






原文:https://exitcondition.com/install-hadoop-windows/
文章目录
介绍
您可以通过多种方式在Windows上安装Hadoop,但是大多数方法都需要安装虚拟机或使用Docker容器在其上运行Cloudera或HDP映像。尽管这些方法有效,但它们需要相当高的硬件配置。在本文中,我们制定了详细的分步指南,以在轻量级Windows机器上设置和配置Hadoop,以及将本地文件放入HDFS的小规模演示。
这篇文章介绍了使用二进制文件在Windows 10上安装Hadoop 2.9.1的步骤。您也可以使用其源代码在本地计算机上安装Hadoop 。它要求使用Apache Maven和Windows SDK构建源。我们将在以后的一篇文章中介绍该方法。
分步指南
我们将在此处执行许多步骤,因此我建议您花一些时间,非常耐心地仔细地执行这些步骤。手动步骤很多,任何遗漏都会导致失败或学习机会,具体取决于您看到的杯子是半满还是半空。振作起来!
下载Hadoop 2.9.1二进制文件
要下载二进制文件,请访问Apache.org并搜索Hadoop 2.9.1二进制文件,或单击此处直接转到下载页面。您应该获得hadoop-2.9.1.tar.gz文件。
出于许多明显的原因,您可能希望适当地组织安装。因此,创建一个单独的文件夹,在其中您将解压缩二进制文件。在这篇文章中,我们将创建’C:/BigData/hadoop-2.9.1’文件夹并进一步引用它,但是您可以选择任何适合自己的选项。
文件夹名称中不要留空格。如果文件夹中有空格,则某些变量将无法正确扩展。
在C:/ BigData /中解压缩tar.gzHadoop-2.9.1文件夹。如果您没有解压缩tar.gz的软件,则可以下载7-zip 。请注意,某些标准的解压缩软件可能会产生“路径太长”错误。解决这些错误的方法之一是使用标准tar软件包安装Cygwin,然后运行“ tar –xvfWindows / Cygwin命令提示符下的<文件名>”。二进制文件解压缩后,您应该会看到以下文件和文件夹。
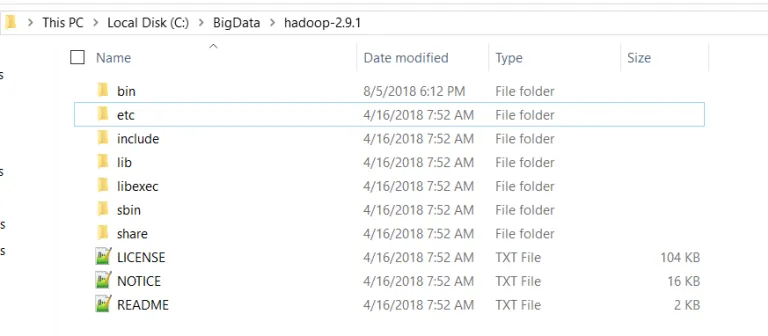
下载Windows兼容的二进制文件
转到此GitHub Repo并下载zip 格式的bin文件夹,如下所示。解压缩该zip并将bin文件夹下存在的所有文件复制到C:\ BigData \ hadoop-2.9.1 \ bin。也替换现有文件。
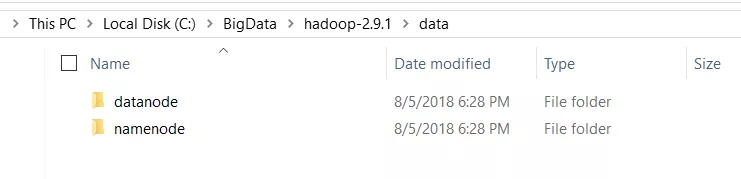
为datanode和namenode创建文件夹
转到C:/BigData/hadoop-2.9.1并创建一个文件夹“数据”。在“ data”文件夹中,创建两个文件夹“ datanode”和“ namenode”。HDFS上的文件将位于datanode文件夹下。
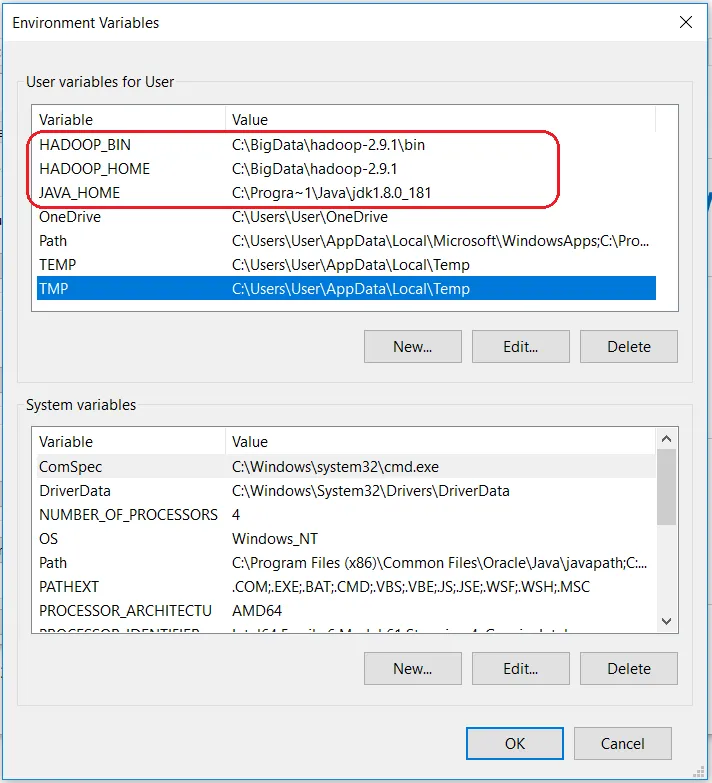
设置Hadoop环境变量
Hadoop需要设置以下环境变量。
HADOOP_HOME =” C:\ BigData \ hadoop-2.9.1”
HADOOP_BIN =” C:\ BigData \ hadoop-2.9.1 \ bin”
JAVA_HOME = <JDK安装的根目录>”
要设置这些变量,请导航至“我的电脑”或“此电脑”。右键单击->属性->高级系统设置->环境变量。在这里插入图片描述单击新建创建一个新的环境变量。
如果您尚未安装JAVA 1.8,则需要先下载 并安装。如果已经设置了JAVA_HOME环境变量,则检查路径中是否有空格(例如:C:\ Program Files \ Java \…)。JAVA_HOME路径中的空格将导致您遇到问题。有一个解决方法。将变量值中的“ 程序文件 ” 替换为“ Progra〜1 ”。确保Java版本为1.8,并且JAVA_HOME指向JDK 1.8。
编辑PATH环境变量
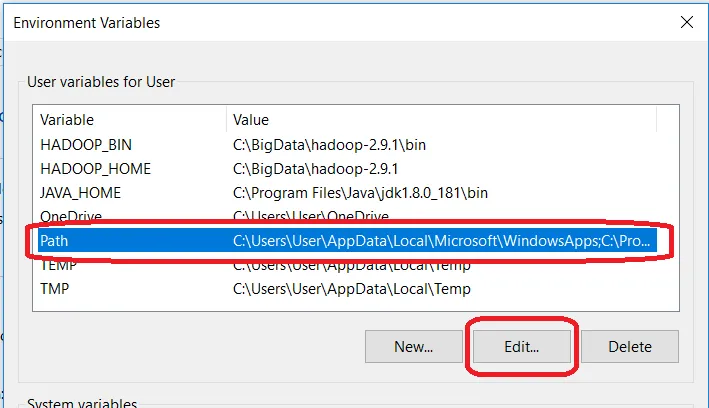
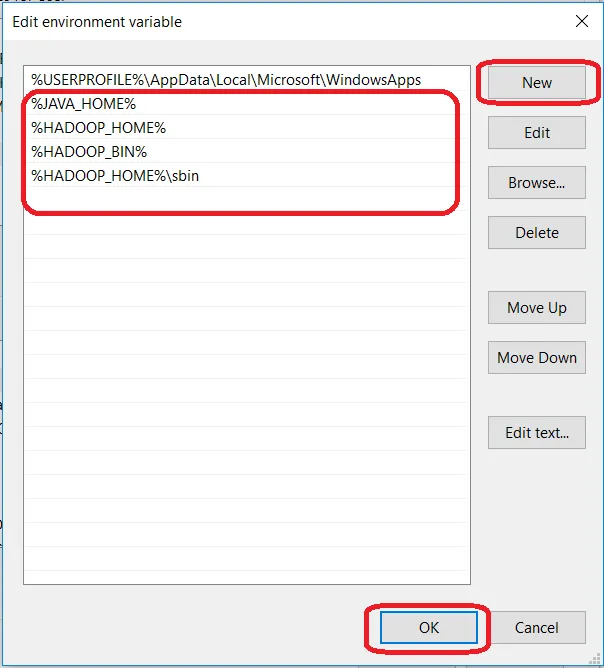
单击“新建”,然后将%JAVA_HOME%,%HADOOP_HOME%,%HADOOP_BIN%,%HADOOP_HOME%/ sbin一一添加到您的PATH。
现在我们已经设置了环境变量,我们需要验证它们。打开一个新的Windows命令提示符,并对每个变量运行echo命令,以确认已为它们分配了所需的值。
echo %HADOOP_HOME%
echo %HADOOP_BIN%
echo %PATH%
如果尚未初始化变量,则可能是因为您正在旧会话中对其进行测试。确保您打开了新的命令提示符以对其进行测试。
配置Hadoop
设置环境变量后,我们需要通过编辑以下配置文件来配置Hadoop。
hadoop-env.cmd
core-site.xml
hdfs-site.xml
mapred-site.xml
编辑hadoop-env.cmd
首先,让我们配置Hadoop环境文件。打开C:\ BigData \ hadoop-2.9.1 \ etc \ hadoop \ hadoop-env.cmd并在底部添加以下内容
set HADOOP_PREFIX=%HADOOP_HOME%
set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop
set YARN_CONF_DIR=%HADOOP_CONF_DIR%
set PATH=%PATH%;%HADOOP_PREFIX%\bin
编辑core-site.xml
现在,配置Hadoop Core的设置。打开C:\ BigData \ hadoop-2.9.1 \ etc \ hadoop \ core-site.xml并在 </ configuration>标记内的内容下方打开。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:19000</value>
</property>
</configuration>
编辑hdfs-site.xml
编辑core-site.xml之后,您需要设置复制因子以及namenode和datanode的位置。打开C:\ BigData \ hadoop-2.9.1 \ etc \ hadoop \ hdfs-site.xml并在 </ configuration>标记内的内容下方打开。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>C:\BigData\hadoop-2.9.1\data\namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>C:\BigData\hadoop-2.9.1\data\datanode</value>
</property>
</configuration>
编辑mapred-site.xml
最后,让我们为Map-Reduce框架配置属性。打开C:\ BigData \ hadoop-2.9.1 \ etc \ hadoop \ mapred-site.xml并在 </ configuration>标记内的内容下方打开。如果看不到mapred-site.xml,请打开mapred-site.xml.template文件并将其重命名为mapred-site.xml
<configuration>
<property>
<name>mapreduce.job.user.name</name>
<value>%USERNAME%</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.apps.stagingDir</name>
<value>/user/%USERNAME%/staging</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>local</value>
</property>
</configuration>
检查是否存在C:\ BigData \ hadoop-2.9.1 \ etc \ hadoop \ slaves文件,如果没有,则创建一个并在其中添加localhost并保存
格式名称节点
要格式化名称节点,请打开一个新的Windows命令提示符并在命令下方运行。它可能会给您一些警告,请忽略它们。
hadoop namenode -format
启动Hadoop
幸运的是,设置和配置Hadoop的难点已经过去。大!现在,让我们直接进入好部分,即在您的计算机上启动Hadoop。
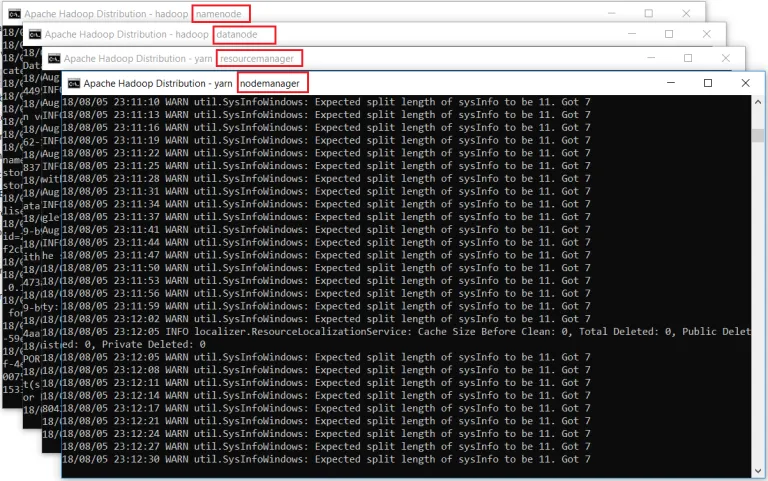
打开一个新的Windows命令提示符,请确保以管理员身份运行它,以避免权限错误。打开后,执行start-all.cmd命令。由于我们已将%HADOOP_HOME%\ sbin添加到PATH变量,因此您可以从任何文件夹运行此命令。如果尚未执行此操作,请转到%HADOOP_HOME%\ sbin文件夹并运行命令。

它将为4个守护进程打开4个新的Windows cmd终端,即namenode,datanode,nodemanager和resourcemanager。不要关闭这些窗口,将它们最小化。关闭窗口将终止守护程序。如果您不喜欢,可以在后台运行它们至 看到这些窗口。
Hadoop Web用户界面
最后,让我们监视一下Hadoop守护进程的运行情况。更不用说您可以使用Web UI进行各种管理和监视。打开浏览器并开始使用。
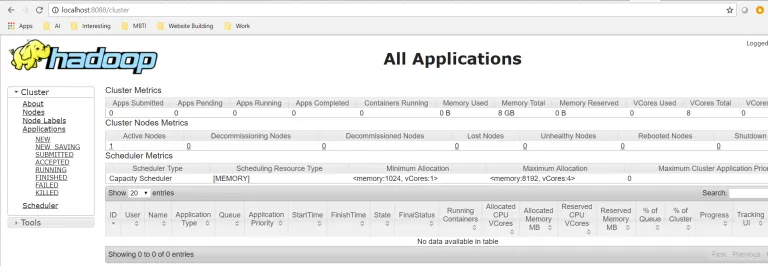
资源经理
打开localhost:8088以打开资源管理器
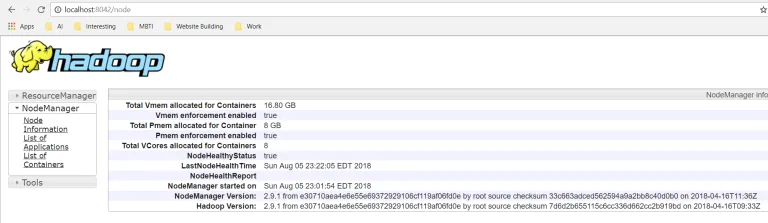
节点管理器
打开localhost:8042以打开节点管理器
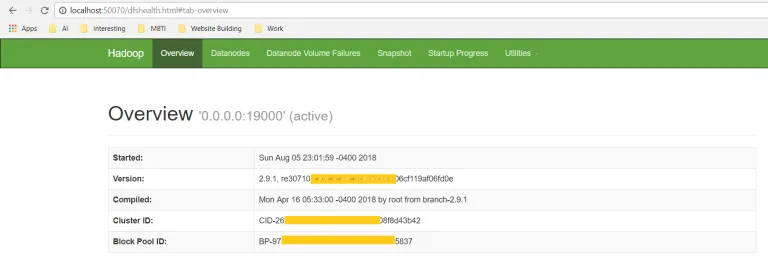
名称节点
打开localhost:50070以检查Name Node的运行状况
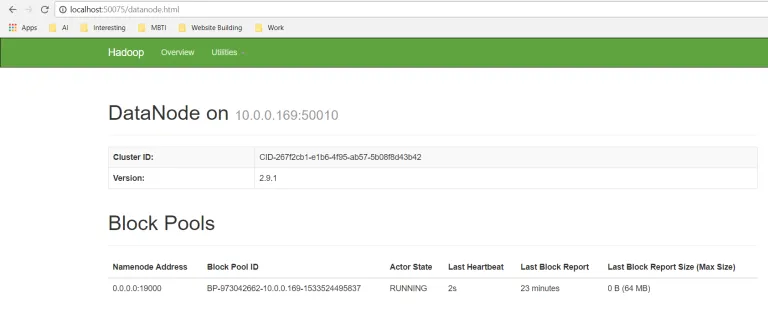
数据节点
打开localhost:50075签出数据节点
最后,使用HDFS
最后,我们将使用hdfs命令行工具将一个小文件放入HDFS。更不用说,有很多方法可以将数据导入HDFS。诸如Apache Sqoop,Flume,Kafka,Spark之类的工具是众所周知的。如果您想尝试Apache Spark并读写Json或Parquet文件,则可以参考此逐步指南Apache Spark入门。
打开一个新的Windows命令提示符并运行以下命令。我已经在本地文件系统中创建了sample.txt测试文件。
hdfs dfs -ls /
hdfs dfs -mkdir /test
hdfs dfs -copyFromLocal Sample.txt /test
hdfs dfs -ls /test
hdfs dfs -cat /test/Sample.txt














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









