







浏览器不管访问JSP、PHP还是ASP.NET,其流程几乎是一样的。
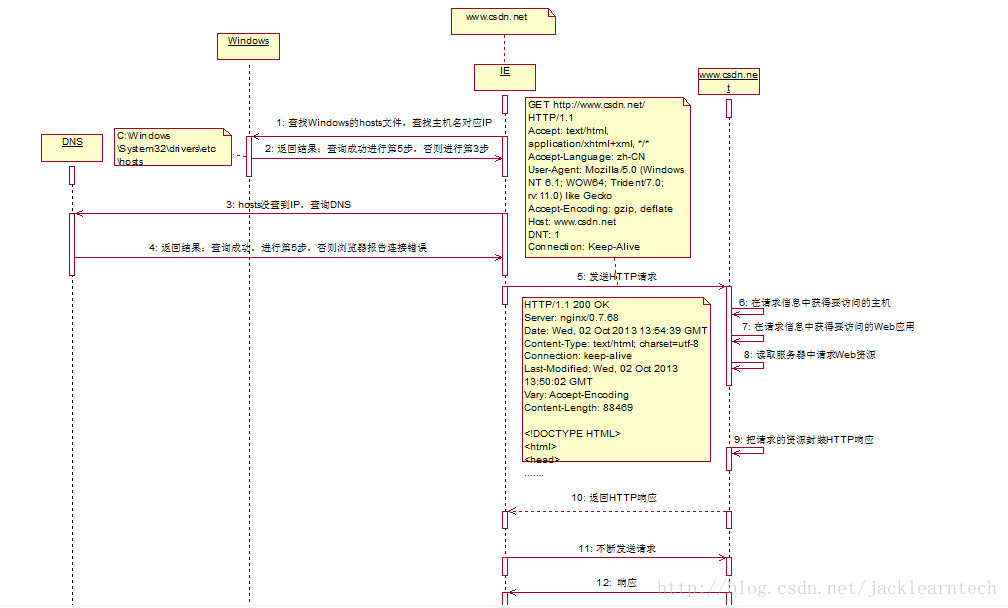
1.浏览器拿到URL后,会首先查找IP,两方面查找,①查询hosts文件,成功则直接进行第5步,无果②查询DNS,无果,返回错误。
2.浏览器发送HTTP请求
浏览器会把自身相关信息与请求相关信息封装成HTTP请求消息改送给服务器,这也不难理解,一些网站为什么可以知道你的浏览器类型了。

3.服务器处理请求
服务器会读取HTTP请求中的内容,然后查找相关资源,查找成功,返回状态码200,失败返回404,如http://www.csdn.net/fuck,这个资源是不存在的,故而返回了大名鼎鼎的404错误。你可能说了没找到,为什么还返回了页面,这是因为被服务器监测到请求不存在的资源后,会按照程序员设置的跳转到别的页面。

4.服务器返回HTTP响应

浏览器得到返回数据后可以会提取数据,然后调用解析内核进行翻译,最后显示出页面。
现在我们也就明白了不管是PHP的超全局数组还是JSP的内置对象,其中关于浏览器与服务器的信息都是在HTTP协议中获取的,而这个流程也是Web开发必备的基础。
说明
1. 当你在浏览器输入URL http://www.csdn.net的时候,浏览器发送一个Request去获取 http://www.csdn.net 的html首页. 服务器把Response发送回给浏览器.
2. 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如图片,CSS文件,JS文件。
3. 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
4. 等所有的文件都下载成功后。 网页就被显示出来了。
我可能写得不是很全,欢迎大家与我讨论,一起补全,成为最牛逼的Web资源请求流程文章。















 2404
2404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









