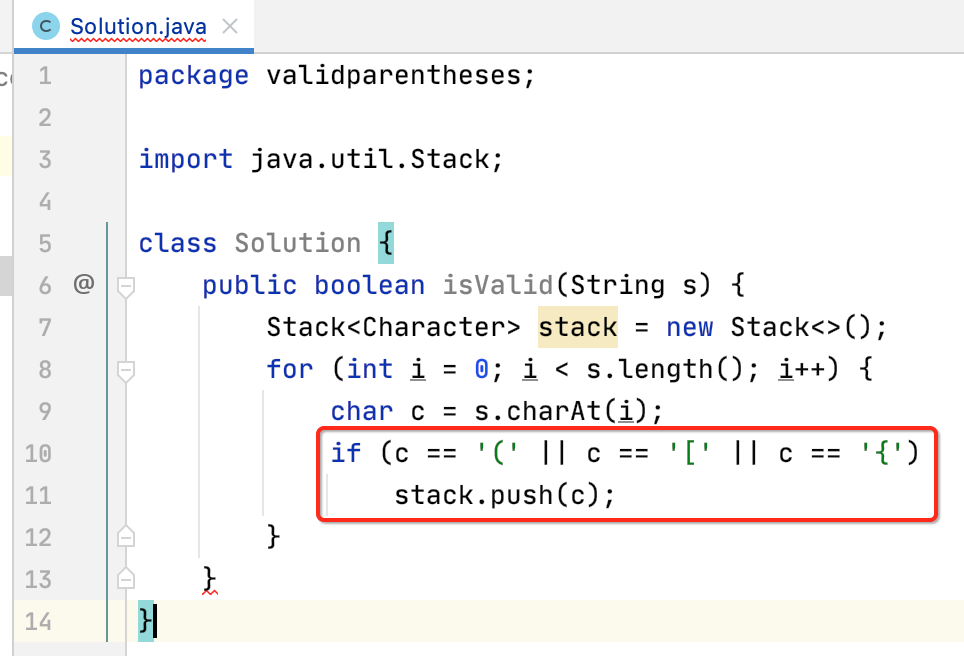
5、 遇右括号,跟栈顶元素进行匹配:
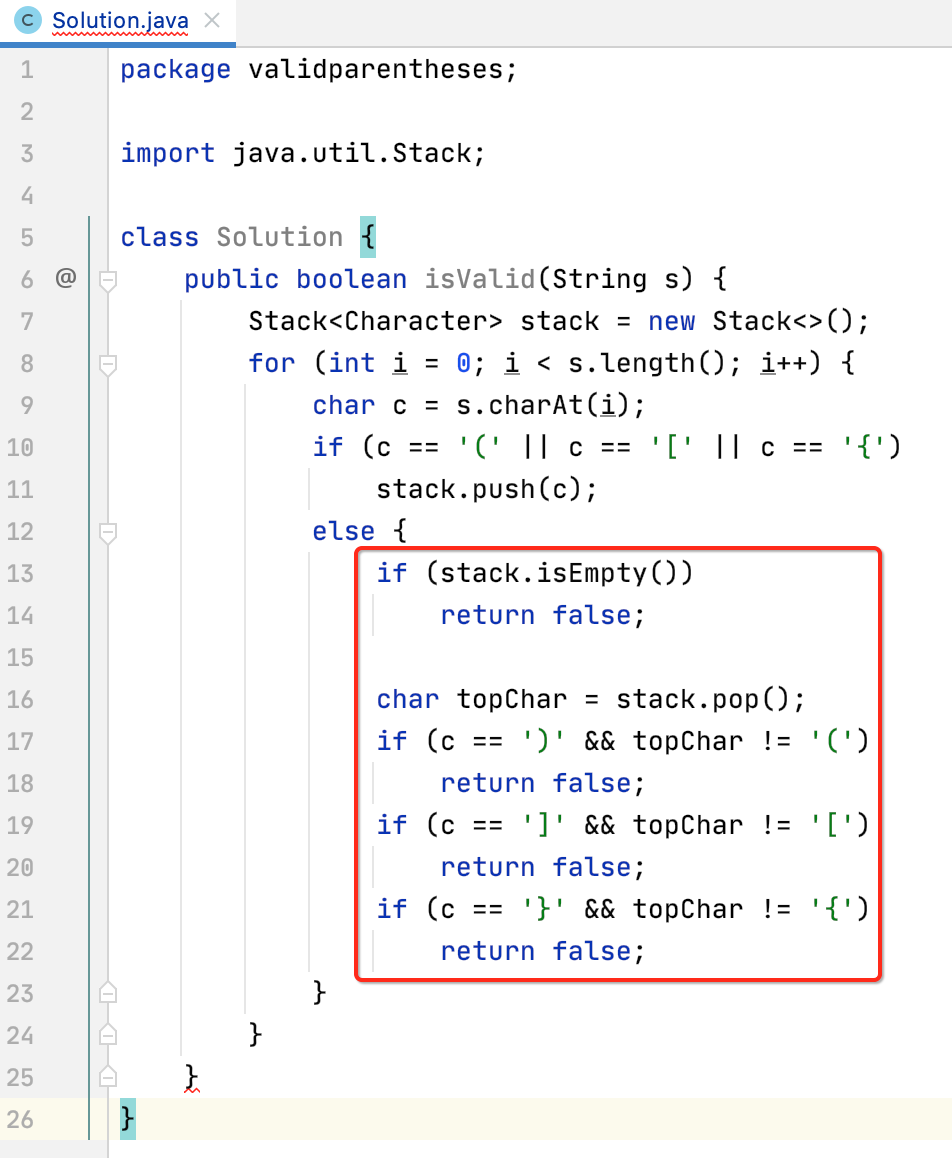
6、最后判断栈是否为空:
注意,最后还得看栈中是否是空栈哟,所以整个的实现逻辑为:
package validparentheses;
import java.util.Stack;
class Solution {
public boolean isValid(String s) {
Stack<Character> stack = new Stack<>();
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (c == '(' || c == '[' || c == '{')
stack.push(c);
else {
if (stack.isEmpty())
return false;
char topChar = stack.pop();
if (c == ')' && topChar != '(')
return false;
if (c == ']' && topChar != '[')
return false;
if (c == '}' && topChar != '{')
return false;
}
}
return stack.isEmpty();
}
}
7、运行:
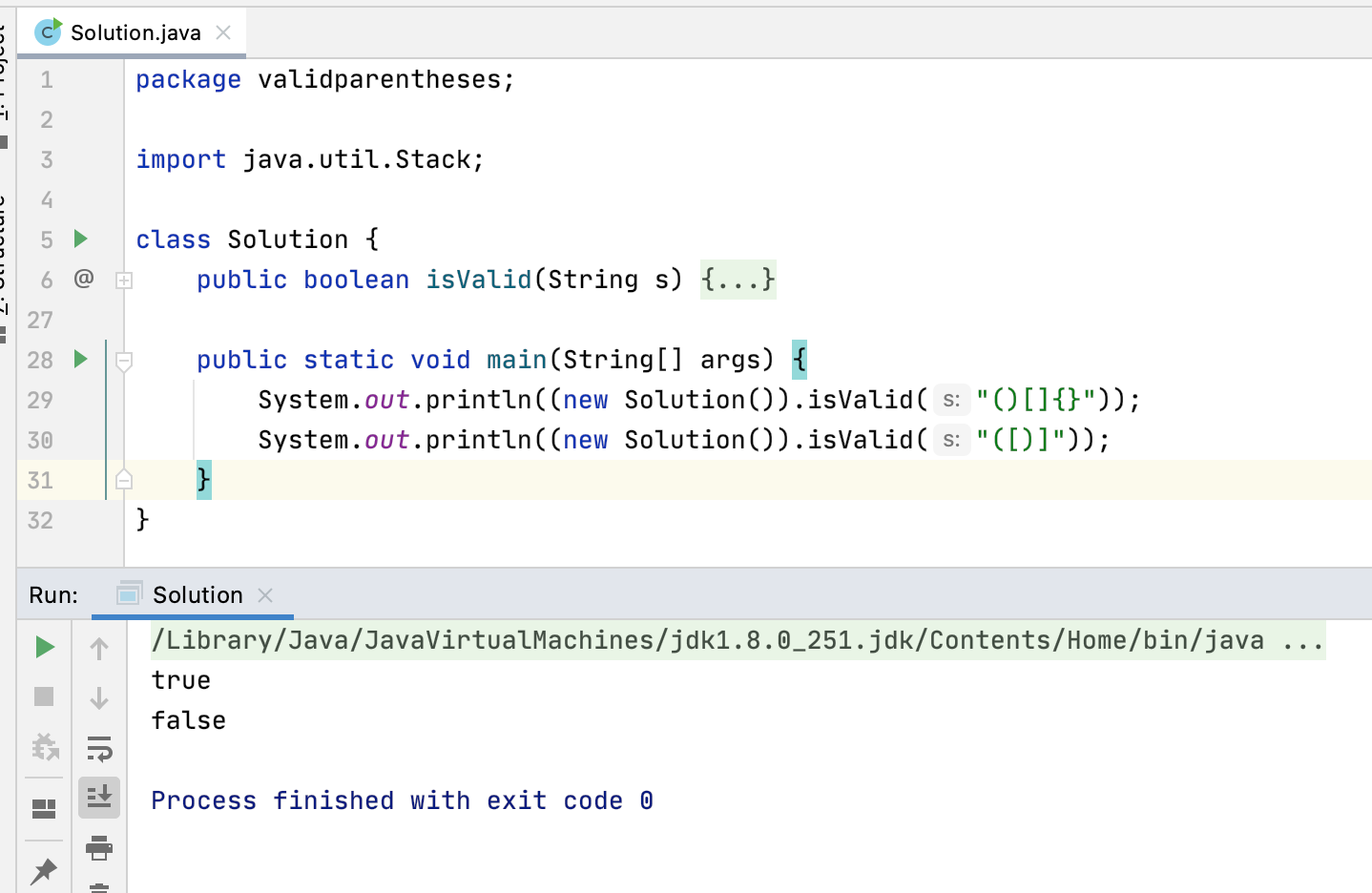
木问题。
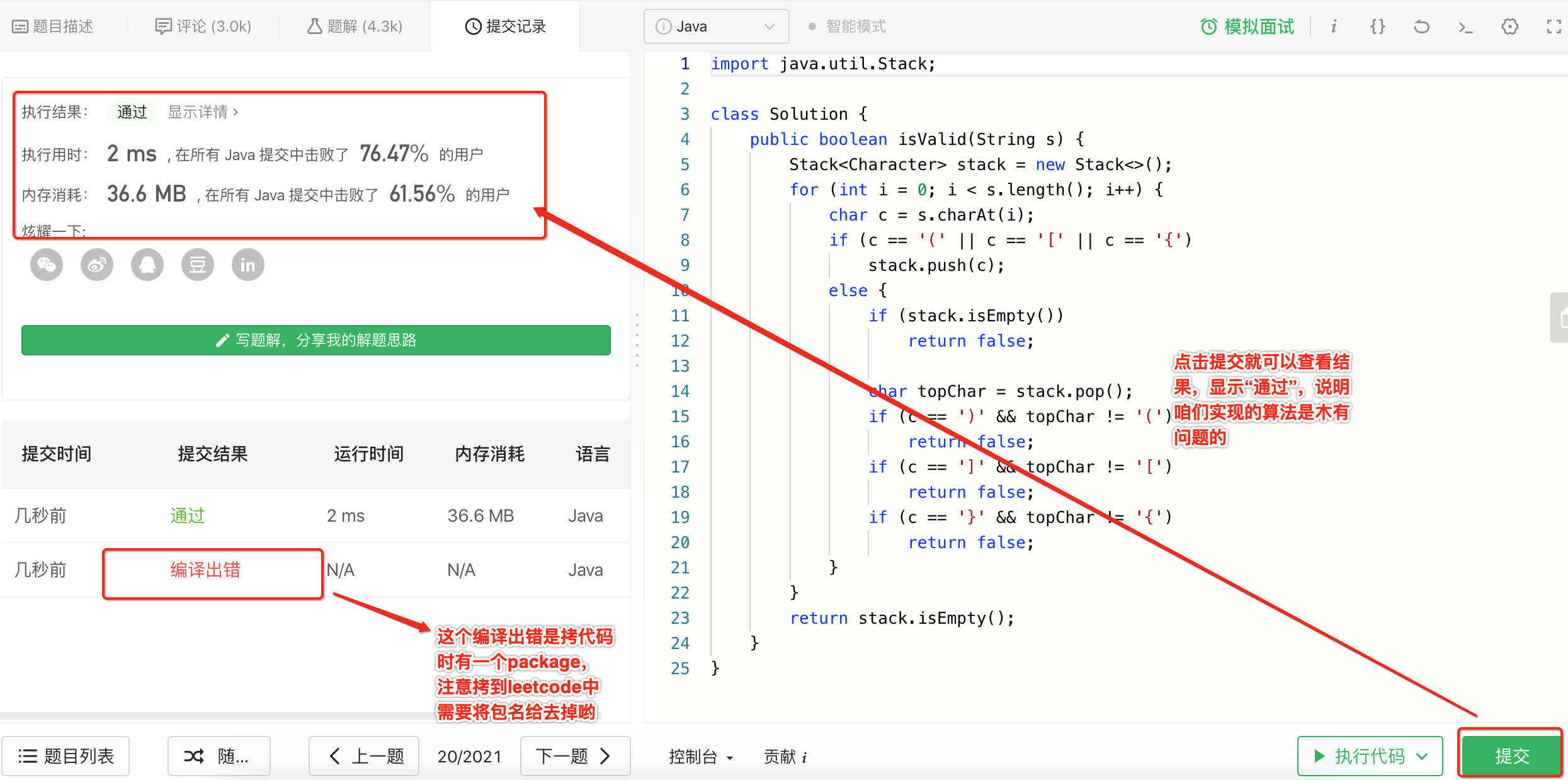
拷贝到Leetcode中进行结果验证:
接下来将咱们实现的代码拷到Leetcode中进行验证:
关于 Leetcode 的更多说明:
1、main函数可以不用删除:
通常在实现时都会先本机写个main函数进行验证写的正确性,而当拷贝到leetcode验证明,这个main()函数是不用删除的,看一下:
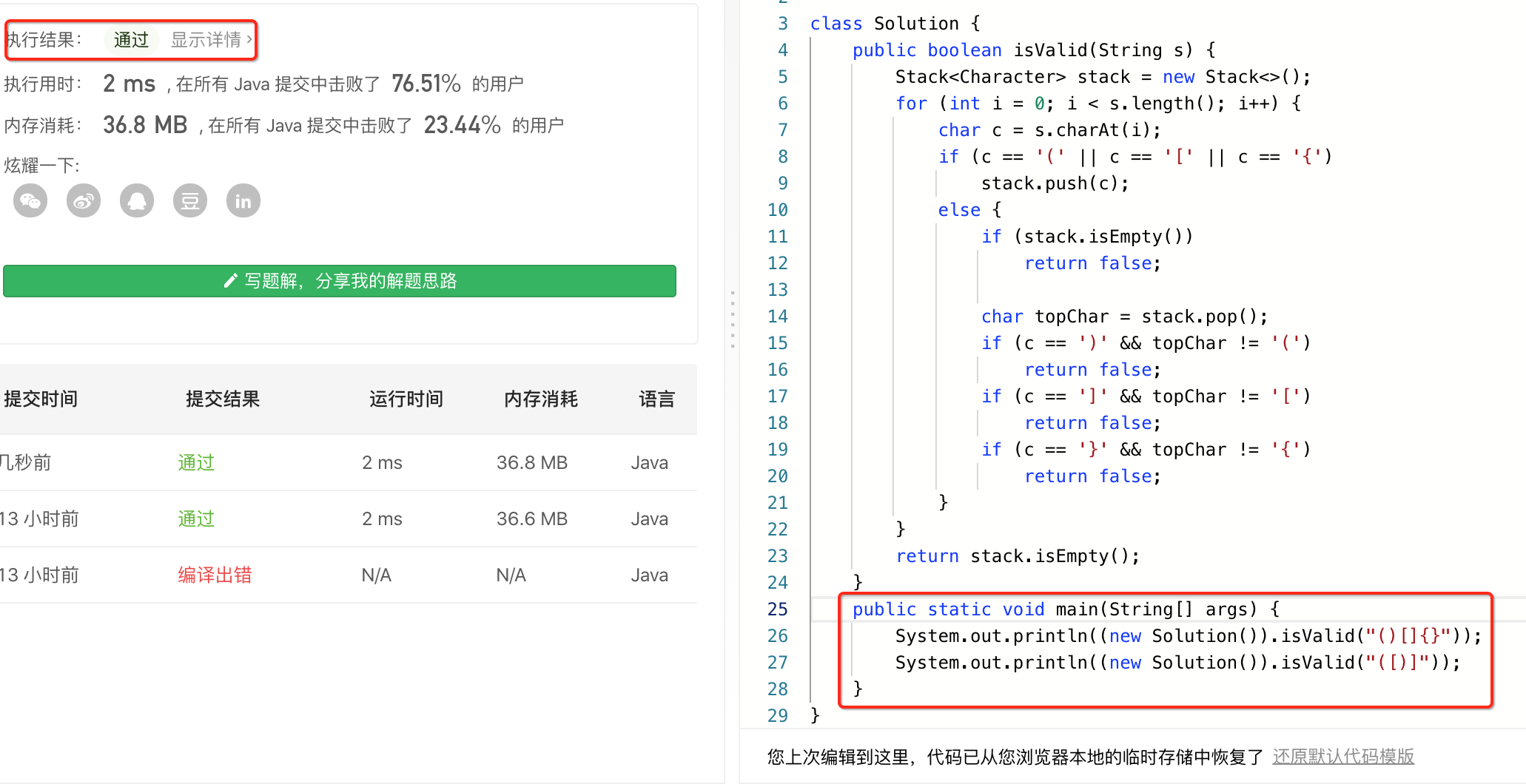
很明显LeetCode只找isValid()方法,其它方法不影响。
2、方法必须是public的:
如果将isValid()改为私有的看下结果:
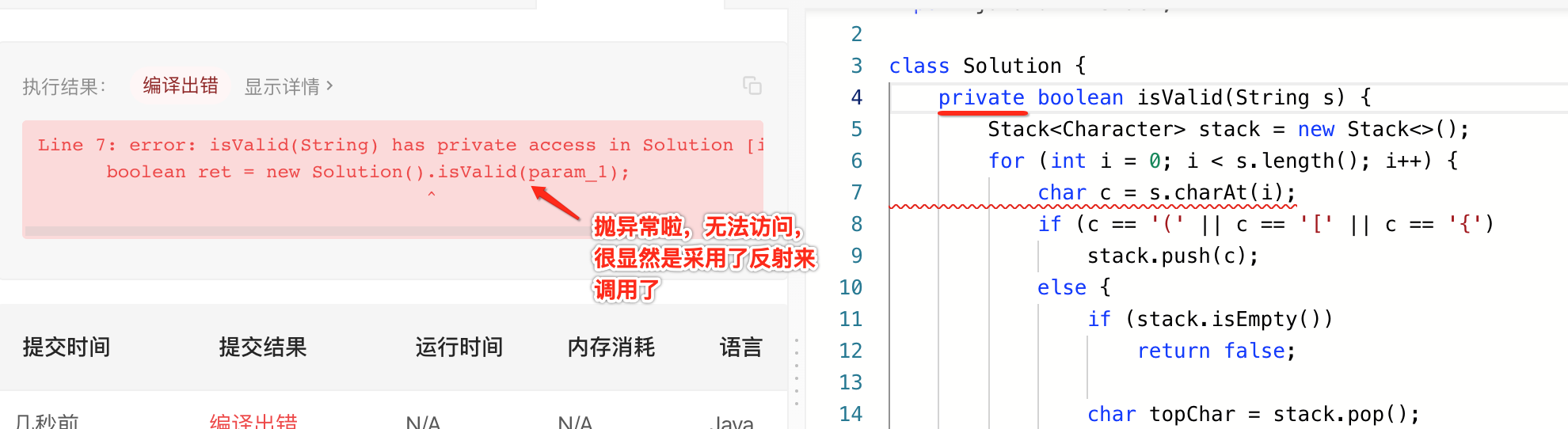
3、引用其它类:
目前咱们实现栈是用的jdk中系统的Stack,而如果改为咱们自己实现的ArrayStack呢?下面改造一下:
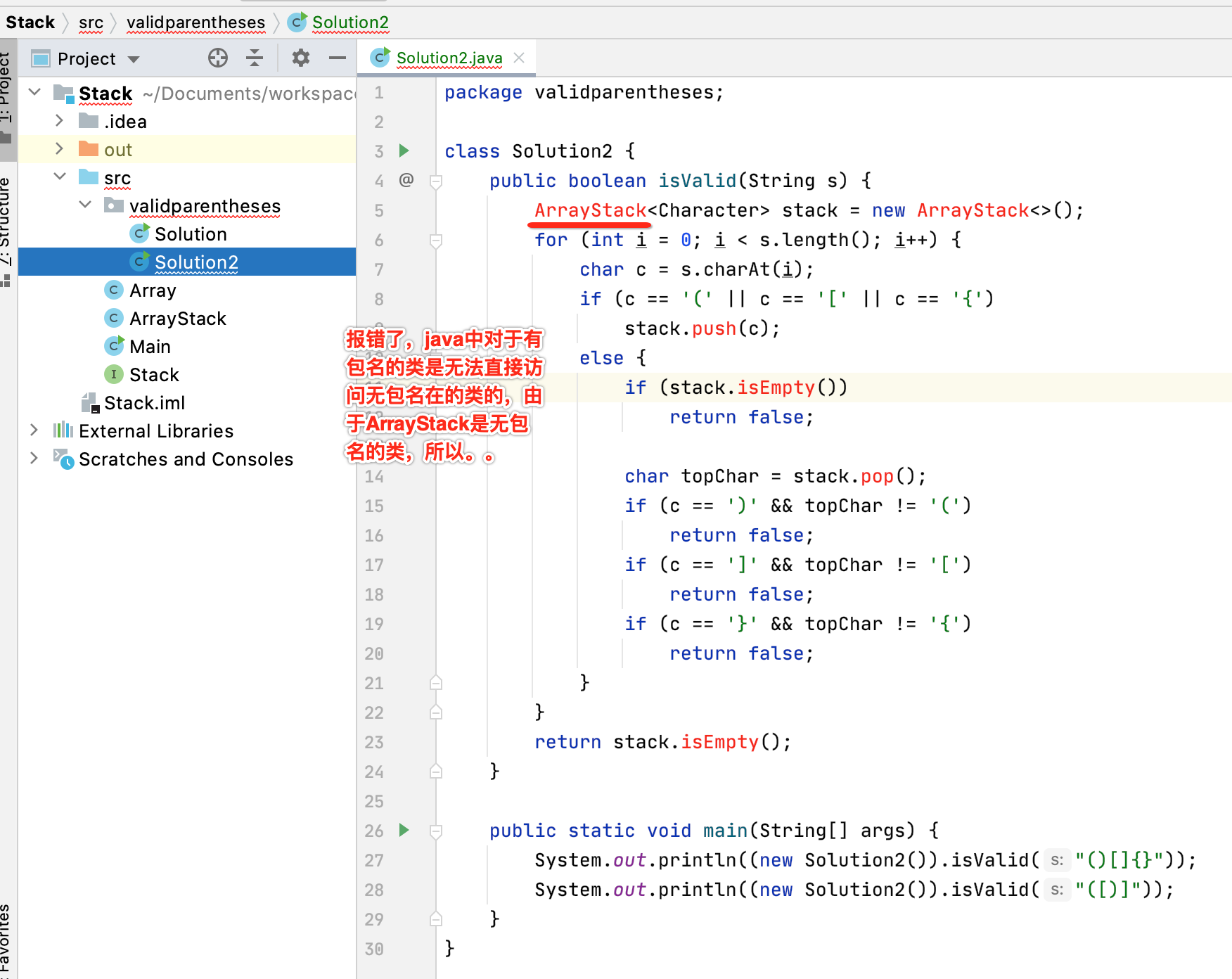
这个细节说实话我还有些疑惑,所以将其挪到ArrayStack平级目录中,再来看一下:

换成咱们自己实现的栈也木有问题,那么问题来了,目前咱们的实现是依赖于其它三个类:
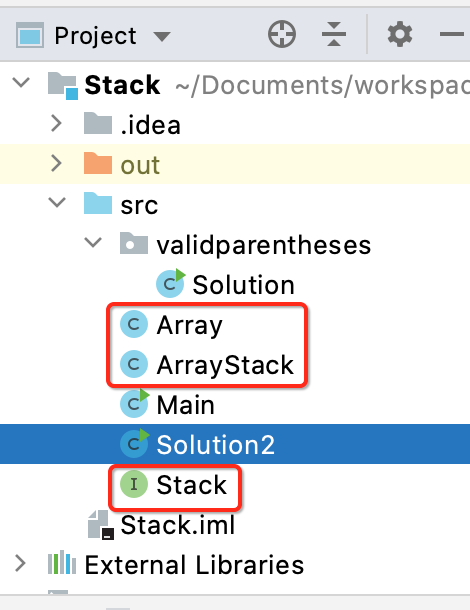
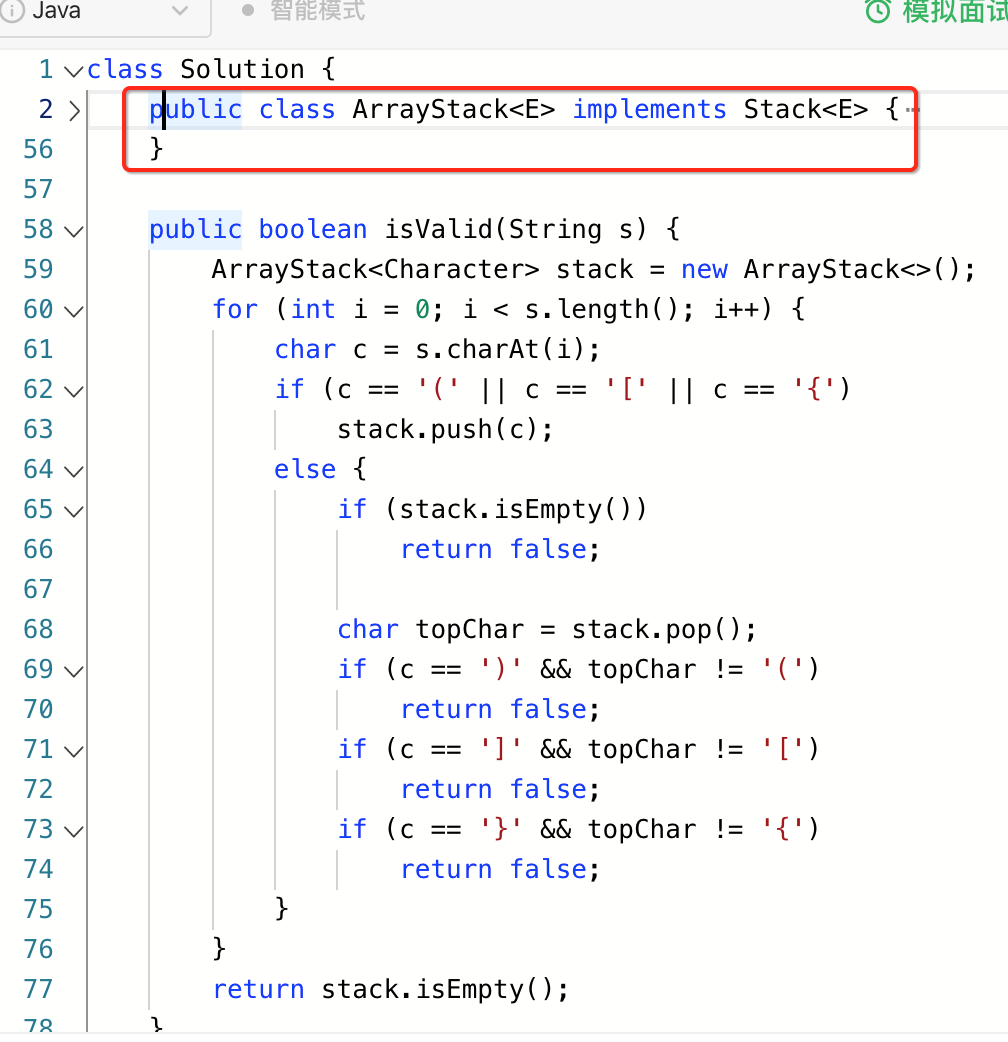
那如何将其拷到Leetcode中进行验证呢?其实也是可以的,咱们先来将Solution的实现拷进LeetCode中:

很明显目前是编译不过的:

解决办法也是很简单的,直接将依赖的类拷到Solution中当成内部类既可,如下:
代码太长了可以折叠一下:
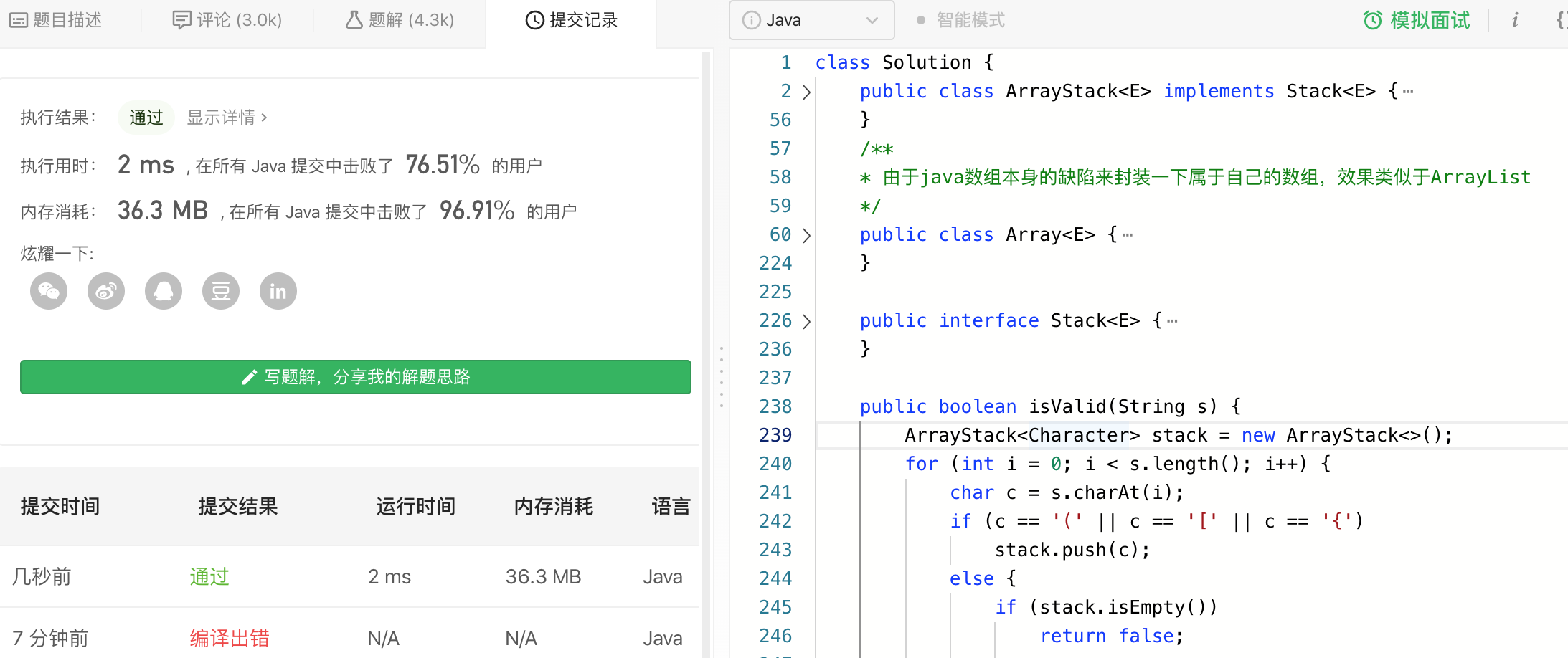
其它两个类似,都拷过来:
这样执行就成功通过了,另外还有一个小细节,就是对于拷过来的这三个类很明显对于LeetCode而言是调用不到的,它只是给程序内部用的,所以其实都可以将其声明为private,咱们试一下:
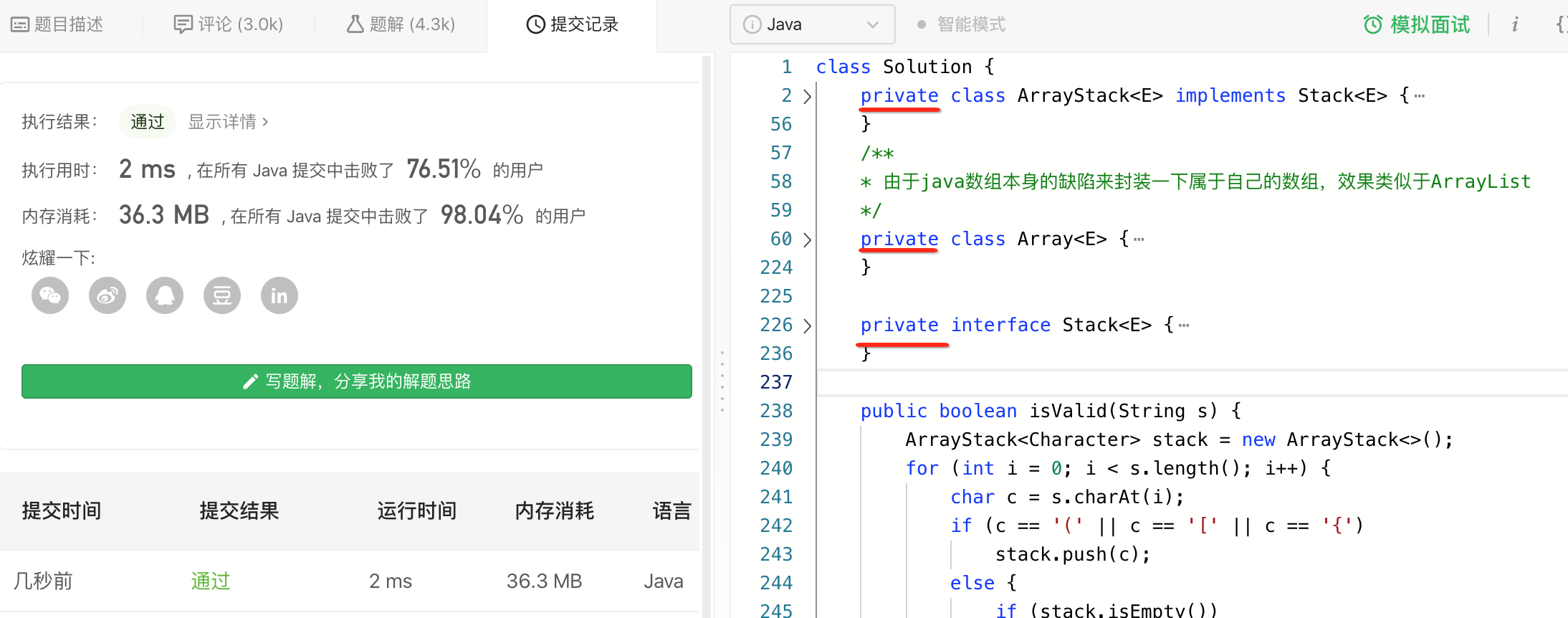
木问题。
队列【Queue】:
- 队列也是一种线性结构;
- 相比数组,队列对应的操作是数组的子集;
- 只能从一端(队尾)添加元素,只能从另一端(队首)取出元素;
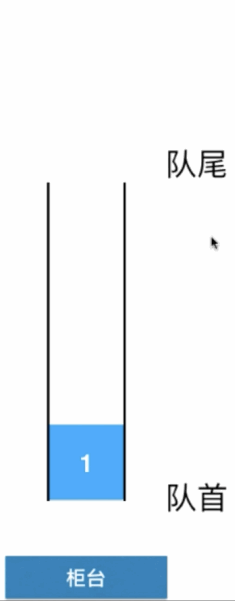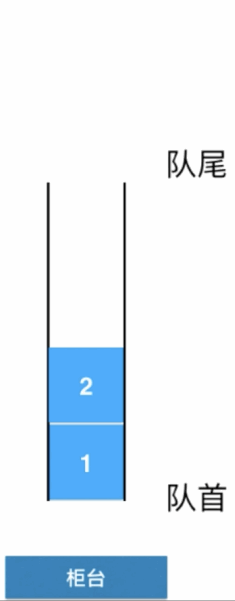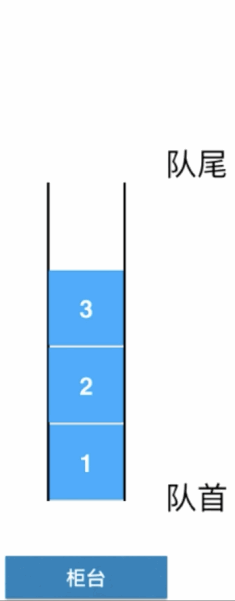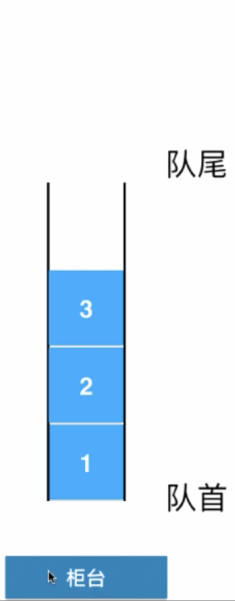
以图来表示,比如这么一个队列:
这里可以以到银行柜台办业务的场景来理解:
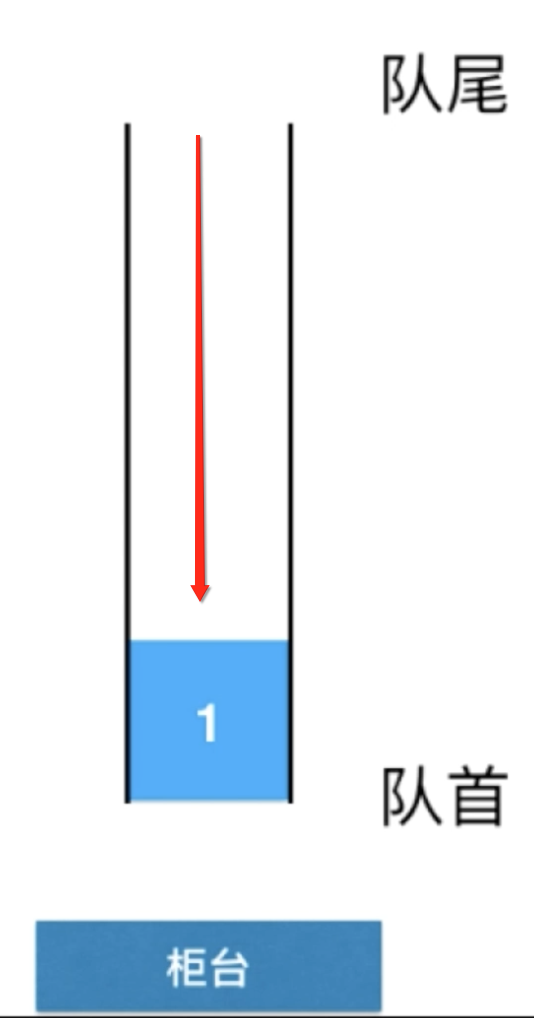
来了一个人来办理业务,从队尾进入,接下来再来几个人同样的都是从队尾进入排队:
此时业务员已经办完了一个,接下来则需从队列中取出一个元素进行处理,此时就从队首中取一个,如下:
此时这里就可以对比上面学习的栈了,栈取出的是最后添加的,也就是3,但是对于队列来说是1,也就是最先添加的,好继续,又来了一个人,队尾排队:
此时业务员又叫号处理下一位,这一位同样是来自于队首: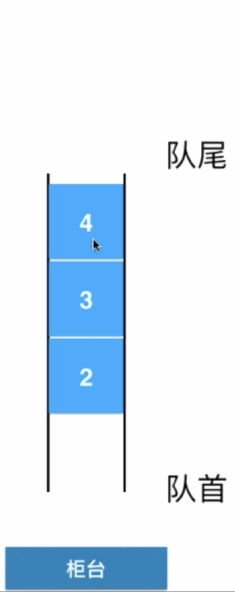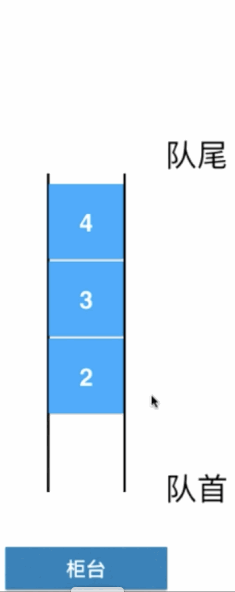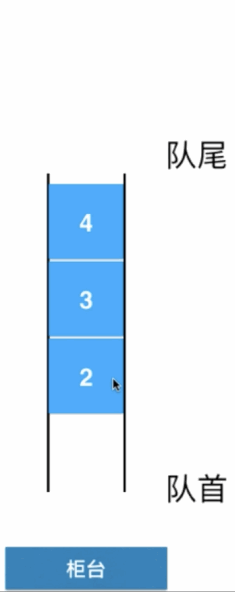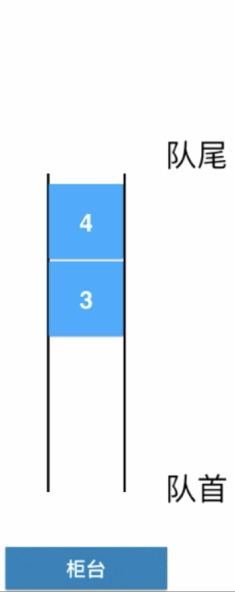
- 从上面也可以看出,队列是一种先进先出【First In First Out(FIFO)】的数据结构(先到先得)。
队列的基本实现:
接下来则来实现一下队列,通常队列会有如下方法:

数组队列:
同样的,这里底层也用Array来进行实现:

1、新建工程:
同样将咱们自己实现的Array拷贝进来。
2、定义Queue接口:
public interface Queue<E> {
int getSize();
boolean isEmpty();
void enqueue(E e);
E dequeue();
E getFront();
}
3、 实现ArrayQuque:
由于这块比较简单,直接将整个代码贴出来,栈和队列基本上都比较熟了:
public class ArrayQueue<E> implements Queue<E> {
private Array<E> array;
public ArrayQueue(int capacity) {
array = new Array<>(capacity);
}
public ArrayQueue() {
array = new Array<>();
}
@Override
public int getSize() {
return array.getSize();
}
@Override
public boolean isEmpty() {
return array.isEmpty();
}
public int getCapacity() {
return array.getCapacity();
}
@Override
public void enqueue(E e) {
array.addLast(e);
}
@Override
public E dequeue() {
return array.removeFirst();
}
@Override
public E getFront() {
return array.getFirst();
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append("Queue: ");
res.append("front [");
for (int i = 0; i < array.getSize(); i++) {
res.append(array.get(i));
if (i != array.getSize() - 1)
res.append(", ");
}
res.append("] tail");
return res.toString();
}
public static void main(String[] args) {
ArrayQueue<Integer> queue = new ArrayQueue<>();
for (int i = 0; i < 10; i++) {
queue.enqueue(i);
System.out.println(queue);
if (i % 3 == 2) {
queue.dequeue();
System.out.println(queue);
}
}
}
}
运行:
/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/bin/java -Dfile.encoding=UTF-8 -classpath /Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/charsets.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/deploy.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/cldrdata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/dnsns.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/jaccess.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/jfxrt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/localedata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/nashorn.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunec.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunjce_provider.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunpkcs11.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/zipfs.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/javaws.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jce.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jfr.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jfxswt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jsse.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/management-agent.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/plugin.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/resources.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/rt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/ant-javafx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/dt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/javafx-mx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/jconsole.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/packager.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/sa-jdi.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/tools.jar:/Users/xiongwei/Documents/workspace/IntelliJSpace/algorithm_system_sudy/Queue/out/production/Queue ArrayQueue
Queue: front [0] tail
Queue: front [0, 1] tail
Queue: front [0, 1, 2] tail
Queue: front [1, 2] tail
Queue: front [1, 2, 3] tail
Queue: front [1, 2, 3, 4] tail
Queue: front [1, 2, 3, 4, 5] tail
Queue: front [2, 3, 4, 5] tail
Queue: front [2, 3, 4, 5, 6] tail
Queue: front [2, 3, 4, 5, 6, 7] tail
Queue: front [2, 3, 4, 5, 6, 7, 8] tail
Queue: front [3, 4, 5, 6, 7, 8] tail
Queue: front [3, 4, 5, 6, 7, 8, 9] tail
Process finished with exit code 0
复杂度分析:
整个复杂度跟ArrayStack差不多:

其中标红的出队跟出栈的复杂度是不一样的,为啥呢?因为它是删除数组的第0个元素,删除之后数组后面的元素都得进行一个向前的移位,回忆一下:
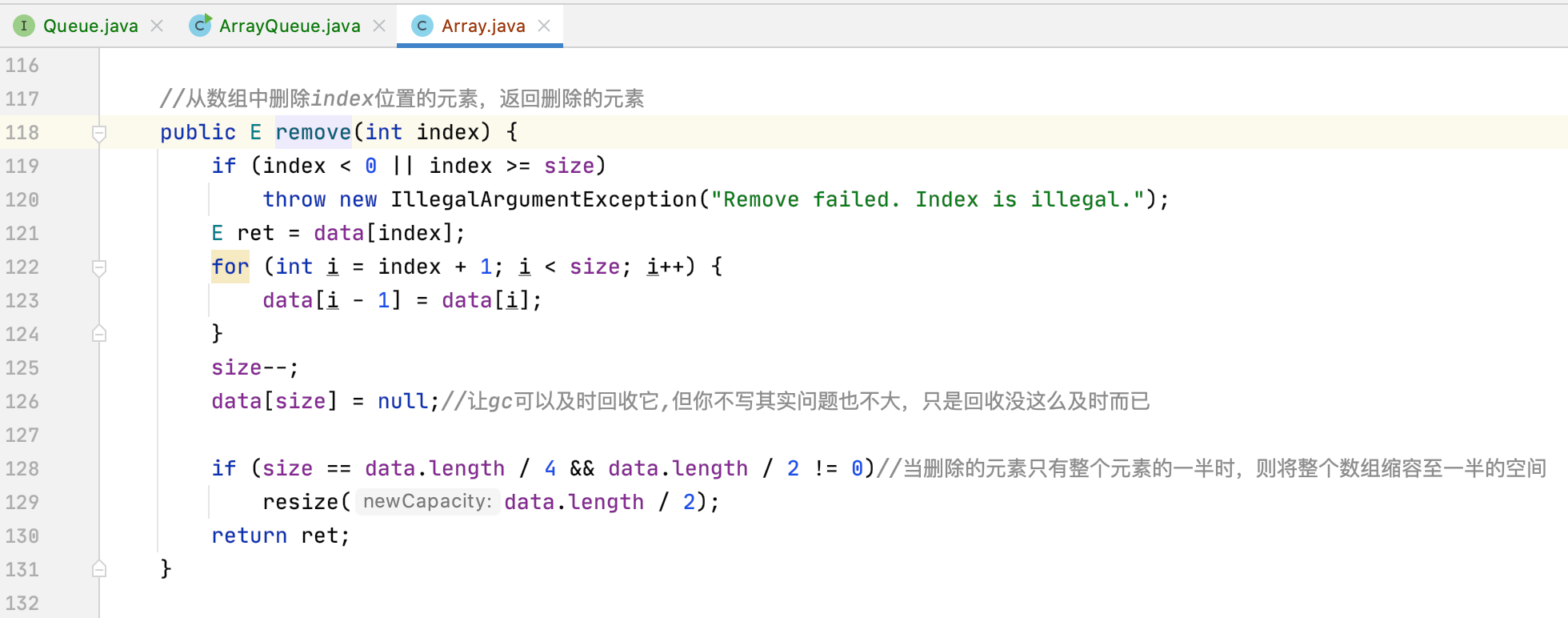
那么此时数组队列的这个弊端就出来了,也就是如果队列中当数据量很大的时候,出队操作性能是很差的,那有木有办法让出队的复杂度也能变为O(1)呢?可以的,继续往下学习就可以知晓了。
循环队列:
数组队列的问题:
在上面咱们也提到对于数组队列存在的一个很大的问题就是对于出队它的复杂度是O(n),性能不好,那么要解决这个问题之前先来正视一下它,比如这么一个队列:
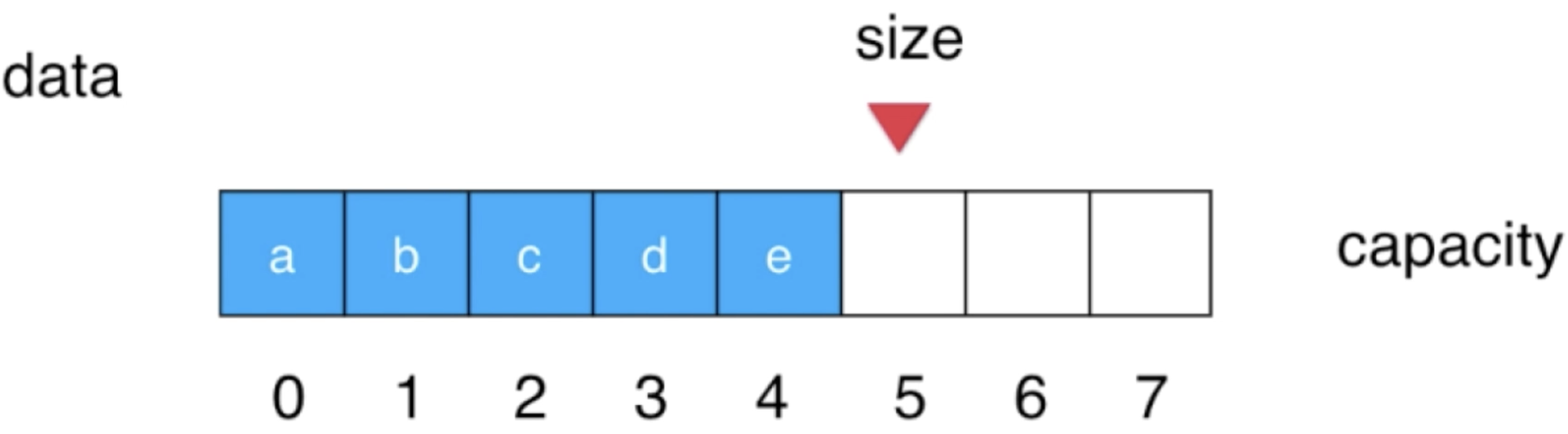
其中假设左边是队首,右边是队尾,接下来要删除队首的元素此时“a”就会出队:

此时后面的元素都必须往前挪一个位置,然后size--:
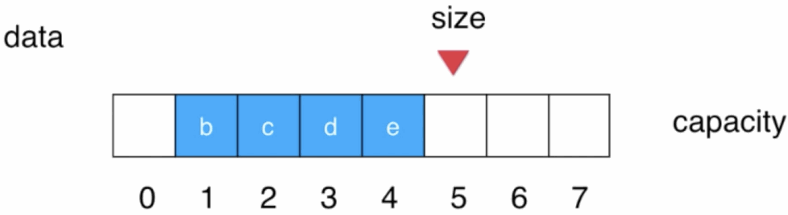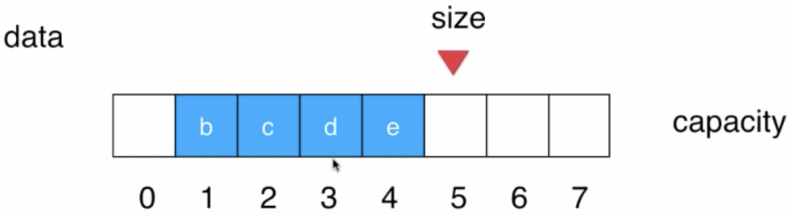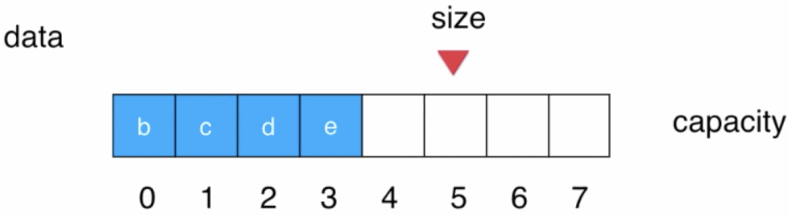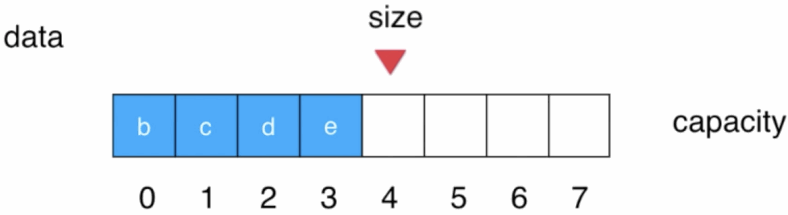
这是O(n)出现的根本原因,要解决的话思路其实也很简单,那就是在队首出队时,后面的元素想办法不让其往前挪动就成了,那如何办到呢?此时就得增加2个标识用来表示当前队列的队首和队尾了,如下:
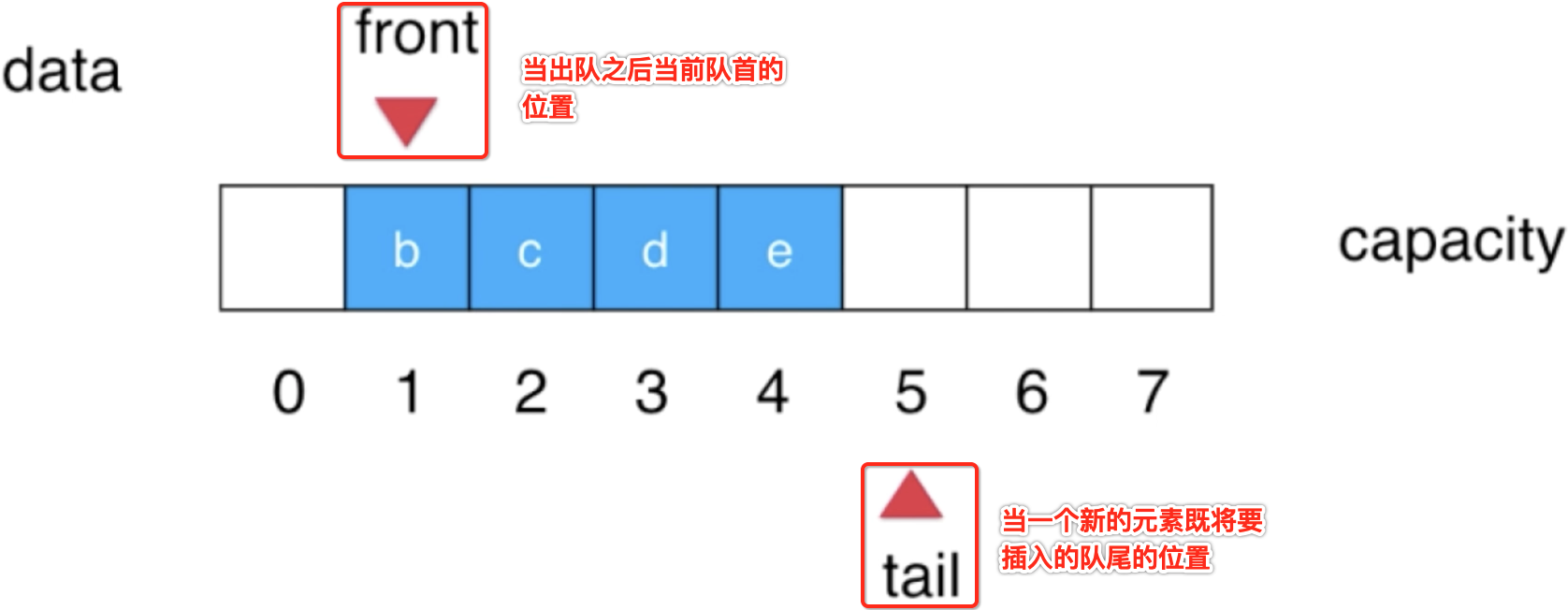
这样当元素从队列中移出时,只需要维护一下front和tail指向既可,这样就避免了元素移动造成性能不好的问题了,基于这种想法循环队列就出现了。
了解循环队列:
接下来了解一下循环队列。
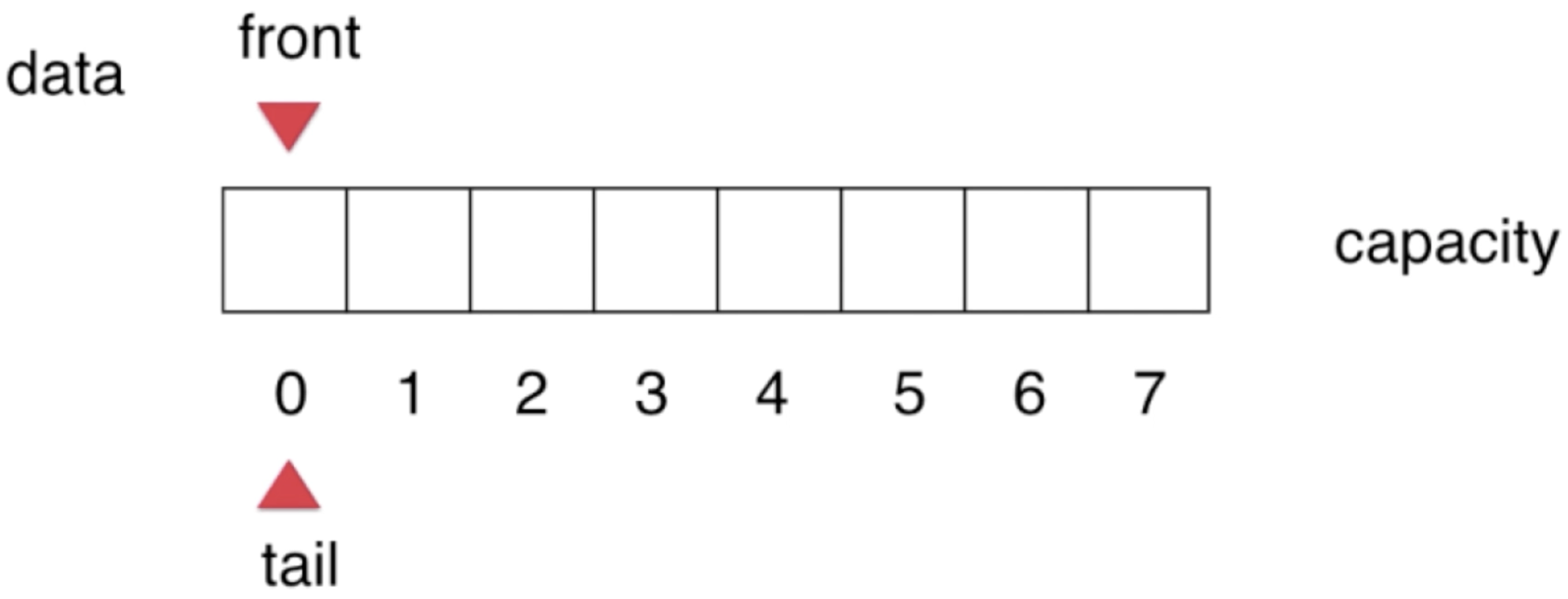
1、初始的状态下:
此时的front==tail【这也是队列为空的一个判断条件】:
2、“a”入队:
接下来有个元素入队了:
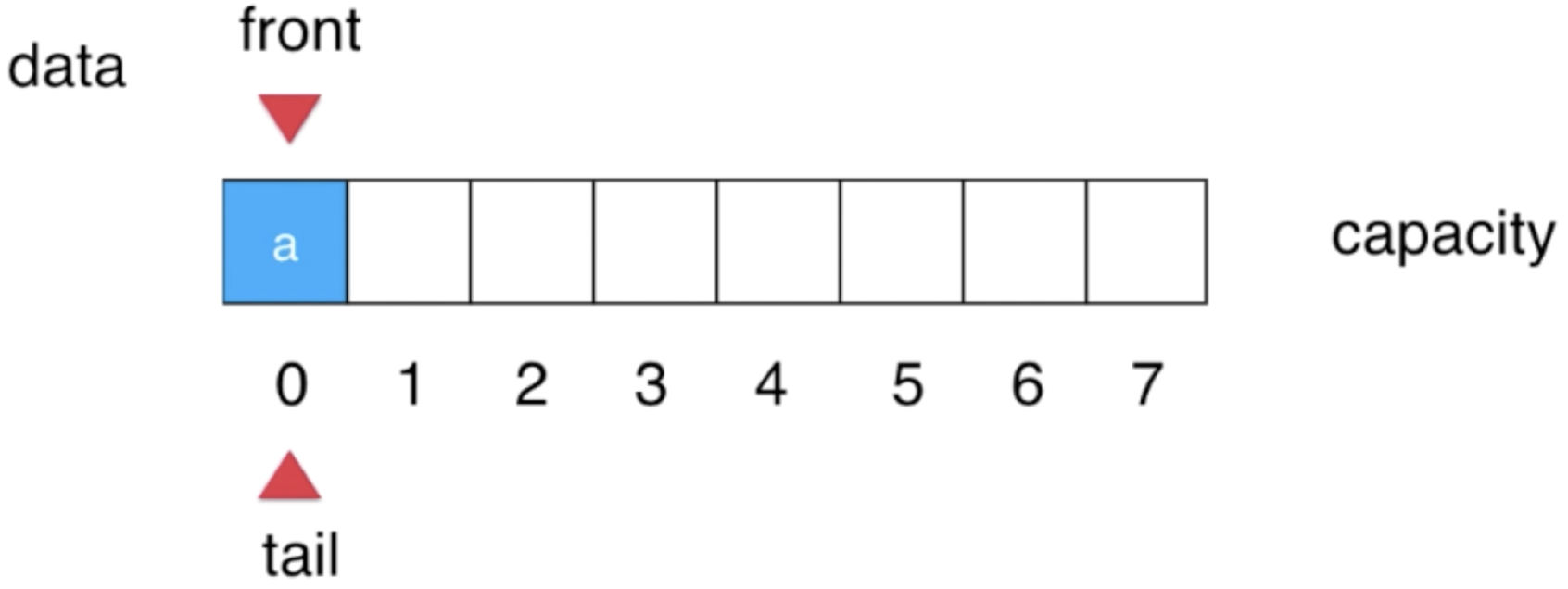
此时只需维护一下tail, 让其指向下一个元素:
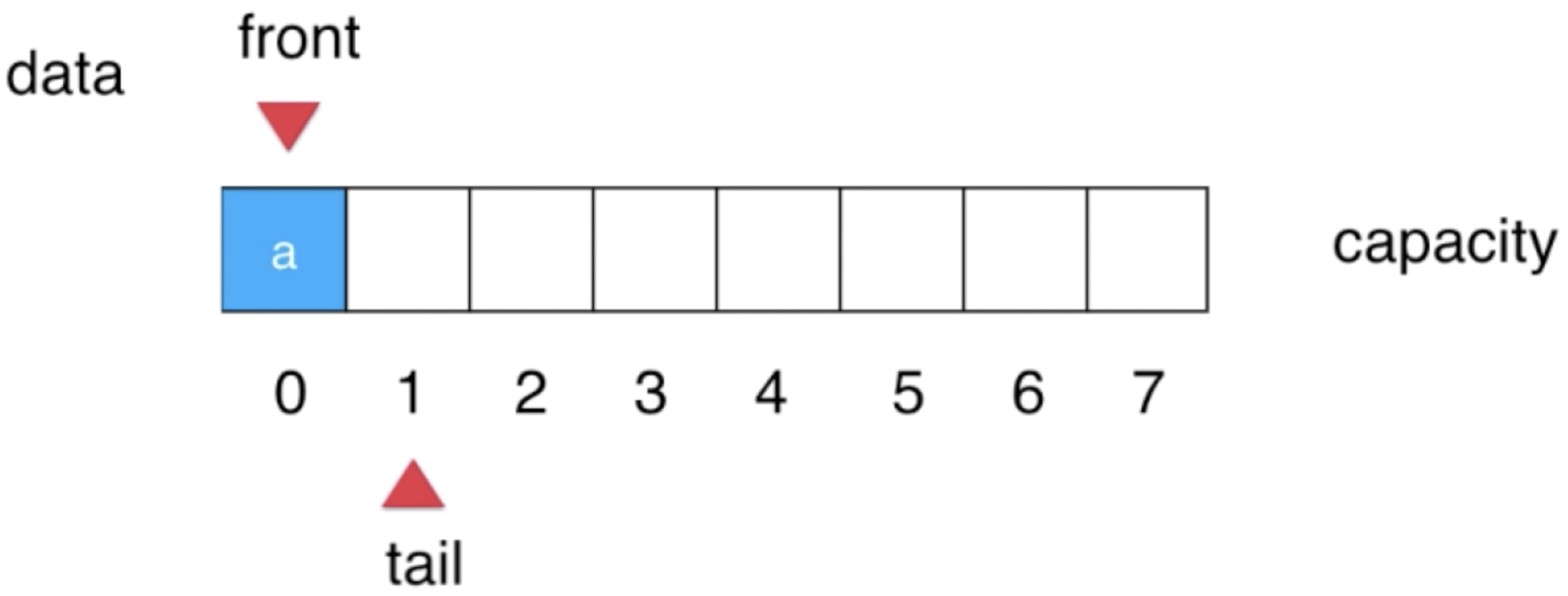
3、“b”入队:
接下来又队列一个元素,形态类似维护一下tail:
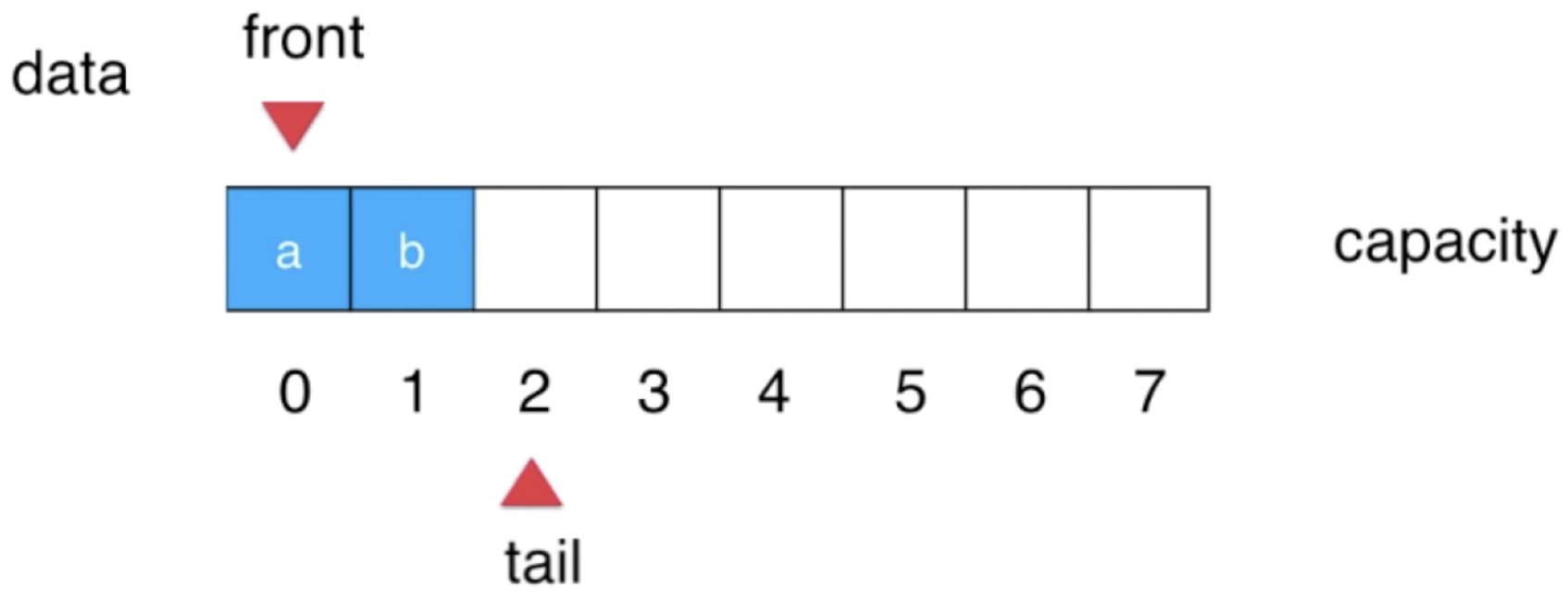
4、再入三个元素:
此时形态就为:
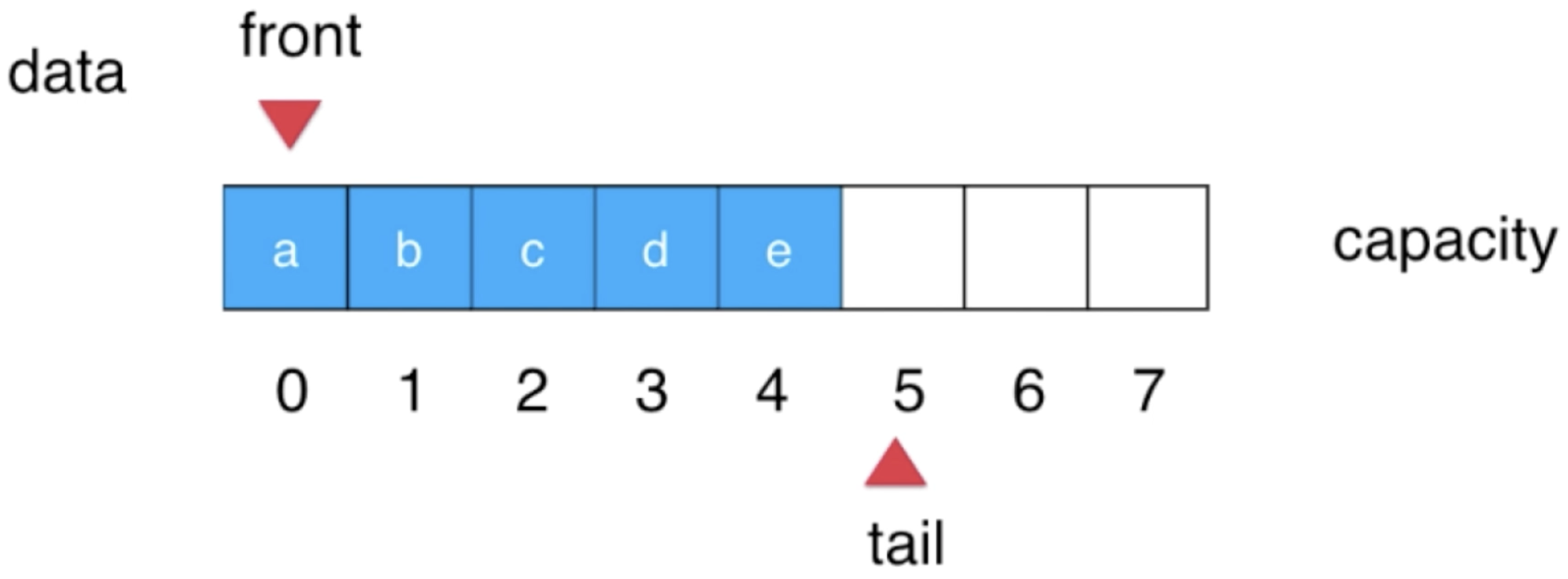
5、队首元素出队:
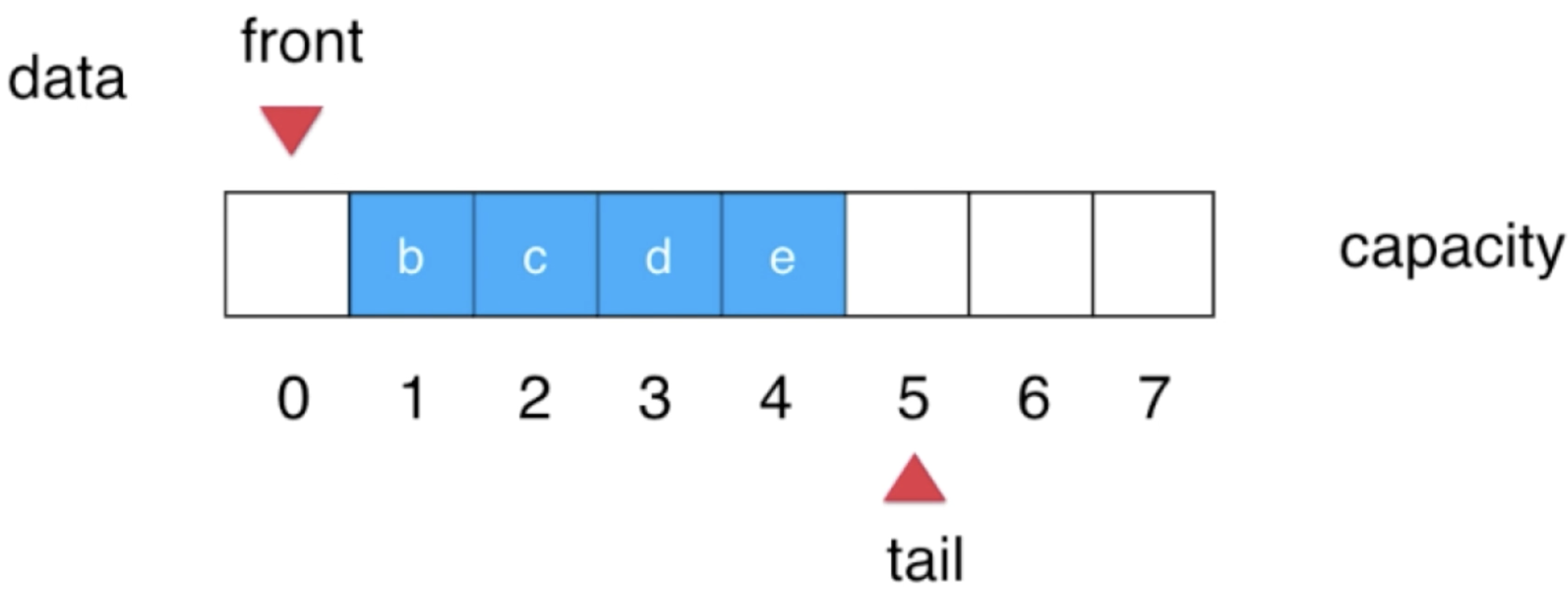
此时front需要维护一下:

此时就不需要将后面的所有元素进行挪动了,很显然复杂度由O(n)就变为了O(1)了。
6、 再出队首:
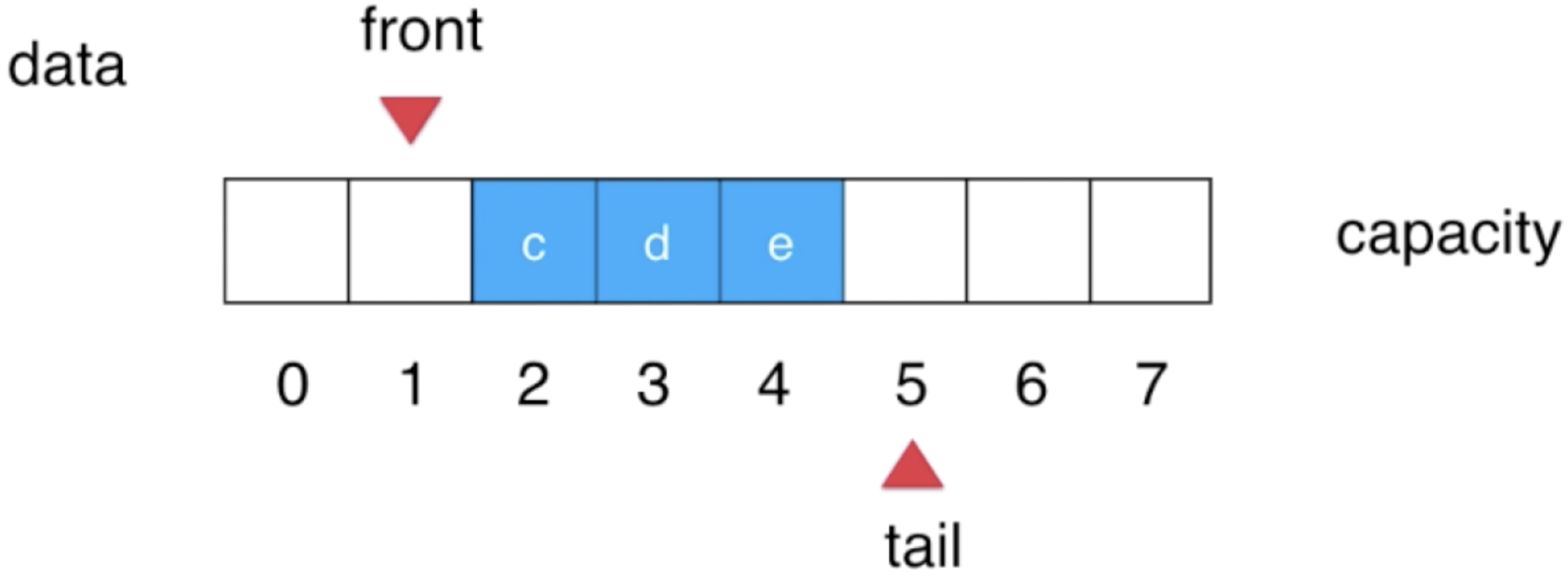
front++:
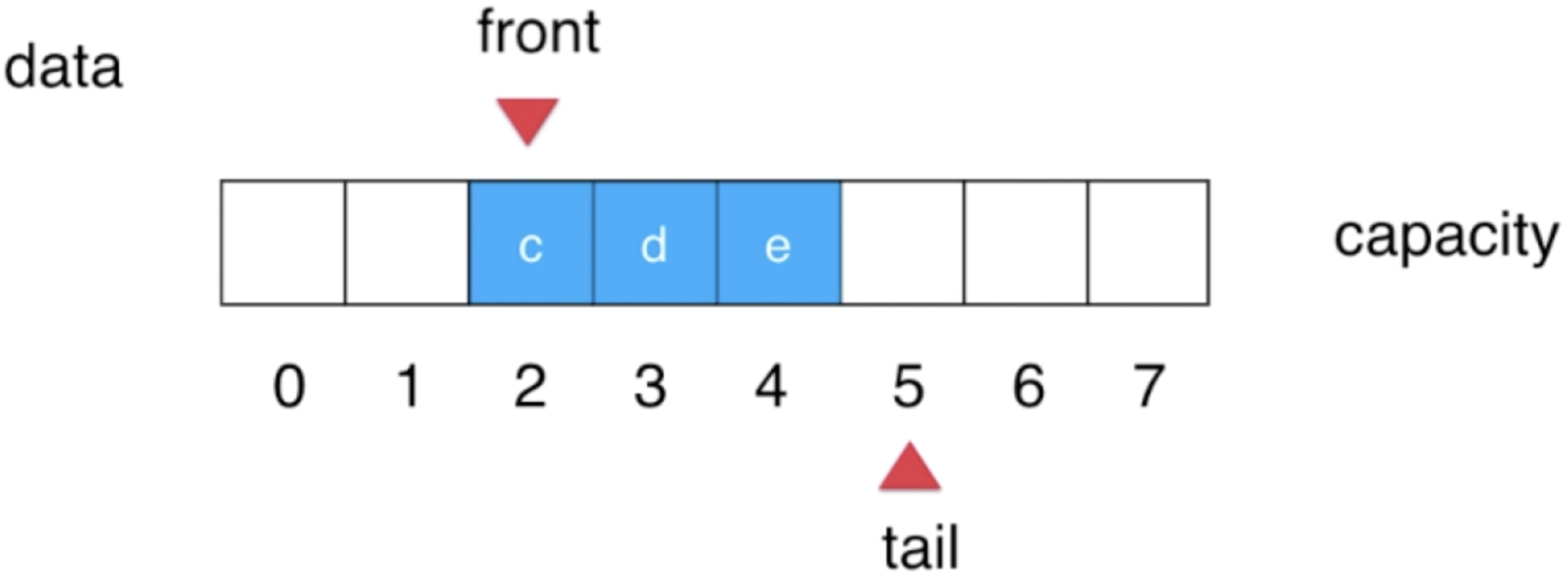
7、再入队2个元素【为啥叫循环队列的场景出现了】:
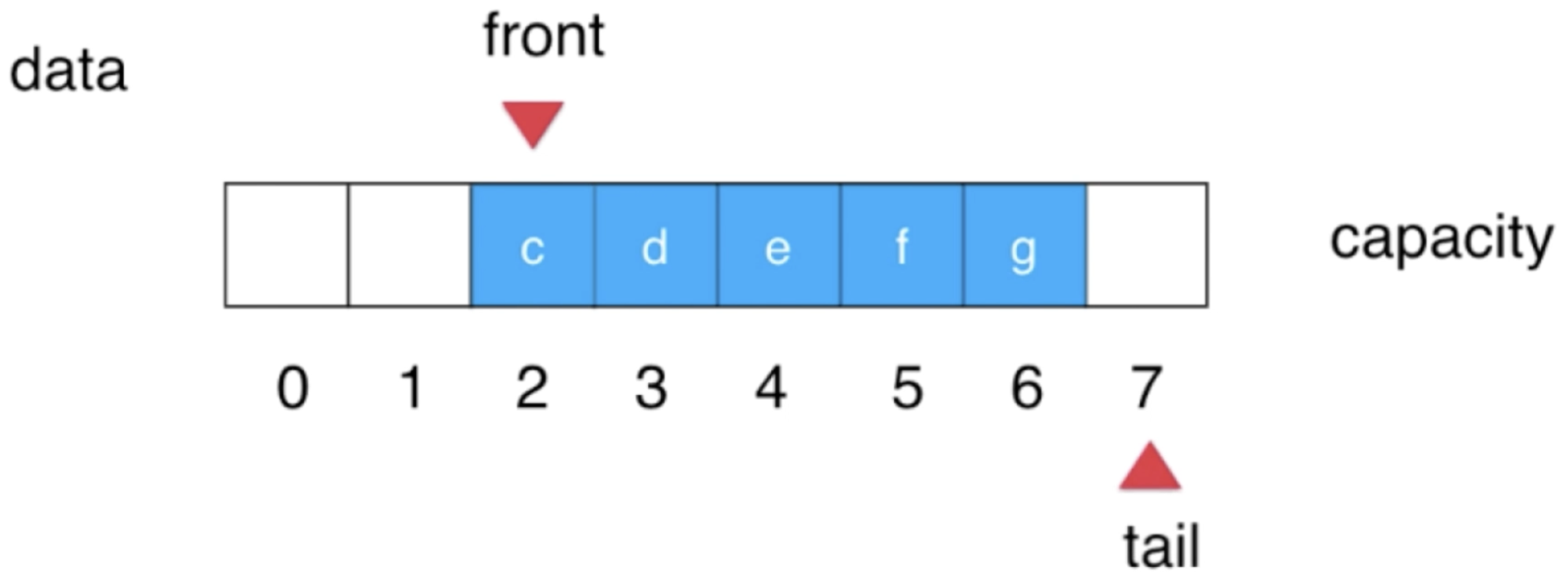
接下来再进来一个元素:
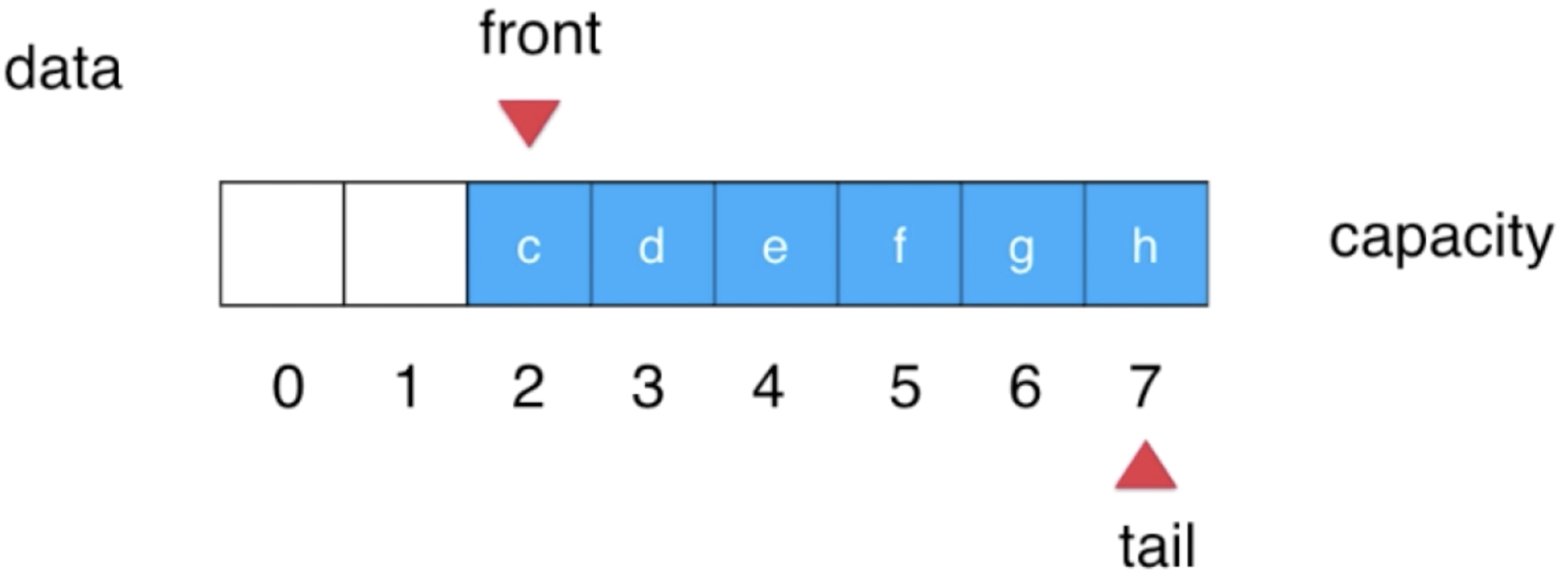
此时tail++就不能了,因为已经指向了数组的最后一个元素了再++就数组越界了,所以此时需要回到数组的开头进行元素插入了,此时tail就指向:
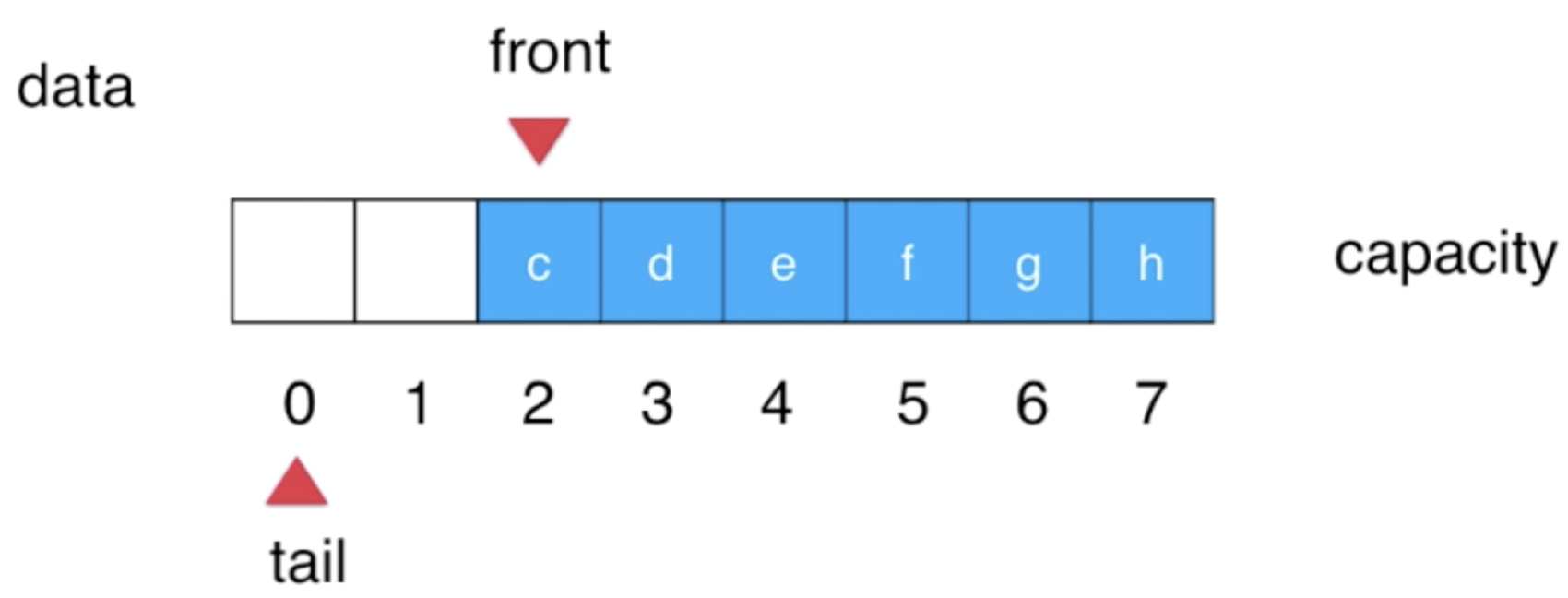
是不是整个数组就形成了一个环,也就是为啥叫循环队列了,很好理解,所以很显然对于tail的位置应该是(tail++ % size)。
8、再入队一个元素:
此时再队列元素就会在数组的开头了:
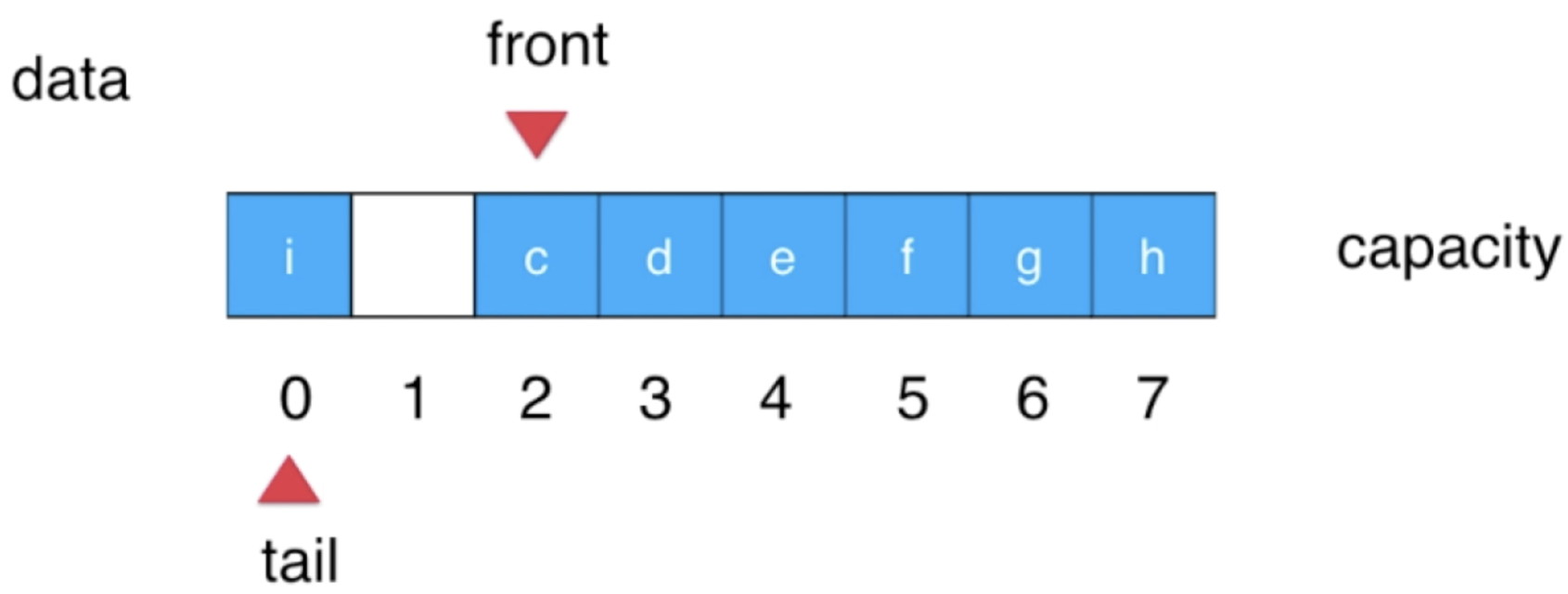
tail++:
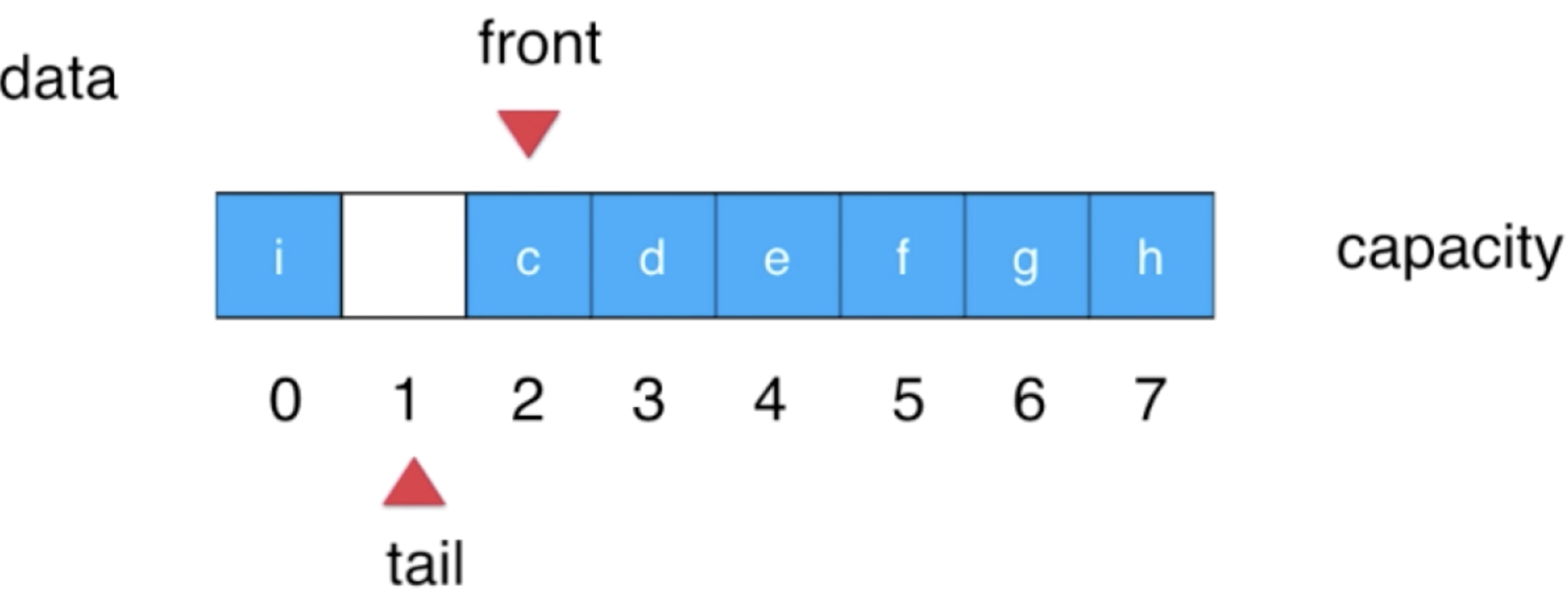
此时就要注意了,虽说数组中还剩一个空间,但是不能再往里增加元素了,为啥?还记得之前说的一个条件么?“front == tail表示队列为空”,如果此时再添加一个元素是不是tail++之后就满足此条件了?很明显队列是满的怎么可能是表示队列为空呢?
9、扩容情况:
所以一个新的条件咱们又可以定义了:“(tail + 1) % c = front则表示队列满”,当此条件满足时则capacity需要进行一个扩容了。
循环队列的实现:
1、新建文件:
public class LoopQueue<E> implements Queue<E> {
@Override
public int getSize() {
return 0;
}
@Override
public boolean isEmpty() {
return false;
}
@Override
public void enqueue(E e) {
}
@Override
public E dequeue() {
return null;
}
@Override
public E getFront() {
return null;
}
}
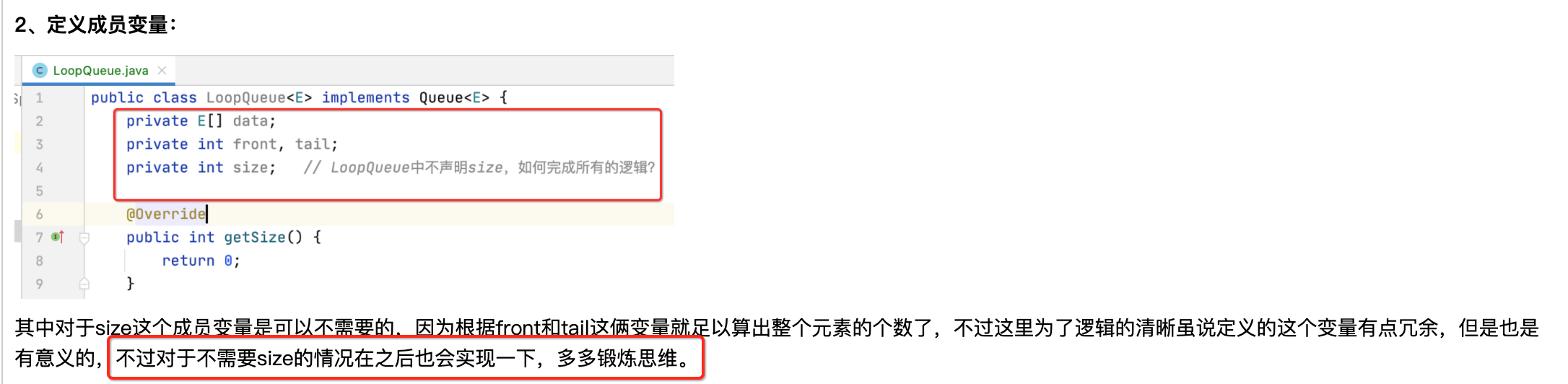
2、定义成员变量:
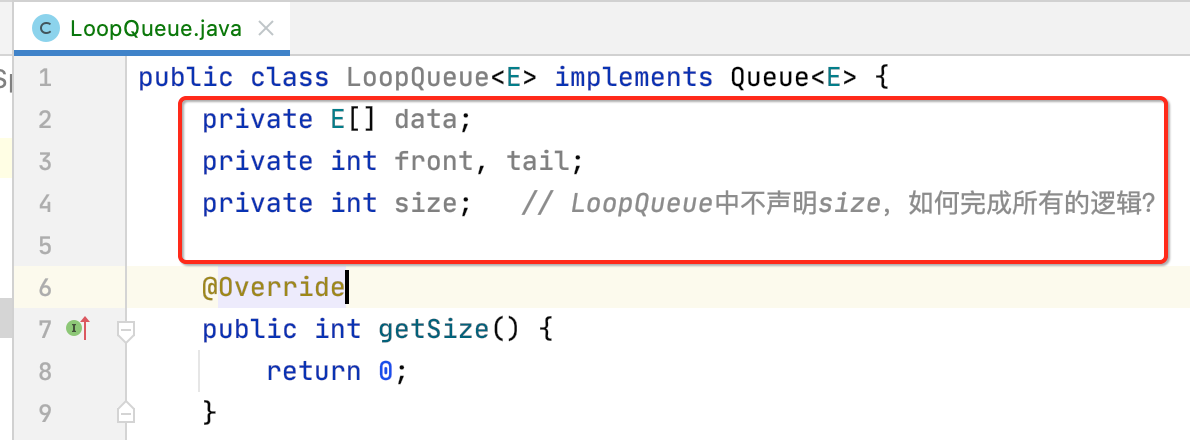
其中对于size这个成员变量是可以不需要的,因为根据front和tail这俩变量就足以算出整个元素的个数了,不过这里为了逻辑的清晰虽说定义的这个变量有点冗余,但是也是有意义的,不过对于不需要size的情况在之后也会实现一下,多多锻炼思维。
另外对于底部数组就没有用到咱们之前实现的Array了,因为已经满足不了循环队列的要求了,所以这里直接定义原生的数组。
3、定义构造:
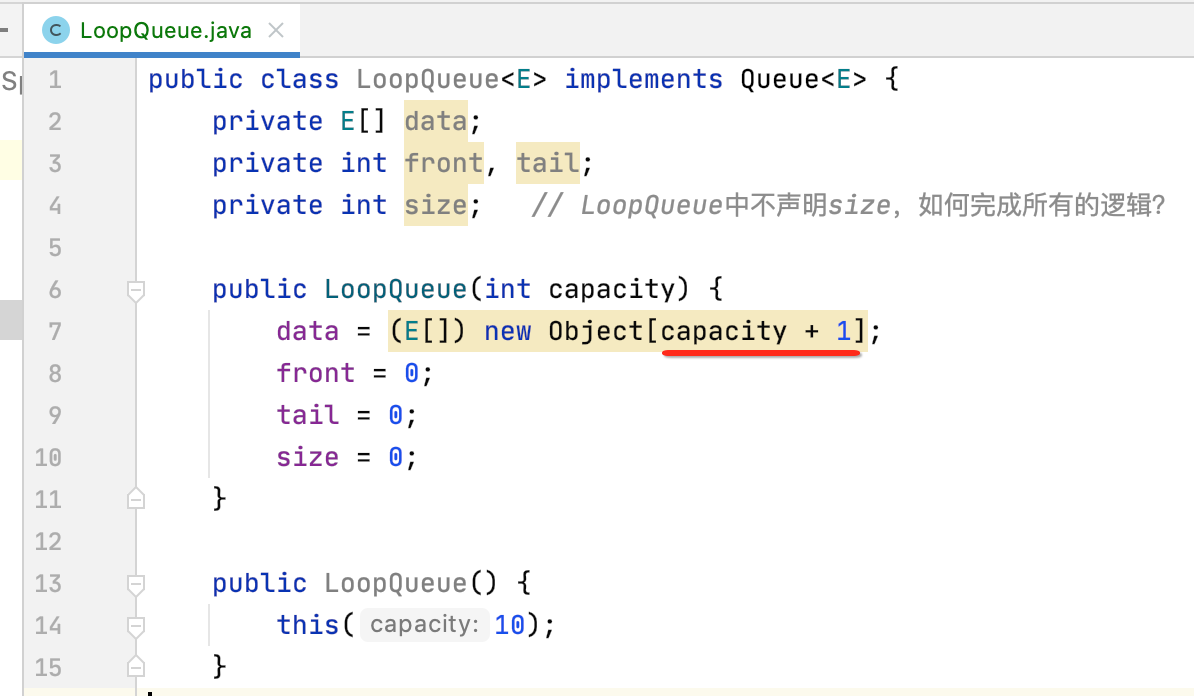
其中标红的为啥是+1呢?在上面理论描述循环队列过程时也能看出会有意的浪费一个空间,所以这也为啥是+1的原因了。
4、getCapacity():
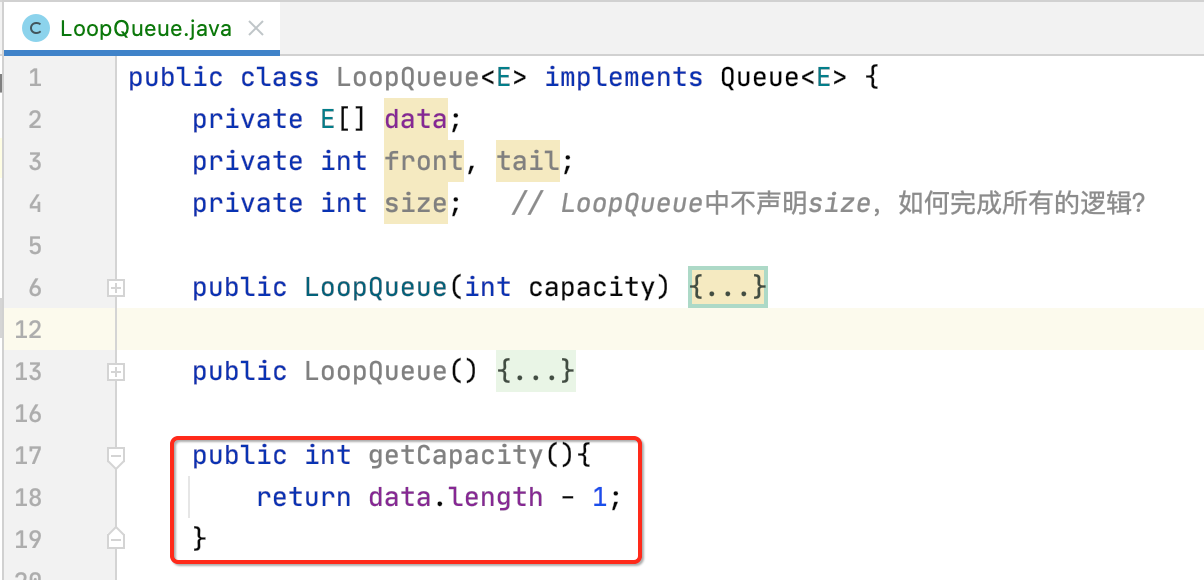
由于会浪费一个空间,所以同样的整个队列的容积大小需要减1。
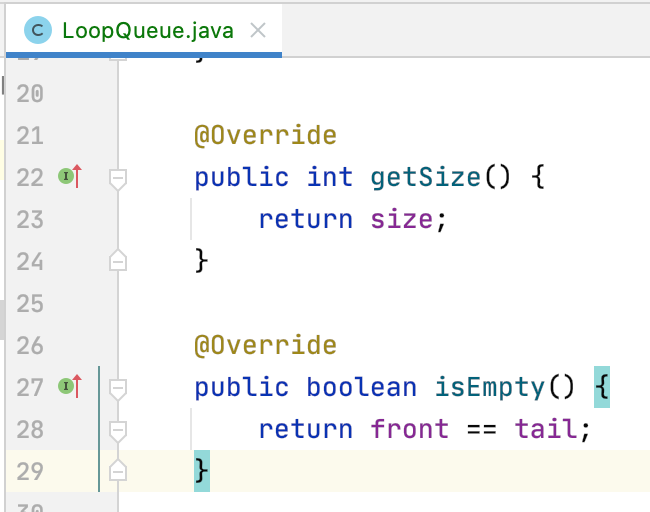
5、getSize()、isEmpty():
6、enqueue():
接下来先来实现一下入队,在入队时先判断一下空间是否满了,满了的话是需要进行扩容的:
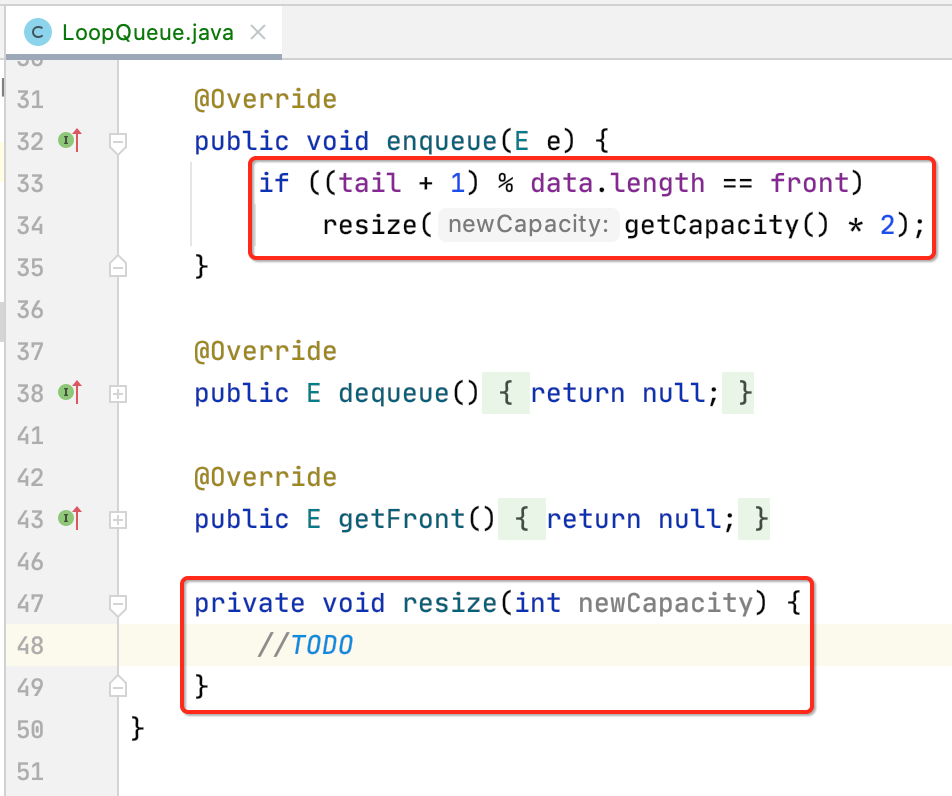
为啥是tail+1,如果不太清楚的可以回顾上面所理论描述循环队列的过程,接下来处理扩容的逻辑:
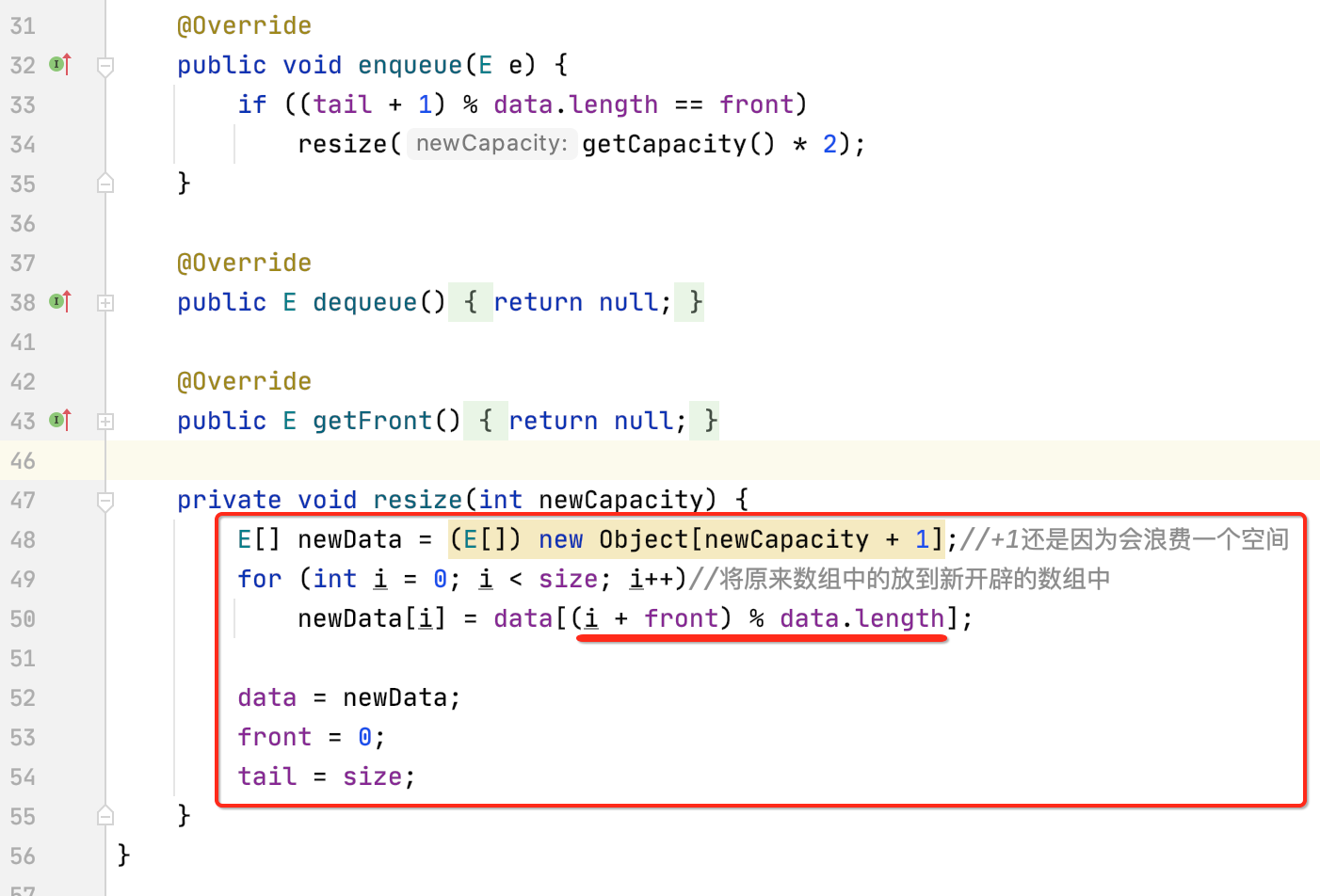
其中data[(i + front) % data.length]能否理解呢?这是因为data中的元素相比于newData的元素索引值是有一个front个偏移,另外还要考虑越界的情况,所以还需要“% data.length”了,当整个都赋值给newData之后,front和tail也需要重置一下,扩容之后肯定是完全能容纳之前数组元素的值了。
好,完成了扩容的处理之后,下面对于入队的操作就可以继续往下编写了:
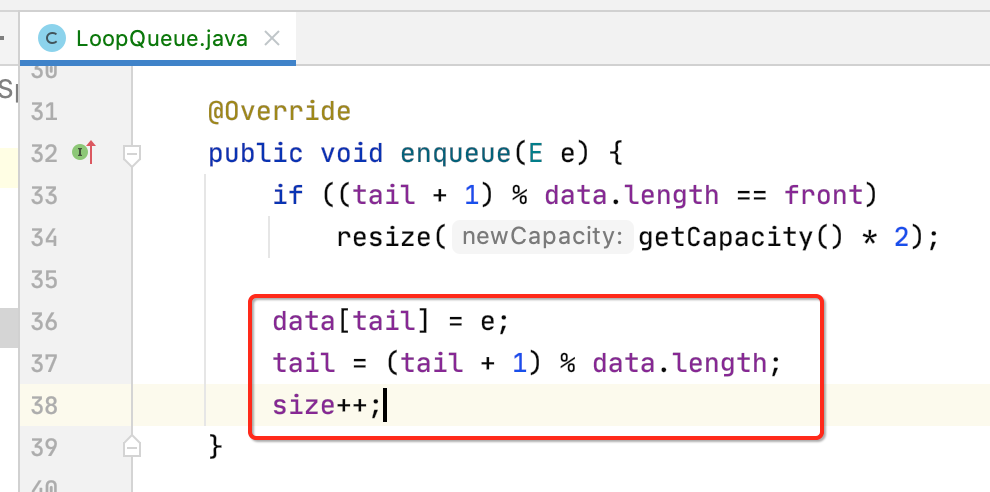
7、dequeue():
接下来处理出队,首先做一个容错:

接下来则弹出队首的元素并将其置空:

然后需要维护一下front引用:
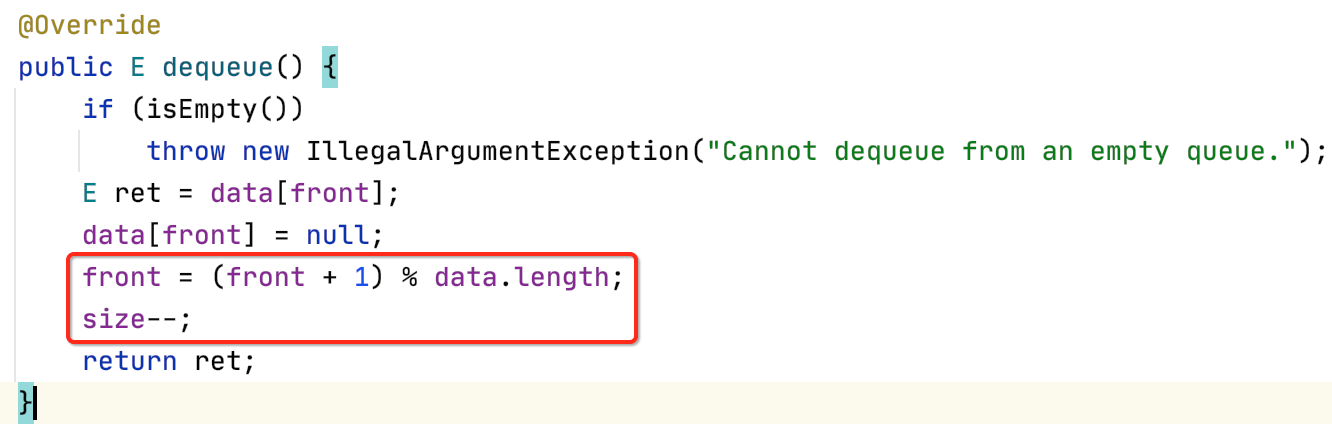
同动态数组一样,最后还得处理一下缩容的过程,如下:
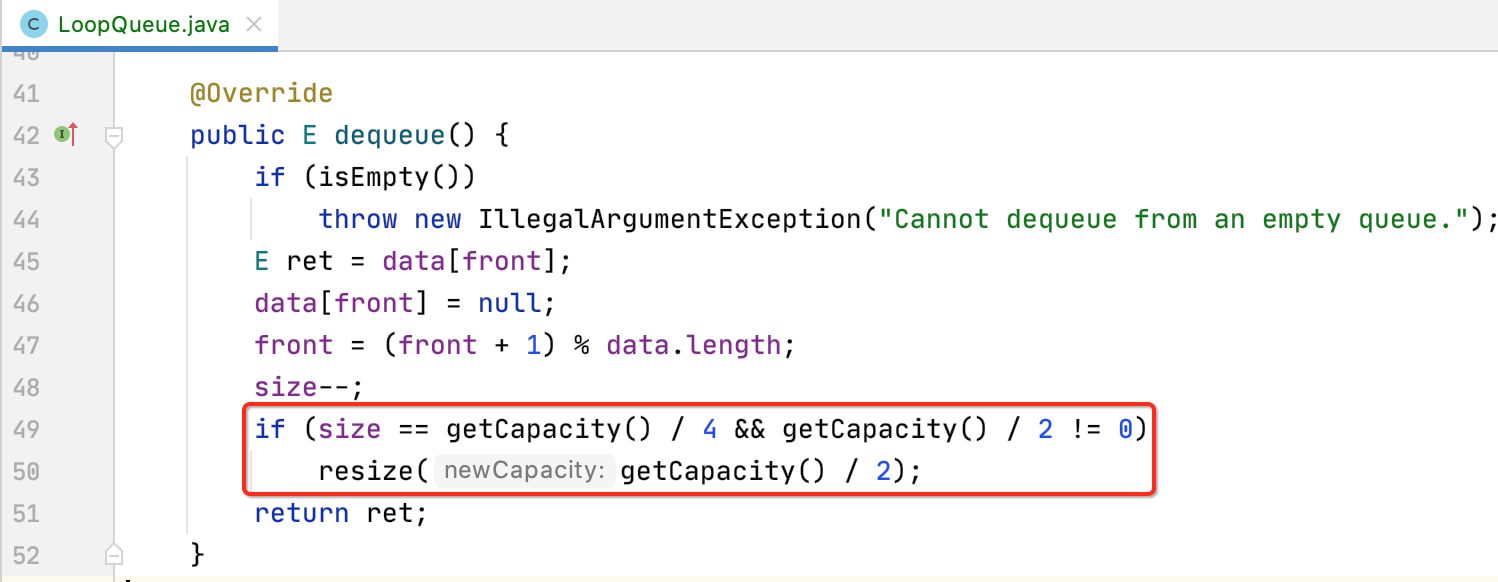
8、getFront():
@Override
public E getFront() {
if (isEmpty())
throw new IllegalArgumentException("Queue is empty.");
return data[front];
}
9、toString():
为了测试方便,重写一下toString():
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append(String.format("Queue: size = %d , capacity = %d\n", size, getCapacity()));
res.append("front [");
for (int i = front; i != tail; i = (i + 1) % data.length) {
res.append(data[i]);
if ((i + 1) % data.length != tail)//如果不是最后一个元素则以逗号分隔
res.append(", ");
}
res.append("] tail");
return res.toString();
}
其中这里使用了另一种队列元素的遍历方式了:

而在之前实现的resize()方法也使用到了遍历,回忆一下当时遍历的另一种写法:
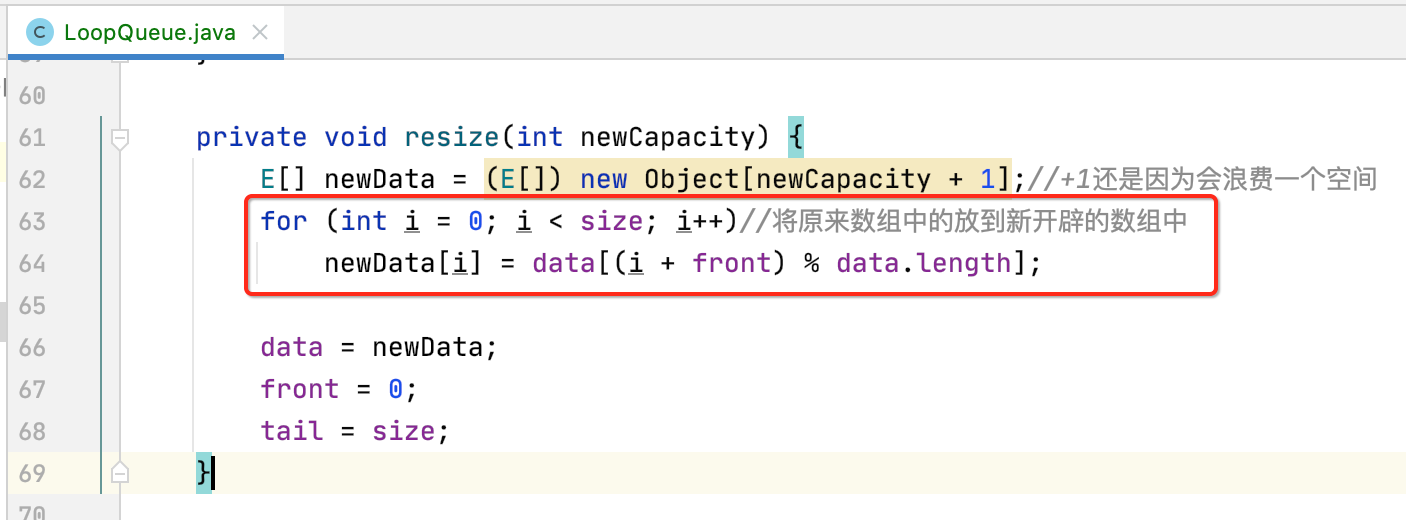
两者都是等价的,可以体会一下两种遍历方式的不同。
10、测试:
最后写个main()测试一下,这里直接将之前数组队列的测试用例拷过来:

稍加修改一下:
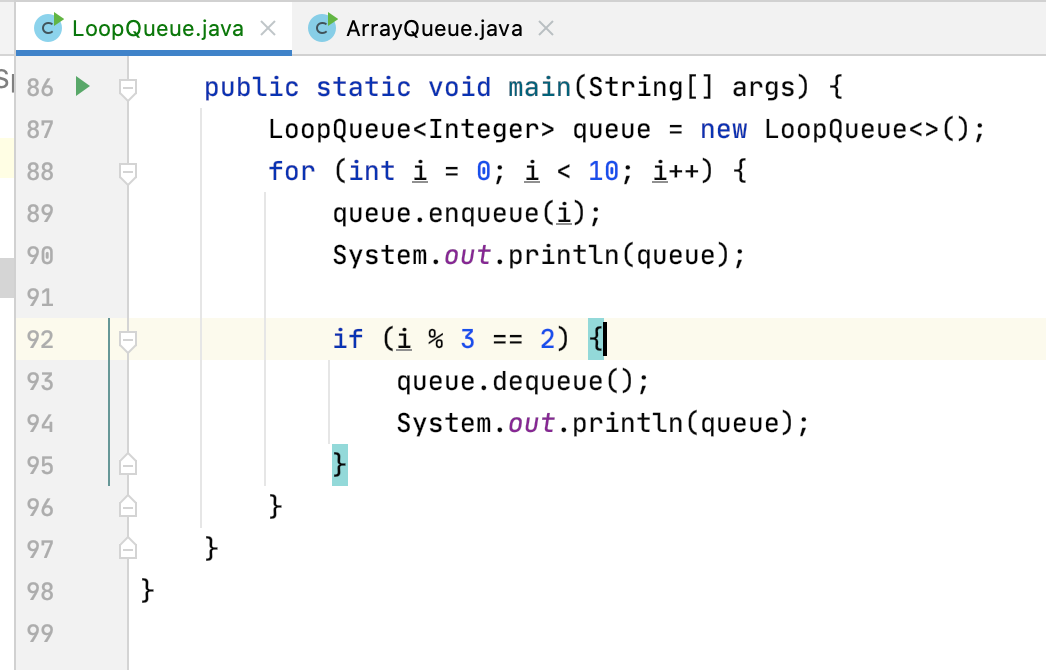
运行:
/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/bin/java -Dfile.encoding=UTF-8 -classpath /Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/charsets.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/deploy.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/cldrdata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/dnsns.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/jaccess.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/jfxrt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/localedata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/nashorn.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunec.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunjce_provider.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunpkcs11.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/zipfs.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/javaws.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jce.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jfr.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jfxswt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jsse.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/management-agent.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/plugin.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/resources.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/rt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/ant-javafx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/dt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/javafx-mx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/jconsole.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/packager.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/sa-jdi.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/tools.jar:/Users/xiongwei/Documents/workspace/IntelliJSpace/algorithm_system_sudy/Queue/out/production/Queue LoopQueue
Queue: size = 1 , capacity = 10
front [0] tail
Queue: size = 2 , capacity = 10
front [0, 1] tail
Queue: size = 3 , capacity = 10
front [0, 1, 2] tail
Queue: size = 2 , capacity = 5
front [1, 2] tail
Queue: size = 3 , capacity = 5
front [1, 2, 3] tail
Queue: size = 4 , capacity = 5
front [1, 2, 3, 4] tail
Queue: size = 5 , capacity = 5
front [1, 2, 3, 4, 5] tail
Queue: size = 4 , capacity = 5
front [2, 3, 4, 5] tail
Queue: size = 5 , capacity = 5
front [2, 3, 4, 5, 6] tail
Queue: size = 6 , capacity = 10
front [2, 3, 4, 5, 6, 7] tail
Queue: size = 7 , capacity = 10
front [2, 3, 4, 5, 6, 7, 8] tail
Queue: size = 6 , capacity = 10
front [3, 4, 5, 6, 7, 8] tail
Queue: size = 7 , capacity = 10
front [3, 4, 5, 6, 7, 8, 9] tail
Process finished with exit code 0
其输出都妥妥。
时间复杂度分析:

这就通过循环队列将出队操作由O(n)变成了O(1)了,其中依然会涉及到均摊复杂度,因为在出队过程中也有可能会触发缩容操作的。最后贴一下整个特环队列的代码:
public class LoopQueue<E> implements Queue<E> {
private E[] data;
private int front, tail;
private int size; // LoopQueue中不声明size,如何完成所有的逻辑?
public LoopQueue(int capacity) {
data = (E[]) new Object[capacity + 1];
front = 0;
tail = 0;
size = 0;
}
public LoopQueue() {
this(10);
}
public int getCapacity() {
return data.length - 1;
}
@Override
public int getSize() {
return size;
}
@Override
public boolean isEmpty() {
return front == tail;
}
@Override
public void enqueue(E e) {
if ((tail + 1) % data.length == front)
resize(getCapacity() * 2);
data[tail] = e;
tail = (tail + 1) % data.length;
size++;
}
@Override
public E dequeue() {
if (isEmpty())
throw new IllegalArgumentException("Cannot dequeue from an empty queue.");
E ret = data[front];
data[front] = null;
front = (front + 1) % data.length;
size--;
if (size == getCapacity() / 4 && getCapacity() / 2 != 0)
resize(getCapacity() / 2);
return ret;
}
@Override
public E getFront() {
if (isEmpty())
throw new IllegalArgumentException("Queue is empty.");
return data[front];
}
private void resize(int newCapacity) {
E[] newData = (E[]) new Object[newCapacity + 1];//+1还是因为会浪费一个空间
for (int i = 0; i < size; i++)//将原来数组中的放到新开辟的数组中
newData[i] = data[(i + front) % data.length];
data = newData;
front = 0;
tail = size;
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append(String.format("Queue: size = %d , capacity = %d\n", size, getCapacity()));
res.append("front [");
for (int i = front; i != tail; i = (i + 1) % data.length) {
res.append(data[i]);
if ((i + 1) % data.length != tail)//如果不是最后一个元素则以逗号分隔
res.append(", ");
}
res.append("] tail");
return res.toString();
}
public static void main(String[] args) {
LoopQueue<Integer> queue = new LoopQueue<>();
for (int i = 0; i < 10; i++) {
queue.enqueue(i);
System.out.println(queue);
if (i % 3 == 2) {
queue.dequeue();
System.out.println(queue);
}
}
}
}
数组队列和循环队列的比较:
这里回想一下,初次咱们实现了一个数组队列,但是呢它有出队操作性能不太好,于是乎又实现了循环队列来对这个出队的性能进行了一个质的飞跃,那么在算法或数据结构领域永远在追求一个更优的方式来实现其背后的意义又在哪呢?下面以一个具体的测试数据来回答这个意义。
然后里面先定义测试两者性能的代码:
public class Main {
// 测试使用q运行opCount个enqueueu和dequeue操作所需要的时间,单位:秒
private static double testQueue(Queue<Integer> q, int opCount) {
long startTime = System.nanoTime();
//TODO...
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
public static void main(String[] args) {
int opCount = 100000;
ArrayQueue<Integer> arrayQueue = new ArrayQueue<>();
double time1 = testQueue(arrayQueue, opCount);
System.out.println("ArrayQueue, time: " + time1 + " s");
LoopQueue<Integer> loopQueue = new LoopQueue<>();
double time2 = testQueue(loopQueue, opCount);
System.out.println("LoopQueue, time: " + time2 + " s");
}
}
测10万的数据,然后具体测试方法就是对这10万个数据进行入队与出队,如下:
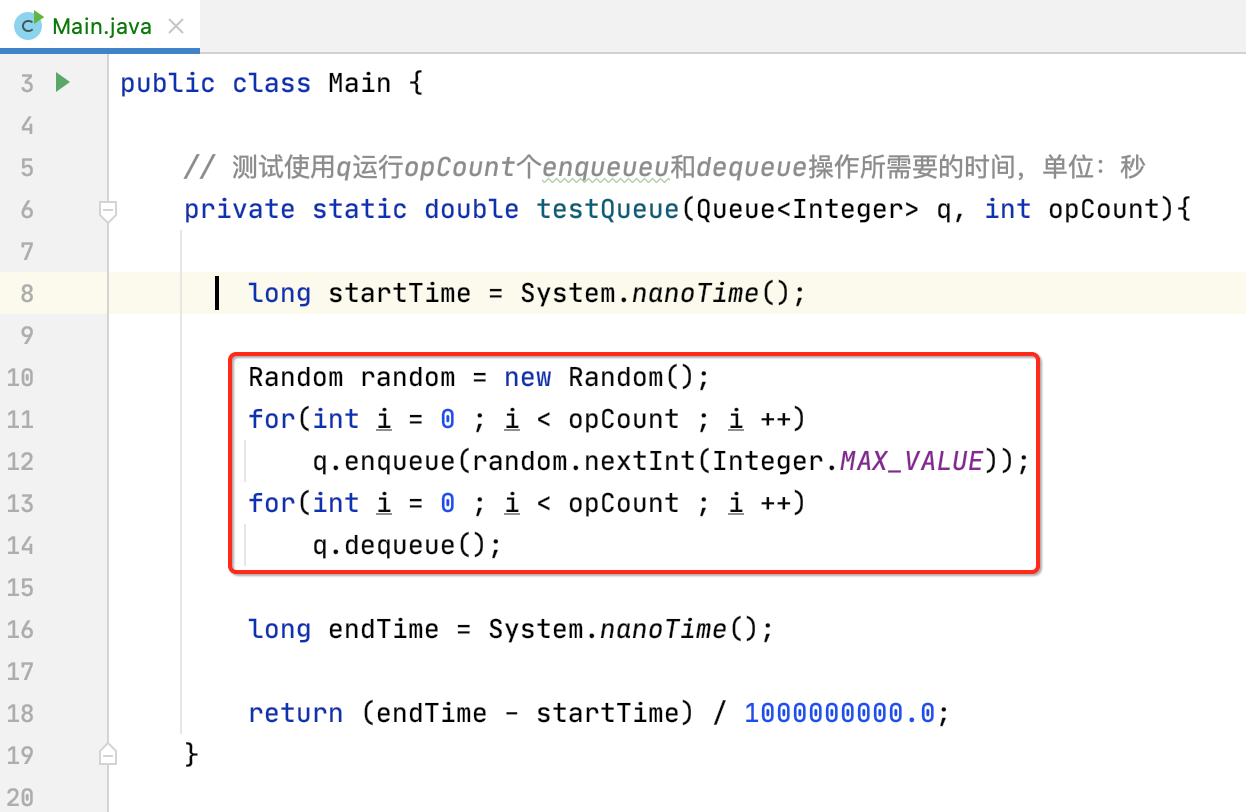
下面来运行一下:
/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/bin/java -Dfile.encoding=UTF-8 -classpath /Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/charsets.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/deploy.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/cldrdata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/dnsns.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/jaccess.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/jfxrt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/localedata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/nashorn.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunec.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunjce_provider.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/sunpkcs11.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/ext/zipfs.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/javaws.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jce.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jfr.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jfxswt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/jsse.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/management-agent.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/plugin.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/resources.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/jre/lib/rt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/ant-javafx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/dt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/javafx-mx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/jconsole.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/packager.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/sa-jdi.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_251.jdk/Contents/Home/lib/tools.jar:/Users/xiongwei/Documents/workspace/IntelliJSpace/algorithm_system_sudy/Queue/out/production/Queue Main
ArrayQueue, time: 4.480805875 s
LoopQueue, time: 0.018219318 s
Process finished with exit code 0
是不是非常直观地能感受到两者的性能差异,其实主要是差异就是在出队上面,这也是要追求最优算法的真正的意义,能直接决定程序的性能。
换个方式实现循环队列?
为了进一步强化对于队列的理解,下面以两个全新的视角来改造一下咱们的循环队列。
不浪费一个空间实现队列:
还记得咱们在实现时是故意浪费一个空间了么?回忆一下:
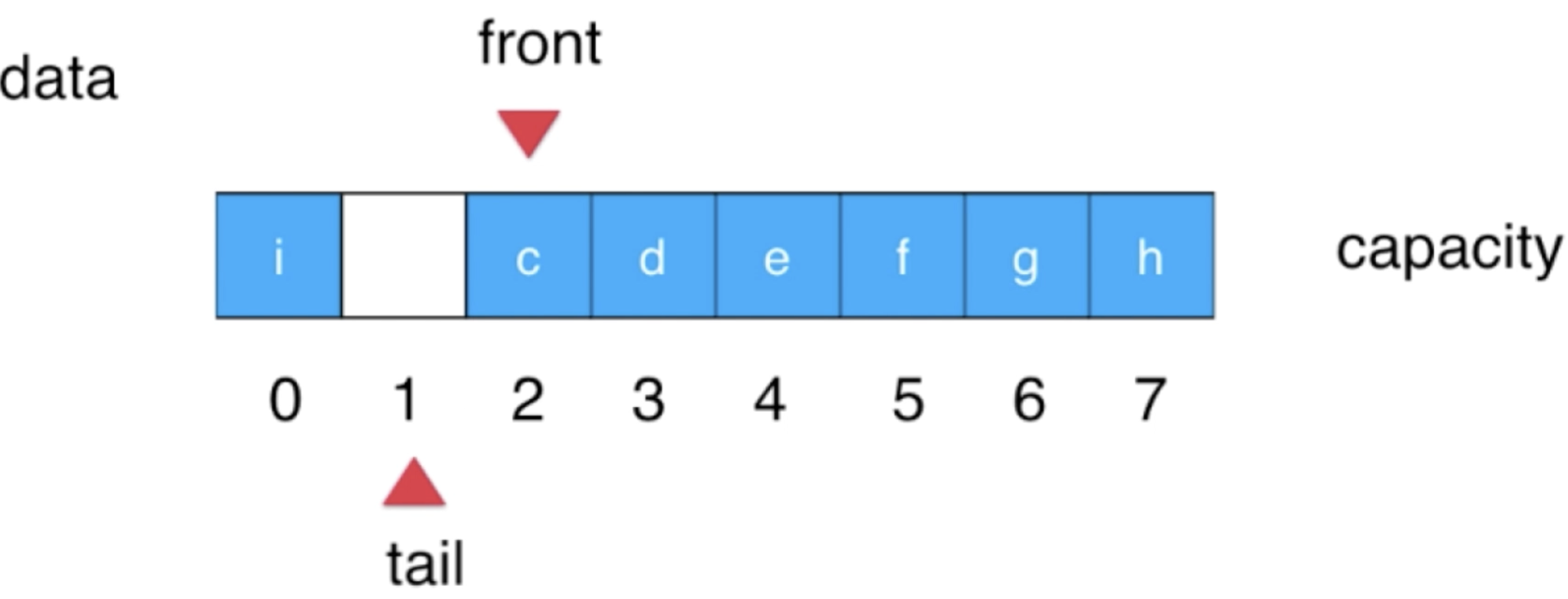
其实此空间也可以不浪费,下面将这种实现方式贴出来,也比较简单:
// 在这一版LoopQueue的实现中,我们将不浪费那1个空间
public class LoopQueue2<E> implements Queue<E> {
private E[] data;
private int front, tail;
private int size;
public LoopQueue2(int capacity) {
data = (E[]) new Object[capacity]; // 由于不浪费空间,所以data静态数组的大小是capacity,而不是capacity + 1
front = 0;
tail = 0;
size = 0;
}
public LoopQueue2() {
this(10);
}
public int getCapacity() {
return data.length;
}
@Override
public boolean isEmpty() {
// 注意,我们不再使用front和tail之间的关系来判断队列是否为空,而直接使用size
return size == 0;
}
@Override
public int getSize() {
return size;
}
@Override
public void enqueue(E e) {
// 注意,我们不再使用front和tail之间的关系来判断队列是否为满,而直接使用size
if (size == getCapacity())
resize(getCapacity() * 2);
data[tail] = e;
tail = (tail + 1) % data.length;
size++;
}
@Override
public E dequeue() {
if (isEmpty())
throw new IllegalArgumentException("Cannot dequeue from an empty queue.");
E ret = data[front];
data[front] = null;
front = (front + 1) % data.length;
size--;
if (size == getCapacity() / 4 && getCapacity() / 2 != 0)
resize(getCapacity() / 2);
return ret;
}
@Override
public E getFront() {
if (isEmpty())
throw new IllegalArgumentException("Queue is empty.");
return data[front];
}
private void resize(int newCapacity) {
E[] newData = (E[]) new Object[newCapacity];
for (int i = 0; i < size; i++)
newData[i] = data[(i + front) % data.length];
data = newData;
front = 0;
tail = size;
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append(String.format("Queue: size = %d , capacity = %d\n", size, getCapacity()));
res.append("front [");
// 注意,我们的循环遍历打印队列的逻辑也有相应的更改
for (int i = 0; i < size; i++) {
res.append(data[(front + i) % data.length]);
if ((i + front + 1) % data.length != tail)
res.append(", ");
}
res.append("] tail");
return res.toString();
}
public static void main(String[] args) {
LoopQueue<Integer> queue = new LoopQueue<>();
for (int i = 0; i < 10; i++) {
queue.enqueue(i);
System.out.println(queue);
if (i % 3 == 2) {
queue.dequeue();
System.out.println(queue);
}
}
}
}
其中有变化的都标有注释,不过多解释了,一看就能明白。
浪费一个空间,但不使用 size 实现队列:
如上面也提到过,在实现循环队列时:
定义了一个size变量来表示队列元素的个数,其实根据front和tail就足以算出元素个数了, 所以接下来不定义size这个变量也同样数组浪费一个空间看整个循环队列的实现又会如何?同样代码贴出来,也比较容易:
// 在这一版本的实现中,我们完全不使用size,只使用front和tail来完成LoopQueue的所有逻辑
public class LoopQueue3<E> implements Queue<E> {
private E[] data;
private int front, tail;
public LoopQueue3(int capacity) {
data = (E[]) new Object[capacity + 1];
front = 0;
tail = 0;
}
public LoopQueue3() {
this(10);
}
public int getCapacity() {
return data.length - 1;
}
@Override
public boolean isEmpty() {
return front == tail;
}
@Override
public int getSize() {
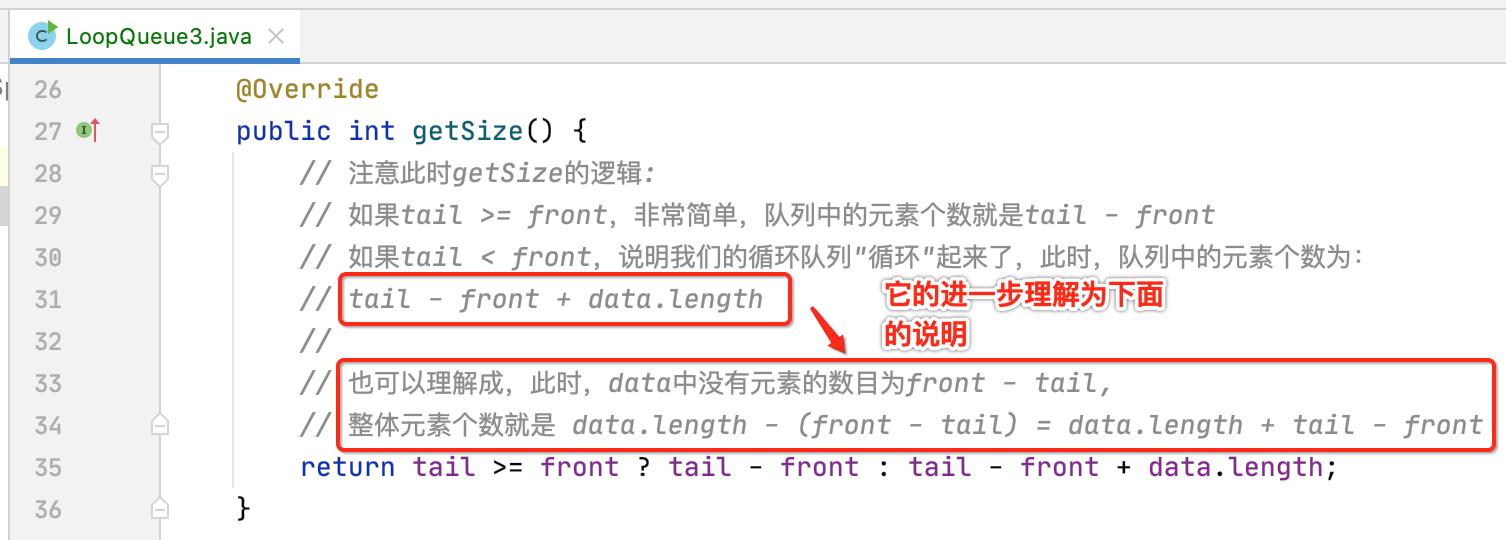
// 注意此时getSize的逻辑:
// 如果tail >= front,非常简单,队列中的元素个数就是tail - front
// 如果tail < front,说明我们的循环队列"循环"起来了,此时,队列中的元素个数为:
// tail - front + data.length
//
// 也可以理解成,此时,data中没有元素的数目为front - tail,
// 整体元素个数就是 data.length - (front - tail) = data.length + tail - front
return tail >= front ? tail - front : tail - front + data.length;
}
@Override
public void enqueue(E e) {
if ((tail + 1) % data.length == front)
resize(getCapacity() * 2);
data[tail] = e;
tail = (tail + 1) % data.length;
}
@Override
public E dequeue() {
if (isEmpty())
throw new IllegalArgumentException("Cannot dequeue from an empty queue.");
E ret = data[front];
data[front] = null;
front = (front + 1) % data.length;
if (getSize() == getCapacity() / 4 && getCapacity() / 2 != 0)
resize(getCapacity() / 2);
return ret;
}
@Override
public E getFront() {
if (isEmpty())
throw new IllegalArgumentException("Queue is empty.");
return data[front];
}
private void resize(int newCapacity) {
E[] newData = (E[]) new Object[newCapacity + 1];
int sz = getSize();
for (int i = 0; i < sz; i++)
newData[i] = data[(i + front) % data.length];
data = newData;
front = 0;
tail = sz;
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append(String.format("Queue: size = %d , capacity = %d\n", getSize(), getCapacity()));
res.append("front [");
for (int i = front; i != tail; i = (i + 1) % data.length) {
res.append(data[i]);
if ((i + 1) % data.length != tail)
res.append(", ");
}
res.append("] tail");
return res.toString();
}
public static void main(String[] args) {
LoopQueue<Integer> queue = new LoopQueue<>();
for (int i = 0; i < 10; i++) {
queue.enqueue(i);
System.out.println(queue);
if (i % 3 == 2) {
queue.dequeue();
System.out.println(queue);
}
}
}
}
其中有一个地方理解稍稍麻烦一点,就是如何根据front和tail来获取元数个数:
也就是用整个数组的个数减去data中木有无数的数目既为整个队列的个数,而对于data中没有元素的数目的计算看这个图就能理解:
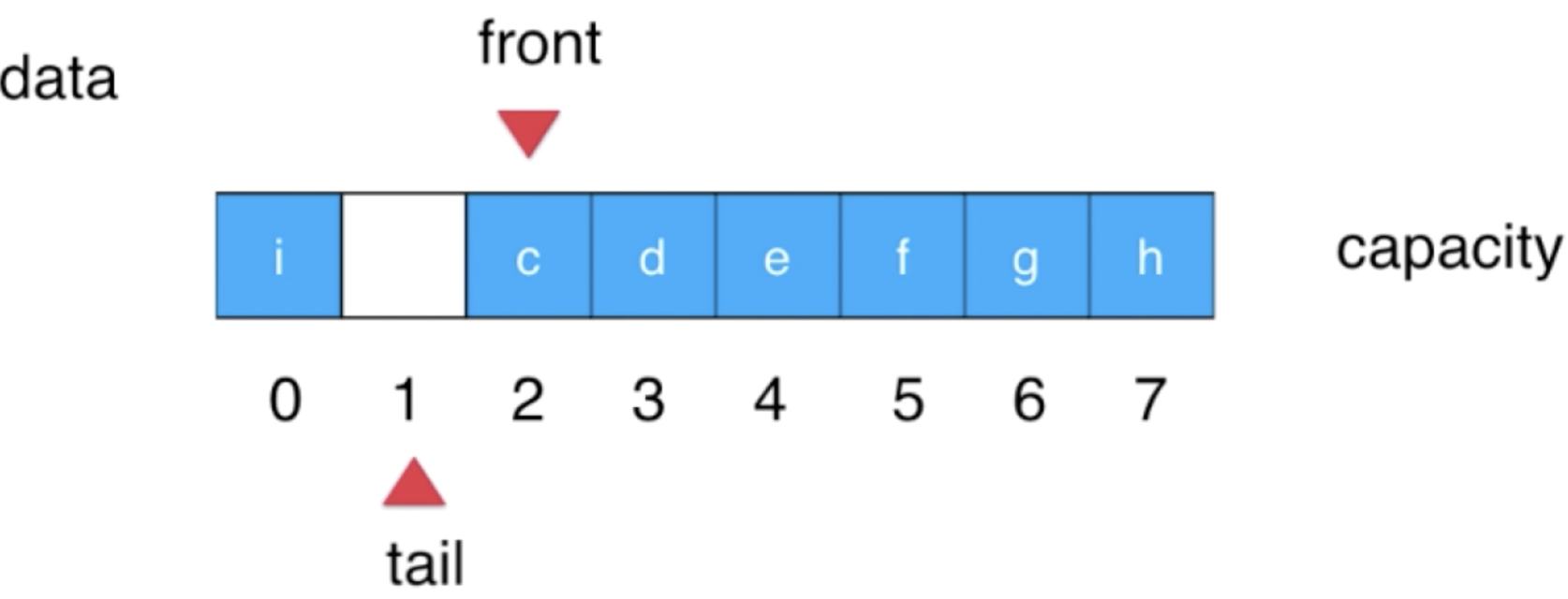
图中还剩一个空间是空的,这1个空间就可以用front-tail=1,所以这也是为啥上面的实现是这样的原因了。
















 4744
4744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











