










我将用俩个docker的mysql容器做讲解,不会docker也不要紧,你就把“容器”理解为一台有mysql环境的虚拟机。也可以看我写的docker系列。
下载mysql5.7镜像
# docker pull mysql:5.7
启动俩个mysql容器
# docker run --name db1 -v /dockerdata/mysql/db1:/var/lib/mysql -e MYSQL_ROOT_PASSWORD='password' -d -p 3000:3306 mysql:5.7
# docker run --name db2 -v /dockerdata/mysql/db2:/var/lib/mysql -e MYSQL_ROOT_PASSWORD='password' -d -p 3001:3306 mysql:5.7
此时,外部访问db1的端口为3000,db2的端口为3001。
连接账户都是root,密码均为password。
查看容器是否启动
# docker ps

里面每一行就是这样的开启了的虚拟机

好了,docker和虚拟机的相似性后面就不讲了。
进入容器内mysql控制台
# docker exec -it 容器id bash
# mysql -uroot -ppassword
在db1容器新建一个数据库和一张test表,表内有id和name字段。
mysql> create database db1;
mysql> use db1
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
切换至db2容器
mysql> create database db2;
mysql> use db2
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
接下来,需要修改三个文件,这三个文件互有关联。都在mycat的conf目录下。分别是:
| 文件名 | 文件作用 |
|---|---|
| server.xml | 配置登录和一些参数 |
| schema.xml | 数据库和表的配置 |
| rule.xml | 分片规则的配置 |
打开server.xml
我们只要看底部的就行了,其它的默认。这个文件在这篇文章里不需要修改。

user标签属性
name:登录mycat的账户名
property name="password":登录mycat的密码
property name="schemas":数据库名,这里会和schema.xml中的配置关联,多个用逗号分开。
打开schema.xml

schema标签
用来定义mycat实例中的逻辑库
table标签属性
name:表名,物理数据库中表名
dataNode:表存储到哪些节点,多个节点用逗号分隔
primaryKey:主键字段名,自动生成主键时需要设置
autoIncrement:是否自增
rule:分片规则名
type:逻辑表的类型,目前逻辑表只有全局表和普通表。全局表: global 普通表:无。全局表查询任意节点,普通表查询所有节点效率低。
childTable标签属性
name:子表名
primaryKey:主键
joinKey:指定子表关联的字段
parentKey:指定父表关联的字段

datanode标签属性
定义了mycat中的数据节点,也就是数据分片。一个datanode标签就是一个独立的数据分片。
name:定义数据节点的名字,这个名字需要唯一。我们在table标签上用这个名字来建立表与分片对应的关系。
dataHost:用于定义该分片属于哪个数据库实例,属性与下面的datahost标签属性上定义的name对应。
database:用于定义该分片属于数据库实例上的具体库。
dataHost标签属性
这个标签直接定义了具体数据库实例,读写分离配置和心跳语句。
name:唯一标示dataHost标签,供上层使用
maxCon:指定每个读写实例连接池的最大连接。
minCon:指定每个读写实例连接池的最小连接,初始化连接池的大小。
balance:负载均称类型。
0:不开启读写分离机制,所有读操作都发送到当前可用的writeHost上
1:全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1-S1,M2-S2 并且M1 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡。
2:所有读操作都随机的在writeHost、readHost上分发
3:所有读请求随机的分发到writeHst对应的readHost执行,writeHost不负担读写压力。
writeType :负载均衡类型。
0:所有的写操作发送到配置的第一个writeHost,第一个挂了切换到第二个。切换记录在文件dnindex.properties
1:所有的鞋操作都随机的发送到配置的writeHost,1.5以后版本废弃不推荐。
dbType:指定后端链接的数据库类型目前支持二进制的mysql协议。
dbDriver:指定连接后段数据库使用的driver。
heartbeat标签
这个标签内指明用于和后端数据库进行心跳检查的语句。 mysql使用 select user()。
writeHost标签指定写实例。readHost标签,指定读实例。
host:用于标识不同实例。
url:后端实例连接地址。
user:后端存储实例需要的用户名字。
password :后端存储实例需要的密码。
配置修改
把里面原有的注释先去掉,再排版。看起来就很舒服了。现在,我们进行修改。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="test" primaryKey="id" dataNode="dn1,dn2" rule="mod-long" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost2" database="db2" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.247.140:3000" user="root" password="password" />
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.247.140:3001" user="root" password="password" />
</dataHost>
</mycat:schema>
打开rule.xml

tableRule标签属性
name:属性指定唯一的名字,用于标识不同的表规则。
columns:指定要拆分的列名。
algorithm:使用下方function标签中的name属性。

function标签属性
name:指定算法的名字。
class:指定路由算法具体的类名字。
property:为具体算法需要用到的一些属性。
修改rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long"
class="io.mycat.route.function.PartitionByMod">
<!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="count">2</property>
</function>
</mycat:rule>
io.mycat.route.function.PartitionByMod为取模法,根据id与count(节点数)进行求模运算,从而将数据均匀的分布于各节点上。
还有其它的一些分片规则这里先不讲。分片规则用于设置数据以什么方式去存储到不同的节点上。
启动
# cd /usr/local/mycat/bin/
# ./mycat start
等一分钟,开启有点慢。报ERROR 2003 (HY000): Can't connect to MySQL server on '192.168.247.140' (111)就是还没启动完毕
# mysql -h ip地址 -uroot -p123456 -P8066
mysql> show databases;
mysql> use TESTDB
mysql> INSERT INTO test (id,name)VALUES ('1','weikaixxxxxx');
mysql> INSERT INTO test (id,name)VALUES ('2','weikaixxxxxx');
mysql> INSERT INTO test (id,name)VALUES ('3','weikaixxxxxx');
mysql> INSERT INTO test (id,name)VALUES ('4','weikaixxxxxx');
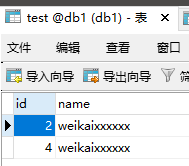
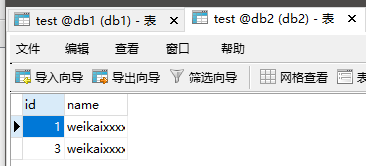
通过id,插入了不同的库。
查询
mysql> select * from test;
不过有个缺陷,就是如果增加操作不提供id就无法插入。这在实际项目中肯定是不行的。
所以需要使用全局序列号来实现表自增ID。
全局序列号有三种方式
本地文件方式:0
数据库方式:1
本地时间戳方式:2
这里采用的是本地文件方式。
打开server.xml
修改name属性为sequnceHandlerType的值

conf目录下的sequence_conf.properties是配置文件。在下面添加

TEST:表名,作为后缀,请看下方的添加操作
HISIDS:表示使用过的历史分段,一般无特殊需要可不配置
MINID:最小id值
MAXID:最大id值
CURID:当前id值,这个值会随添加的id而变化,添加数据后再查看吧。
重启,等待启动的时间去清空db1和db2的数据表
# ./mycat restart
测试添加操作
# mysql -h ip地址 -uroot -p123456 -P8066
mysql> show databases;
mysql> use TESTDB
mysql> INSERT INTO test (id, name)VALUES (next value for MYCATSEQ_TEST, 'weikaixxxxxx1');
mysql> INSERT INTO test (id, name)VALUES (next value for MYCATSEQ_TEST, 'weikaixxxxxx2');
mysql> INSERT INTO test (id, name)VALUES (next value for MYCATSEQ_TEST, 'weikaixxxxxx3');
mysql> INSERT INTO test (id, name)VALUES (next value for MYCATSEQ_TEST, 'weikaixxxxxx4');
语法上的不同就是把输入的id值换成next value for MYCATSEQ_TEST,后面的TEST就是我们在配置文件里配置的。
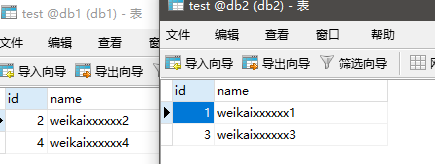
再查看配置文件sequence_conf.properties
排版变了,不过还是可以找到的,记录值是现在的id4

你以为结束了?不!还没有,因为。。
来自官方的权威指南的说明

这个“重新发布后”自己理解吧,反正网上也没搜到。。以我的智商是理解不了的。
所以为了保险起见,改为数据库方式,上面那个也不是浪费时间,毕竟好理解。
数据库方式
在数据库中建立一张表,存放sequence 名称(name),sequence 当前值(current_value),步长(incrementint 类型每次读取多少个sequence,假设为K)等信息;
打开server.xml
name属性为sequnceHandlerType的改成1
在db2节点创建MYCAT_SEQUENCE表
节点任意,但是必须和下面的创建函数三个function在同一个节点。
DROP TABLE IF EXISTS `MYCAT_SEQUENCE`;
CREATE TABLE `MYCAT_SEQUENCE` (
`name` varchar(50) NOT NULL,
`current_value` int(11) NOT NULL,
`increment` int(11) NOT NULL DEFAULT '100',
PRIMARY KEY (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
name:sequence的名称
current_value:当前id。
increment:增长步长,可理解为mycat 在数据库中一次读取多少个sequence. 当这些用完后, 下次再从数据库中读取。
插入一条sequence
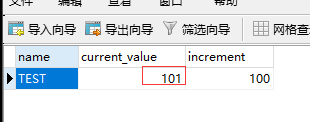
mysql> INSERT INTO MYCAT_SEQUENCE(name, current_value, increment) VALUES ('TEST', -99, 100);
为什么是-99?因为设置1的话是从101开始。
创建函数
现在仍然在刚才的db2节点mysql控制台,执行下面三个操作。
取当前squence的值(返回当前值,增量)
DROP FUNCTION IF EXISTS mycat_seq_currval;
DELIMITER $$
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50))RETURNS VARCHAR(64) CHARSET 'utf8'
BEGIN
DECLARE retval VARCHAR(64);
SET retval='-999999999,NULL';
SELECT CONCAT(CAST(current_value AS CHAR),',',CAST(increment AS CHAR)) INTO retval FROM
MYCAT_SEQUENCE WHERE NAME = seq_name;
RETURN retval;
END$$
DELIMITER ;
DELIMITER $$是把结束符’;‘换成’$$’,第二个DELIMITER ;是把结束符’$$‘换成’;’
END表示函数结束。然后DELIMITER把结束符恢复正常。
设置sequence值
DROP FUNCTION IF EXISTS mycat_seq_setval;
DELIMITER $$
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNS VARCHAR(64) CHARSET 'utf8'
BEGIN
UPDATE MYCAT_SEQUENCE SET current_value = VALUE WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END$$
DELIMITER ;
取下一个sequence的值
DROP FUNCTION IF EXISTS mycat_seq_nextval;
DELIMITER $$
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64) CHARSET 'utf8'
BEGIN
UPDATE MYCAT_SEQUENCE SET current_value = current_value + increment
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END$$
DELIMITER ;
打开conf目录下的sequence_db_conf.properties,和之前那个不同哦。
在尾部添加 TEST=dn2
TEST:添加到MYCAT_SEQUENCE表的name
dn2:节点名
清空db1和db2的数据表,重启mycat
# ./mycat restart
# mysql -h ip地址 -uroot -p123456 -P8066
mysql> use TESTDB
mysql> INSERT INTO test (id, name)VALUES (next value for MYCATSEQ_TEST, 'weikaixxxxxx1');
mysql> INSERT INTO test (id, name)VALUES (next value for MYCATSEQ_TEST, 'weikaixxxxxx2');
mysql> INSERT INTO test (id, name)VALUES (next value for MYCATSEQ_TEST, 'weikaixxxxxx3');
mysql> INSERT INTO test (id, name)VALUES (next value for MYCATSEQ_TEST, 'weikaixxxxxx4');
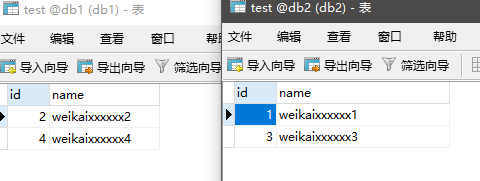
当添加的数据id为101时当前值才会变化














 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









