








传送门
从登录说起
记得刚毕业不久,在一家公司做一个投资管理系统,当时开发一个登录功能,做用户本地认证
- 用户输入账号,密码,点击提交
- 后台接收登录请求,获得账号,密码
- 到db里面获得用户信息,验证账号,密码是否正确
一般的登录认证功能,可能各有差异,这里不做讨论,只关注一个问题:如何验证密码正确?
简单的做法是直接比较,比如java中的字符串:a.equals(b),返回boolean值来判断是否一致。但是用户输入的是明文,db里面也是存储明文吗?答案肯定不会,稍微有点经验的程序员都会对密码进行加密存储,区别在于加密的算法及安全强度。
当然也有自信的CXDN(手动马赛克,虽说不吃人家的饭,但也不能砸它的锅),就是明文存储的,引起了轰动一时的密码泄露密码外泄门![]() https://baike.baidu.com/item/%E5%AF%86%E7%A0%81%E5%A4%96%E6%B3%84%E9%97%A8/4976608
https://baike.baidu.com/item/%E5%AF%86%E7%A0%81%E5%A4%96%E6%B3%84%E9%97%A8/4976608
而当时我们自己用的MD5进行加密(暂且这么称呼),那么上述流程就细化成如下

- 其中的MD5加密就达到了安全的目的,这样即使被黑客拖库也不会导致明文密码泄露
那么,这样多想一步,就会冒出一个疑问:MD5为什么能保证数据的安全性?用了MD5算法真的安全吗?在回答这些问题之前,先看下百度给出的定义
MD5信息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致
什么是单向散列函数?
为什么叫MD5?
不知道思考过一个问题没有,为什么这个算法会叫MD5?MD还可以理解,Message-Digest Algorithm,那带个5是为啥?一个最直接的想法就是版本。没错,MD5算法之前,还有MD2,MD4等版本的算法,但都是因为不断发现算法的弱点或被破解而进行升级改进,才到了现在普遍通用的MD5。这一系列的MD算法都是散列函数,更多信息参考MD5算法
什么是单向函数?
MD5是单向散列函数,从字面理解,这类函数至少具有2个特性:
- 单向
- 散列
通俗理解,单向函数即:正向计算容易,逆向运算困难的函数。也就是说,给定你一个输入,你很容易计算出输出;但是给定你一个输出,你却很难计算出输入是什么。

这也从定义上决定了没有绝对安全的算法,因为困难并不意义着做不到,各种算法或者版本都只是在提升难度系数。如果难度系数足够大,大到现阶段技术手段无法实现或者所需时间非常长,比如按现在的计算机算力都要几十年,也可以认为是足够安全的。就好比俗语说"覆水难收",可以把输入数据当做泼出去的水,要收回是几乎是不可能的,除非是孙大圣显了神通。在网上还流行一个形象的例子(来自《应用密码学》),比如把盘子打碎是一件很简单的事情,但是把这些碎片再拼接成一个完整的盘子,就是一件非常困难的事情。
那么是不是算法强度越高,破解越困难,就越好呢?如果是真实使用场景中,要平衡两个方面
- 算法计算速度:正向计算会更容易,容易程度就是这个函数的计算性能
- 算法破解强度:逆向运算会更困难,困难程度就是这个函数的破解强度
理论来说,计算性能越高,安全性相对要差一些。如果一味追求算法的高强度,而导致计算特别慢在生产上也是很难使用的;反之亦然
什么是散列函数?
说到散列函数,做java应该不陌生,以前面试八股文经常会问HashMap的碰撞问题:HashMap如何处理hash冲突?
其实hashCode()方法也是一个散列函数,Object根类提供了这个方法。自定义对象可以覆盖这个方法
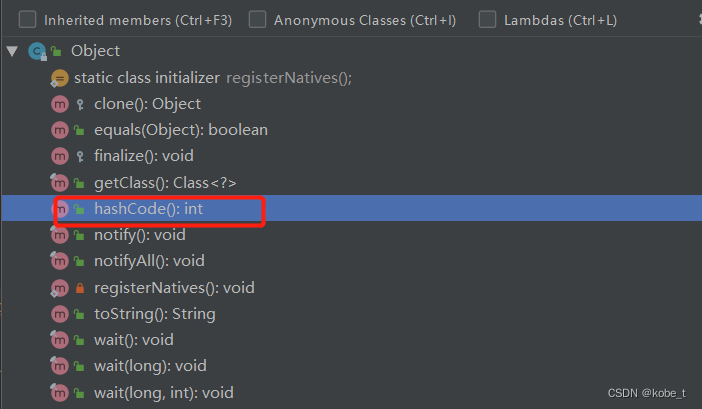
所以如果对于自定义hashCode()方法,要求仅量少发生碰撞,如果碰撞过多,会影响HashMap检索性能,极端情况会退化成一个链表,这由此引出了散列函数的一个特性:一个好的散列函数,它的散列值应该是均匀分布的。也就是说,每一个散列值出现的概率都是一样的。
怎么才能做均匀分布,即减小碰撞呢?最直接的办法,就是在输出数据的长度上想办法。在讨论如何在输出长度上做手脚前,先定义一下散列函数:
散列函数(Hash Function)是一个可以把任意大小的数据,转行成固定长度的数据的函数。比如说,无论输入数据是一个字节,或者一万个字节,输出数据都是 16 个字节。我们把转换后的数据,叫做散列值。
MD5的JAVA实现
在java中实MD5是很简单的,在包java.security有个类MessageDigest:
public abstract class MessageDigest extends MessageDigestSpi该MessageDigest类为应用程序提供消息摘要算法的功能,如SHA-1或SHA-256。 消息摘要是采用任意大小的数据并输出固定长度散列值的安全单向散列函数。
MessageDigest对象开始初始化。 数据通过它使用update方法进行处理。 在任何时候可以调用reset来重置摘要。 一旦要更新的所有数据都被更新,则应调用其中一个digest方法来完成哈希计算。
对于给定数量的更新,可以调用
digest方法一次。 在digest之后,将MessageDigest对象重置为初始化状态。
更多用法参考在线API
public class DigestUtil
{
/** MD5 */
public static final String MD5 = "MD5";
/**
* 对字符串md5加密
* @param data 待加密数据
* @return
*/
public static String Md5Digest(String data)
{
// 为空不处理
if (data == null)
{
return null;
}
try
{
// 指定摘要算法的MessageDigest对象
MessageDigest md = MessageDigest.getInstance(MD5);
// 使用指定的字节更新摘要
md.update(data.getBytes());
// digest()最后确定返回md5 hash值,返回值为8位字符串。因为md5 hash值是16位的hex值,实际上就是8位的字符
// BigInteger函数则将8位的字符串转换成16位hex值,用字符串来表示;得到字符串形式的hash值
return new BigInteger(1, md.digest()).toString(16);
}
catch (NoSuchAlgorithmException e)
{
e.printStackTrace();
}
return null;
}
public static void main(String[] args)
{
String md1 = Md5Digest("aaaa");
System.out.println(md1 + ",长度为" + md1.length());
String md2 = Md5Digest("aaaaa");
System.out.println(md2 + ",长度为" + md2.length());
String md3 = Md5Digest("abcdefghijklmnopqrstuvwxyz");
System.out.println(md3 + ",长度为" + md3.length());
String md4 = Md5Digest("aacdefghijklmnopqrstuvwxyz");
System.out.println(md4 + ",长度为" + md4.length());
String md5 = Md5Digest("");
System.out.println(md5 + ",长度为" + md5.length());
}
}看一下打印的输出
74b87337454200d4d33f80c4663dc5e5,长度为32
594f803b380a41396ed63dca39503542,长度为32
c3fcd3d76192e4007dfb496cca67e13b,长度为32
67dd96962bfdd39c25ab439c4eb702bd,长度为32
d41d8cd98f00b204e9800998ecf8427e,长度为32会发现无论输入多么长的字符串,输出长度都是32。所以回到上面的问题怎么才能做均匀分布,即减小碰撞呢?
答案是增大散列值的长度,比如上面的MD5是128比特,那么用一个输出更大长度的散列函数,来减小碰撞概率比如SHA-1算法
将上面的MD5算法稍加改造如下,即实现了SHA-1算法
/** SHA-1 */
public static final String SHA_1 = "SHA-1";
/**
* 对字符串sha1加密
* @param data 待加密数据
* @return
*/
public static String sha1Digest(String data)
{
// 为空不处理
if (data == null)
{
return null;
}
try
{
// 指定摘要算法的MessageDigest对象
MessageDigest md = MessageDigest.getInstance(SHA_1);
// 使用指定的字节更新摘要
md.update(data.getBytes());
// BigInteger函数则将8位的字符串转换成16位hex值,用字符串来表示;得到字符串形式的hash值
return new BigInteger(1, md.digest()).toString(16);
}
catch (NoSuchAlgorithmException e)
{
e.printStackTrace();
}
return null;
}其实就是算法从MD5变成了SHA-1,再把上面的数据用MD5跟SHA-1同时加密一遍对比一下
public static void main(String[] args)
{
String md1 = md5Digest("aaaa");
System.out.println(md1 + ",md5长度为" + md1.length());
md1 = sha1Digest("aaaa");
System.out.println(md1 + ",sha1长度为" + md1.length());
String md2 = md5Digest("aaaaa");
System.out.println(md2 + ",md5长度为" + md2.length());
md2 = sha1Digest("aaaaa");
System.out.println(md2 + ",sha1长度为" + md2.length());
String md3 = md5Digest("abcdefghijklmnopqrstuvwxyz");
System.out.println(md3 + ",md5长度为" + md3.length());
md3 = sha1Digest("abcdefghijklmnopqrstuvwxyz");
System.out.println(md3 + ",sha1长度为" + md3.length());
String md4 = md5Digest("aacdefghijklmnopqrstuvwxyz");
System.out.println(md4 + ",md5长度为" + md4.length());
md4 = sha1Digest("aacdefghijklmnopqrstuvwxyz");
System.out.println(md4 + ",sha1长度为" + md4.length());
String md5 = md5Digest("");
System.out.println(md5 + ",md5长度为" + md5.length());
md5 = sha1Digest("");
System.out.println(md5 + ",sha1长度为" + md5.length());
}看下输出结果,md5为32,而SHA-1为40明显长度更长,理论上SHA-1也是比MD5的安全性高一些
74b87337454200d4d33f80c4663dc5e5,md5长度为32
70c881d4a26984ddce795f6f71817c9cf4480e79,sha1长度为40
594f803b380a41396ed63dca39503542,md5长度为32
df51e37c269aa94d38f93e537bf6e2020b21406c,sha1长度为40
c3fcd3d76192e4007dfb496cca67e13b,md5长度为32
32d10c7b8cf96570ca04ce37f2a19d84240d3a89,sha1长度为40
67dd96962bfdd39c25ab439c4eb702bd,md5长度为32
1b008a08964e0c0acb12a291622696d734926e4b,sha1长度为40
d41d8cd98f00b204e9800998ecf8427e,md5长度为32
da39a3ee5e6b4b0d3255bfef95601890afd80709,sha1长度为40散列函数的雪崩效应
前面从2个方面讨论了散列哈希函数的特性,一个好的散列哈希函数至少需要满足
- 单向,逆向运算困难
- 散列,构造碰撞困难
比如,对于MD5加密,一个字符串"I am a md5 test str",展示一下它加密之后的字符串
1884bb9eec01695c4071075ae12c15e8然后再稍微改一下字符串"I an a md5 test str",展示一下它加密之后的字符串
bc4bc186df93caccc2c8c332a24d911a这2个字符串就差一个字符,边位置都没有变化,但是加密之后的字符串差异非常大,这种就是算法上雪崩效应,关于它的相关定义引用如下
雪崩效应(Avalanche Effect)是密码学算法一个常见的特点,指的是输入数据的微小变换,就会导致输出数据的巨大变化。严格雪崩效应是雪崩效应的一个形式化指标,我们也常用来衡量均匀分布。严格雪崩效应指的是,如果输入数据的一位反转,输出数据的每一位都有 50% 的概率会发生变化。
而这也是单向函数背后的一个基础特性。
此雪崩非彼雪崩
需要说明的是,这里雪崩跟常说的缓存雪崩是不同的,如果强行类比的话,都是牵一发而动全身,对于应用系统是要尽力避免缓存引起的雪崩效应,而散列算法是必须要具有这个特性
应用
在开头讨论的登录场景里,提到了密码存储问题。一般RMDB里面如果涉及存储密码,都是会通过MD5这种散列函数加密,而这就是散列函数的一个应用场景:用于密码管理
密码管理
对于用户密码管理,除了防止被黑客获取,直接拖库获得明文;也要防止管理员直接获取,所谓的监守自盗。所以一般密码存储都是散列函数加密存储,这样即使泄露,也不能直接获得明文导致泄露,因为即使得到了密文,基于单向的特性,要反向推算出明文非常困难,所以理论上这个难度系数足够大,甚至可以认为密文就是不可逆的,也就是安全的
而散列函数的另一大应用就是数据的完整性保证
怎么解决完整性问题?
什么是数据的完整性问题呢?完整性的核心是数据未经授权,不得更改。或者说被恶意更改了的数据能被认别,不被接受
从上面的雪崩例子可以看出,对于优秀的散列算法,对于数据的任意,微小的变动都会引起加密之后的字符串产生巨大的变化,从而可以利用这个特性来验证数据的完整性
数据发送方
- 确定加密的散列算法A,比如MD5
- 根据散列算法对待发送的数据D加密,得到散列值H
- 发送数据D,及对应的散列值H,一起发送给接收方{"data":"D","digest":"H"}
数据接收方
- 接收数据D,及对应的散列值H,{"data":"D","digest":"H"}
- 根据约定的算法MD5,对数据D进行加密,得到散列值H'
- 比如H与H'是否一致,不一致则视数据非法
数据发送方与接收方首先要约定好散列算法,比如MD5;数据传递队了原始数据之外,额外增加数据的散列值H来验证数据是否完整。
可以看出,完整性验证的步骤对接收方来说,就是发送方的反向操作
性能影响
但是如果多想一点,就会有疑问,这样多了加密与解密,是否会有额外的性能损耗?答案是肯定有的,而且无法避免,所以对性能的影响就落在了对加密算法的优化及具体应用的使用上:比如选择速度快,加密之后散列值体积小的算法,及只对关键信息加密等
API加验签
其实刚才的完整性验证严格来说,是有一定的安全漏洞的,问题在于数据传输过程中的中间人攻击,如下
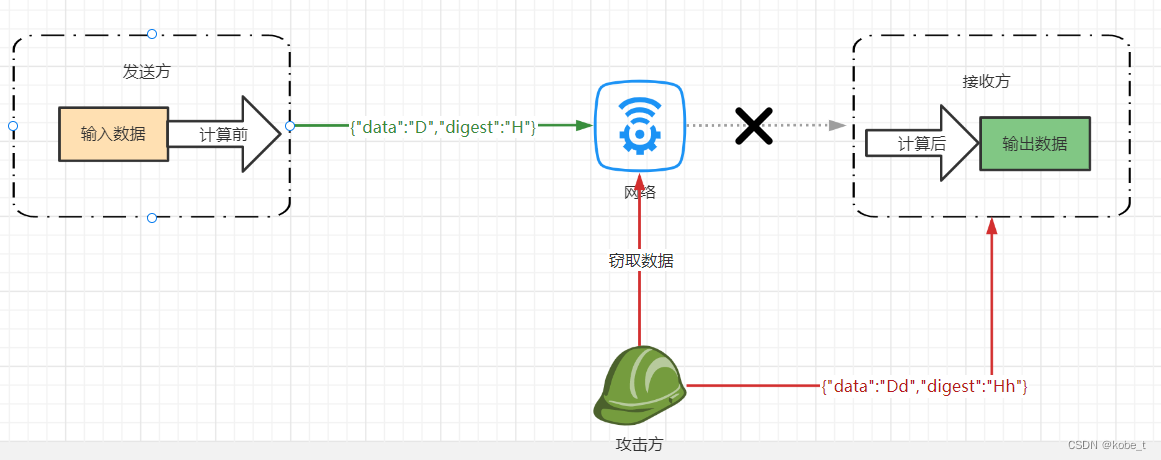
数据发送方
- 确定加密的散列算法A,比如MD5
- 根据散列算法对待发送的数据D加密,得到散列值H
- 发送数据D,及对应的散列值H,一起发送给接收方{"data":"D","digest":"H"}
但是这里如果有安全攻击,并不会像上面的正常的发送数据接收方,因为在网络环境中,传输过程不一定是安全的。这个时候如果有黑客进行数据窃取,拿到了发送的方的数据,进行数据替换
- 窃取发送方数据{"data":"D","digest":"H"}
- 更改数据data内容为Dd,根据Dd生成新的散列值Hh(假设算法也被窃取)
- 发送数据给接收方,{"data":"Dd","digest":"Hh"}
这个时候可怕的事情就会出现了
数据接收方
- 接收数据Dd,及对应的散列值Hh,{"data":"D","digest":"H"}
- 根据约定的算法MD5,对数据Dd进行加密,得到散列值Hh
- 比如H与Hh是否一致,一致进行了更新
那么错误的数据就会被接受并被执行,如果是转账等场景是非常危险,所以针对这种特殊场景,对算法加密必须加上特定的盐,在下一节单独介绍一下,一般API调用的加验签做方法














 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









