







首先我们要了解Python爬虫四步走
- 第一步:尝试请求
- 第二步:解析页面
- 第三步:提取内容
- 第三步:数据保存
本文介绍了使用Python实现网易云音乐爬虫的四个关键步骤:请求网页、解析页面、提取内容和数据保存。通过requests库发送网络请求,lxml库解析HTML并提取音乐ID和名称,最后将音乐文件保存至本地。教程包含了完整的代码实现,包括请求头设置、XPath数据提取和文件存储操作,适合具备Python基础环境的开发者学习网络爬虫技术。运行后可自动下载指定榜单的音乐文件到本地"网易云音乐"文件夹。
下面我们直接看代码:
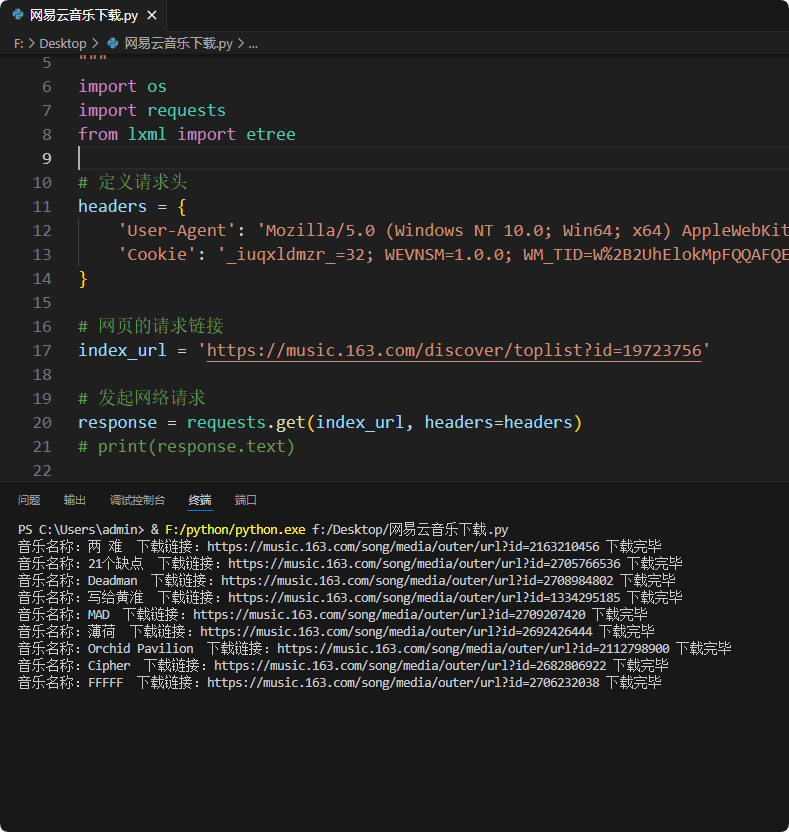
"""
前情提示:此视频教程需在正确安装 Python 环境的和一些库情况下才能正常进行程序代码;
如果没有安装好python解释器和pycharm编辑器的同学,文末的名片微信下载;
或者也可以直接私信找我领取。
"""
import os
import requests
from lxml import etree
# 定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36',
'Cookie': '_iuqxldmzr_=32; WEVNSM=1.0.0; WM_TID=W%2B2UhElokMpFQQAFQELUn9wfjRvH6lk%2B; ntes_utid=tid._.46j7nkoJT0FBQhVQVVbFy9gKzA7Wv0pn._.0; NMTID=00ObVYRGkNufmW7gkdKldpTc7slEQoAAAGMluRQ0A; _ntes_nnid=0db8a97a3f0ccb5f24f4d668f5fc9f42,1703338595424; _ntes_nuid=0db8a97a3f0ccb5f24f4d668f5fc9f42; WNMCID=eytpiz.1703338596196.01.0; sDeviceId=YD-J79E4izoh3JBRlRUEUeAnu3PISufEQFA; __snaker__id=qWAOQ7SI238ClQ0v; timing_user_id=time_1ooVj6i8Xt; _ga=GA1.1.255450216.1715757340; _clck=5yrj01%7C2%7Cfls%7C0%7C1596; Qs_lvt_382223=1715757340%2C1715761090; Qs_pv_382223=2766425085168803300%2C594513287698168400%2C1241654787482157800%2C2606747499782075000%2C244661778963075800; _clsk=hpfjx8%7C1715761175285%7C9%7C1%7Cw.clarity.ms%2Fcollect; _ga_C6TGHFPQ1H=GS1.1.1715761090.2.1.1715761199.0.0.0; JSESSIONID-WYYY=y0ABc%2FWDVPyq9feqhGujNzhnIm9etDgDQx3%2FsjjVuzhx7Ep3Yc8zfzQTapRWc9qUEDz02Dp7aUHbTMQhgg0bBbrgcZjgDvTt8sPE1WmGClFjMRhEqFU%2F6stdkwesTd4liIh1vGW%5CcKnDSt%2FiPeu5xh4%2BlTiFAu0dZ3WYUwYSrjHz6w4C%3A1715763341403; WM_NI=tHWlJUP9dRo5JL66XiOxoBKk3pxkSmZ8%2BAPrKs7pQMSbBgTVympu%2FYSNzktZ0NfTEpJhsjtJcNb2itrdhHAI%2Fjn%2BrXSiiIBqTj9mxo%2FIv9CLyTuy9Q7xiW%2FKQUUngpPcd1U%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eedad56b93bffed1bb4d85928ab2d14b929f9eacc53ebaaaaf84ee7e8399f9aaf42af0fea7c3b92ab898998dc95f94e7acb3ee3f8a94fad7db638da8a1a3ca61f1b0b88cd2679ae8e5a2d37a89adf991d44791be8e88d75ebbb3c096ae539192b68cf752f492aab5c87c8ab8bd8bf742a192aed3ec80b2bca8a9c443edb6a2ccf15491b7a7aac17b98b6f78efb65ed97badac248bb8cbb9abc5bf5a8a7b8ae41938b9b8fe67c94bdacd2d837e2a3; gdxidpyhxdE=HGDxKqxX53b%2FpfjhkhO%2F039bdlPlNxAGP9U%2FRilo21PMy3VGcjgE67J3QfldXnJy1MjT96OyDYC7Y9ne%2BB1H%5CHghDfqDnWCQffdDbeyL9VUfe28SZlcsTOxhgz0huKPf%2FpAmGJu7y%5Cek4p%5CazSeVAfRCpWXuk8O%5CCJc%5CiAeGnUqRU0Po%3A1715762446400; MUSIC_U=0070F7FB3516B3C7962CB13761CAA7A3F290A58EBBBB7A947821BA2DBD6E887574238763D2864A59B9A31FEB8F549F8CC6FB3F10F14865EC74138C00766E3EE29FF6C33EBCA80259D3B2B93386E223DF8AB137F93257419E53771DD45E0AC3665711C4C7781CD09F74F298CC9D57956027769C8CC1C850CCCCEC685BB5883A8C8D56B12D974CED6DDAA7778D75586109432BCC901AFF00C414A1301CBCB1951C99842DA5D278A093C609670573DF41B7A0334061B7BA350982CDBDF459C1982EC04D90339A39C000CE97C58D788CD63A48E4ACDFE605868BA77D0F0536C4289E3CD38078F88589BD15D3DC27F2EEAB60B60E604CD96D4DF41AD596A9685D466DAD37181D740CCC71A9A1E0365D84DB9111E78FAC9907BE7C0C30FA594B893ED560D3E4058F46C6219EB02AE27C7C6D5724D6ECD77E8533E10BA2188801FF5269AD1E8D6FA197797C90E6B2B6C95CDC29010B9543F12C98F69532D5FD24C5D47815; __csrf=e1f13890502a39b4f65a43ad92bb5ea8; ntes_kaola_ad=1'
}
# 网页的请求链接
index_url = 'https://music.163.com/discover/toplist?id=19723756'
# 发起网络请求
response = requests.get(index_url, headers=headers)
# print(response.text)
# 将网页的html字符串转换成树形结构
html = etree.HTML(response.text)
# 使用xpath表达式来筛选出音乐的ID
id_info_list = html.xpath('//ul[@class="f-hide"]/li/a/@href')
# print(id_info_list)
# 使用xpath表达式来筛选出音乐的名称
name_list = html.xpath('//ul[@class="f-hide"]/li/a/text()')
# print(name_list)
# 判断路径中是否有对应的文件夹, 如果存在则跳过
if not os.path.exists('网易云音乐'):
# 如果不存在就创建这个文件夹
os.mkdir('网易云音乐')
# 使用列表进行遍历
for id_info, name in zip(id_info_list, name_list):
# 对ID信息使用=进行切割,获取右边的ID数字
music_id = id_info.split('=')[1]
# 定义下载音乐的接口链接
music_url = 'https://music.163.com/song/media/outer/url?id=' + music_id
# 发起网络请求,获取音乐数据
response = requests.get(music_url, headers=headers)
name = name.replace('/', '-')
# 将获取的音乐数据保存到音乐文件中
with open(f'./网易云音乐/{name}.mp3', 'wb') as file:
file.write(response.content)
print(f'音乐名称:{name} 下载链接:{music_url} 下载完毕')
运行结果:
点击下方名片可以下载python工具和完整源码


















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









