







1、补充强化知识点。使用Hibernate时我们需要自己创建数据库,表可以不创建,我们在配置文件中配置了类对应的表之后,程序运行后会帮我们自动创建表(尽管没有涉及到表的插入等操作,只要运行,配置文件就生效就创建表),但是这个自动创建的功能是否能发挥作用,全看是否有下面这个配置:
<property name="hbm2ddl.auto">update</property>2、Hibernate默认的是slf4j日志管理,但是Java开发人员更熟悉log4j的日志管理,如果我们希望把日志转变成我们之前基础的log4j的话:
——先构建Hibernate环境。导入主jar包,再导入required里的所有jar包,再导入jpa里的jar包,再创建一个实体类(比如User),配置User.hbm.xml文件,再配置hibernate.cfg.xml,再写Hibernate工具类,最后写一个空的测试类。接下来的工作是在此基础上使用Log4J。
——先导jar包。一个是log4j,一个是它俩之间转换的jar包。slf4j-api-1.6.1.jar我们之前在导入Hibernate必须要的jar包时就已经导入进来了。别忘了Build Path。
——然后在hibernate-distribution-3.6.10.Final\project\etc里面有一个log4j.properties放到src目录下。只保留下面这些就够了,表示开启控制台输出,也开启了文件日志输出(默认是注释掉的),我们更改一下日志文件存放路径。再修改一下log4j.rootLogger,修改日志级别是info(默认是warn),再把我们刚刚启动的日志文件输出添加进去,关键字就是key的最后面那个单词,就是file。
### direct log messages to stdout ###
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
### direct messages to file hibernate.log ###
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=e:/hibernate.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
### set log levels - for more verbose logging change 'info' to 'debug' ###
log4j.rootLogger=info, stdout, file
#log4j.logger.org.hibernate=info
log4j.logger.org.hibernate=debug——这个时候,我们运行程序后,发现在控制台的输出信息格式发生了变化,这就是我们在log4j.properties里面定义的输出格式,自己可以修改。然后我们在e盘下,发现有如下日志文件生成了。

3、一对一关系。要么在一方使用外键引用另一方。要么让双方的主键同步,也就是说双方的主键也是外键。
——Hibernate推荐的是主键同步策略。我们新建2个类Company和Address,分别配置类映射文件。双方都是one-to-one标签,但是在某一方需要把主键id设置关联一下另一个类。
//Company.hbm.xml
<hibernate-mapping package="com.hello.domain">
<class name="Company" table="t_company">
<id name="id" column="id">
<generator class="native"></generator>
</id>
<property name="name" column="name"></property>
<one-to-one name="address" class="Address"></one-to-one>
</class>
</hibernate-mapping>//Address.hbm.xml
<hibernate-mapping package="com.hello.domain">
<class name="Address" table="t_address">
<!-- 先把主键id设置成外键并且对应另一张表 -->
<id name="id" column="id">
<generator class="foreign">
<param name="property">company</param>
</generator>
</id>
<property name="name" column="name"></property>
<!-- 添加一个约束即可 -->
<one-to-one name="company" class="Company" constrained="true"></one-to-one>
</class>
</hibernate-mapping>——别忘了在hibernate.cfg.xml里面添加这2个类的映射配置文件。然后在测试类里面就可以使用插入查询等功能了。
// insert
// Company c=new Company();
// c.setName("Titac");
// Address a=new Address();
// a.setName("Beijing hello road");
// a.setCompany(c);
// openSession.save(c);
// openSession.save(a);
// query
Company c=(Company) openSession.get(Company.class, 1);
System.out.println(c.getAddress().getName());还有一种配置实在不想配置了,因为一对一关系在实际中使用较多,所以配置很少使用,再加上Hibernate已经推荐配置主键同步了,所以,不配置了。但是说一下基本原理吧:利用外键嘛,那当然是利用了多对一的那个思想,比如我们在Address配置文件中写many-to-one标签,然后添加一个unique="true"的属性,就是说我虽然是多对一的但是要唯一,也就相当于一对一了。然后在Company的配置文件中使用one-to-one标签,但是因为这是默认使用主键同步使用的标签,所以这个标签需要增加一个property-ref="company"属性,表示声明Company在对方类里面的属性名称。就这样。
4、二级缓存。
——之前说的一级缓存的Session属于线程级别的缓存,它是利用快照来减少数据库的查询次数以提交效率。它是Session与数据库之间的关系。
——今天说的二级缓存就是存在于Session与数据库之间的,SessionFactory控制的进程级别的二级缓存。缓存的好处是存取速度高、不需要连接数据库节约网络资源。放在缓存中的数据应该是经常被使用的而且不经常修改的。
——实际开发中二级缓存的使用并不高,因为还有三级缓存。二级缓存有时候直接存放的时一些比较死的数据,比如国家省市数据,用于前台显示的时候取数据用,相当于把数据库中的这些数据放到了二级缓存中,以后用的时候直接从二级缓存拿。
——Hibernate只提供了二级缓存的接口,具体实现需要导入第三方的jar包。
——二级缓存中的并发策略,也相当于是隔离级别:transactional(事务性,相当于Repeatable read)、read-write(读写型,相当于read committed)、nonstrict-read-write(非严格读写型)、read-only(只读型,适用于从来不会修改的数据,如果被修改了就会报错)。效率是从低到高。
——二级缓存的提供商,也就是实现二级缓存接口的,包括EHCache、openSymphony、 SwarmCache和JBossCache,这4家全都支持read-only,但是其他几种支持不一。
——配置二级缓存的步骤。
- 第一步,添加3个jar包,并且build path。
- 第二步,在
hibernate.cfg.xml里面添加配置说我要使用二级缓存了,并且告诉Hibernate使用的是哪家的二级缓存,这些配置信息都在hibernate.properties里面可以找到,我们用的是EHCache二级缓存供应商。
<property name="hibernate.cache.use_second_level_cache">true</property>
<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property>- 第三步,指定我们需要缓存的内容,内容包括类缓存、集合缓存、查询缓存(HQL)、时间戳缓存。我们先使用类缓存,就是把查询类的时候放到二级缓存里面去。仍然是在
hibernate.cfg.xml里面,但写在哪里?我们鼠标放到session-factory标签上可以看到些在mapping后面。

<class-cache usage="read-only" class="com.hello.domain.User"/>- 最后一步就是验证这个类是否放到二级缓存里。因为一级缓存的存在,所以我们验证的时候查询了一个类之后立即清空一级缓存,然后再次获取这个类,如果不打印SQL语句,说明没有去数据库去,而是去了二级缓存取。这样就能说明二级缓存的存在了。利用断点可以测试。并且如下代码打印结果是false,说明在二级缓存里面存的不是一个对象,而是对象的散列,它需要用的时候,就拿出来在一级缓存里面封装成对象。
User u1=(User) openSession.get(User.class, 1);
openSession.clear();
User u2=(User) openSession.get(User.class, 1);
System.out.println(u1==u2);5、接上一小节,集合缓存。那些导jar包等操作是不变的,只是在hibernate.cfg.xml里面配置类缓存的那一地方修改成配置集合缓存。
——我们下面可见,虽然我们配置了Customer里面的orders集合,在最后一行。但是我们仍然需要配置相应的Order类缓存,第2行。
<class-cache usage="read-only" class="com.hello.domain.Customer"/>
<class-cache usage="read-only" class="com.hello.domain.Order"/>
<collection-cache usage="read-only" collection="com.hello.domain.Customer.orders"/>——我们测试的时候依然是,先做一遍操作,然后清空一级缓存,再操作一遍看看是否有SQL语句产生。
Customer c1=(Customer)openSession.get(Customer.class,1);
for(Order o:c1.getOrders()){
System.out.println(o.getName());
}
openSession.clear();
Customer c1=(Customer)openSession.get(Customer.class,1);
for(Order o:c1.getOrders()){
System.out.println(o.getName());
}——如果我们在配置集合缓存的时候不配置Order的类缓存,那么在第二次缓存查询的时候,还是会去查询Order。这个时候我们如果看这个查询语句,可以发现它是以Order的id去查询的。所以我们这里需要了解的知识是,集合时以什么样的形式存在二级缓存中的?集合缓存就是把集合里每个Order的id存放在二级缓存里面,这样当我们通过Customer再次查询orders的时候,我们就拿到了所有Order的id,然后根据这些id看看类缓存里面有没有这个Order,如果有(就是我们添加了Order类缓存配置的情况),那么第二次就不会有查询order的SQL语句,如果没有,它就拿着这个id继续去数据库里面查询所以就有了第二次的SQL语句输出。所以我们在配置集合缓存的时候一定要记住配置对应的类缓存,不然在仍然需要查询数据库的话效率没有得到有效提高,还无故增加了二级缓存这个环节,得不偿失,所以既然要配置使用二级缓存,就要尽量减少对数据库的查询。
6、查询缓冲。
——第一步,在hibernate.cfg.xml里面增加如下配置,这个和使用二级缓存不是同一个key,需要重新增加一个如下的key-value。
<property name="hibernate.cache.use_query_cache">true</property>——第二步,上面只是开启了查询缓存,但是在使用的时候需要说明使用查询缓存。需要注意的是查询缓存针对的是HQL,所以使用的时候对createQuery有效。
Query createQuery = openSession.createQuery("from User");
//这个HQL使用查询二级缓存
createQuery.setCacheable(true);
List<User> list = createQuery.list();
openSession.clear();
Query createQuery2 = openSession.createQuery("from User");
//这个HQL使用查询二级缓存
createQuery2.setCacheable(true);
List<User> list2 = createQuery2.list();——我们在使用createQuery.setCacheable(true);的时候,其实意思是说,先在查询缓存区里面找,如果没找到,那么就去数据库查询,并且把查询结果放在二级缓存里面,这样下一次使用的时候就可以不去数据库查直接使用二级缓存里面的查询缓存区了。
——还有一个需要注意的地方是,我们以上案例是在配置了User类缓存的基础上实验得。你通过集合缓存的原理,可以猜到,如果我们在查询缓存的案例里面如果取消掉配置User类缓存,那么第二次查询的时候,依然会去数据库去找每一个User。而且这个查询过程是根据id来的,所以自然而言的根据之前的经验可知,查询缓存区里面存放的数据可以很多的id,第二次查询的时候先拿到这些id,去类缓存里面去找,如果找到(比如我们配置了User类缓存)就不用去数据库了,如果找不到就还要去数据库查询。
7、时间戳缓存。是保证缓存的有效性的,也就是说我们使用二级缓存的时候它会和数据库的最后一次操作时间戳比对,如果不一致,那么说明二级缓存失效了,那么就会重新向数据库查询而不是直接使用二级缓存里面的 数据。
——做实验的话,就是先get查询一次,然后createQuery修改这条数据,清空一级缓存后,再get查询一次。会发现如果没有中间的那个修改的话第二次查询时没有SQL语句也就是不会查询数据库的,但是如果有中间那个修改,第二次查询时有SQL语句也就是说会去查询数据库的(因为时间戳不一致)。
8、二级缓存的其他配置。仅作了解。
——默认的配置是在jar包里可以找到,如下路径。
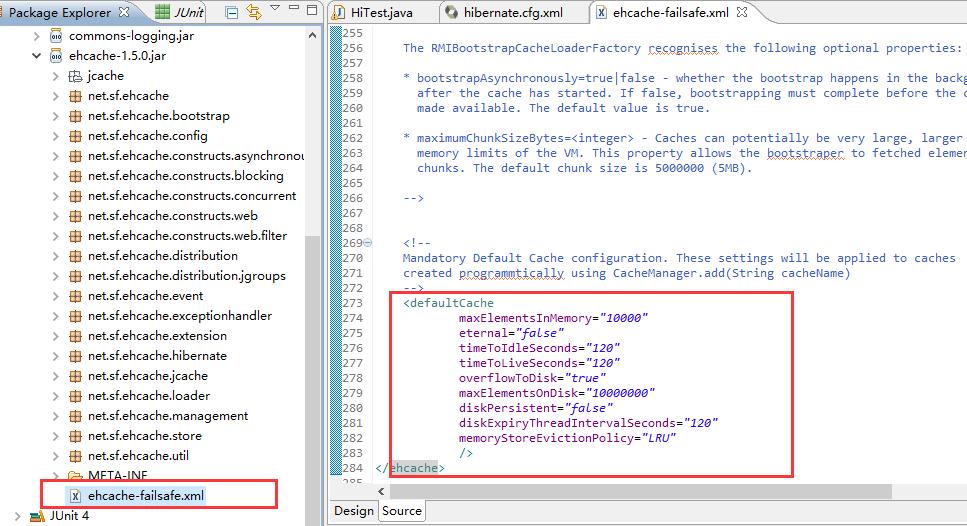
——我们需要配置的话,在src下新建一个ehcache.xml的文件即可,文件名以ehcache开头即可。然后把上面默认文件内容拷贝过来,删除注释后就只有下面这么多。
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="../config/ehcache.xsd">
<!-- 二级缓存存放路径,比如d:/haha.txt -->
<diskStore path="java.io.tmpdir"/>
<defaultCache
<!-- 最大的类缓存数量 -->
maxElementsInMemory="10000"
eternal="false"
<!-- 超过这个时间没被使用的话就销毁 -->
timeToIdleSeconds="120"
<!-- 最多存活时间,需要≥上面的时间 -->
timeToLiveSeconds="120"
<!-- 过载后是否写入硬盘文件中去 -->
overflowToDisk="true"
<!-- 往硬盘上写的最大对象数量 -->
maxElementsOnDisk="10000000"
<!-- 是否持久化?当是false的时候就不持久化,也就是虚拟机关闭后删除了在硬盘上的对象 -->
diskPersistent="false"
<!-- 轮询时间,轮询的内容是是否有过期的对象是否有要写入硬盘等事情 -->
diskExpiryThreadIntervalSeconds="120"
<!-- 当缓存满之后有新的进来时的策略,LRU(最近最少使用的移除)LFU(最不常使用)FIFO(先进先出) -->
memoryStoreEvictionPolicy="LRU"
/>
</ehcache>9、贴吧案例。
——我们在配置struts2和Hibernate的时候,双方都有如下这个jar包,我们删除一个版本低的,删除的时候最好是关闭这个项目,然后在Workspaces里面删除。然后再打开项目在lib目录上刷新一下即可,不然会有提示。

——别忘记导入连接MySQL驱动的jar包。
——配置好环境后,在HibernateUtil.java中写个主函数,以java程序运行一下,看看数据库是否可以创建这2个表,如果正常,那么说明配置是OK的。
public static void main(String[] args) {
System.out.println(openSession());
}——事务的问题。如果我们在DAO层开启和关闭事务的话,在页面显示数据的时候容易取不到数据,所以我们把事务的开启关闭范围扩大一下,借助过滤器,在过滤器的预处理时候开启,后处理的时候关闭(提交)。注意的是,系统帮我们在xml中配置的filter-mapping是放在主mapping后面的,我们需要把它放在主mapping前面,不然永远不会生效。
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
Session openSession = HibernateUtil.openSession();
openSession.beginTransaction();
try {
chain.doFilter(request, response);
if(openSession!=null && openSession.isOpen()){
openSession.getTransaction().commit();
}
} catch (Exception e) {
e.printStackTrace();
if(openSession!=null && openSession.isOpen()){
openSession.getTransaction().rollback();
}
}
}——把处理get请求参数乱码的filter拷贝到项目里来,还有一个Myrequst。
——把静态页面复制到Web-Root下。写动作类和dao。测试的时候几个jsp和html可能会报错,选中它们右击->MyEclipse->exclude from validation。















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









