







一 、字节对齐的含义
要理解字节对齐,首先得理解系统内存的组织结构。内存由许多存放一段信息的单元(位置)组成,每个单元有一个编号,程序可以通过这个编号来访问这个单元,这个编号就是这个单元的地址。在x86体系架构中,内存单元大小为8bit,物理内存地址是对单元进行寻址,举个例子来说,一个拥有32位地址总线的CPU来说,能够寻址的内存大小为232x8bit(1Byte)=4GByte。
这里为了方便,把1个内存单元称为1个字节,字节再组成字,在8086时代,16位的机器中1字=2个字节=16bit,而80386以后的32位系统中,1字=4个字节。大多数计算机指令都是对字进行操作,如将两字相加等。也就是说,32位CPU的寄存器为32位,导致指令的操作对象是32位字;16位CPU的寄存器为16位,移动、加、减等指令的操作对象也是16位字。由于指令的原因,内存的寻址也同样是按字进行操作,在16位系统中,如果你访问的只是低8位,内存寻址还是按16位进行,然后再根据A0地址线选择低8位还是高8位,这一过程成为一次内存读(写),在16位系统中,如果读取一个32位数,要花费两个内存读周期(先读低16,再读高16)。同理32位CPU的内存寻址按4个单元进行。以下引用80386使用手册中的一段话来说明:
When used in a configuration with a 32-bit bus, actual transfers of data between processor and memory take place in units of doublewords beginning at addresses evenly divisible by four; however, the processor converts requests for misaligned words or doublewords into the appropriate sequences of requests acceptable to the memory interface. Such misaligned data transfers reduce performance by requiring extra memory cycles.
为了达到高效的目的,在16位系统中,变量存储的起始地址是2的倍数,32位系统中,变量存储的起始地址是4的倍数,而这些工作都是由编译器来完成的。下面举个例子来说明这个问题。如下图所示:
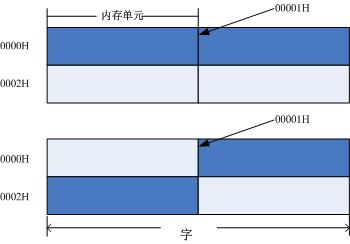
上图是16位系统的内存布局图,深蓝色表示变量覆盖的内存范围,假设变量的大小为2个字节,变量的起始物理内存地址为0000H时,访问这个变量时,只需要一次内存的读写。然而,当变量的内存起始地址为0001H时,cpu将耗费两次读周期进行变量访问,具体过程如下:为了访问变量的低8位,cpu将通过寻址访问起始地址为0000H所在的字,然后找到当前字的高8位;随后cpu再访问0002H所处字的低8位,此低8位就是
变量的高8位,这样经过cpu的拼装变量的访问就结束了,可见,需要经过两次读周期才能正确访问变量的值,效率是前者的1/2。
二、字节对齐的使用场合
这里我们只考虑与平时编程相关某些部分,像全局变量对齐、函数参数和局部变量对齐、指令对齐由具体的编译器处理。下面讨论以下两部分内容:
结构体字节对齐
在两个异构的CPU进行通信时,如果利用结构体作为消息承载体,那么可能会遇到两个很常见的问题:结构体字节对齐和大小端定义。只有深刻理解了这两部分内容,才能在两个不同的体系架构的主机之间进行通信。当结构体采用的对齐方式或者大小端定义不一致时,就会造成数据访问的错误(特别是在类型强制转换时,这在网络通信中经常用到)。这里仅仅讨论结构体字节对齐,大小端定义感兴趣可以参看我的博文《大小端之我的见解》。下面引用一篇文章能够很好地讲述结构体字节对齐的问题(避免重造车轮,呵呵):
通常,我们写程序的时候,不需要考虑对齐问题。编译器会替我们选择适合目标平台的对齐策略。当然,我们也可以通知给编译器传递预编译指令而改变对指定数据的对齐方法。
但是,正因为我们一般不需要关心这个问题,所以因为编辑器对数据存放做了对齐,而我们不了解的话,常常会对一些问题感到迷惑。最常见的就是struct数据结构的sizeof结果,出乎意料。为此,我们需要对对齐算法所了解。
对齐的算法:
由于各个平台和编译器的不同,现以本人使用的gcc version 3.2.2编译器(32位x86平台)为例子,来讨论编译器对struct数据结构中的各成员如何进行对齐的。
设结构体如下定义:
struct A
{
int a;
char b;
hort c;
};
结构体A中包含了4字节长度的int一个,1字节长度的char一个和2字节长度的short型数据一个。所以A用到的空间应该是7字节。但是因为编译器要对数据成员在空间上进行对齐。所以使用sizeof(strcut A)值为8。现在把该结构体调整成员变量的顺序:
struct B
{
char b;
int a;
short c;
};
这时候同样是总共7个字节的变量,但是sizeof(struct B)的值却是12。
下面我们使用预编译指令#pragma pack (value)来告诉编译器,使用我们指定的对齐值来取代缺省的:
#pragma pack (2) /*指定按2字节对齐*
struct C
{
char b;
int a;
short c;
};
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
#pragma pack (1) /*指定按1字节对齐*/
struct D
{
char b;
int a;
short c;
};
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
sizeof(struct C)值是8,sizeof(struct D)值为7。
对于char型数据,其自身对齐值为1,对于short型为2,对于int,float,double类型,其自身对齐值为4,单位字节。
这里面有四个概念值:
1. 数据类型自身的对齐值:就是上面交代的基本数据类型的自身对齐值。
2. 指定对齐值:#pragma pack (value)时的指定对齐值value。
3. 结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
4. 数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值。
有了这些值,我们就可以很方便的来讨论具体数据结构的成员和其自身的对齐方式。有效对齐值N是最终用来决定数据存放地址方式的值,最重要。有效对齐N,就是表示“对齐在N上”,也就是说该数据的"存放起始地址%N=0".而数据结构中的数据变量都是按定义的先后顺序来排放的。第一个数据变量的起始地址就是数据结构的起始地址。结构体的成员变量要对齐排放,结构体本身也要根据自身的有效对齐值圆整(就是结构体成员变量占用总长度需要是对结构体有效对齐值的整数倍,结合下面例子理解)。这样就不能理解上面的几个例子的值了。
例子分析:
分析例子B:
struct B
{
char b;
int a;
short c;
};
假设B从地址空间0x0000开始排放。该例子中没有定义指定对齐值,在笔者环境下,该值默认为4。第一个成员变量b的自身对齐值是1,比指定或者默认指定对齐值4小,所以其有效对齐值为1,所以其存放地址0x0000符合0x0000%1=0.第二个成员变量a,其自身对齐值为4,所以有效对齐值也为4,所以只能存放在起始地址为0x0004到0x0007这四个连续的字节空间中,复核0x0004%4=0,且紧靠第一个变量。第三个变量c,自身对齐值为2,所以有效对齐值也是2,可以存放在0x0008到0x0009这两个字节空间中,符合0x0008%2=0。所以从0x0000到0x0009存放的都是B内容。再看数据结构B的自身对齐值为其变量中最大对齐值(这里是b)所以就是4,所以结构体的有效对齐值也是4。根据结构体圆整的要求,0x0009到0x0000=10字节,(10+2)%4=0。所以0x0000A到0x000B也为结构体B所占用。故B从0x0000到0x000B共有12个字节,sizeof(struct B)=12;
同理,分析上面例子C:
#pragma pack (2) /*指定按2字节对齐*/
struct C
{
char b;
int a;
short c;
};
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
第一个变量b的自身对齐值为1,指定对齐值为2,所以,其有效对齐值为1,假设C从0x0000开始,那么b存放在0x0000,符合0x0000%1=0;第二个变量,自身对齐值为4,指定对齐值为2,所以有效对齐值为2,所以顺序存放在0x0002、0x0003、0x0004、0x0005四个连续字节中,符合0x0002%2=0。第三个变量c的自身对齐值为2,所以有效对齐值为2,顺序存放。在0x0006、0x0007中,符合0x0006%2=0。所以从0x0000到0x00007共八字节存放的是C的变量。又C的自身对齐值为4,所以C的有效对齐值为2。又8%2=0,C只占用0x0000到0x0007的八个字节。所以sizeof(struct C)=8。
在不同架构的主机通信中,只要确保结构体的对齐方式一致(可以通过#pragma pack()指定),就可以正确地通信。
缓存对齐
缓存对齐与具体的硬件架构有关,对数据进行缓存对齐,能够有效提高效率。在内核的协议栈里头可以看到一个宏SKB_DATA_ALIGN,这个宏的作用就是强制数据与硬件架构的cache line size对齐,这样能够减小内存到cache之间传递数据的次数。什么叫cache line,可以通过下面一段英文进行理解:
cache line is The smallest unit of memory than can be transferred between the main memory and the cache. Rather than reading a single word or byte from main memory at a time, each cache entry is usually holds a certain number of words, known as a "cache line" or "cache block" and a whole line is read and cached at once. This takes advantage of the principle of locality of reference: if one location is read then nearby locations (particularly following locations) are likely to be read soon afterwards. It can also take advantage of page-mode DRAM which allows faster access to consecutive locations.
大体的意思是cache line是主存与缓存之间进行传送的最小内存单元个数。如果进行非缓存对齐,那么读取一块数据,可能要花费两个或者更多的周期,而进行缓存对齐后,只需要一次传送周期就搞定。下面可以引用内核中alloc_skb的代码作为例子:
skb = kmem_cache_alloc(skbuff_head_cache, gfp_mask & ~_ _GFP_DMA);
/* ... ... ...*/
size = SKB_DATA_ALIGN(size);
data = kmalloc(size + sizeof(struct skb_shared_info), gfp_mask);
这里使用SKB_DATA_ALIGN的作用是把skb_share_info结构的起始地址挤到下一个cache line中,以便提高效率。
缓存对齐在网络协议开发中可能会经常碰到,所以对它进行一定的了解,能够改善和优化你协议的性能!















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









