






文章目录
一、Scrapy 框架的整体架构和组成
Scrapy 底层运用多线程原理,用纯 Python 语言爬取网站页面数据、结构性数据的应用型框架。它提供了基础的爬虫基类,如 BaseSpider、sitemap 爬虫等,还可以爬取网页内容以及各种图片。Scrapy 用途广泛,可应用于数据爬取、挖掘、监测和自动化测试等各方面。
 Scrapy 运行时,请求发出去的整个流程大概如下。
Scrapy 运行时,请求发出去的整个流程大概如下。
(1)首先爬虫将需要发送请求的 URL(Request)经 Scrapy Engine 交给 cheduler;
(2)排序处理后,经过 Scrapy Engine、Downloader Middlewares 后交给 Downloader。
(3)Downloader 向互联网发送请求,并接收下载 Response。将经 Scrapy Engine,可选交给Spider。
(4)Spider 处理 Response,提取数据并将数据经 Scrapy Engine 交给 Item Pipeline保存;
(5)提取 URL 重新经 Scrapy Engine 交给 Scheduler 进行下一个循环,直到无 URL 请求后程序终止。
二、安装 Scrapy 框架
使用命令:pip install scrapy 进行安装。如果直接不成功,需使用更新 pip 命令:python -m pip install -U --force-reinstall pip 后,再进行安装 Scrapy。
(1)首先下载 Scrapy 的 whl 包,下载地址:“httpAddr-019”,在网页中搜索‘scrapy’找到 Scrapy‑2.5.0‑py3‑none‑any.whl。

(2)安装 Scrapy 的 whl 包依赖 wheel 库。直接运行 pip install wheel 即可。

(3)Scrapy 还需要 twisted,同样使用 whl 格式的包进行安装。进入“httpAddr-019”网页,在网页中搜索 twisted 找到其对应的 whl 包并下载。这里要注意,需要根据 Python版本选择合适的包。
(4)Scrapy 还依赖 lxml 包,需要先安装 lxml 包,lxml 包依赖 libxml2,libxml2-devel,所以需要安装 lxmllibxml2、libxml2-devel 等,下面是安装 lxml 库。

(5)所有准备工作做完,进入 whl 包所在的文件夹执行命令 Scrapy‑2.5.0‑py3‑none‑any.whl 所在的目录,运行 pip install scrapy 之后,即可安装 Scrapy 包。

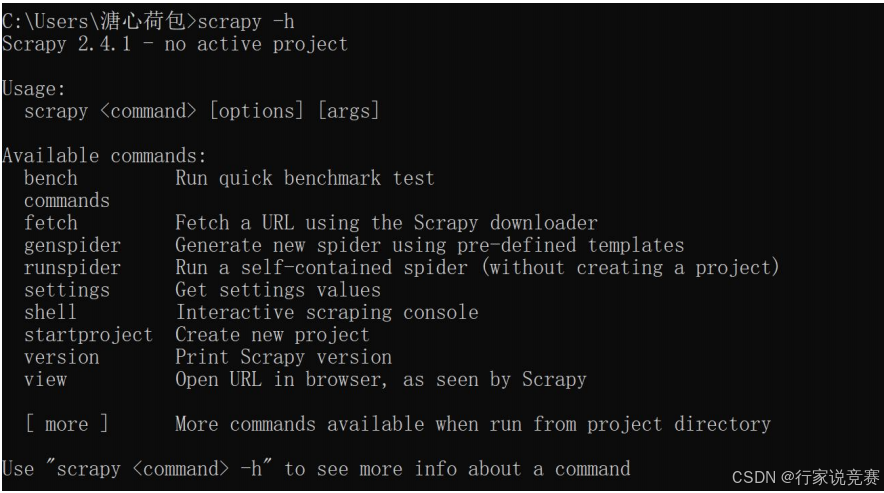
(6)Scrapy 包安装完成后,还需验证 Scrapy 是否安装成功,输入 scrapy -h,出现所示界面即可。
三、Scrapy 框架的使用
1、创建 Scrapy 工程
(1)创建爬虫项目,命令:scrapy startproject xxx(项目名称),创建完成后会自动生成一些文件。例如本例中进入 D 盘的 Spider 目录夹,运行 scrapy startproject pachong1的命令。

项目创建完成后回到 Pycharm 中我们可以看到,出现一个 Scrapy 框架自动生成的爬虫目录
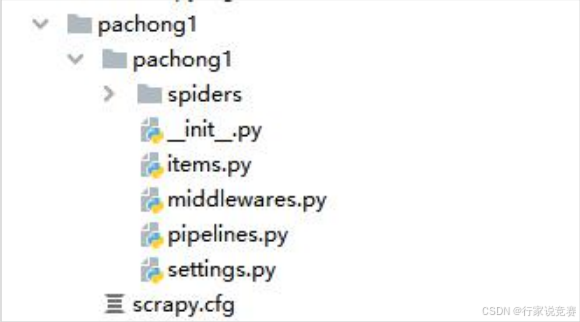
爬虫目录内容如下:
init.py:这个包是注释使用,包含 Scrapy 项目的 Spider,以及有关如何创建和管理 sppider 的信息。
items.py:定义 Item 数据结构的文件。在此可以编写所有的 Item 数据定义。
middlewares.py:项目中间件文件。
pipelines.py:数据处理文件,对爬取到的数据进行处理保存等。
settings.py:项 目设置 文件 ,可以 定义项 目的 全局设 置,比 如 USER_AGENT,
ROBOTSTXT_OBEY 等。
scrapy.cfg:项目配置文件。定义了项目设置文件路径、部署信息等内容。
(2)进入爬虫项目文件夹,生成定向爬取某页面的爬虫。
命令为 cd pachong1 和 scrapy genspider baidu baidu.com,进入 pachong1 文件夹后,生成了一个名为 baidu 的爬虫去爬取 baidu.com

这时回到 Pycharm 中可以看到,自动生成了 baidu.py 文件,并生成所示代码:
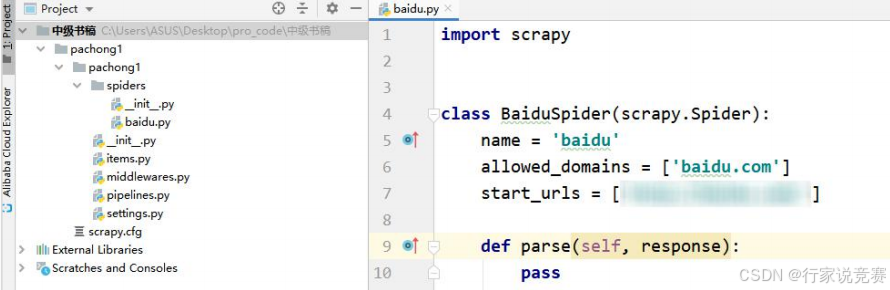
【示例】通过下面的代码块 baidu.py 实现定向爬虫。
import scrapy
from pachong1.items import Pachong1Item
query = "python1+X"
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['baidu.com']
start_urls = [' httpAddr-018 % query]
def parse(self, response):
print(response.url)
print(response.headers)
title = response.xpath("/html/head/title/text()").extract()[0]
item = Pachong1Item()
item['title'] = title
yield item
这段代码的主要作用是利用 Scrapy 抓取页面标题,从起始网页开始,利用 Scrapy 框架”httpAddr-018”中提供的快捷选择器 response.xpath,采用 extract()方式获得指定路径下的页面标题。
2、使用 Spider 提取数据
Spider 是 Scrapy 提供的基本类,Scrapy 中包含的其他基本类或者自定义的 Spider 都必须继承自这个类。
Spider 类定义的是网页的爬取逻辑规则,下面介绍利用 Spider 爬取数据的典型过程。
首先,Spider 的入口方法为 start_requests 请求 start_urls 列表中定义的网页链接地址,返回Request 对象,同时默认传递一个名为 parse 的回调函数。
其次,下载器获取 Response 后,由回调函数会解析,Response 返回 yield 的结果。这里的结果由爬取到的数据组成,可以是列表、字典、Item 或者 Request 对象等。
然后,使用 Scrapy 自带的选择器工具解析数据。
最后,将返回的数据字典或者 Item 自己保存为文件或存储在数据库中。
对于代码文件,由 Scrapy 生成的 class XXXSpider(scrapy.Spider)类中有几个重要的属性:
Name:是字符串,用于设置 Spider 的名字,实际中一般为每个独立网站创建一个 Spider。
allowed_domains:是一个字符串列表。规定了允许爬取的网站域名,非域名下的网页将被自动过滤。
strart_urls:是一个必须定义包含初始请求页面 URL 的列表。start_requests()方法会引用该属性,发出初始的 Request。
start_requests(self):在命立行执行爬虫的时候,如果没有给出指定的 URL,那么引擎会调用这个方法。该方法返回一个迭代器,迭代器的内容为 Request.
parse(self,response):引擎默认的响应处理函数。如果没有在 Request 中指定响应处理函数,那么引擎会调用这个函数。
Spider 允许接收一些参数以修改其行为。需要再执行 scrapy crawl 命令时传递参数-a例如希望给 Spider 传递一个 kw 参数也可以这样做。
scrapy crawl spider_name -a kw=electronics
【示例】通过下面的代码块 baidu.py,可以带参数运行爬虫。
import scrapy
from scrapy import cmdline
class BaiduSpider(scrapy.Spider):
name = 'baidu'
start_urls = ['httpAddr-017']
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 方式一:在 init 方法中获取参数
num = kwargs.get('num')
print('init num: ', num)
def parse(self, response):
# 方式二:在实例方法中获取参数
# 如果没有传参数会报错: AttributeError: 'BaiduSpider' object has no
attribute 'num'
print('self.num: ', self.num)
# 方式三:在实例方法中获取参数
num = getattr(self, 'num', False)
print('getattr: ', num)
if __name__ == '__main__':
cmdline.execute("scrapy crawl baidu -a num=10".split())
在方法-中,有 response.xpath 这样一行代码,这就是爬取网页中尤为重要的也是用户自定义的关键部分。在爬取网页时,最常见的是从 HTML 源码中解析网页,提取数据,而以往 Python 中也有一些常用的库来处理这些问题,如使用 BeautifulSoup 网页分析库或者是 lxml(一个基于ElementTree 的 Python 化的 XML 解析库)。
在 Scrapy 中 Spider 实现了自己的提取数据的一套机制,其被称为 Selectors(选择器),这些选择器是构建在 lxml 库之上,并简化了 API。Spider 提取数据的选择器包括 Xpath 和CSS 两种。Xpath 可以用来在 XML、HTML 文件中选择节点和元素,其常操作见下表。CSS 是HTML 文档样式化的语言。
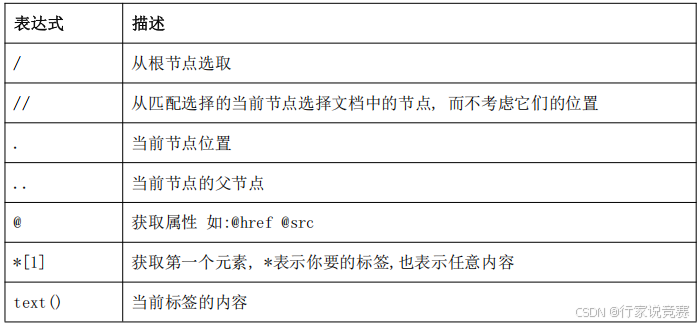
与 Xpath 选择器相比,CSS 选择器的语法比 Xpath 选择器更简单一些,但功能不如 Xpath选择器强大。相对来说,前端工程师可能会更加喜欢使用 CSS 选择器,同时它的使用方式写CSS 时的方法基本一样,其常用操作见下表。
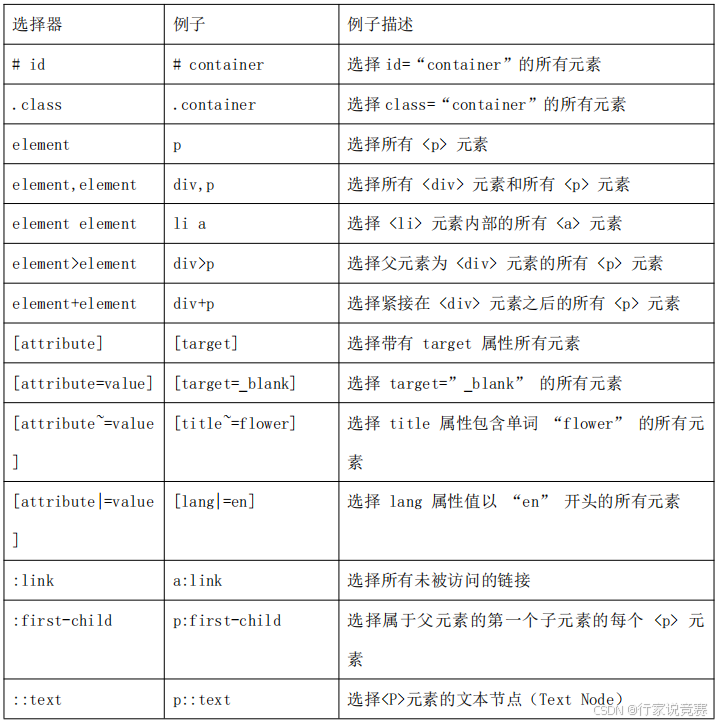
3、使用 Item 封装数据
在Scrapy 的数据传递方式中,可以使用字典封装爬取到的数据,但是字典存在一些缺陷,因此使用 Scrapy 自动生成的 items.py 中的 Item 类封装爬取到的数据。其优点是:
(1)清晰地了解数据中包含的字段。
(2)可以对字段名进行检测。
(3)便于携带元数据。
例如在 items.py 中实例化 CarItems, Item 类是自定义数据类(CarItems)的基类,需要被自定义数据类继承。Field 类用来描述自定义数据类包含哪些字段,如 name、price等。
from scrapy import Item,Field
class CarItems(Item):
name = Field()
price = Field()
这里实例化 CarItems,并将解析得到的 name 和 price 传入给 Item,并用 yield 返回给引擎处理。
spider.py 文件中具体内容如下:
import scrapy
from GuaziItems import CarItems
class CarSpider(scrapy.Spider):
name = "start"
urls = ["httpAddr-016"]
def parse(self, response):
for car in response.css('article.product_pod'):
name = car.Xpath('./h3/a/@title').extract_first()
price = car.css('p.price_color::text').extract_first()
item = CarItems()
item['name'] = name
item['price'] = price
yield item
这里 Item 的键是和定义的字段相对应的,如果写成其他的,会报错。
4、使用 Item Pipline 处理数据
当一个 Item 被爬虫使用,它就会被发送到 Item Pipeline,并通过组件按顺序执行。
在 settings.py 文件中,在 ITEM_PIPELINES 中添加项目管道的类名,就可以激活项目管道组件,它们接收一个项目并对其执行操作,同时决定该项目是继续通过管道还是被丢弃而不再处理。Item Pipeline 一般有两种,文件管道和图像管道。
Item Pipeline 的作用主要是清理 HTML 数据、验证爬取的数据(检查项目是否包含某些字段/图片)、检查重复项(并删除它们)和在文件或数据库中存储爬取的项目。
使用 Item Pipeline 时,典型的文件管道工作步骤如下。
(1)在 Spider 中,选取一个项目并将所需项目的 URL 放入字段中。
(2)项目从 spider 返回并进入 Item Pipeline。
(3)当项目到达 Files Pipeline 时,字段中的 URL 将使用标准的 Scrapy scheduler 和Downloader(可重用 Scheduler 和 Downloader 中间件)计划下载,但优先级更高,在爬取其他页面之前对其进行处理。在文件完成下载(或由于某种原因失败)之前,该项在特定管道阶段保持“锁定”。
(4)下载文件时,另一个字段(文件)将填充结果。此字段将包含一个目录列表,其中包有关下载文件的信息,例如下载路径、原始爬取的 URL、文件校验和文件状态。文件列表字段中的文件将保留与原始文件字段相同的顺序。如果某个文件下载失败,则会记录一个错误,并且该文件不会出现在“文件”字段中。
(5)当 Item 在 Spider 中被收集之后,就会被传递到 Item Pipeline 中进行处理。
使用 Item Pipline 时,典型的图像管道工作流步骤与文件管道工作流步骤类似。
①爬取一个 Item,将图片的 URLs 放入 image_urls 字段。
②从 Spider 返回的 Item,传递到 Item Pipeline。
③当 Item 传递到 Image Pipeline 时,将调用 Scrapy 调度器和下载器完成 image_urls中 URL 的调度和下载。
④图片下载成功后,图片下载路径、URL 和校验和等信息会被填充到 images 字段中。
下面介绍编写 Item Pipeline 必须实现的函数 process_item(self,item,spider)。
①每个 Item Pipeline 组件是一个独立的 Python 类,必须实现以 process_item(self,item,spider)方法。
②每个 Item Pipeline 组件都需要调用该方法,这个方法必须返回一个具有数据的字典,或者 Item 对象,或者抛出 DropItem 异常,被丢弃的 Item 将不会被之后的 Pipeline 组件所处理。
③编写 Item Pipeline 可以选择实现 open_spider(self,spider),表示当 Spider 被开启时调用该方法,或者选择实现 close_spider(self,spider),其表示当 spider 关闭时调用。
④写完 Item pipeline 后,需要在 settings 中设置才可生效,在此设置中为类指定的整数值决定了它们的运行顺序,从低值到高值。通常将这些整数值的数字定义在 0~1000 之间。

















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









