




系列文章目录
文章目录
前言
前一章我们介绍 jpeg 编码原理的相关知识,本章则进入实战环节,手写 jpeg 解码器。
所有代码我已经放到了 github-simple_jpeg_decoder,你可以运行 tests 下单测,或者运行 main.cpp 来解码一个 jpeg 文件。
接下来是对整体解码流程的介绍,主要包含两个部分:JFIF文件解析和JEPG数据解码。
一、JFIF 文件解析
1.1 JFIF 文件介绍
JPEG本身只规定了图像的压缩算法和数据格式,并没有规定文件的封装结构,经过 JPEG 压缩后得到的比特流,需要存放在一个文件中,并且这个文件中还需要有其他额外信息,帮助我们进行解码,例如需要有图片的宽高、文件像素格式等等。
JFIF 全称是 JPEG File Interchange Format,即“JPEG文件交换格式”。JFIF 是在 JPEG 压缩的图像流之上,增加了简单的文件结构和元数据定义的一种文件格式。他定义了包括像素密度、图像宽高、颜色空间等信息的存储方式。
JFIF是一种JPEG文件的实现封装格式,在实际用途中,绝大多数以.jpg或.jpeg为后缀的图片其实就是“JPEG编码+JFIF封装”。
也就是说,常见的JPEG图片文件其实是“JFIF格式的JPEG图片”。
因此,我们解码 jpeg 文件时,首先要做的是解析 JFIF 文件,获取该文件中各个"段",这些段中有很多重要的信息,用这些信息可以进行 jpeg 比特流的解码。
2.1 JFIF 格式
JFIF 文件格式指定了对应于不同片段(segment)的标记(marker)。每个片段包含了解码图像所需信息的一部分。标记实际上就是两个字节(word)大小的数据,总是以字节 ff 开头,结尾则是一个取值不是 ff 或 00 的字节。下面表格中使我们需要关心的列表:
| Marker | Segment (English) | 中文含义 |
|---|---|---|
| ff d8 | Start of Image segment (SOI) | 图像开始标记段 |
| ff e0 | JPEG/JFIF Image segment (APP-0) | JPEG/JFIF 图像信息段 |
| ff fe | Comment segment (COM) | 注释段 |
| ff db | Define Quantization Table (DQT) | 定义量化表段 |
| ff c0 | Start of Frame-0 (SOF-0) | 帧开始标记0段 |
| ff c4 | Define Huffman Table (DHT) | 定义哈夫曼表段 |
| ff da | Start of Scan segment (SOS) | 扫描开始段 |
| ff d9 | End of Image segment (EOI) | 图像结束标记段 |
下面几个字段的顺序是固定要求的
- SOI
- APP-0
- SOS
- EOI
其他的字段,例如 COM、DQT 没有严格的顺序,但必须在 APP-0 和 SOS 之间。
此外,一些标记如APP-0、COM等在其后面紧跟着额外的数据,而像SOI和EOI这样的标记则是自包含的。
ff xx l1 l2 <payload>
在这里,前两个字节ff和xx描述标记,接着是两个字节l1和l2,描述标记后面载荷数据的长度。然后是实际的载荷数据,其长度正好等于字节l1和l2所指定的长度。
我们的解码器将只处理定义了SOF-0段的图像,因为SOF-0对应的是基线DCT JPEG图像。
接下来对每个段进行说明,并配上解析的代码。详细代码参考 sjpg_jfif_parser.h
2.1.1 SOI
Marker: ff d8
每个 JFIF 文件都以这个 marker 开头
static bool hasSOIMark(std::istream &stream) {
// 记录当前位置
unsigned char soi[2];
stream.read(reinterpret_cast<char *>(soi), 2);
bool result =
(stream.gcount() == 2 && soi[0] == JFIF_BYTE_FF && soi[1] == JFIF_SOI);
return result;
2.2.2 APP-0
| Bytes | 大小(字节) | 描述 |
|---|---|---|
ff e0 | 2 | APP-0 段标记 |
<byte> <byte> | 2 | 载荷长度 |
4a 46 49 46 00 | 5 | 字符串 “JFIF\0” |
<byte> <byte> | 2 | JFIF 版本(高字节为主版本号,低字节为次版本号) |
<byte> | 1 | 像素密度单位:00 无单位,01 像素/英寸,02 像素/厘米 |
<byte> <byte> | 2 | 水平像素密度(>0) |
<byte> <byte> | 2 | 垂直像素密度(>0) |
<byte> | 1 | 缩略图水平像素数(0 表示无缩略图) |
<byte> | 1 | 缩略图垂直像素数(0 表示无缩略图) |
<thumbnail-data> | 3 × 水平像素数 × 垂直像素数 | 未压缩 24 位 RGB 缩略图数据 |
void parseAPP0Segment(std::istream &stream) {
app0_ = std::make_unique<segments::APP0Segment>();
app0_->file_pos = stream.tellg();
app0_->length = StreamReader::read2BytesBigEndian(stream);
StreamReader::readTo(stream, app0_->identifier, 5);
app0_->major_version = StreamReader::readByte(stream);
app0_->minor_version = StreamReader::readByte(stream);
app0_->pixel_units = StreamReader::readByte(stream);
app0_->x_density = StreamReader::read2BytesBigEndian(stream);
app0_->y_density = StreamReader::read2BytesBigEndian(stream);
app0_->thumbnail_width = StreamReader::readByte(stream);
app0_->thumbnail_height = StreamReader::readByte(stream);
static constexpr int kRGBChannels = 3;
static constexpr int kRGBBits = 8; // 每个RGB通道8位
static constexpr int kRGBBytesPerPixel = kRGBChannels * (kRGBBits / 8);
const auto thumbnail_image_pixel_count =
app0_->thumbnail_width * app0_->thumbnail_height;
const auto thumbnail_data_length =
kRGBBytesPerPixel * thumbnail_image_pixel_count;
app0_->thumbnail_data.resize(thumbnail_data_length);
if (thumbnail_data_length > 0) {
StreamReader::readTo(
stream, reinterpret_cast<char *>(app0_->thumbnail_data.data()),
thumbnail_data_length);
}
app0_->print();
}
2.2.3 COM
| Bytes | 大小(字节) | 描述 |
|---|---|---|
ff fe | 2 | 注释段标记 |
<byte> <byte> | 2 | 载荷长度 |
<comment-data> | n | 实际注释数据,n = 上一步指定的长度 |
void parseCOMSegment(std::istream &stream) {
com_ = std::make_unique<segments::COMSegment>();
com_->file_pos = stream.tellg();
com_->length = StreamReader::read2BytesBigEndian(stream);
auto commentSize = com_->length - 2; // 减去长度字段的2个字节
com_->comment.resize(commentSize); // 减去长度字段的2个字节
StreamReader::readTo(stream, reinterpret_cast<char *>(com_->comment.data()),
commentSize);
com_->print();
2.2.4 DQT
| Bytes | 大小(字节) | 描述 |
|---|---|---|
ff db | 2 | DQT 段标记 |
<byte> <byte> | 2 | 段长度 𝑛(含 DQT 段标记) |
<byte> | 1 | 高 4 位:精度 𝑃𝑞(0 = 8 位,1 = 16 位) 低 4 位:量化表编号 𝑇𝑞 |
<quantization-table-data> | 64 | 量化表数据,按 Zig-zag 顺序排列的 64 个元素 |
void parseDQTSegment(std::istream &stream) {
// TODO: multiple table in a dqt segment
segments::DQTSegment dqt;
dqt.file_pos = static_cast<unsigned long>(stream.tellg());
dqt.length = StreamReader::read2BytesBigEndian(stream);
auto tmp = StreamReader::readByte(stream);
segments::QuantizationTable table;
table.precision = tmp >> 4;
table.id = tmp & 0x0F;
constexpr static int kQuantizationTableSize = 64; // 8x8 matrix
table.data.resize(kQuantizationTableSize);
StreamReader::readTo(stream, reinterpret_cast<char *>(table.data.data()),
kQuantizationTableSize);
dqt.tables.emplace_back(table);
dqt.print();
dqt_segments_.emplace_back(dqt);
auto &last_segment = dqt_segments_.back();
for (auto i = 0; i < last_segment.tables.size(); i++) {
auto table_id = last_segment.tables[i].id;
q_table_refs[table_id] = &last_segment.tables[i];
}
}
2.2.5 SOF-0
| Bytes | 大小(字节) | 描述 |
|---|---|---|
ff c0 | 2 | SOF-0 段标记 |
<byte> <byte> | 2 | 段长度 |
<byte> | 1 | 帧数据精度 |
<byte> <byte> | 2 | 图像高度(像素) |
<byte> <byte> | 2 | 图像宽度(像素) |
<byte> | 1 | 帧内分量数 n(RGB 图像通常为 3) |
<component-data> | 3 × n | 每分量 3 字节: – 第 1 字节:分量标识符 – 第 2 字节:采样因子(高 4 位=水平,低 4 位=垂直) – 第 3 字节:使用的量化表号 |
void parseSOF0Segment(std::istream &stream) {
sof0_ = std::make_unique<segments::SOF0Segment>();
sof0_->file_pos = stream.tellg();
sof0_->length = StreamReader::read2BytesBigEndian(stream);
sof0_->bitPerSample = StreamReader::readByte(stream);
sof0_->height = StreamReader::read2BytesBigEndian(stream);
sof0_->width = StreamReader::read2BytesBigEndian(stream);
sof0_->num_components = StreamReader::readByte(stream);
for (int i = 0; i < sof0_->num_components; i++) {
auto b0 = StreamReader::readByte(stream);
auto b1 = StreamReader::readByte(stream);
auto b2 = StreamReader::readByte(stream);
sof0_->component_id.push_back(b0);
sof0_->sampling_factor.push_back(b1);
sof0_->quantization_table_id.push_back(b2);
}
sof0_->print();
}
2.2.6 DHT
| Bytes | 大小(字节) | 描述 |
|---|---|---|
ff c4 | 2 | DHT 段标记 |
<byte> <byte> | 2 | 段长度(含标记) |
<byte> | 1 | 霍夫曼表信息:高 4 位 = 类型(0 = DC,1 = AC),低 4 位 = 表号 |
<symbol-count> | 16 | 各码长(1–16 位)的符号数量(共 16 字节) |
<symbols> | n | 符号数据,按码长顺序排列,共 n 个字节 |
void parseDHTSegment(std::istream &stream) {
auto dht = segments::DHTSegment();
dht.file_pos = static_cast<unsigned long>(stream.tellg());
dht.length = StreamReader::read2BytesBigEndian(stream);
auto b = StreamReader::readByte(stream);
dht.dc_or_ac = b >> 4;
dht.table_id = b & 0x0F;
static constexpr int kHuffmanTableSize = 16;
dht.symbol_counts.resize(kHuffmanTableSize);
StreamReader::readTo(stream,
reinterpret_cast<char *>(dht.symbol_counts.data()),
kHuffmanTableSize);
auto num_total_symbols =
std::accumulate(dht.symbol_counts.begin(), dht.symbol_counts.end(), 0);
dht.symbols.resize(num_total_symbols);
StreamReader::readTo(stream, reinterpret_cast<char *>(dht.symbols.data()),
num_total_symbols);
dht.print();
dht_segments_.emplace_back(dht);
}
2.2.7 SOS
| Bytes | 大小(字节) | 描述 |
|---|---|---|
ff da | 2 | SOS 段标记 |
<byte> <byte> | 2 | 段长度 |
<byte> | 1 | 分量数 n |
<component-data> | 2 × n | 每分量 2 字节:第 1 字节 = 分量 ID;第 2 字节 = 高 4 位 DC 霍夫曼表号,低 4 位 AC 霍夫曼表号 |
<skip-bytes> | 3 | 固定跳过字节 |
void parseSOSSegment(std::istream &stream) {
sos_ = std::make_unique<segments::SOSSegment>();
sos_->file_pos = static_cast<unsigned long>(stream.tellg());
sos_->length = StreamReader::read2BytesBigEndian(stream);
sos_->num_components = StreamReader::readByte(stream);
for (int i = 0; i < sos_->num_components; i++) {
auto b0 = StreamReader::readByte(stream);
auto b1 = StreamReader::readByte(stream);
sos_->component_id.push_back(b0);
auto huffman_table_id_dc = b1 >> 4;
auto huffman_table_id_ac = b1 & 0x0F;
sos_->huffman_table_id_ac.push_back(huffman_table_id_ac);
sos_->huffman_table_id_dc.push_back(huffman_table_id_dc);
}
// skip 3 bytes
for (int j = 0; j < 3; j++) {
StreamReader::readByte(stream);
}
sos_->print();
}
2.2.8 图像数据 和 EOI
在 SOS 段后,立马就是图像压缩后的比特流数据,接着是 EOI 端。因此在解析完 SOS 段后,里面开始读压缩数据:
parseSOSSegment(stream);
scanImageDataAndEOI(stream);
void scanImageDataAndEOI(std::istream &stream) {
for (;;) {
auto b = StreamReader::readByte(stream);
if (b == JFIF_BYTE_FF) {
auto next_b = StreamReader::readByte(stream);
if (next_b == JFIF_EOI) {
// build eoi segment
eoi_ = std::make_unique<segments::EOISegment>();
eoi_->file_pos = static_cast<unsigned long>(stream.tellg());
return;
}else {
// it is encoded data
encoded_data_.push_back(b);
}
}else {
encoded_data_.push_back(b);
}
}
注意代码中关于填充字节的处理,0xFF 字节被用作各种标记(marker)的起始标志。为了防止压缩数据中意外产生的 0xFF 被误认为是标记的起始,JPEG 标准规定:
- 如果在扫描数据中出现了 0xFF,就会在其后插入一个 0x00 字节(即 0xFF 0x00)。
- 这个 0x00 就是“填充字节”或者“填塞字节”。
二、JPEG 数据解码
2.1 比特流
解码是编码的逆过程,让我们先回忆下编码的过程,但这次逆着方向来,从比特流开始。
解析 JFIF 后,我们得到了一些段,另外最重要的就是一堆 01 组成的比特流数据,例如:
010001010101010101101......
JPEG 编码时最小单位是 MCU,因此这些比特流是按 MCU 编号来排列的,编码顺序是从左到右,然后从上到下,就像阅读文本一样。
假设一个图像被分割成多个8×8的块(MCU):
┌─────┬─────┬─────┬─────┐
│ MCU │ MCU │ MCU │ MCU │
│ 1 │ 2 │ 3 │ 4 │ ← 第一行
├─────┼─────┼─────┼─────┤
│ MCU │ MCU │ MCU │ MCU │
│ 5 │ 6 │ 7 │ 8 │ ← 第二行
├─────┼─────┼─────┼─────┤
│ MCU │ MCU │ MCU │ MCU │
│ 9 │ 10 │ 11 │ 12 │ ← 第三行
├─────┼─────┼─────┼─────┤
│ MCU │ MCU │ MCU │ MCU │
│ 13 │ 14 │ 15 │ 16 │ ← 第四行
└─────┴─────┴─────┴─────┘
编码顺序:1 → 2 → 3 → 4 → 5 → 6 → 7 → 8 → 9 → 10 → 11 → 12 → 13 → 14 → 15 → 16
因此这些比特流,也是按照 MCU 编码来排序的
100110 | 0110 | 10101011 | 110 | 00100101 | 1110
| | | | | |
MCU1 MCU2 MCU3 MCU4 MCU5 MCU6
每个 MCU 的比特流由两部分依次组成:
-
DC 系数编码(使用差分编码)
- Category 字段(哈夫曼编码,表示该差值的位宽)
- Bit representation 字段(该差值按 Category 指定的位宽进行的实际二进制表示)
-
AC 系数游程编码
逐个游程-幅值(run-length/value)进行编码,每个非零 AC 系数的编码都包含:- (Run/Category) 字段(哈夫曼编码,其中 Run 为前导 0 的数量,Category 为该非零 AC 的位宽,两者合成一个字节如 RRRRSSSS)
- Bit representation 字段(该 AC 系数经过 Category 位宽的实际二进制代码)
全部 AC 系数以 EOB(End-of-Block)标记终结。
这部分很绕,很复杂,也是解码过程中最麻烦的地方。首先我们要了解 Category 和 Bit representation 的概念。
2.2 Category 概念
在 JPEG 编解码中,Category(类别) 是指对 DCT 系数的幅值(绝对值)进行分组分类 的一个概念,主要用于 哈夫曼编码的设计。它是 JPEG 熵编码部分(尤其是 DC/AC 系数的编码)里的一个重要术语。
1. Category 的定义
- Category 表示一个系数幅值的范围(具体来说,是幅度的二进制位数)。
- 对于一个待编码的数值(比如 DPCM 后的 DC 差值或某个 AC 系数),Category = 该数字的最小二进制编码所需的位数。
2. 具体划分方式
- Category 0: 0
- Category 1: ±1
- Category 2: ±2, ±3
- Category 3: ±4 ~ ±7
- Category 4: ±8 ~ ±15
- Category 5: ±16 ~ ±31
- … 以此类推
3. 作用
JPEG 熵编码把 DCT 系数(DC/AC)拆成两部分编码:
Category(类别):通过哈夫曼编码对“类别号”进行编码。
Amplitude(幅值):用定长二进制补全实际值。
这样做可以利用系数幅值分布的特性,大多数系数绝对值较小,从而提高编码效率。
4. 与 JPEG 码流的关系
在 JPEG 码流里,DC 系数和 AC 系数的哈夫曼表其实对应的就是 category。
例如,(RUNLENGTH, CATEGORY) 作为 AC 系数编码的前缀(哈夫曼编码),category 也用于 DC。
简单来说,Category 就是指明“接下来你要读取几位比特(bit)” 来获得系数的实际数值。
2.3 Bit representation
Bit representation(JPEG 标准里常叫 additional bits、raw bits、或 appended bits)就是 在 Category 指明长度之后,紧跟的那一串原始比特,用来唯一地确定量化后系数的实际正负值。
长度由 Category 决定(1-10 位)。
内容是一个“带符号的变长整数”——最左位是符号位,需要按 JPEG 的约定再转成真正的有符号数。
所以:
- Category = “读几位”;
- Bit representation = “那几位到底长什么样”。
接下去我们需要将 Bit representation 转换为真正的数字,逻辑只有两步,记住“先还原无符号数,再转成有符号数”即可。
设额外读到的 bit 串为 B,长度为 L = Category。
- 把
B当无符号整数:V = uint(B)。 - 计算有符号值:
- 如果
V < 2^L - 1,则系数 =V - 否则 系数 =
V - (2^{L+1} - 1)
- 如果
一个更常用的等价写法(代码最直观):
if (B >= (1 << (L-1))) // 最高位为 1 → 正数
coeff = B;
else // 最高位为 0 → 负数
coeff = B - (1 << L) + 1;
举例
Category = 4,读到的 4 bit = 1011 (11)
11 < 15→ 系数 =11 - (2^4 - 1) = -4
这就是 JPEG 把 bit representation 变成真实 DCT 系数的全部逻辑。下面是具体代码逻辑
static int16_t decodeNumber(uint16_t code_length, const std::string &bits)
{
if (code_length == 0) return 0; // Category 0 时无附加位
uint16_t v = static_cast<uint16_t>(std::stoi(bits, nullptr, 2));
int16_t half = 1 << (code_length - 1); // 2^(L-1)
// JPEG 的“附加位”编码规则
return (v < half) ? v - (2 * half - 1) : v;
}
2.4 举例说明
让我用例子来进一步说明。假设某个 MCU 有这样一个比特流
11000001 0110 1101101
解码过程如下图
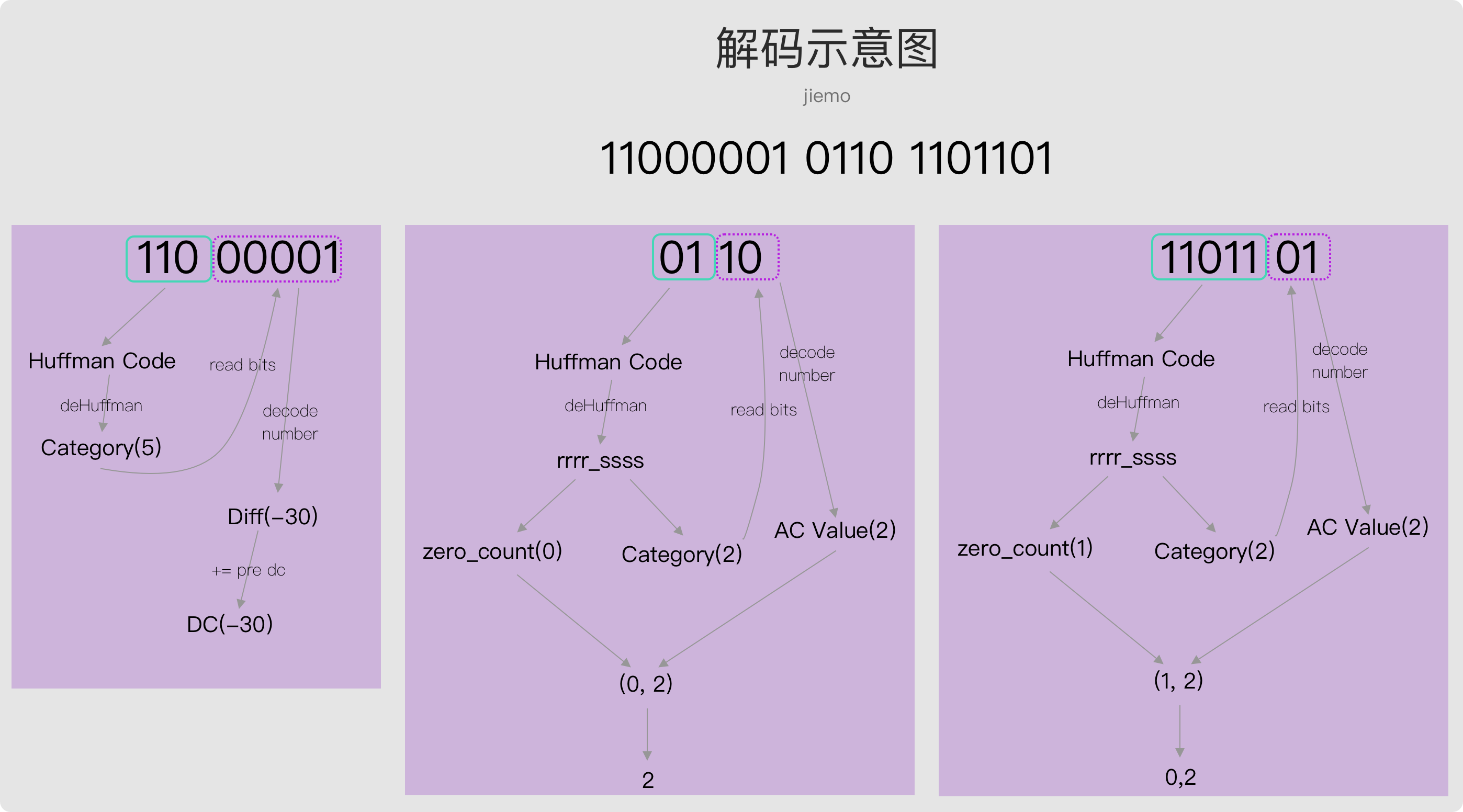
DC 解码过程(左图):
- 匹配到Huffman码(110),查表获Category(5)。
- 根据类别长度,读取后续5位(00001),得到差分的比特流。
- 解析 bit representation,得到 -30
- 用 DC_pred 之前的直流值加这个Δ,得到当前 mcu 的DC系数。
AC 系数解码过程(中图):
- 匹配到Huffman码(01),查表得 rrrr=0, ssss=2,得到 zero_count = 0, Category=2
- 根据 Category 读取2bit(10),以JPEG规则转化为系数值:2
- 得到游程编码是(0, 2),实际表示 [2]
AC 系数解码过程(中图):
- 匹配到Huffman码(11011),查表得 rrrr=1, ssss=2,得到 zero_count = 1, Category=2
- 根据 Category 读取2bit(10),以JPEG规则转化为系数值:2
- 得到游程编码是(1, 2),实际表示 [0, 2]
经过上面三次解码,我们得到 4 个值,以此类推解码整个 mcu
-30 2 0 2
DC AC0 AC1 AC2
2.5 理解哈夫曼表
注意,DC 和 AC 编解码过程中分别使用到了不同的哈夫曼表,此外 Y 分量和 UV 分量使用的哈夫曼表也是不一样的,因此通常一共有 4 个哈夫曼表。
| 分量/类型 | DC(直流) | AC(交流) |
|---|---|---|
| Y(亮度分量) | 哈夫曼表 #0 (DHT0) | 哈夫曼表 #1 (DHT1) |
| UV(色度分量) | 哈夫曼表 #2 (DHT2) | 哈夫曼表 #3 (DHT3) |
DHT 段中定义了哈夫曼表的数据,例如下面有 4 个 DHT 段,“DC(0)/AC(1)” 和 “Table ID” 可以让我们标识这个表格。
DHT segment
File position: 245
Length: 31
DC(0)/AC(1): 0
Table ID: 0
Symbol counts(16):
0,1,5,1,1,1,1,1,1,0,0,0,0,0,0,0,
Symbols(12):
0,1,2,3,4,5,6,7,8,9,10,11,
DHT segment
File position: 278
Length: 181
DC(0)/AC(1): 1
Table ID: 0
Symbol counts(16):
0,2,1,3,3,2,4,3,5,5,4,4,0,0,1,125,
Symbols(162):
1,2,3,0,4,17,5,18,33,49,65,6,19,81,97,7,34,113,20,50,129,145,161,8,35,66,177,193,21,82,209,240,36,51,98,114,130,9,10,22,23,24,25,26,37,38,39,40,41,42,52,53,54,55,56,57,58,67,68,69,70,71,72,73,74,83,84,85,86,87,88,89,90,99,100,101,102,103,104,105,106,115,116,117,118,119,120,121,122,131,132,133,134,135,136,137,138,146,147,148,149,150,151,152,153,154,162,163,164,165,166,167,168,169,170,178,179,180,181,182,183,184,185,186,194,195,196,197,198,199,200,201,202,210,211,212,213,214,215,216,217,218,225,226,227,228,229,230,231,232,233,234,241,242,243,244,245,246,247,248,249,250,
DHT segment
File position: 461
Length: 31
DC(0)/AC(1): 0
Table ID: 1
Symbol counts(16):
0,3,1,1,1,1,1,1,1,1,1,0,0,0,0,0,
Symbols(12):
0,1,2,3,4,5,6,7,8,9,10,11,
DHT segment
File position: 494
Length: 181
DC(0)/AC(1): 1
Table ID: 1
Symbol counts(16):
0,2,1,2,4,4,3,4,7,5,4,4,0,1,2,119,
Symbols(162):
0,1,2,3,17,4,5,33,49,6,18,65,81,7,97,113,19,34,50,129,8,20,66,145,161,177,193,9,35,51,82,240,21,98,114,209,10,22,36,52,225,37,241,23,24,25,26,38,39,40,41,42,53,54,55,56,57,58,67,68,69,70,71,72,73,74,83,84,85,86,87,88,89,90,99,100,101,102,103,104,105,106,115,116,117,118,119,120,121,122,130,131,132,133,134,135,136,137,138,146,147,148,149,150,151,152,153,154,162,163,164,165,166,167,168,169,170,178,179,180,181,182,183,184,185,186,194,195,196,197,198,199,200,201,202,210,211,212,213,214,215,216,217,218,226,227,228,229,230,231,232,233,234,242,243,244,245,246,247,248,249,250,
DHT 端中最重要的数据是 Symbol counts 和 Symbols,其中
- Symbols,如你所见,就是一些真正的数,例如 0, 10, 100 等,由于 YUV 数据范围是 [0, 256],所以这些数都在这个范围内。
- Symbol counts,是一个数组,固定长度为 16;第 i 个字节(i = 1 … 16)存放的是 码长 = i 的所有符号的个数;告诉解码器“码长 1 有多少个码字,码长 2 有多少个码字……码长 16 有多少个码字”。
通过 Symbol counts 和 Symbols 我们可以重建哈夫曼表,逻辑如下:
static std::map<std::string, uint16_t> buildHuffmanTable(
const std::vector<uint8_t>& counts,
const std::vector<uint8_t>& symbols) {
constexpr static auto kMaxHuffmanCodeLength = 16;
assert(counts.size() == kMaxHuffmanCodeLength);
std::map<std::string, uint16_t> table;
int code = 0;
int symInd = 0;
// length: 1 ~ 16 (JPEG哈夫曼表的码长范围)
for (int length = 1; length <= kMaxHuffmanCodeLength; ++length) {
int numCodes = counts[length - 1];
for (int i = 0; i < numCodes; ++i) {
// 生成指定位长的二进制字符串
std::string codeStr = std::bitset<kMaxHuffmanCodeLength>(code).to_string().substr(kMaxHuffmanCodeLength - length, length);
table[codeStr] = symbols[symInd++];
code++;
}
code <<= 1;
}
return table;
}
把生成的码字与 symbols 列表中的第 k 个符号一一配对,得到 {码字 → 符号} 的查找表。这样我们可以输入一个 bit 流,得到一个 symbol。
此外,SOS 段告诉我们该使用哪个哈夫曼表,例如:
SOS segment
File position: 677
Length: 12
Number of components: 3
Component ID: 1
Huffman table ID DC: 0
Huffman table ID AC: 0
Component ID: 2
Huffman table ID DC: 1
Huffman table ID AC: 1
Component ID: 3
Huffman table ID DC: 1
Huffman table ID AC: 1
- Y分量(亮度):使用第0号DC哈夫曼表、第0号AC哈夫曼表。
- Cb分量(色度1):使用第1号DC哈夫曼表、第1号AC哈夫曼表。
- Cr分量(色度2):使用第1号DC哈夫曼表、第1号AC哈夫曼表。
因此我们根据输入的分量信息以及是否是 DC,可以获得相应的哈夫曼表
2.6 哈夫曼解码
这部分立即直接看代码吧,理解了上面的内容后,就很简单啦。代码链接:deHuffman
2.7 剩下的步骤
哈夫曼解码后,我们得到了一个 mcu 的 dct 系数,首先对它做反量化,这个步骤我也写带了 deHuffman 函数中
// dequant
for (int i = 0; i < kMCUPixelSize; ++i) {
decoded_data[i] *= qtable->data[i];
}
return decoded_data;
接着,反 zig-zag、DCT逆变换、逆电平位移,最后将 mcu 解码出来的数据填充到一个大数组里。整体逻辑如下代码,细节还请参考源码。
auto num_block_in_x_dir = sof0->width / h_block_size;
auto num_block_in_y_dir = sof0->height / v_block_size;
int16_t pre_dc_value_y = 0;
int16_t pre_dc_value_u = 0;
int16_t pre_dc_value_v = 0;
auto mcu_count = 0;
for (auto y = 0; y < num_block_in_y_dir; ++y) {
for (auto x = 0; x < num_block_in_x_dir; ++x) {
mcu_count++;
auto y_data = deHuffman(parser, 0, pre_dc_value_y);
auto u_data = deHuffman(parser, 1, pre_dc_value_u);
auto v_data = deHuffman(parser, 2, pre_dc_value_v);
auto zig_zag_y = deZigZag(y_data);
auto zig_zag_u = deZigZag(u_data);
auto zig_zag_v = deZigZag(v_data);
auto idct_y = idct(zig_zag_y);
auto idct_u = idct(zig_zag_u);
auto idct_v = idct(zig_zag_v);
levelShift(idct_y);
levelShift(idct_u);
levelShift(idct_v);
// fill mcu to decoded data
auto left_top_x = x * 8;
auto left_top_y = y * 8;
for (int j = 0; j < kMCUPixelSize; j++) {
auto img_pos_x = left_top_x + j % 8;
auto img_pos_y = left_top_y + j / 8;
auto img_index = img_pos_y * sof0->width + img_pos_x;
y_decoded_data_[img_index] = static_cast<uint8_t>(idct_y[j]);
u_decoded_data_[img_index] = static_cast<uint8_t>(idct_u[j]);
v_decoded_data_[img_index] = static_cast<uint8_t>(idct_v[j]);
}
}
2.8 保存为 RGB 图片
JPEG 解码后是 YUV 数据,在 main.cpp 中我们演示了如何将 yuv 数据转换为 rgb,并保存到本地。

















 2207
2207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









