







时间:2025年 08月 10日
作者:小蒋聊技术
邮箱:wei_wei10@163.com
微信:wei_wei10
音频:喜马拉雅
大家好,我是小蒋。前段时间停更了一阵,让大伙儿等急了,先道个歉哈~ 今天不整那些虚头巴脑的概念,咱就掰开揉碎了聊 RAG 数据库 —— 这玩意儿到底是啥,为啥现在 AI 圈都在追它?
一句话说透:RAG 就是 AI 的 “私人记忆硬盘”
别被 “检索增强生成” 这词儿唬住,说白了特简单:普通大模型自带的记忆,就像个堆满旧书的仓库,你问新事儿、偏门事儿,它要么卡壳,要么从旧书里东拼西凑瞎糊弄。
但 RAG 不一样,它给 AI 加了个 “可自定义的硬盘”—— 你想让 AI 懂啥,就往里面塞啥:公司的内部文档、行业白皮书、甚至你自己的学习笔记。等 AI 回答问题时,会先翻这个 “专属硬盘”,再开口说话。
核心逻辑就是:用 “你的数据” 打破 AI 自带知识库的局限,让AI说的每句话都贴着你的需求来。
别被 “生成” 带偏了!真本事在 “怎么把数据喂进去、捞出来”
很多人觉得 RAG 的关键是 AI 怎么 “生成” 答案,其实跑偏了。真正的硬功夫,藏在 “数据处理” 和 “精准检索” 这两步里。
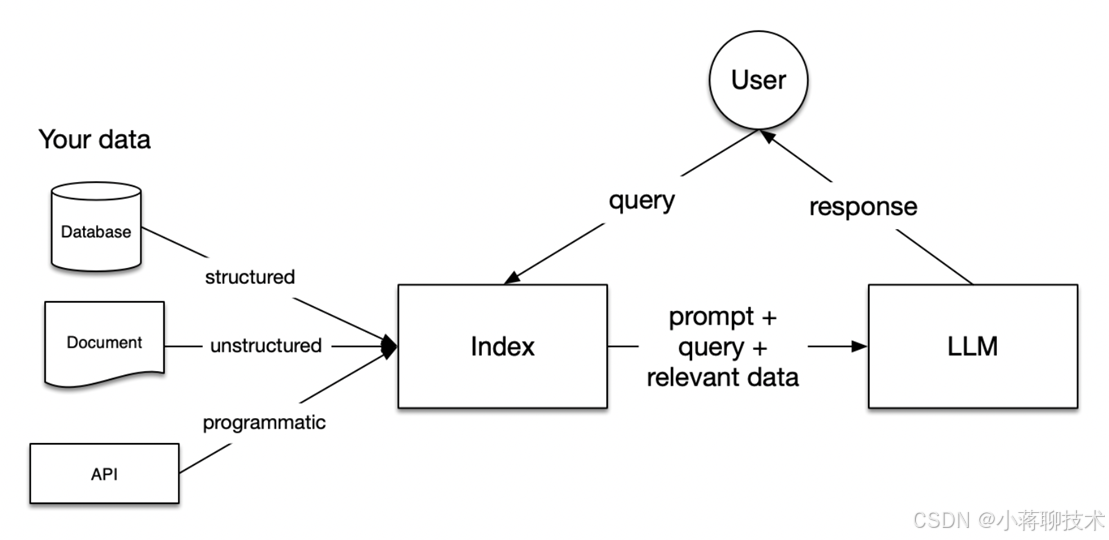
第一步:把数据 “碾碎” 成 “语义密码”
你扔给 RAG 一本《量子力学》,它不会原封不动存着。而是用 “嵌入模型”(比如 OpenAI 的 embedding)给文字编 “数字密码”—— 每句话、每个段落都变成一串数字(向量)。
这串数字可不是瞎编的,它能抓住文字的 “意思”:比如 “薛定谔的猫” 和 “量子叠加态” 的数字串会很像,和 “红烧肉做法” 的数字串就差老远。
说白了,这一步是让电脑 “看懂” 文字的含义,而不是只认字母数字。
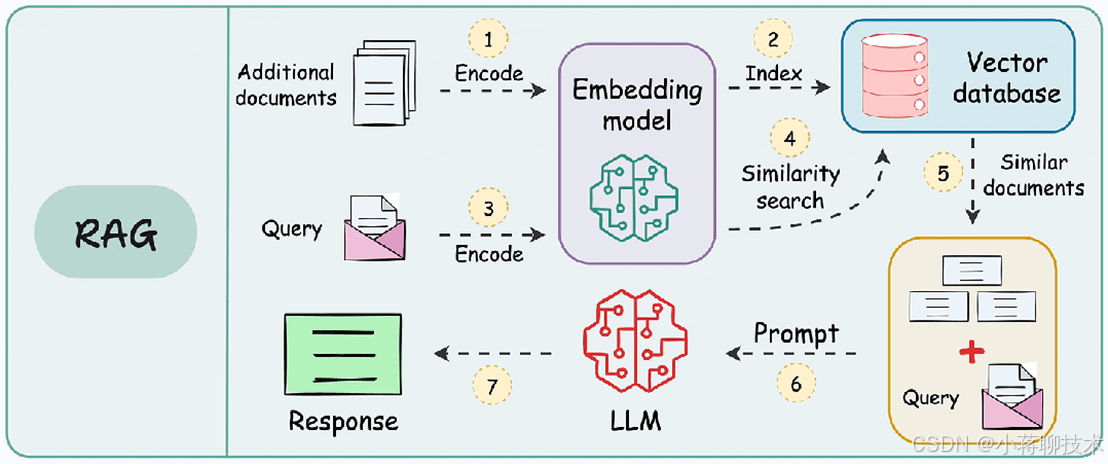
第二步:用 “向量数据库” 当 “智能抽屉”
这些数字串存在哪儿?不是 Excel 或 MySQL,得用专门的 “向量数据库”(比如 Milvus、Qdrant)。这东西牛在哪儿?
你问个问题,它先把问题也变成数字串,然后在几百万个颗粒里,瞬间找到 “数字最像” 的那些 —— 也就是意思最相关的内容。
举个例子:普通数据库搜 “苹果”,只会给你带 “苹果” 俩字的内容;但向量数据库能明白 “苹果手机怎么修” 和 “iPhone 故障排除” 是一回事,直接把相关内容给你拎出来。
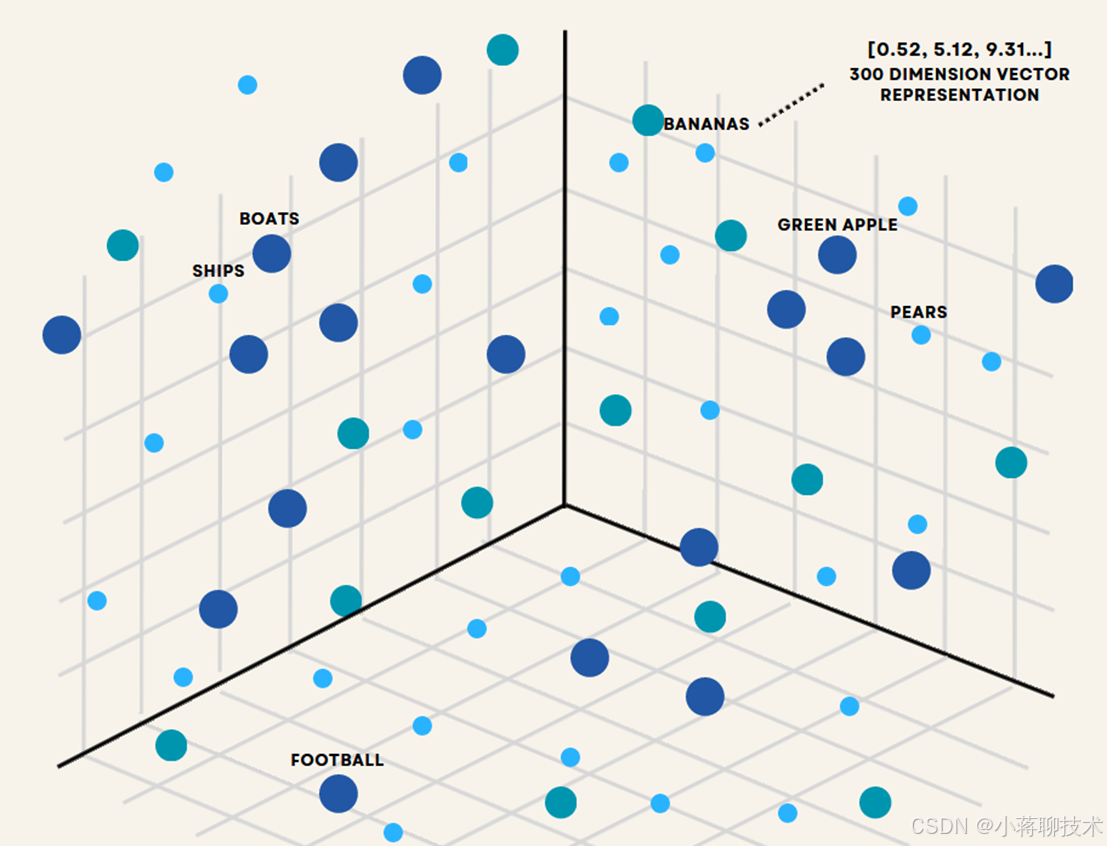
为啥大家都在折腾 RAG?它让 AI 从 “通用工具” 变成 “你的工具”
通用 AI 再强,也不懂 “你的具体事儿”。RAG 就解决了这个痛点:
对企业:把 “老员工的经验” 变成 “谁都能用的资产”
公司里太多知识藏在老员工脑子里、散在邮件文档里:比如某个客户的特殊要求、某个项目踩过的坑。RAG 能把这些全塞进数据库,新来的同事、客服,甚至 AI 机器人,随时都能调出来用。从此 “只有老王知道” 变成 “谁问谁知道”。
对个人:打造 “私人定制的 AI 大脑”
你考研学英语,把真题、错题解析塞进去,AI 讲题就只围绕这些内容,不会扯到雅思托福;你做自媒体,把自己的文章、风格笔记塞进去,AI 帮你写稿就不会跑偏。
本质上,RAG 让 AI 从 “对着全世界喊” 变成 “只跟你一人聊”。
最后小蒋总结一下:RAG 的牛,在于它让 AI 真正 “落地” 了。大模型再炫,不能解决你的具体问题也是白搭。而 RAG 就是架在 “你的数据” 和 “AI 能力” 之间的桥,让你的知识活起来,让 AI 真真切切为你服务。
下次再有人聊 RAG,别听虚的,先问:你的数据怎么碾碎喂的?如何进行精准检索的?—— 这才是真本事。
小蒋聊技术咱今天就聊到这儿,有疑问评论区见~ 下次再聊点硬核的!


















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











