





卷积神经网络图片滤镜
将CoreML用于iPhone的复杂视频滤镜和效果 (Using CoreML for complex video filters and effects for iPhone)
In a previous project, I worked on replicating fast neural style transfer, transforming an image by taking the artistic styling from one image and applying it to another image through deep neural networks. While transforming images in a python notebook works well, it is not very accessible to the average user. I wanted to deploy the model on an iOS device similar to the Prisma app made popular a few years ago. More than that, I wanted to test the limits of a generative model and transform frames on live video feed. The goal of this project was to run a generative model on real time video, exploring what is possible given the current boundaries of the technology. There are a few things that made this possible — 1) scaling inputs, 2) utilizing the device’s GPU, and 3) simplifying the model. Since this builds upon the previous project, some familiarity with the previous post will be helpful.
在先前的项目中 ,我致力于复制快速的神经样式转换,通过从一个图像获取艺术样式并将其通过深度神经网络应用于另一图像来转换图像。 虽然在python笔记本中转换图像效果很好,但普通用户不太容易使用。 我想将该模型部署在类似于几年前流行的Prisma应用程序的iOS设备上。 不仅如此,我还想测试生成模型的局限性,并在实时视频源上转换帧。 该项目的目标是在实时视频上运行生成模型,探索在当前技术限制下可能实现的目标。 有几件事使之成为可能:1)缩放输入,2)利用设备的GPU,以及3)简化模型。 由于这是基于先前的项目,因此对先前的帖子有所了解会有所帮助。
缩放输入 (Scaling Inputs)
Many phones today can take stunning 4k videos, including the iPhone XS that I developed on. While the A12 chip in the device is powerful, it would be far too slow to use a deep neural network on every frame of that size. Usually video frames are downscaled for image recognition on devices and the model is run on a subset of frames. For instance, an object recognition app may run a model every second on a 224 x 244 frame, instead of 30 times per second on a 4096 x 2160 frame. That works in an object detection use case, as objects don’t change that much between frames.
如今,许多手机都可以拍摄令人惊叹的4k视频,包括我开发的iPhone XS。 尽管设备中的A12芯片功能强大,但要在该大小的每个帧上都使用深度神经网络实在太慢了。 通常,视频帧会按比例缩小以在设备上进行图像识别,并且模型会在一部分帧上运行。 例如,对象识别应用可以在224 x 244帧上每秒运行一次模型,而不是在4096 x 2160帧上每秒运行30次。 这适用于对象检测用例,因为对象在帧之间的变化不大。
This obviously won’t work for stylizing video frames. Having only a single stylized frame flicker every second would not be appealing to a user. However, there are some takeaways from this. First, it is completely reasonable to downscale the frame size. It is common for video to be streamed at 360p and scaled up to the device’s 1080p screen. Second, perhaps running a model on 30 frames per second is not necessary and a slower frame rate would be sufficient.
这显然不适用于样式化视频帧。 每秒钟只有一个样式化的框架闪烁不会吸引用户。 但是,这有一些要点。 首先,缩小帧大小是完全合理的。 视频通常以360p进行流传输并放大到设备的1080p屏幕。 其次,也许没有必要以每秒30帧的速度运行模型,并且较低的帧速率就足够了。
There is a trade-off between model resolution and frame rate, as there are a limited number of computations the GPU can make in a second. You may see some video chat platforms have a slower frame rate or more buffering when using convolutions for video effects (i.e. changing the background). To get a sense of what different frame rates and input shapes looked like, I created a few stylized videos on a computer with the original neural network and OpenCV. I settled on a goal frame rate of 15 fps with 480 x 853 inputs. I found these to still be visually appealing as well as recognizable numbers for benchmark testing.
在GPU每秒可以进行的计算数量有限的情况下,模型分辨率和帧速率之间需要权衡取舍。 当使用卷积进行视频效果(即更改背景)时,您可能会看到某些视频聊天平台的帧速率较慢或缓冲更多。 为了了解不同的帧频和输入形状,我在具有原始神经网络和OpenCV计算机上创建了一些程式化的视频。 我确定了使用480 x 853输入的15 fps目标帧速率。 我发现这些在视觉上仍然很吸引人,并且对于基准测试而言也是可识别的数字。
利用GPU (Utilizing the GPU)
I used tfcoreml and coremltools to transform the Tensorflow model to a CoreML model. A gist of the complete method can be found below. There were a couple of considerations with this. First, I moved to batch normalization instead of instance normalization. This was because CoreML does not have an instance normalization layer out of the box, and this simplified the implementation since only one frame would be in each batch at interference time. A custom method could also be used in tfcoreml to convert the instance normalization layer.
我使用tfcoreml和coremltools将Tensorflow模型转换为CoreML模型。 完整方法的要点可以在下面找到。 有两个考虑因素。 首先,我转向批处理规范化,而不是实例规范化。 这是因为CoreML没有开箱即用的实例规范化层,这简化了实现,因为在干扰时间每批中只有一帧。 tfcoreml中也可以使用自定义方法来转换实例规范化层。
Next, the tensor shapes differ between TensorFlow and CoreML. The TensorFlow model has an out in (B, W, H, CH) while CoreML supports (B, CH, W, H) for images. After converting the model to a CoreML model, I edited the model spec to have a transpose layer to adjust to shape. Only after changing the model output shape to the format (B, CH, W, H) did I change the output type to an image. This something that has to manually be done on the model spec; as of this writing tfcoreml supports images as inputs as a parameter but not outputs.
接下来,TensorFlow和CoreML之间的张量形状有所不同。 TensorFlow模型的输出为(B,W,H,CH),而CoreML支持图像的(B,CH,W,H)。 将模型转换为CoreML模型后,我编辑了模型规范,以具有可调整形状的转置层。 仅在将模型输出形状更改为格式(B,CH,W,H)后,才将输出类型更改为图像。 这必须在模型规格上手动完成; 在撰写本文时,tfcoreml支持将图像作为输入作为参数,但不支持输出。
Additionally, since I downscaled the images to pass them through the network, I was able to add an upscaling layer using coremltools to bring the image to to a reasonable 1920 x 1080 frame size. An alternative would be to resize the pixel buffer after getting the result of the network, but this would either involve work from the CPU or additional queueing on the GPU. CoreML’s resize layer has a bilinear scaling and provided satisfactory upscaling with few feature or pixel artifacts. Since this resizing layer is not based on convolutions, it also added minimal time to the model inference time.
另外,由于我缩小了图像的大小以使其通过网络,因此我能够使用coremltools添加一个放大层,以将图像调整为合理的1920 x 1080帧大小。 一种替代方法是在获取网络结果后重新调整像素缓冲区的大小,但这将涉及CPU的工作或GPU上的其他排队。 CoreML的调整大小层具有双线性缩放,并提供了令人满意的向上缩放,几乎没有特征或像素伪像。 由于此调整大小层不是基于卷积,因此它还为模型推断时间增加了最少的时间。
One final way I utilized the GPU was in displaying the frames. Since I added custom processing to the frames, I could not send them directly to standard AVCaptureVideoPreviewLayer. I used an MTKView from the Metal Kit to present the frames, which utilizes the GPU. While the Metal shader was a simple pass through function (the input was returned as the output), the drawing proved performant and the queues in the view were also helpful in the event that a frame was dropped.
我利用GPU的最后一种方法是显示帧。 由于我向帧添加了自定义处理,因此无法将它们直接发送到标准AVCaptureVideoPreviewLayer。 我使用了金属套件中的MTKView来显示框架,该框架利用了GPU。 虽然“金属着色器”是一个简单的传递函数(输入作为输出返回),但是图形被证明是高性能的,并且在视图中的队列在掉落框架时也很有用。
简化模型架构 (Simplifying the model architecture)
The original model architecture had five residual convolutional layers. While very performant on a standard GPU this was too deep for a the A12 processor, at least for a typical frame rate. One primary component for the neural net to learning a variety of textures is the five residual blocks. If a texture is simple, the later residual layers may look closer to identity filters. If the texture is more complex, all layers may have meaningful filters. I experimented with trimming out some of these blocks for a more performant network, at the cost of not being able to learn some highly complex textures. Additionally, I experimented with separable convolutional layers instead of traditional fully connected layers, as used in other light weight architectures such as MobileNets.
原始模型体系结构具有五个残留卷积层。 虽然在标准GPU上表现非常出色,但对于A12处理器而言还是太深了,至少对于典型帧速率而言是如此。 神经网络学习各种纹理的一个主要组成部分是五个残差块。 如果纹理简单,则后面的残留层可能看起来更靠近标识过滤器。 如果纹理更复杂,则所有图层可能都具有有意义的滤镜。 我尝试修剪掉其中一些块以获得更高性能的网络,但以无法学习一些高度复杂的纹理为代价。 另外,我尝试了可分离的卷积层,而不是像其他轻量级体系结构(如MobileNets)中使用的传统的完全连接层。
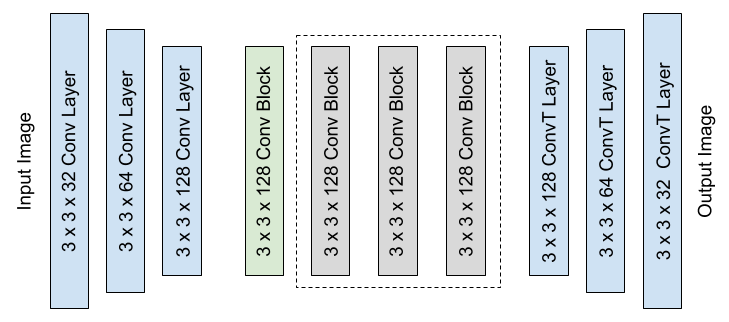
I tested several different architectures on a computer GPU to narrow down the most performant networks with minimal degradation in texture. I kept the downscaling and upscaling from the original architecture largely consistent though I only used 3 x 3 sized kernels. Some changes (reducing the residual blocks to 1, narrowing the number of filters to 64) had fast inference times, but had a high degradation in quality. Afterward the GPU testing I tested the models on an iPhone XS with an A12 chip.
我在计算机GPU上测试了几种不同的体系结构,以缩小性能最差的网络,同时使纹理降级最小。 尽管我只使用3 x 3大小的内核,但我在原始体系结构上进行的降级和升级在很大程度上保持了一致。 某些更改(将残留块减少到1,将过滤器的数量减少到64)具有快速的推理时间,但是质量下降很大。 在进行GPU测试之后,我在配备A12芯片的iPhone XS上测试了这些模型。

These are the results (in milliseconds) of a benchmark test of 100 iterations, with an input frame size of 480 x 853. The first frame was omitted since it was an outlier from the model “starting up”. One interesting take from these results is that the separable convolutional blocks did not make the network more performant. Separable convolutional layers are often difficult to implement for efficiency. I’ve read a variety cases in which the separable layers do not perform as anticipated in different environments, which could be the case here as well and this deserves more investigation.
这些是100次迭代的基准测试的结果(以毫秒为单位),输入帧大小为480 x853。由于第一帧与模型“启动”不同,因此省略了第一帧。 从这些结果中得出的一个有趣的结论是,可分离的卷积块并未使网络具有更高的性能。 为了提高效率,可分离的卷积层通常难以实现。 我读过各种情况,其中可分离的层在不同的环境中无法达到预期的效果,在这里也可能是这种情况,这值得进一步研究。
I used the 3 full (not separable) residual blocks for the following results. This model worked very well on a variety of styles and cases. With 15 fps being 66 milliseconds per frame, this implementation was probably the upper bound of the device with this implementation as there were a couple of occurrences of dropped frames or lag.
我将3个完整(不可分离)的残差块用于以下结果。 该模型在各种样式和案例上都非常有效。 15 fps是每帧66毫秒,此实现可能是此实现的设备上限,因为会发生丢帧或延迟的情况。
结果与注意事项 (Results and Considerations)
Below are some examples with different styles and textures applied. These results display much more complex effects for video on a mobile device than currently popular effects that only use shaders or a single filter.
下面是一些应用了不同样式和纹理的示例。 与仅使用着色器或单个滤镜的当前流行效果相比,这些结果在移动设备上显示的视频效果要复杂得多。
One learning from this experiment is that the trimmed neural architecture does not generalize on all styles, since there are fewer layers to decompose the image. This is most apparent on complex styles that transform the objects in the image more. Transformation with neural networks is a difficult problem to solve so this is not surprising. The mosaic style is a great example of this problem. My implementation repeats similar tessellations in the image compared to the more complex features other implementations contain, which use the full network in post processing. Simpler styles, on the other hand, such as “The Scream” and the generic sketch texture performed quite well and were similar to what would be anticipated from the full architecture.
从该实验中学到的一项知识是,修剪后的神经体系结构并不能在所有样式上通用,因为分解图像的层数较少。 这在复杂的样式上最为明显,这些样式可以更多地变换图像中的对象。 用神经网络进行转换是一个很难解决的问题,因此这不足为奇。 马赛克样式是此问题的一个很好的例子。 与其他实现所包含的更复杂的功能相比,我的实现在图像中重复了类似的细分,后者在后期处理中使用了整个网络。 另一方面,“尖叫”和通用的草图纹理等较简单的样式效果很好,并且与整个体系结构中预期的样式相似。
Another shortcoming was the lack of generalized hyper-parameters. With the trimmed network, I found no single reliable set of hyper-parameters that worked for most styles. Once again, the mosaic style had room for improvement here, as content component was sacrificed with the hope of having more complex style features.
另一个缺点是缺乏广义的超参数。 使用修剪后的网络,我发现没有适用于大多数样式的一组可靠的超参数。 马赛克样式再次有待改进的地方,因为牺牲了内容成分,希望具有更复杂的样式特征。
With future advancements in hardware, being able to use larger neural networks is inevitable. Along with more complex networks, more complex styles, textures, and even object transformations may be possible. For now, this shows that a variety of filters and effects can be developed for use in real time video content like social media.
随着硬件的未来发展,使用更大的神经网络是不可避免的。 除了更复杂的网络外,更复杂的样式,纹理甚至对象转换都是可能的。 目前,这表明可以开发各种滤镜和效果,以用于社交媒体等实时视频内容。
相关工作 (Related Work)
Real Time Video Neural Style Transfer, Kate Baumli, Daniel Diamont, and John Sigmon — https://towardsdatascience.com/real-time-video-neural-style-transfer-9f6f84590832
实时视频神经风格转换, Kate Baumli,Daniel Diamont和John Sigmon — https://towardsdatascience.com/real-time-video-neural-style-transfer-9f6f84590832
卷积神经网络图片滤镜















 3850
3850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









