





by Prateek Mishra, Director of Engineering, Noodle.ai
通过 Prateek米什拉 ,工程总监, Noodle.ai
Noodle.ai is focused on providing AI products to address a diverse set of problems which could aide in better visibility, decision making and waste reduction for our Enterprise customers. This two-part blog covers the journey of building our in-house ML framework — Atlas, explaining the factors that were considered, choices that were made and the benefits that we derived out of it. In the first part the focus will be on 4 high-level factors which contribute to complexity of building an AI application and we will dive into details of each of these:
Noodle.ai致力于提供AI产品,以解决各种问题,这些问题可能有助于为我们的企业客户提供更好的可视性,决策和减少浪费。 这个由两部分组成的博客介绍了构建内部ML框架的过程-Atlas,解释了所考虑的因素,做出的选择以及我们从中获得的收益。 在第一部分中,重点将放在四个高级因素上,这些因素会导致构建AI应用程序的复杂性,我们将深入探讨以下每个因素的详细信息:
Enterprise AI Applications: What does it take to build an Enterprise AI product
企业AI应用程序:构建企业AI产品需要什么
AI Application Development Lifecycle: Where is the choke point in the product development process and why
AI应用程序开发生命周期:产品开发过程中的瓶颈在哪里,为什么?
ML Pipeline Development: What are the velocity challenges with iterative experiments
ML管道开发:迭代实验的速度挑战是什么
Tech Stack Selection: What are the tools available, overview of one such combination we use at Noodle
技术栈选择:有哪些可用的工具,我们在Noodle中使用的一种此类组合的概述
1.企业AI应用 (1. Enterprise AI Applications)
There are numerous blogs which describe the challenges when developing an AI application. This comes largely due to the iterative nature of development when compared to a more deterministic rule-based software.
有许多博客描述了开发AI应用程序时遇到的挑战。 与更具确定性的基于规则的软件相比,这主要是由于开发的迭代性质。
Building Enterprise grade software is always treated differently than building other applications and a testament to this fact is that most open source software offer a community and an enterprise version of the same product. A Forbes article covers this topic in detail.
始终将构建企业级软件与构建其他应用程序区别对待,这一事实证明,大多数开源软件都提供同一产品的社区和企业版本。 福布斯》(Forbes)文章详细介绍了该主题。
What do we know so far?
到目前为止我们知道什么?
- Building AI applications is tough 构建AI应用程序很困难
- Building Enterprise grade software is tough 构建企业级软件非常困难
So, what would be the complexity in building an Enterprise AI application?
那么,构建企业AI应用程序的复杂性是什么?
To understand this, we try to see the application of AI driven Recommendation Engine, evaluated for different category of end users.
为了理解这一点,我们尝试查看针对特定类别的最终用户进行评估的AI驱动推荐引擎的应用。
- Recommending songs or videos to the end user on an audio/video streaming application 在音频/视频流应用程序上向最终用户推荐歌曲或视频
- Recommending optimal parameters to an operations engineer in a manufacturing plant. 向制造工厂的运营工程师推荐最佳参数。
In each of the example above, while the approach taken to solve the problems could be similar the impact of decision made is quite different. In the #2 scenario, errors made by the application could cause significant loss to the end users.
在上面的每个示例中,尽管解决问题所采用的方法可能相似,但决策的影响却截然不同。 在#2方案中,应用程序犯的错误可能会给最终用户造成重大损失。
When you are building an Enterprise software such as Confluence, you would be paying to consume core features such as Documentation & Collaboration. It might be using an AI/ML backed search algorithm to better assist you in navigation.
当您构建诸如Confluence之类的企业软件时,您将需要花费诸如文档和协作之类的核心功能。 它可能正在使用AI / ML支持的搜索算法来更好地帮助您进行导航。
Another example could be Zoom, where you would be paying to use the meetings, screen share and recording features. It could be using AI based systems to flag content on video calls.
另一个示例可能是Zoom,在这里您需要付费使用会议,屏幕共享和录制功能。 它可能正在使用基于AI的系统来标记视频通话中的内容。
Both are examples of Enterprise products where AI is an Add On Feature. At Noodle we build products where AI is the core feature of the application, which belong to the yellow path shown in Fig. 1. AI is not an added layer of intelligence, but it is the feature for which we get payed. This adds additional layers of complexity in the development and deployment lifecycle. A failure in this component will result in failure of product and most likely cause losses. The criticality of performance is higher and so are the expectations.
两者都是企业产品的示例,其中AI是附加功能。 在Noodle,我们构建的产品将AI视为应用程序的核心功能,该功能属于图1所示的黄色路径。AI并不是智能的附加层,而是我们为此付费的功能。 这在开发和部署生命周期中增加了更多的复杂性。 该组件的故障将导致产品故障,最有可能导致损失。 性能的关键性更高,期望也更高。
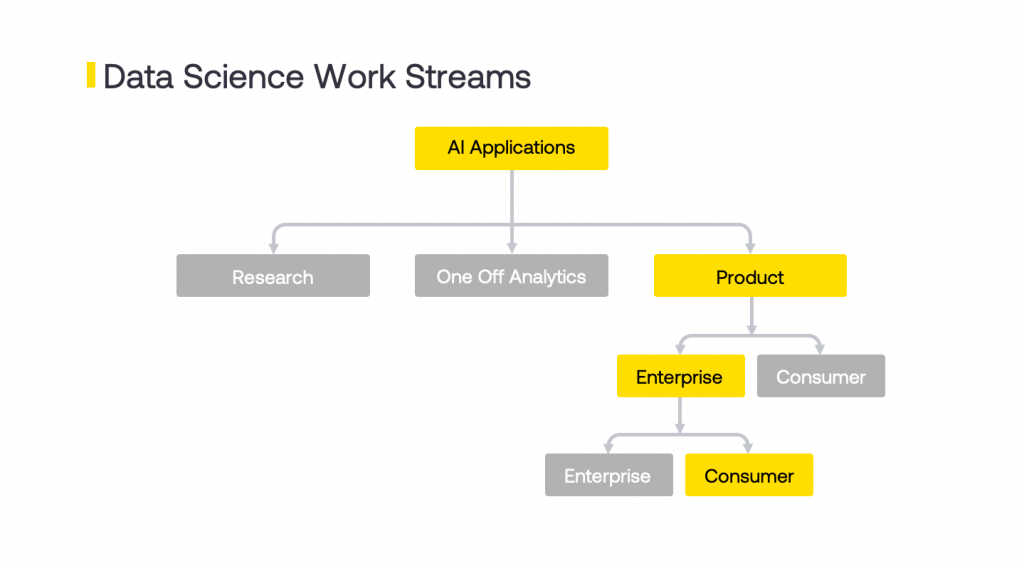
Some of the challenges that we have experienced when building Enterprise AI products are described below:
下面介绍了我们在构建企业AI产品时遇到的一些挑战:
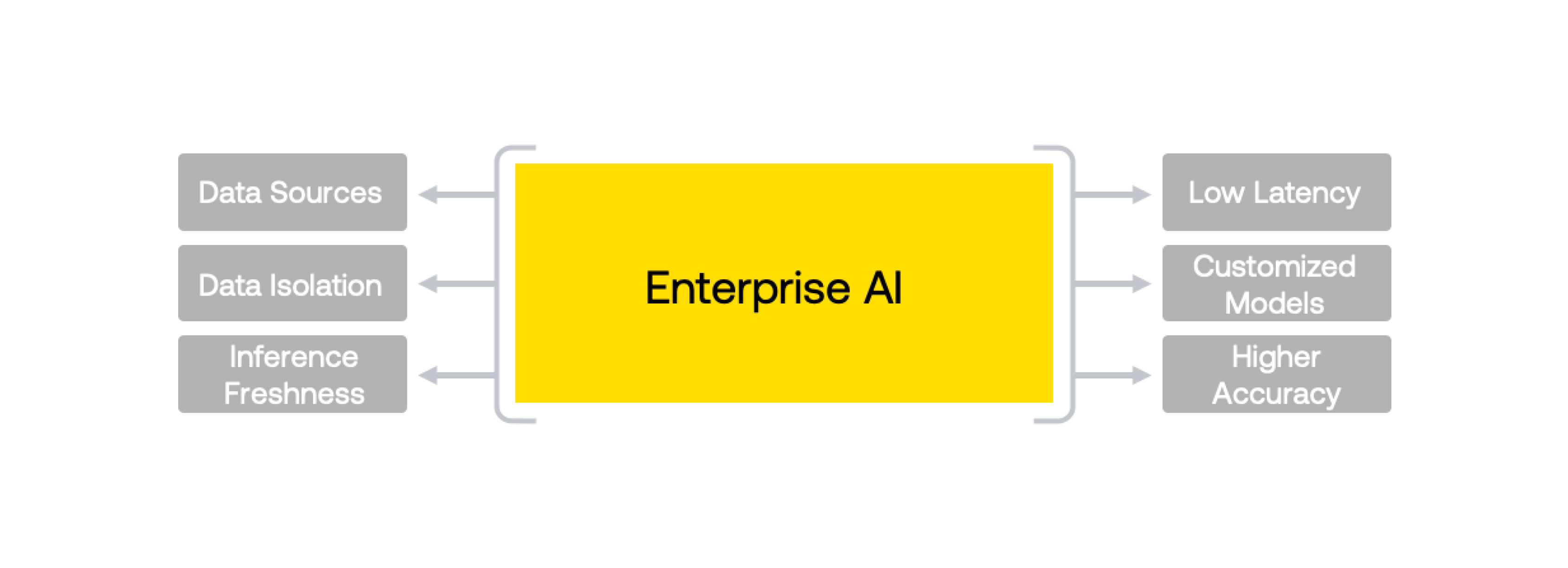
Data Variations — Enterprise tenants have variations in storing and naming the data sets, often involving data being spread across multiple vendor’s software. This makes the efforts to retrieve and process this data intensive.
数据变化 -企业租户在存储和命名数据集方面存在变化,通常涉及跨多个供应商软件分发的数据。 这使得检索和处理此数据的工作量很大。
Customization — Most customers need data isolation and hence even when the domain is the same, customized models must be created for each tenant analyzing their individual historical data and understanding the context.
自定义 -大多数客户需要数据隔离,因此即使域相同,也必须为每个租户创建自定义模型,以分析其各自的历史数据并了解上下文。
Performance — Accuracy of the models should be high to drive impactful decision making and, as seen in the examples above, prevent losses from happening.
性能 -模型的准确性应该很高,以推动做出有影响力的决策,并且如上面的示例所示,可以防止损失的发生。
Freshness — Inference results should be available on the latest data. Inferences which were run earlier become stale and need to be discarded or refreshed.
新鲜度 -推断结果应该在最新数据上可用。 早先运行的推理变得陈旧,需要被丢弃或刷新。
2. AI应用程序开发生命周期 (2. AI Application development lifecycle)
“What you have learned is that the capacity of the plant is equal to the capacity of its bottlenecks,” says Jonah.” — Eliyahu M. Goldratt, The Goal: A Process of Ongoing Improvement
乔纳说:“您了解到的是,工厂的产能等于瓶颈的产能。” — Eliyahu M. Goldratt, 《目标:持续改进的过程》
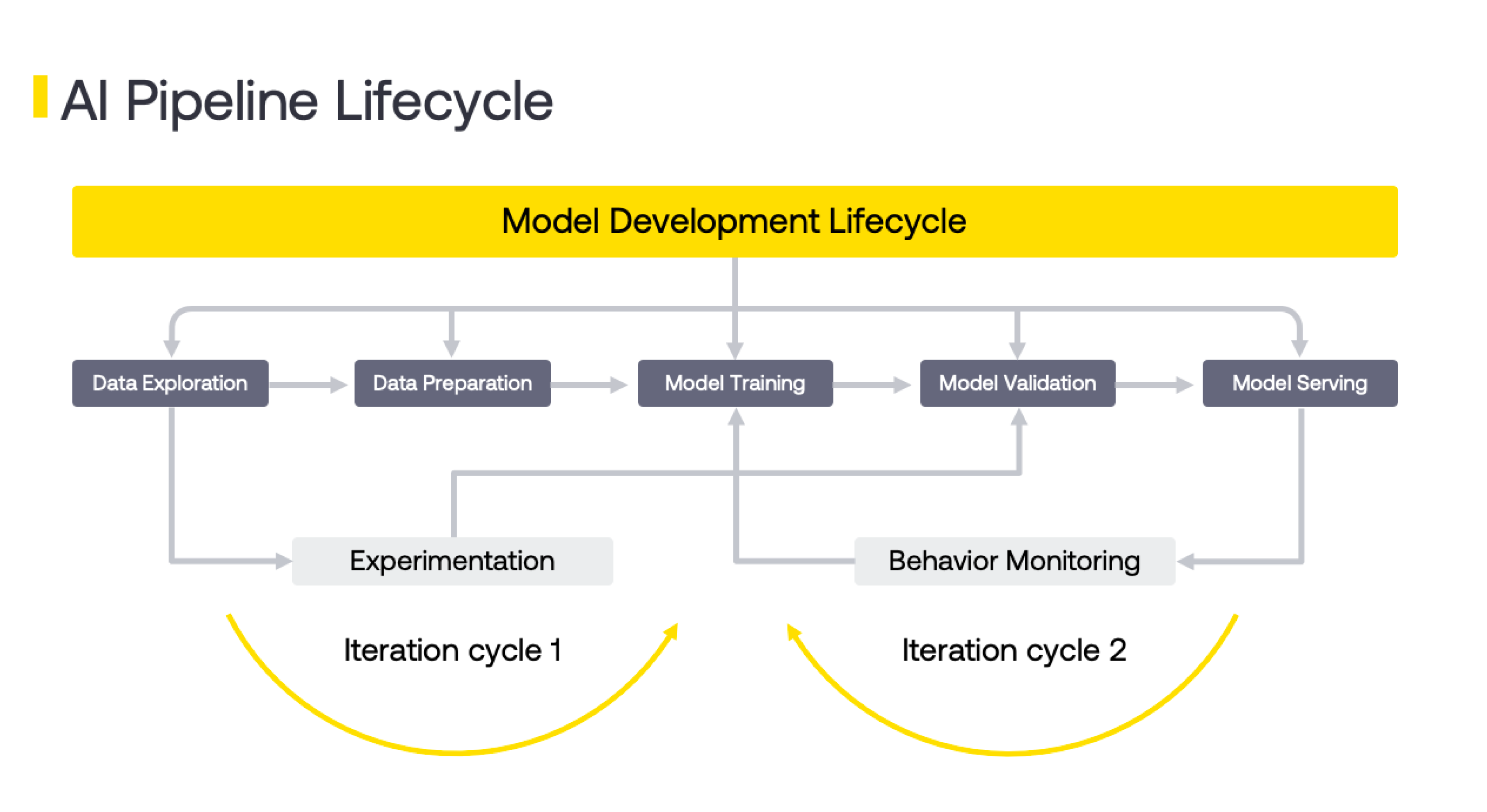
As per the Theory of constraints, every system has one or more constraints which prevents it from achieving optimum efficiency. Any improvement done before or after this constraint is ineffective. Going from raw data to an AI application involves multiple stages as highlighted in diagram below. A common constraint is the turnaround time of putting new ML pipelines into production. Usually the choke point is the switch over from Model Development to Production Readiness stages as shown below. Enabling faster experiments, adding more members on the team or providing more specialized hardware for ML/DL will not have any impact till this is addressed.
根据约束理论,每个系统都有一个或多个约束,这使其无法实现最佳效率。 在此约束之前或之后所做的任何改进都是无效的。 从原始数据到AI应用程序涉及多个阶段,如下图所示。 一个常见的限制是将新的ML管道投入生产的周转时间。 通常,瓶颈在于从模型开发阶段过渡到生产就绪阶段,如下所示。 在解决此问题之前,启用更快的实验,在团队中添加更多成员或为ML / DL提供更多专业硬件不会产生任何影响。
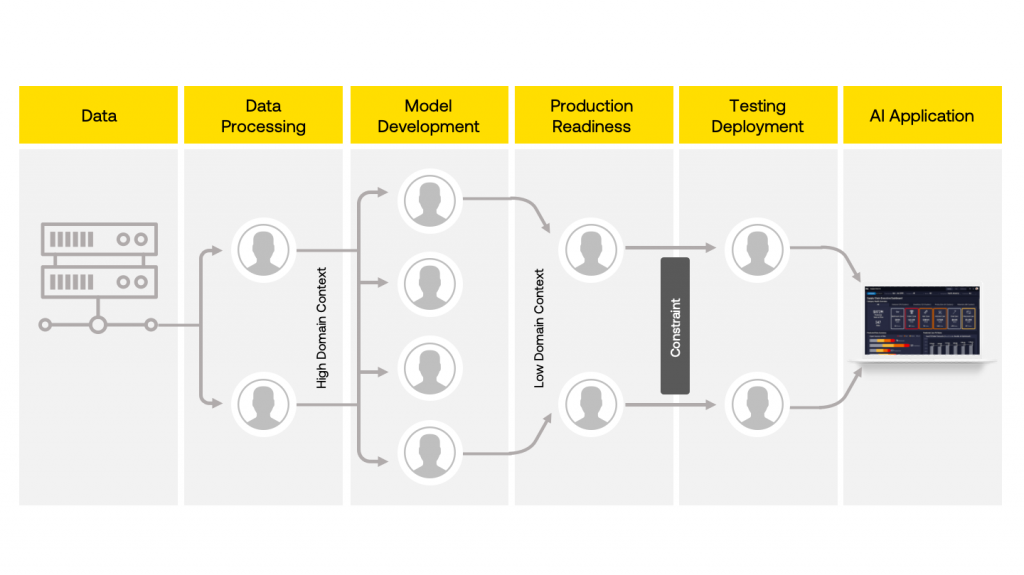
If we examine the two stages leading to the constraint namely Model Development and Production Readiness, we can see that the reason for this delay is that the developers in the two stages are trying to meet different goals.
如果我们检查导致约束的两个阶段,即“模型开发”和“生产就绪”,则可以看到造成这种延迟的原因是两个阶段的开发人员都在尝试实现不同的目标。
模型开发 (Model development)
- Domain understanding / Data Labelling 领域理解/数据标签
- Modelling technique selection 建模技术选择
- Feature selection 功能选择
- Experimentation 实验性
- Evaluation 评价
- Visualization 可视化
生产准备 (Production Readiness)
- Code Modularization 代码模块化
- Reduce duplication 减少重复
- Interface definition 接口定义
- Test case identification and automation 测试用例识别和自动化
- Workflow orchestration 工作流程编排
- Scalable execution 可扩展执行
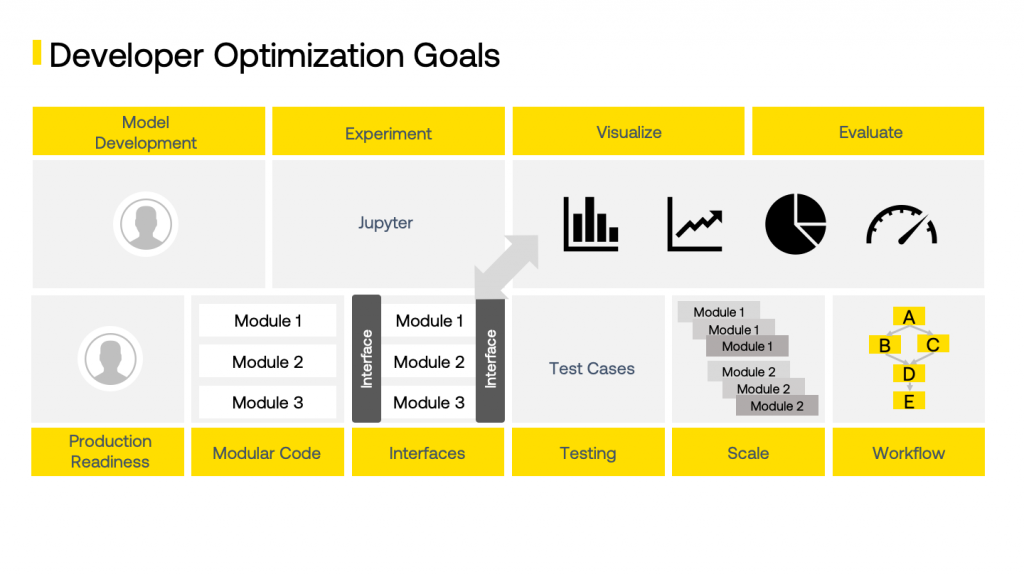
Balancing the different goals and bringing in the right velocity is tough between these two stages. The amount of effort to be invested in this process varies if you are trying to build one product vs if you are trying to build a suite of products across different domains. In the latter scenario, optimization of this process becomes a necessity.
在这两个阶段之间很难平衡不同的目标并以适当的速度进行调整。 如果您尝试构建一个产品,而尝试跨不同领域构建一套产品,则在此过程中投入的精力会有所不同。 在后一种情况下,必须优化此过程。
3.机器学习管道开发模型 (3. ML Pipeline Development Model)
Development is an iterative process which involves experimentation and evaluation cycles factoring for both code and data changes. While it is tempting to continue this cycle to chase a certain state of perfection but if we apply the principles of DevOps, also referred to as MLOps, we would want to promote reasonably performing models and their corresponding ML pipelines to production quickly. There are a few articles that cover this topic in detail and are a recommended read.
开发是一个反复的过程,其中涉及对代码和数据更改进行因素分析的实验和评估周期。 虽然很想继续这个周期以追求某种完美状态,但是如果我们应用DevOps的原理(也称为MLOps),我们希望将性能合理的模型及其相应的ML管道快速推广到生产中。 有几篇文章详细介绍了此主题,建议阅读。
MLOps: Continuous delivery and automation pipelines in machine learning
All AI applications must embrace the concept of iterative, exploratory development process. This is a difficult premise for software development where most practices known have been designed around clarity in requirements. The constant experimentation creates 2 more problems which become tougher to solve as time passes.
所有AI应用程序都必须包含迭代探索性开发过程的概念。 这对于软件开发来说是一个困难的前提,在软件开发中,大多数已知的实践都是围绕需求的清晰性而设计的。 不断进行的实验又产生了2个问题,随着时间的流逝,这些问题将变得更加难以解决。
- There is a tendency to keep improving the models and push for an ideal state. This makes the development follow a waterfall model where most of the integration and testing gets delayed. 有一种趋势是不断改进模型并推动达到理想状态。 这使得开发遵循瀑布模型,其中大多数集成和测试都被延迟了。
- The boundary between a successful experiment prototype and an application deployed in production becomes unclear and this leads to massive technical debt [Prototype Smell]. 成功的实验原型和在生产中部署的应用程序之间的界限不明确,这导致了巨大的技术负担[Prototype Smell]。
4.技术栈选择 (4. Tech Stack Selection)
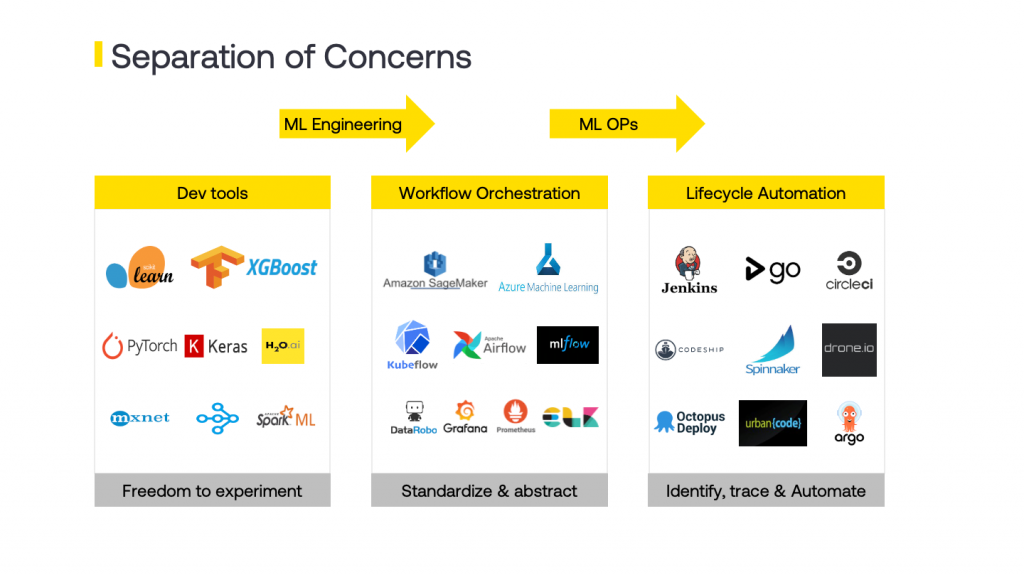
There is an added complexity of selecting the right tech stack amongst the numerous packages and tools that are available.
在众多可用的软件包和工具中选择合适的技术堆栈会增加复杂性。
At Noodle, we have a hybrid infrastructure. We have a private data centre that houses heavy compute clusters and public cloud — AWS + Azure, is used to host the application. Each tenant can opt in for dedicated VPC or VNet based on their data + compute isolation needs. Development and training phases are mostly carried out in the private data centre and the trained models are deployed to cloud. To ensure seamless operations across 3 different environments, we have leveraged Kubernetes (K8s) to be the layer of abstraction for our operations and deployments.
在Noodle,我们拥有混合基础架构。 我们有一个私有数据中心 ,其中包含大量计算集群和公共云-AWS + Azure ,用于托管应用程序。 每个租户都可以根据其数据+计算隔离需求选择专用的VPC或VNet。 开发和培训阶段主要在私有数据中心中进行,而经过培训的模型则部署到云中。 为了确保在3个不同环境中的无缝操作,我们利用Kubernetes (K8)作为我们的操作和部署的抽象层。
The initial focus was more on hardening the inference scalability and deployments. For this we selected Airflow which has been battle tested and proven in our operations. We deployed Airflow on K8s, using the K8s Executor to achieve parallelism across 100s of pipelines spawning 1000s of containers.
最初的重点是加强推断的可伸缩性和部署。 为此,我们选择了经过实战测试并在我们的运营中得到证明的Airflow。 我们使用K8s Executor 在K8s上部署了Airflow ,以实现100多个管道的并行性,从而产生了1000多个容器。
Development for ML pipelines is usually done in Jupyter converted to python scripts and tested in Docker. To scale the training workflow and enable rapid experimentation we choose Kubeflow, since this blends well with our K8s stack. MLFlow was selected as a model registry and experiment tracker since it gives a good REST-based interface to abstract model versions.
ML管道的开发通常在Jupyter中完成,然后转换为python脚本并在Docker中进行测试。 为了扩展培训工作流程并进行快速实验,我们选择Kubeflow ,因为它可以与我们的K8s堆栈很好地融合在一起。 MLFlow被选为模型注册和实验跟踪器,因为它为抽象模型版本提供了一个基于REST的良好接口。
Our workflow is shown in the diagram below.
我们的工作流程如下图所示。
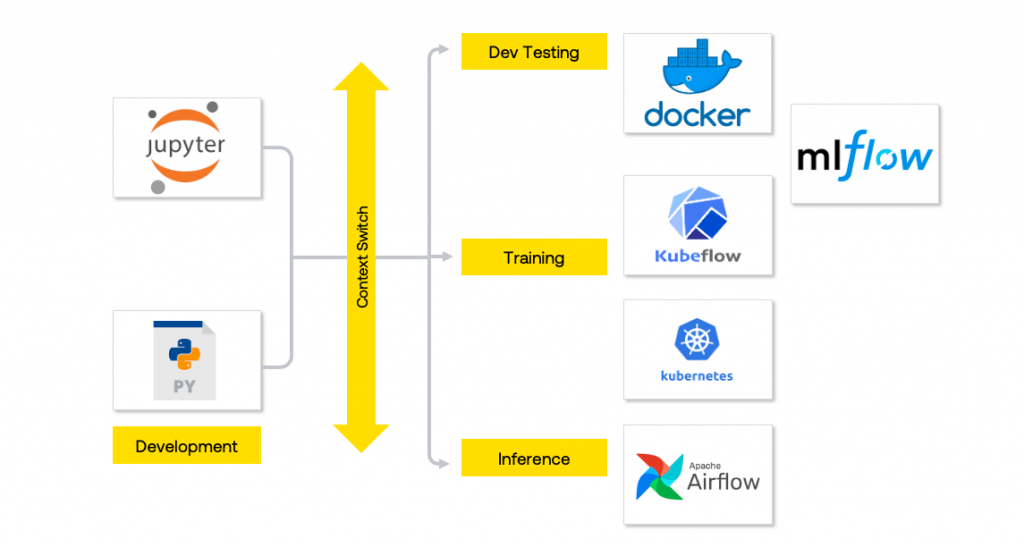
Context Switch: Training to Production — Training is different from inference in pipeline steps, infra (GPU -> CPU) and tech stack (refer pic Above) which causes developers to factor for all these in their code. For example, a developer needs to do the following.
上下文切换:从培训到生产—培训与流水线步骤,红外线(GPU-> CPU)和技术堆栈(请参见上图)的推理不同,后者导致开发人员将所有这些因素都纳入代码中。 例如,开发人员需要执行以下操作。
- Develop experiment in Jupyter 在Jupyter中进行实验
- Create a Training pipeline in Kubeflow 在Kubeflow中创建培训管道
- Test the training pipeline using Docker container 使用Docker容器测试训练管道
- Deploy pipeline to Kubeflow + GPU instances 将管道部署到Kubeflow + GPU实例
- Write an airflow DAG for the inference pipelines 为推理管道编写气流DAG
- Test the inference within Docker 在Docker中测试推理
- Deploy inference pipeline to Airflow + CPU instances 将推理管道部署到Airflow + CPU实例
摘要 (Summary)
So far, we have seen the challenges in building AI Applications due to the following factors.
到目前为止,由于以下因素,我们已经看到了构建AI应用程序的挑战。
- Enterprise AI applications have more layers of complexity added due to the end users it serves and the cost involved in decision making. 由于企业AI应用程序所服务的最终用户以及决策所涉及的成本,因此增加了更多的复杂性。
- Iterative nature of ML pipeline development and deployment necessitates that we factor for explorative development with room for experimentation. ML管道开发和部署的迭代性质使得我们必须将探索性开发与实验空间一起考虑在内。
- Tech stack and infrastructure variations pose a selection problem. This also causes syntax variations which leads to context switches. 技术堆栈和基础架构的变化带来了选择问题。 这也会导致语法变化,从而导致上下文切换。
- Constraint when promoting ML pipeline from Model development to Production Readiness stages. To ensure the code being promoted to production is maintainable it needs to be modular and reusable. 限制从模型开发到生产就绪阶段的机器学习管道的推广。 为了确保升级到生产的代码是可维护的,它需要模块化和可重用。
When designing a system there are always trade-offs involved and being aware of these helps in making an educated choice. In Part 2 of this blog we start by exploring some of these trade-offs and do an impact analysis on pursuing one set over the other. This will pave the way to define the Design Goals which were most relevant to Noodle and which are the foundation in building a novel in-house ML framework which we call Atlas. We will do a brief walkthrough of developing and deploying an ML pipeline using Atlas.
在设计系统时,总是要权衡取舍,意识到这些因素有助于做出明智的选择。 在此博客的第2部分中,我们首先探讨其中的一些取舍,并对追求一套优于另一套进行影响分析。 这将为定义与Noodle最相关的设计目标铺平道路,这些目标是构建新颖的内部ML框架(称为Atlas)的基础。 我们将简要介绍使用Atlas开发和部署ML管道的过程。














 1048
1048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









