







频繁子图挖掘的基本概念
参考 https://blog.csdn.net/qq_41653753/article/details/79112436
gSpan
为了遍历图,gSpan算法采用深度优先搜索。初始,随机选择一个起始顶点,并且对图中访问过的顶点做标记。被访问过的顶点集合反复扩展,直到建立一个完全的深度优先搜索 (DFS) 树。(图中加粗的边)
如下图所示:

基于边序,如果用5元组(i ,j ,L(i), L(i,j), L(j)) 表示边,其中 L(j) 和 L(i)
分别是 v(i) 和 v(j) 的标记,而 L(i,j) 是连接它们的边的标记, 则

gSpan最右路径扩展规则
给定图G 和G 的DFS树T ,一条新边e 可以添加到最右节点和最右路径上另一个节点之间(后向扩展);或者可以引进一个新的节点并且连接到最右路径上的节点(前向扩展)。由于这两种扩展都发生在最右路径上,因此称为最右扩展。 (黑点为最右路径)第一优先级始终是将当前结束顶点链接回第一个顶点(标记为0的顶点)。如果那是不可能的,我们看看是否可以将它链接回第二个顶点(标记为1的顶点)。如果我们有一个更大的子图,我们将继续尝试链接到第3,第4等,如果可能的话。如果这些都不可能,那么我们的下一个(第三个)优先级是从我们所处的顶点(上面标记为4)增长,并使链长得更长。如果这不起作用,我们回到父节点,再退一步,然后尝试从那里开始增长(图(e))。如果这不起作用,那么我们再向上迈出一步,并尝试从那里成长(下面的第五个例子)。

gSpan伪代码

实例

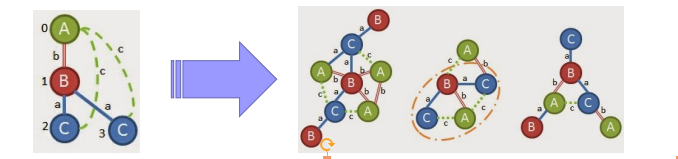
步骤一:图里共有有7个alpha(α)顶点,8个beta(β)顶点和14个lambda(λ)顶点。有15个边缘为纯蓝色,13个为双红色,8个为绿色点缀。现在我们已经有了这些计数,我们需要将顶点和边的原始标签排序成一个代码,这将有助于我们稍后对搜索进行优先级排序。为此,我们创建一个代码,该代码以具有最高计数的顶点和边开始降序排列标号。
我们首先查看各个边(例如A,b,A),看看它们是否满足此最小支持阈值。我将从查看顶部的第一个图表开始。有一个边是(B,a,C),我需要计算有多少图有这样的边。我可以在第一张图,第二张图,第三张图和第四张图中找到它,因此它支持4; 我们会保留那一个。还要注意我可以选择将该边写为(C,a,B),但是选择用B作为起始顶点来编写它,因为我们在上面建立了它的顺序。我们继续前进并检查(A,a,C)并发现它只能在第一个图中找到; 它被丢弃了。我们检查(A,c,C)并在前4个图中找到它; 收下




我们基于优先级规则的下一步是尝试将顶点3(‘C’)链接到根或’A’。我们可以选择的唯一常用边是(C,c,A)。
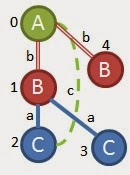
这仅存在于我们的一个图表中,因此我们将进入下一个增长优先级。由于在顶点3处的’C’与’B’和顶点1之间已经存在链接,因此第二优先级不是一个选项,因此我们尝试再次从顶点3处的’C’增长/延伸。我们可以添加(C,a,B)或(C,c,A)。添加(C,a,B)看起来像这样

我们尝试添加(C,c,A)。但在我们留下的任何图表中都找不到它。由于我们在这里再次走向死胡同,我们将进入我们的第五个优先增长选择:再次从根增长。如果我们试图从根’A’增长,我们可以使用(A,b,B)或(A,c,C)。从(A,b,B)开始,我们将得到一个如下所示的子图
这在我们的任何图表中都找不到,所以我们尝试添加(A,c,C)作为我们最后的努力
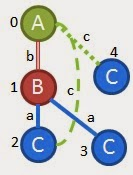
support=0,回到最近一个待定状态(1,3,B,b,A),其support<3,继续回到(0,4,A,c,C)support<3,继续回到上一个待定状态(0,2,A,c,C)。

我们可以从C节点扩展,我们的两个选项是(2,3,C,a,B)和(2,3,C,c,A)添加(2,3,C,a,B)看起来像这样

第一条边扩展结束,下面来扩展第二条边(0,1,A,c,C)此时在原图中去掉(A,b,B)边。原图变为

经过一系列扩展后得到

下面来扩展第三条边(0,1,B,a,C)此时在原图中去掉(A,b,B),(A,c,C)边。原图变为
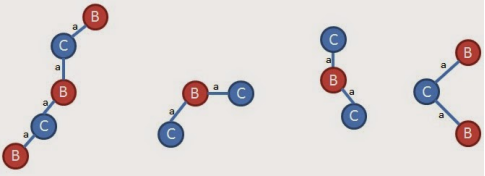
经过一系列扩展后得到
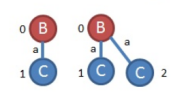
综上所述,所有的频繁子图为:
















 4737
4737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









