





openai-gpt
介绍 (Introduction)
Let’s start with the basics. GPT-3 stands for Generative Pretrained Transformer version 3, and it is a sequence transduction model. Simply put, sequence transduction is a technique that transforms an input sequence to an output sequence.
让我们从基础开始。 GPT-3代表Generative Pretrained Transformer版本3,它是一个序列转导模型。 简而言之,序列转导是一种将输入序列转换为输出序列的技术。
GPT-3 is a language model, which means that, using sequence transduction, it can predict the likelihood of an output sequence given an input sequence. This can be used, for instance to predict which word makes the most sense given a text sequence.
GPT-3是一种语言模型,这意味着使用序列转导,它可以在给定输入序列的情况下预测输出序列的可能性。 例如,这可以用于预测给定文本序列哪个单词最有意义。
A very simple example of how these models work is shown below:
这些模型如何工作的一个非常简单的示例如下所示:

INPUT: It is a sunny and hot summer day, so I am planning to go to the…
输入 :今天是一个炎热的夏日,所以我打算去…
PREDICTED OUTPUT: It is a sunny and hot summer day, so I am planning to go to the beach.
预计的输出 :这是一个阳光明媚的夏日,所以我打算去海滩 。
GPT-3 is based on a specific neural network architecture type called Transformer that, simply put, is more effective than other architectures like RNNs (Recurrent Neural Networks). This article nicely explains different architectures and how sequence transduction can highly benefit from the Transformer architecture GPT-3 uses.
GPT-3基于一种称为Transformer的特定神经网络架构类型,简单来说,它比RNN(递归神经网络)等其他架构更有效。 本文很好地解释了不同的体系结构,以及序列转导如何从GPT-3使用的Transformer体系结构中受益匪浅。
Transformer architectures are not really new, as they became really popular 2 years ago because Google used them for another very well known language model, BERT. They were also used in previous versions of OpenAI’s GPT. So, what is new about GPT-3? Its size. It is a really big model. As OpenAI discloses on this paper, GPT-3 uses 175 billion parameters. Just as a reference, GPT-2 “only” used 1,5 billion parameters. If scale was the only requisite to achieve human-like intelligence (spoiler, it is not), then GPT-3 is only about 1000x too small.
变压器架构并不是真正的新事物,因为它们在2年前变得非常流行,因为Google将其用于另一种非常著名的语言模型BERT 。 它们还在早期版本的OpenAI的GPT中使用。 那么,GPT-3有何新变化? 它的大小。 这是一个很大的模型。 正如OpenAI在本文中披露的那样 ,GPT-3使用了1,750亿个参数。 作为参考,GPT-2“仅”使用了15亿个参数。 如果规模是实现类人智力的唯一必要条件(破坏者,不是),那么GPT-3大约只有1000倍 。
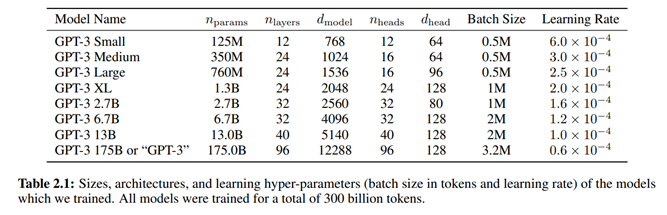
Using this massive architecture, GPT-3 has been trained using also huge datasets, including the Common Crawl dataset and the English-language Wikipedia (spanning some 6 million articles, and making up only 0.6 percent of its training data), matching state-of-the-art performance on “closed-book” question-answering tasks and setting a new record for the LAMBADA language modeling task.
使用这种庞大的体系结构,GPT-3还使用了巨大的数据集进行了训练,包括Common Crawl数据集和英语Wikipedia ( 涵盖了大约600万篇文章,仅占其训练数据的0.6% ),与“已关闭”问题解答任务的最新性能,并为LAMBADA语言建模任务创下新记录。
用例 (Use cases)
What really makes GPT-3 apart from previous language models like BERT is that, thanks to its architecture and massive training, it can excel in task-agnostic performance without fine tuning. And here is when magic comes. Since it was released, GPT-3 has been applied in a broad range of scenarios, and some developers have come with really amazing use case applications. Some of them are even sharing the best ones on github or their own websites for everyone to try:
真正使GPT-3与BERT等以前的语言模型不同的是,由于其架构和大量培训, 它无需进行微调即可在与任务无关的性能方面表现出色 。 魔法来了。 自发布以来,GPT-3已被广泛应用于各种场景中,并且一些开发人员已经提供了非常出色的用例应用程序。 其中一些人甚至在github或自己的网站上分享了最好的,供所有人尝试:
A non exhaustive list of applications based on GPT-3 are shown below:
下面显示了基于GPT-3的应用的详尽列表:
Text summarizing
文字摘要
Regular Expressions
常用表达
Natural language to SQL
SQL的自然语言
Natural language to LaTeX equations
LaTeX方程式的自然语言
Creative writing
创意写作
Interface design and coding
界面设计与编码
Text to DevOps
文字到DevOps
Automatic mail answering
自动邮件回复
Guitar tablature generation
吉他谱生成
是时候惊慌了? (Time to panic?)
The first question that comes to mind as someone working in the IT services market when seeing all these incredible GPT-3 based applications is clear: will software engineers run out of jobs due to AI improvements like these? The first thing that comes to my mind here is that software engineering is not the same as writing code. Software engineering is a much profound task that implies problem solving, creativity, and yes, writing the code that actually solves the problem. That being said, I do really think that this will have an impact on the way we solve problems through software, thanks to priming.
当看到所有这些令人难以置信的基于GPT-3的应用程序时,在IT服务市场工作的人们想到的第一个问题是明确的:由于此类AI的改进,软件工程师会不会失业吗? 我想到的第一件事是软件工程与编写代码不同。 软件工程是一项非常艰巨的任务,它意味着解决问题,发挥创造力,是的,编写实际上可以解决问题的代码。 话虽这么说,我确实认为这将对我们通过软件解决问题的方式产生影响,这要归功于启动。
Just as humans need priming to recognize something we have never noticed before, GPT-3 does too. The concept of priming will be key for making this technology useful, providing the model with a partial block of code, a good question on the problem we want to solve, etc. Some authors are already writing about the concept of “prompt engineering” as a new way to face problem solving through AI in the style of GPT-3. Again, an engineering process still requires much more that what it is currently solved by GPT-3, but it will definitely change the way we approach coding as part of it.
正如人类需要启动以识别我们之前从未注意到的事物一样,GPT-3也是如此。 启动技术的概念对于使该技术有用,为模型提供部分代码块,对我们要解决的问题的好问等,将是关键。一些作者已经在写“ 及时工程 ”的概念,例如一种以GPT-3风格通过AI面对解决问题的新方法。 同样,工程流程仍然需要比GPT-3当前解决的功能更多的东西,但是它肯定会改变我们作为其中一部分进行编码的方式。
GPT-3 has not been available for much time (and actually, access to its API is very restricted for the moment) but it is clearly amazing what developer’s creativity can achieve by using this model capabilities. Which brings us to the next question. Should GPT-3 generally available? What if this is used for the wrong reasons?
GPT-3尚待推出很长时间(实际上,目前暂时无法访问其API),但显然,使用此模型功能可以使开发人员的创造力达到惊人的程度。 这就引出了下一个问题。 GPT-3是否应普遍可用? 如果出于错误原因使用该怎么办?
Not so long ago, OpenAI wrote this when presenting its previous GPT-2 model:
不久前,OpenAI在展示其先前的GPT-2模型时写下了这一点 :
“Due to concerns about large language models being used to generate deceptive, biased, or abusive language at scale, we are only releasing a much smaller version of GPT-2 along with sampling code. We are not releasing the dataset, training code, or GPT-2 model weights.”
“由于担心使用大型语言模型大规模生成欺骗性,偏见性或辱骂性语言,我们只发布了GPT-2小得多的版本以及示例代码 。 我们不会发布数据集,训练代码或GPT-2模型权重。”
As of today, OpenAI still acknowledges this potential implications but is opening access to its GPT-3 model through a beta program. Their thoughts on this strategy can be found in this twitter thread:
直到今天,OpenAI仍然承认这种潜在的影响,但正在通过Beta程序开放对其GPT-3模型的访问。 他们对这种策略的想法可以在以下Twitter线程中找到:
It is good to see that they clearly understand that misuse of generative models like GPT-3 is a very complex problem that should be addressed by the whole industry:
很高兴看到他们清楚地了解到滥用GPT-3等生成模型是一个非常复杂的问题,整个行业都应解决:
Despite having shared API guidelines with the creators that are already using the API, and claiming that applications using GPT-3 are subject to review by OpenAI before going live, they acknowledge that this is a very complex issue that won’t be solved by technology alone. Even the Head of AI @ Facebook entered the conversation with a few examples on how, when being prompted for writing tweets over just one word (jews, black, women, etc.) GPT-3 can show harmful biases. This might have to do with the fact that GPT-3 has been trained on data filtered by Reddit and that “models built from this data produce text that is shockingly biased.”
尽管与已经使用该API的创建者共享了API准则,并且声称使用GPT-3的应用程序在上线之前需要经过OpenAI的审查,但他们承认这是一个非常复杂的问题,技术无法解决单独。 甚至AI @ Facebook的负责人也加入了一些例子,说明当提示仅用一个字(犹太人,黑人,妇女等)写推文时,GPT-3可能会显示出有害的偏见。 这可能与以下事实有关:对GPT-3进行了Reddit过滤数据的训练,并且“ 根据此数据构建的模型产生的文本有令人震惊的偏差” 。
And this is not the only threat. Advanced language models can be used to manipulate public opinion, and GPT-3 models and their future evolutions could imply huge risks for democracy in the future. Rachel Thomas shared an excellent talk on the topic that you can find here:
这不是唯一的威胁。 可以使用高级语言模型来操纵舆论,而GPT-3模型及其未来的发展可能暗示着未来民主的巨大风险。 雷切尔·托马斯(Rachel Thomas)分享了关于该主题的精彩演讲,您可以在这里找到:
Data Bias is not the only problem with language models. As I mentioned in one of my previous articles, the political design of AI systems is key. In the case of GPT-3 this might have huge implications on the future of work and also on the lives of already marginalized groups.
数据偏差并不是语言模型的唯一问题。 正如我在前一篇文章中提到的那样,人工智能系统的政治设计是关键。 就GPT-3而言,这可能对工作的未来以及已经边缘化的群体的生活产生巨大影响。
As a funny (or maybe scary) note, even GPT-3 thinks GPT-3 should be banned!
有趣的是(甚至令人恐惧的)笔记,甚至GPT-3都认为应该禁止GPT-3!
多大才够大? (How big is big enough?)
Going back to the architecture of GPT-3, training a model of 175 billion parameters is not exactly cheap in terms of computational resources. GPT-3 alone is estimated to have a memory requirement exceeding 350GB and training costs exceeding $12 million.
回到GPT-3的体系结构,训练1750亿个参数的模型在计算资源方面并不是很便宜。 据估计,仅GPT-3的内存需求就超过350GB,培训成本超过1200万美元。
It is clear that the results are amazing but, at which cost? Is the future of AI sustainable in terms of the compute power needed? Let me finish this article by using some sentences that I wrote for my “Is Deep Learning too big to fail?” article:
显然,结果令人惊讶,但是,要付出什么代价呢? 就所需的计算能力而言,人工智能的未来是否可持续? 让我用我为“ 深度学习太大而不能失败 ?”写的一些句子来结束本文。 文章:
Let’s not forget that more data does not necessarily means better data. We need quality data: unbiased and diverse data which can actually help AI benefit a lot of communities that are far from getting access to the state-of-the-art compute power like the one needed to play AlphaStar.
我们不要忘记, 更多数据并不一定意味着更好的数据 。 我们需要高质量的数据 :无偏的和多样化的数据,实际上可以帮助AI使很多社区受益,而这些社区远不能像使用AlphaStar那样获得最先进的计算能力。
Only when we use efficient algorithms (therefore accessible to the vast majority of citizens) trained with biased and diverse data will Deep Learning be too big to fail. And it will be too big because it will then serve those who are too big to be failed: the people.
只有当我们使用受过偏见且多样化的数据训练的高效算法(因此绝大多数公民都可以使用)时,深度学习的规模才会太大而无法失败。 它将太大,因为它将服务于那些太大而不会失败的人:人民。
翻译自: https://towardsdatascience.com/gpt-3-101-a-brief-introduction-5c9d773a2354
openai-gpt
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









