






👉 欢迎加入小哈的星球,你将获得: 专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
新项目:《从零手撸:仿小红书(微服务架构)》 正在持续爆肝中,基于 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., 点击查看项目介绍;
《从零手撸:前后端分离博客项目(全栈开发)》 2期已完结,演示链接:http://116.62.199.48/;
专栏阅读地址:https://www.quanxiaoha.com/column
截止目前,累计输出 82w+ 字,讲解图 3088+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,Spring Cloud Alibaba 等等,戳我加入学习,解锁全部项目,已有2900+小伙伴加入
前言
系统高可用是非常经典的问题,无论在面试,还是实际工作中,都经常会遇到。
这篇文章跟大家一起聊聊,保证系统高可用的10条军规,希望对你会有所帮助。
1 冗余部署
场景:某电商大促期间,数据库主节点突然宕机,导致全站交易瘫痪。
问题:单节点部署的系统,一旦关键组件(如数据库、消息队列)故障,业务直接归零。
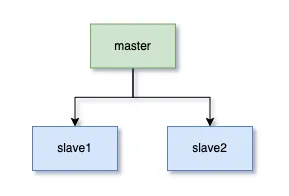
解决方案:通过主从复制、集群化部署实现冗余。例如MySQL主从同步,Redis Sentinel哨兵机制。
MySQL主从配置如下:
-- 主库配置
CHANGE MASTER TO
MASTER_HOST='master_host',
MASTER_USER='replica_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=154;
-- 从库启动复制
START SLAVE;效果:主库宕机时,从库自动切换为可读写状态,业务无感知。
2 服务熔断
场景:支付服务响应延迟,导致订单服务线程池耗尽,引发连锁故障。
问题:服务依赖链中某个环节异常,会像多米诺骨牌一样拖垮整个系统。
解决方案:引入熔断器模式,例如Hystrix或Resilience4j。
Resilience4j熔断配置如下:
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // 失败率超过50%触发熔断
.waitDurationInOpenState(Duration.ofMillis(1000))
.build();
CircuitBreaker circuitBreaker = CircuitBreaker.of("paymentService", config);
// 调用支付服务
Supplier<String> supplier = () -> paymentService.call();
Supplier<String> decoratedSupplier = CircuitBreaker
.decorateSupplier(circuitBreaker, supplier);效果:当支付服务失败率飙升时,自动熔断并返回降级结果(如“系统繁忙,稍后重试”)。
3 流量削峰
场景:秒杀活动开始瞬间,10万QPS直接击穿数据库连接池。
问题:突发流量超过系统处理能力,导致资源耗尽。
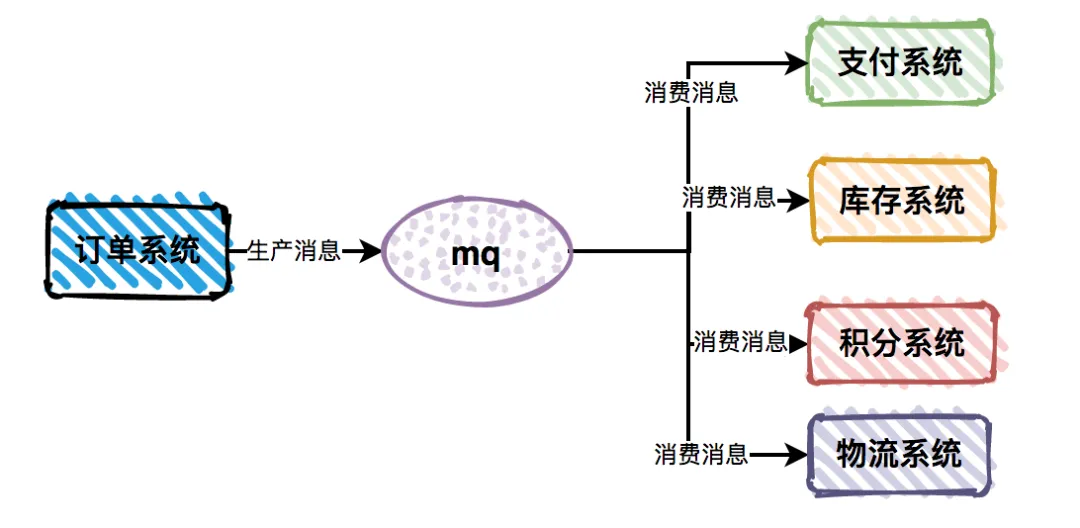
解决方案:引入消息队列(如Kafka、RocketMQ)做异步缓冲。
用户下单的系统流程图如下:
RocketMQ生产者的示例代码:
DefaultMQProducer producer = new DefaultMQProducer("seckill_producer");
producer.setNamesrvAddr("127.0.0.1:9876");
producer.start();
Message msg = new Message("seckill_topic", "订单数据".getBytes());
producer.send(msg);效果:将瞬时10万QPS的请求平滑处理为数据库可承受的2000 TPS。
4 动态扩容
场景:日常流量100台服务器足够,但大促时需要快速扩容到500台。
问题:固定资源无法应对业务波动,手动扩容效率低下。
解决方案:基于Kubernetes的HPA(Horizontal Pod Autoscaler)。
K8s HPA 的配置如下:
apiVersion: autoscaling/v2
kind:HorizontalPodAutoscaler
metadata:
name:order-service-hpa
spec:
scaleTargetRef:
apiVersion:apps/v1
kind:Deployment
name:order-service
minReplicas:2
maxReplicas:10
metrics:
-type:Resource
resource:
name:cpu
target:
type:Utilization
averageUtilization:60效果:CPU利用率超过60%时自动扩容,低于30%时自动缩容。
5 灰度发布
场景:新版本代码存在内存泄漏,全量发布导致线上服务崩溃。
问题:一次性全量发布风险极高,可能引发全局故障。
解决方案:基于流量比例的灰度发布策略。
Istio流量染色配置如下:
apiVersion: networking.istio.io/v1alpha3
kind:VirtualService
metadata:
name:bookinfo
spec:
hosts:
-bookinfo.com
http:
-route:
-destination:
host:reviews
subset:v1
weight:90# 90%流量走老版本
-destination:
host:reviews
subset:v2
weight:10# 10%流量走新版本效果:新版本异常时,仅影响10%的用户,快速回滚无压力。
6 降级开关
场景:推荐服务超时导致商品详情页加载时间从200ms飙升到5秒。
问题:非核心功能异常影响核心链路用户体验。
解决方案:配置中心增加降级开关,如果遇到紧急情况,能 动态降级非关键服务。
Apollo配置中心的示例代码如下:
@ApolloConfig
private Config config;
public ProductDetail getDetail(String productId) {
if(config.getBooleanProperty("recommend.switch", true)) {
// 调用推荐服务
}
// 返回基础商品信息
}效果:关闭推荐服务后,详情页响应时间恢复至200ms以内。
7 全链路压测
场景:某金融系统在真实流量下暴露出数据库死锁问题。
问题:测试环境无法模拟真实流量特征,线上隐患难以发现。
解决方案:基于流量录制的全链路压测。
实施步骤:
线上流量录制(如Jmeter+TCPCopy)
影子库隔离(压测数据写入隔离存储)
压测数据脱敏
执行压测并监控系统瓶颈
效果:提前发现数据库连接池不足、缓存穿透等问题。
8 数据分片
场景:用户表达到10亿行,查询性能断崖式下降。
问题:单库单表成为性能瓶颈。
解决方案:基于ShardingSphere的分库分表。
分库分表的配置如下:
sharding:
tables:
user:
actualDataNodes:ds_${0..1}.user_${0..15}
tableStrategy:
standard:
shardingColumn:user_id
preciseAlgorithmClassName:HashModShardingAlgorithm
preciseAlgorithmType:HASH_MOD
shardingCount:16效果:10亿数据分散到16个物理表,查询性能提升20倍。
9 混沌工程
场景:某次机房网络抖动导致服务不可用3小时。
问题:系统健壮性不足,故障恢复能力弱。
解决方案:使用ChaosBlade模拟故障。
示例命令:
# 模拟网络延迟
blade create network delay --time 3000 --interface eth0
# 模拟数据库节点宕机
blade create docker kill --container-id mysql-node-1效果:提前发现缓存穿透导致DB负载过高的问题,优化缓存击穿防护策略。
10 立体化监控
场景:磁盘IOPS突增导致订单超时,但运维人员2小时后才发现。
问题:监控维度单一,无法快速定位根因。
解决方案:构建Metrics-Log-Trace三位一体监控体系。
技术栈组合:
Metrics:Prometheus + Grafana(资源指标)
Log:ELK(日志分析)
Trace:SkyWalking(调用链追踪)
定位问题流程如下 :
CPU利用率 > 80% → 关联日志检索 → 定位到GC频繁 →
追踪调用链 → 发现某个DAO层SQL未走索引效果:故障定位时间从小时级缩短到分钟级。
总结
系统高可用建设就像打造一艘远洋巨轮。
冗余部署是双发动机,熔断降级是救生艇,监控体系是雷达系统。
但真正的关键在于:
故障预防比故障处理更重要(如混沌工程)
自动化是应对复杂性的唯一出路(如K8s弹性扩缩)
数据驱动的优化才是王道(全链路压测+立体监控)
没有100%可用的系统,但通过这10个实战技巧,我们可以让系统的可用性从99%提升到99.99%。
这0.99%的提升,可能意味着每年减少8小时的故障时间——而这,正是架构师价值的体现。
👉 欢迎加入小哈的星球,你将获得: 专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
新项目:《从零手撸:仿小红书(微服务架构)》 正在持续爆肝中,基于 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., 点击查看项目介绍;
《从零手撸:前后端分离博客项目(全栈开发)》 2期已完结,演示链接:http://116.62.199.48/;
专栏阅读地址:https://www.quanxiaoha.com/column
截止目前,累计输出 82w+ 字,讲解图 3088+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,Spring Cloud Alibaba 等等,戳我加入学习,解锁全部项目,已有2900+小伙伴加入

1. 我的私密学习小圈子,从0到1手撸企业实战项目~ 2. 谁说 MySQL 单表行数不要超过 2000W? 3. 这才是批量update的正确姿势! 4. 去哪儿技术面:10亿数据如何最快速插入MySQL?

最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。 获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。 点“在看”支持小哈呀,谢谢啦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









