






众所周知,Elasticsearch 是一个非常流行的搜索引擎,因为它速度快、扩展性强,尤其擅长全文搜索。
近两年,向量嵌入(Vector Embedding)技术的引入,让 Elasticsearch 在处理高级搜索场景时变得更强大,比如语义搜索、推荐系统和 AI 驱动的查询。
👉 欢迎加入小哈的星球,你将获得: 专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
新项目:《从零手撸:仿小红书(微服务架构)》 收尾中,基于 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., 点击查看项目介绍;演示地址:http://116.62.199.48:7070/
《从零手撸:前后端分离博客项目(全栈开发)》 2期已完结,演示链接:http://116.62.199.48/;
专栏阅读地址:https://www.quanxiaoha.com/column
截止目前,累计输出 90w+ 字,讲解图 3556+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,Spring Cloud Alibaba 等等,戳我加入学习,解锁全部项目,已有3100+小伙伴加入
我们来一步步拆解这个技术。

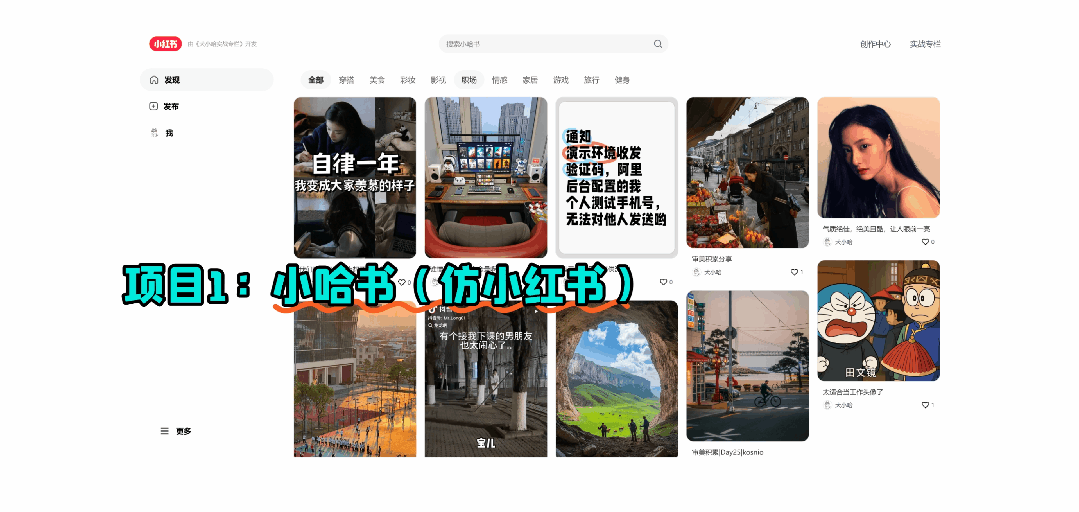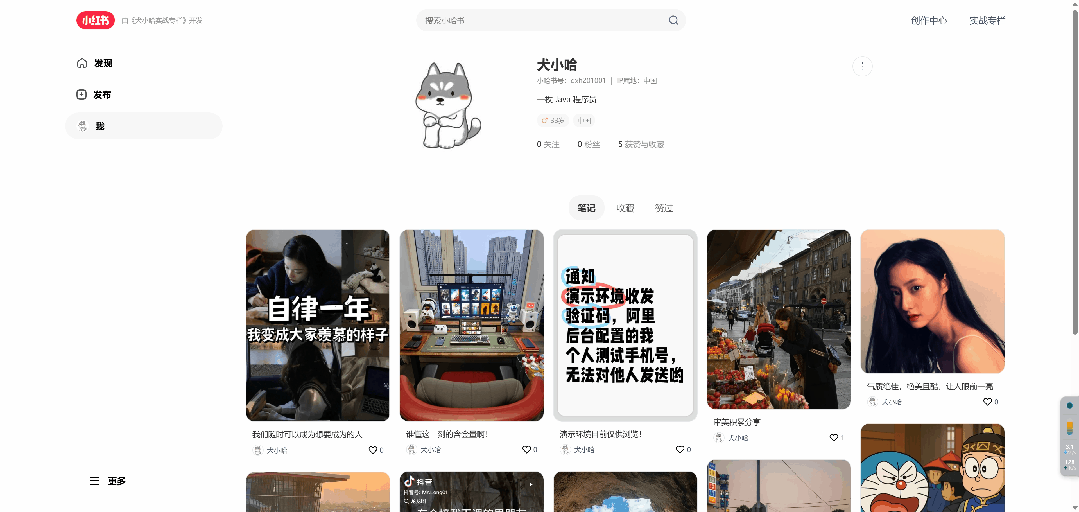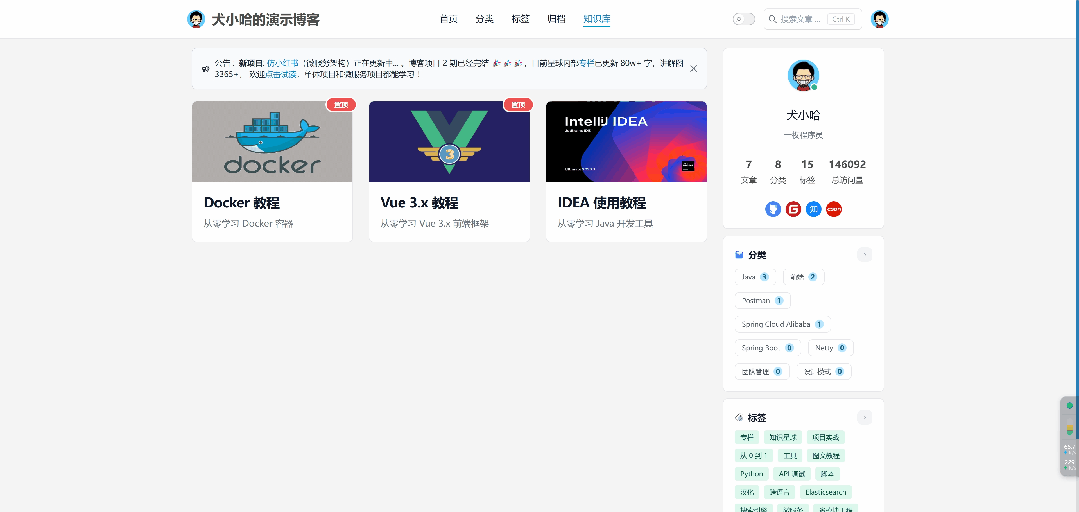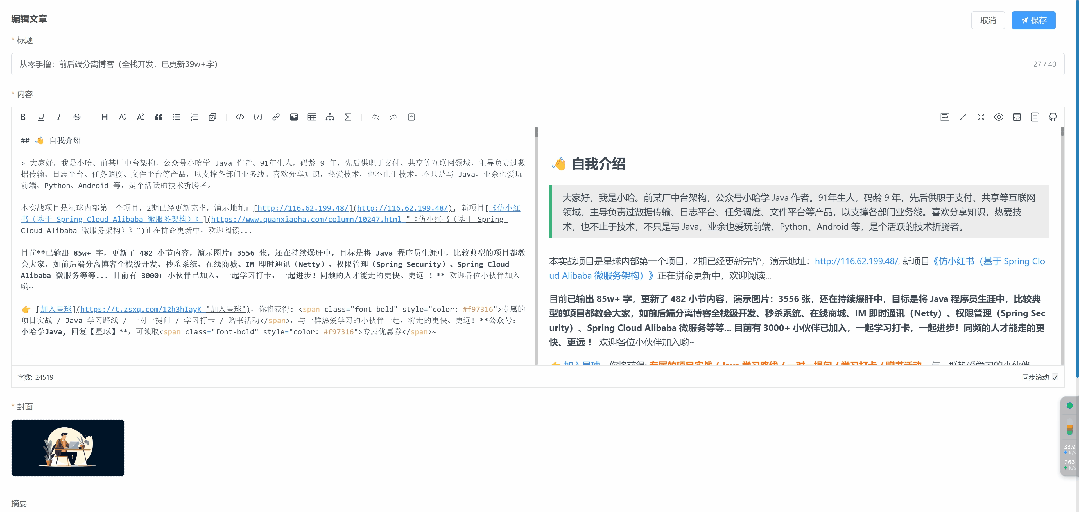
1、什么是向量嵌入?
简单来说,向量嵌入就是把文字、图片或者其他数据变成一组多维的数字(数学数组)。这些数字能让机器理解数据之间的“语义相似性”。
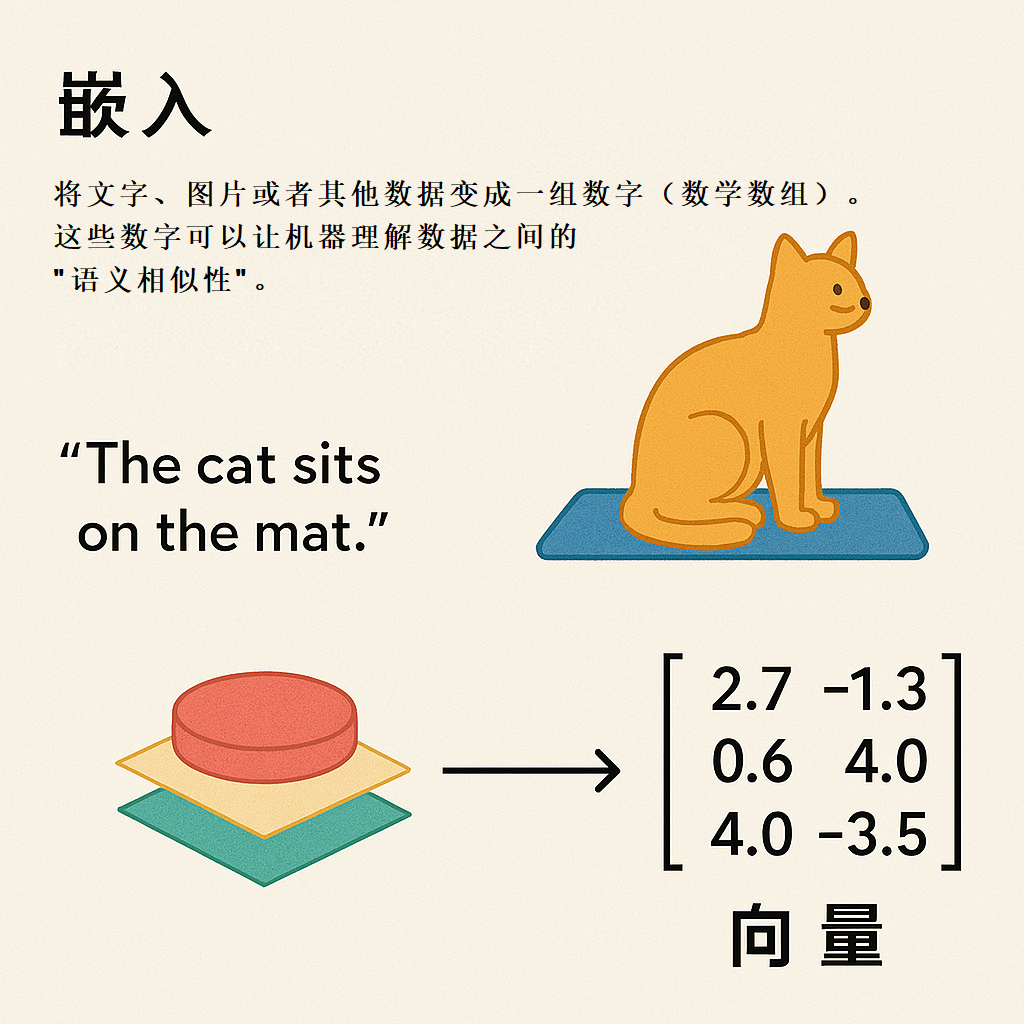
比如,你搜索“新能源 小米”汽车,即使结果里没有完全匹配的关键词,系统也能返回像“小米 SU7”这样的内容,因为它们在语义上是相关的。
2、在Elasticsearch中使用向量嵌入
要在 Elasticsearch 里用上向量嵌入,需要一个完整的流程:
2.1 生成向量嵌入
用AI模型(比如OpenAI的嵌入模型或Transformer模型)把原始文本转成一组数字,这些数字反映了数据之间的关系。
2.2 在Elasticsearch中存储向量
把生成的向量作为字段存进 Elasticsearch,方便后续基于相似性的查询。

2.3 用向量查询
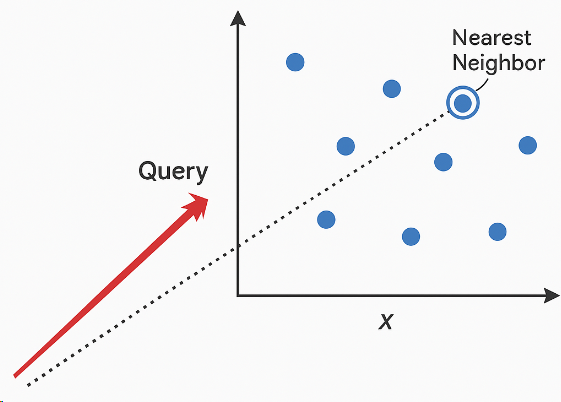
不再是简单的关键词搜索,而是把查询也转成向量,通过比较向量之间的“距离”来找到最接近的结果,这种方法叫“最近邻搜索”(Nearest Neighbor Search)。
2.4 向量嵌入大致流程如下
Step1:提取关键数据(比如标题、描述)。
Step2:用AI模型生成嵌入向量(可以用 Python工具,比如HuggingFace 或 sentence-transformers)。
Step3:把这些向量存进Elasticsearch,用的是“dense_vector”字段类型。
Step4:通过Elasticsearch的 KNN(k-Nearest Neighbor)功能实现向量查询。
接下来,我们重点聊聊怎么为 Elasticsearch 生成向量嵌入,尤其针对日志数据的场景,咱们介绍了两种方法。
3、基于 Python 的实现向量嵌入
用Python实现时,通常会借助elasticsearch或requests库,直接跟Elasticsearch交互。
完整代码实现如下:
from elasticsearch import Elasticsearch, helpersimport requestsimport configparserimport warningsimport timeimport randomimport concurrent.futuresimport logginglogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)# 忽略警告信息(如果需要)warnings.filterwarnings("ignore")# 初始化 Elasticsearch 客户端,根据指定的配置文件读取连接信息。def init_es_client(config_path='./conf/config.ini'): """初始化并返回基于配置文件中的 Elasticsearch 客户端""" config = configparser.ConfigParser() config.read(config_path) es_host = config.get('elasticsearch', 'ES_HOST') es_user = config.get('elasticsearch', 'ES_USER') es_password = config.get('elasticsearch', 'ES_PASSWORD') es = Elasticsearch( hosts=[es_host], basic_auth=(es_user, es_password), verify_certs=False, ca_certs='conf/http_ca.crt' ) return es# 设置嵌入服务 URL 为本地 Ollama 的端点EMBEDDING_SERVICE_URL = "http://localhost:11434/api/embeddings"# 从 Elasticsearch 中获取尚未生成嵌入的文档,使用 scroll API 提高效率。def fetch_documents_from_elasticsearch(es_client, index="logs", query=None, batch_size=25): """ 从 Elasticsearch 中获取缺少嵌入的文档 """ query = query or { "query": { "bool": { "must_not": {"exists": {"field": "embedding"}} } }, "size": batch_size, "sort": [{"@timestamp": "asc"}] } response = es_client.search(index=index, body=query, scroll="1m") scroll_id = response["_scroll_id"] documents = response["hits"]["hits"] while documents: for doc in documents: yield doc response = es_client.scroll(scroll_id=scroll_id, scroll="1m") scroll_id = response["_scroll_id"] documents = response["hits"]["hits"]# 通过向嵌入服务发送 POST 请求,为给定的文本获取嵌入向量。def fetch_embeddings(text): try: response = requests.post( EMBEDDING_SERVICE_URL, json={"model": "all-minilm", "prompt": text}, timeout=10 ) response.raise_for_status() result = response.json() logger.info("result.embedding: %s", result["embedding"]) return result.get("embedding") except requests.exceptions.RequestException as e: logger.error("Error fetching embedding: %s", str(e)) return None# 更新 Elasticsearch 中的文档,添加嵌入向量及元数据,使用脚本避免覆盖已有数据。def update_document_in_elasticsearch(es_client, doc_id, index="logs", embedding=None): """ 更新 Elasticsearch 文档,添加嵌入数据 """ body = { "script": { "source": ''' if (ctx._source.containsKey("embedding_processed_at") && ctx._source.embedding_processed_at != null) { ctx.op = "noop"; } else { ctx._source.embedding = params.embedding; ctx._source.embedding_processed_at = params.timestamp; ctx._source.processing_status = params.status; if (params.error_message != null) { ctx._source.error_message = params.error_message; } } ''', "params": { "embedding": embedding if embedding else None, "timestamp": time.strftime('%Y-%m-%dT%H:%M:%SZ'), "status": "failed" if embedding is None else "success", "error_message": None if embedding else "嵌入生成失败" } } } es_client.update(index=index, id=doc_id, body=body)# 主函数,协调获取文档、生成嵌入并更新 Elasticsearch 的流程,按批次处理。def process_documents(es_client, batch_size=25): """ 主函数:获取文档,生成嵌入,并更新 Elasticsearch """ for doc in fetch_documents_from_elasticsearch(es_client, batch_size=batch_size): doc_id = doc["_id"] text_content = doc["_source"].get("content", "") embedding = fetch_embeddings(text_content) update_document_in_elasticsearch(es_client, doc_id, embedding=embedding)if __name__ == "__main__": # 初始化 Elasticsearch 客户端 es = init_es_client(config_path='./conf/config.ini') # 开始处理文档 process_documents(es, batch_size=25)其中:Ollama 是一个轻量级的开源工具,用于运行语言模型并生成嵌入向量(embeddings)。在这里,它被用作嵌入生成服务。
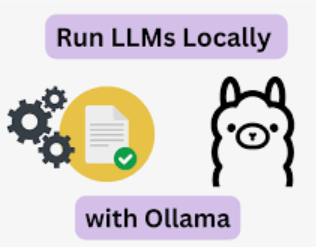
最核心:"model": "all-minilm"。主要指——指定使用名为 "all-minilm" 的模型来生成嵌入向量。
all-minilm 是 Sentence Transformers 模型家族中的一种轻量级模型(基于 MiniLM),适用于生成短文本的嵌入,速度快且资源占用低。 Ollama 支持加载此类模型,并通过 API 提供服务。
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
执行结果:
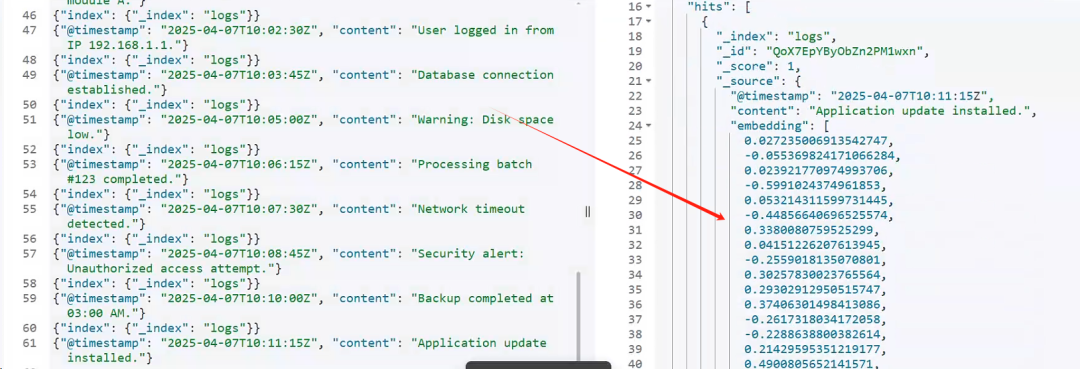
3.1 python 方案嵌入向量优点
灵活性强——可以完全控制数据处理、错误处理和重试策略。
调试方便——支持详细的日志记录和调试。
精细控制——能调整并发、批次大小和重试逻辑。
AI集成简单——跟机器学习模型、大语言模型无缝衔接。
3.2 python 方案嵌入向量缺点
扩展性有限——Python的全局解释器锁(GIL)限制了多线程在CPU密集任务中的表现。
开发成本高——需要手动处理重试、错误监控和优化。
资源占用多——处理大数据时,内存和 CPU 消耗较高。
4、基于 Logstash 实现向量嵌入
4.1 概览
Logstash 是一个轻量级、可扩展的 ETL 工具,特别适合处理大数据流。
4.2 Logstash 嵌入向量实操指南
4.2.1 【输入】Elasticsearch 输入
input {
elasticsearch {
hosts => ["https://127.0.0.1:9200"]
user => "elastic"
password => "changeme"
ssl_enabled => true
ca_file => "E:\logstash-8.15.3-windows-x86_64\logstash-8.15.3\config\http_ca.crt"
index => "logs_20250409"
query => '
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "embedding"
}
}
}
}
}
'
schedule => "*/1 * * * *"
docinfo => true
docinfo_target => "[@metadata]" #这行非常重要
size => 25
}
}4.2.2 【中间处理】过滤:调用嵌入服务
filter {
http {
url => "http://localhost:11434/api/embeddings" # Updated to Ollama's default endpoint
verb => "POST"
body_format => "json"
body => {
"model" => "all-minilm" # Added model field for Ollama compatibility
"prompt" => "%{[content]}" # Changed "text" to "prompt" for Ollama
}
target_body => "embedding_response"
}
}4.2.3【输出】更新Elasticsearch
output {
elasticsearch {
hosts => ["https://127.0.0.1:9200"] # Updated to https for SSL
user => "elastic"
password => "changme"
ssl_enabled => true
cacert => "E:\logstash-8.15.3-windows-x86_64\logstash-8.15.3\config\http_ca.crt"
index => "logs_20250409"
document_id => "%{[@metadata][_id]}" # Ensure correct document ID usage
action => "update"
doc_as_upsert => true # Ensure documents are created if they don't exist
retry_on_conflict => 5 # Increase the retry attempts for handling conflicts
}
}4.3 Logstash 方案优点
扩展性强——通过管道工作线程轻松扩展。
容错性好——内置重试和故障处理机制。
开发简单——用声明式配置,几乎不用写代码。
高效处理——专为高吞吐量数据流优化。
4.4 Logstash 方案缺点
调试困难——出错时排查问题不灵活。
定制性弱——不支持复杂的自定义逻辑或原生ML模型。
依赖性强 ——跟Elasticsearch耦合紧密,替换成本高。
5、如何选择最适合你的方法?
5.1 选型 Python 的情况
需要复杂的自定义逻辑或集成机器学习模型。希望对每个处理步骤有精细控制。要跟Elasticsearch之外的多个系统对接。
5.2 选型 Logstash的情况
需要高效处理海量日志。希望扩展性强,开发工作量少。想要一个开箱即用的ETL方案,专为 Elasticsearch 优化。
6、总结
如果你的目标是处理大规模、高吞吐量的日志数据,Logstash 通常是更好的选择。但如果你的工作流需要高级定制或机器学习支持,Python 会更合适。
👉 欢迎加入小哈的星球,你将获得: 专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
新项目:《从零手撸:仿小红书(微服务架构)》 收尾中,基于 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., 点击查看项目介绍;演示地址:http://116.62.199.48:7070/
《从零手撸:前后端分离博客项目(全栈开发)》 2期已完结,演示链接:http://116.62.199.48/;
专栏阅读地址:https://www.quanxiaoha.com/column
截止目前,累计输出 90w+ 字,讲解图 3556+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,Spring Cloud Alibaba 等等,戳我加入学习,解锁全部项目,已有3100+小伙伴加入

1. 我的私密学习小圈子,从0到1手撸企业实战项目~ 2. 阿里又开源一款数据同步工具 DataX,稳定又高效,好用到爆! 3. kafka 分布式的情况下,如何保证消息的顺序消费? 4. 抖音服务器带宽有多大,才能供上亿人同时刷?

最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。 获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。 点“在看”支持小哈呀,谢谢啦

















 1864
1864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









