







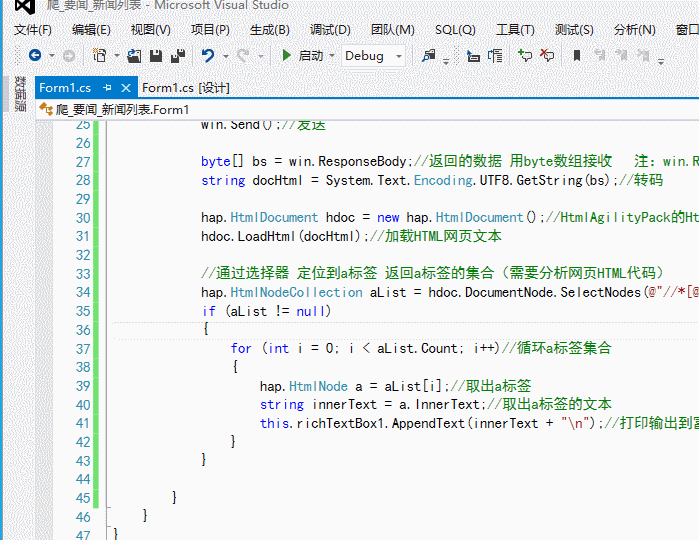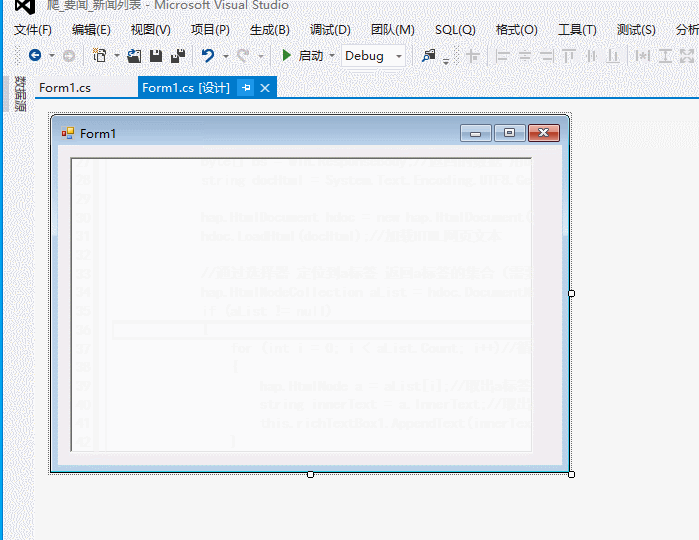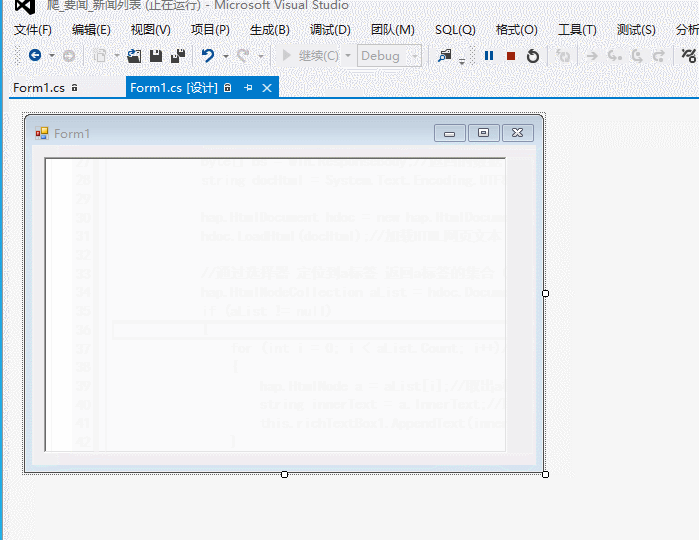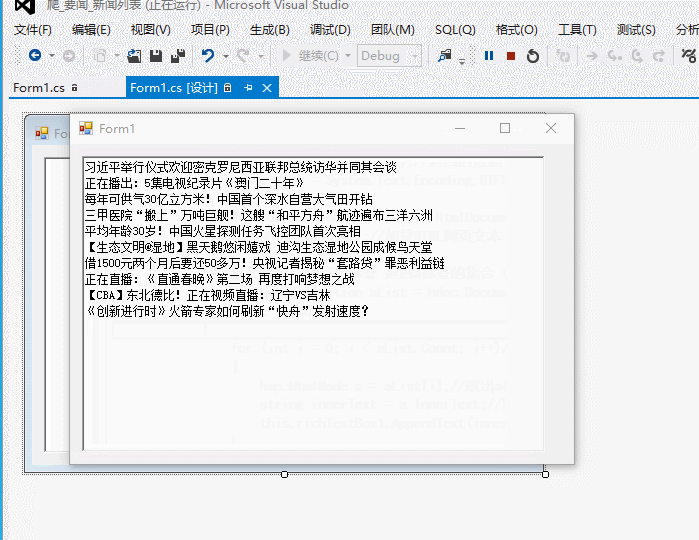
本次爬取的是央视网首页的轮播图的新闻标题列表!
【仅供C#爬虫的研究和学习】

using System;
using System.Collections.Generic;
using System.Windows.Forms;
using WinHttp;//必要的命名空间 添加引用:Com 项下的 Microsoft WinHTTP Services, version 5.1
using hap = HtmlAgilityPack;//必要的命名空间 (需下载HtmlAgilityPack.dll) 添加引用HtmlAgilityPack
using System.Web;//添加引用 程序集项下的System.Web;
namespace 爬_要闻_新闻列表
{
public partial class Form1 : Form
{
public Form1() { InitializeComponent(); }
private void Form1_Load(object sender, EventArgs e)
{
getNewTitleList();// 获取新闻标题列表
}
/// <summary>
/// 获取新闻标题列表
/// </summary>
void getNewTitleList()
{
WinHttpRequest win = new WinHttpRequest();//创建WinHttpRequest
win.Open("GET", "http://www.cctv.com/", false);//win.Oen("请求方式","请求地址",是否异步请求)
win.Send();//发送
byte[] bs = win.ResponseBody;//返回的数据 用byte数组接收 注:win.ResponseText直接输出有中文乱码的情况
string docHtml = System.Text.Encoding.UTF8.GetString(bs);//转码
hap.HtmlDocument hdoc = new hap.HtmlDocument();//HtmlAgilityPack的HtmlDocument的实例化
hdoc.LoadHtml(docHtml);//加载HTML网页文本
//通过选择器 定位到a标签 返回a标签的集合(需要分析网页HTML代码)
hap.HtmlNodeCollection aList = hdoc.DocumentNode.SelectNodes(@"//*[@id=""firstRotation""]//*[@class=""boxTitle""]//div//a");
if (aList != null)
{
for (int i = 0; i < aList.Count; i++)//循环a标签集合
{
hap.HtmlNode a = aList[i];//取出a标签
string innerText = a.InnerText;//取出a标签的文本
this.richTextBox1.AppendText(innerText + "\n");//打印输出到富文本框
}
}
}
}
}
运行效果















 1209
1209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









