





对话生成 深度强化学习
介绍 (Introduction)
I grew up reading science fiction where people would try and embed their consciousness into machines. I always found these stories fascinating. What does it mean to be conscious? If I put a perfect copy of myself into a machine which one is me? If biologic me dies but mechanical copy me survives did I die? I still love stories like this and have been devouring Greg Egan lately, I’d highly recommend his book Diaspora if you think these are interesting questions (it’s only $3).
我从小阅读科幻小说,人们会尝试将其意识嵌入机器中。 我总是觉得这些故事很有趣。 有意识意味着什么? 如果我将自己的完美副本放入机器中,那我是谁? 如果生物死亡,但机械复制使我存活了,我会死亡吗? 我仍然喜欢这样的故事,最近一直吞噬Greg Egan,如果您认为这是个有趣的问题(只需3美元),就强烈推荐他的书D iaspora 。
But I digress. With today’s technology, it’s possible to make a rough approximation of a person’s speaking style with only a few lines of code. As Covid-19 has burned through the world I started to worry about the older people in my life and wonder if it would be possible to preserve a little piece of them somewhere. This tutorial is my feeble attempt at capturing and persisting some conversational aspects of a person beyond the grave.
但是我离题了。 借助当今的技术,仅需几行代码就可以大致近似一个人的讲话风格。 随着Covid-19席卷全球,我开始担心自己一生中的老年人,想知道是否有可能将一小部分老年人保存在某个地方。 本教程是我在捕捉和坚持一个人在坟墓之外的某些对话方面的微不足道的尝试。
TLDR (TLDR)
You can take your texts with any person and use them to train a simple chatbot in only a few lines of code. All code for this tutorial can be found here.
您可以将文本与任何人一起使用,并使用它们仅用几行代码即可训练一个简单的聊天机器人。 本教程的所有代码都可以在这里找到。
获取数据 (Getting Data)
In today’s world, people post so many things online and you can find an enormous amount of data, for better or worse, on most people with just a little Googling. The unfortunate, or fortunate, the reality of collecting data on the elderly is that they don’t have as strong of an online presence. My grandma doesn’t have Twitter or Facebook. If they did, they wouldn’t be posting regularly enough that I’d be able to extract any meaningful signal. So I turn to their phones.
在当今世界上,人们在网上发布了很多东西,对于大多数人来说,只要稍加使用Google搜寻功能,无论情况好坏,您都可以找到大量数据。 不幸的是,幸运的是,收集老年人数据的现实是他们没有那么强大的在线形象。 我的祖母没有Twitter或Facebook。 如果他们这样做了,他们就不会定期发布消息,以至于我无法提取任何有意义的信号。 所以我转向他们的电话。
Everyone has a phone. We use them all the time to communicate and they hold a decent record of our past conversations and interactions. They’re the perfect tool to use for capturing an initial model of someone’s conversational style. For this project, I’m going to create a conversational texting model of my father. He let me borrow his phone for a day to scrape all of the texts from it. With those texts, we’ll format them in a way that a deep conversational model can understand and fine-tune it on his texting patterns.
每个人都有电话。 我们一直在使用它们进行交流,并且它们对我们过去的对话和互动保持着不错的记录。 它们是用于捕捉某人对话风格的初始模型的理想工具。 对于这个项目,我将创建父亲的对话短信模型。 他让我借了一天电话,从中抓取了所有短信。 对于这些文本,我们将以一种深度对话模型可以理解并根据他的短信模式对其进行微调的方式来格式化它们。
提取文字 (Extracting Texts)
My dad and I both have iPhones so this tutorial will center around how to extract and process texts from an iPhone. You can make a backup of your device using iTunes but then viewing and interacting with that backup is kind of a pain. The best thing that I’ve found for extracting and processing texts from an iPhone is iMazing and this tutorial will walk you through how to use that tool. You do not need to purchase iMazing to do this walkthrough. They have a 30-day free trial which should get you through this project no problem, but if you do end up purchasing it, this is my affiliate link so if you buy it after clicking on this link I get a small kickback : ). If affiliate links feel smarmy to you just click on this one. It goes to their normal site, no kickbacks. They’ll never know I sent you.
我父亲和我都拥有iPhone,因此本教程将围绕如何从iPhone提取和处理文本展开。 您可以使用iTunes对设备进行备份,但是查看该备份并与之交互有点麻烦。 我发现从iPhone提取和处理文本的最好方法是iMazing ,本教程将引导您逐步使用该工具。 您无需购买iMazing即可完成本演练。 他们有30天的免费试用期,应该可以使您顺利完成该项目,但是如果您最终购买了该产品,则这是我的会员链接,因此,如果您在单击该链接后购买它,我会得到一笔小小的回扣: 如果会员链接对您感到肮脏,请单击此链接。 它到达了他们的正常站点,没有回扣。 他们永远不会知道我送给您的。
安卓系统 (Android)
If you’re running Android it looks like there are some software options to help you extract and backup texts. This free App seems to do the trick. I also found a post describing how to do it here. Unfortunately, since I don’t have an android phone I haven’t been able to test these methods. Though if you run into trouble formatting your data I’m happy to chat and help you debug.
如果您运行的是Android,则似乎有些软件选项可帮助您提取和备份文本。 这个免费的应用程序似乎可以解决问题。 我还在这里找到了描述如何执行此操作的帖子。 不幸的是,由于我没有Android手机,因此我无法测试这些方法。 虽然如果您在格式化数据时遇到麻烦,我很乐意聊天并帮助您调试。
苹果手机 (iPhone)
步骤1:使用iMazing创建备份 (Step 1: Create a Backup using iMazing)
Plugin your iPhone and open up iMazing. You should see your phone in the top right corner. Right-click on it and select “Back Up”. This will make a backup of your phone much like in iTunes but here you can easily access and export your data. It will probably take five to ten minutes to complete.
插入您的iPhone并打开iMazing。 您应该在右上角看到手机。 右键单击它,然后选择“备份”。 这样可以像在iTunes中一样备份手机,但是在这里您可以轻松访问和导出数据。 可能需要五到十分钟才能完成。

第2步:将数据下载为CSV (Step 2: Download the Data as a CSV)
Once the backup is made we can access our text messages by:
备份完成后,我们可以通过以下方式访问我们的短信:
- clicking on the messages icon 单击消息图标
- Selecting the conversation we want to extract 选择我们要提取的对话
- Clicking on the export to CSV button 单击导出到CSV按钮

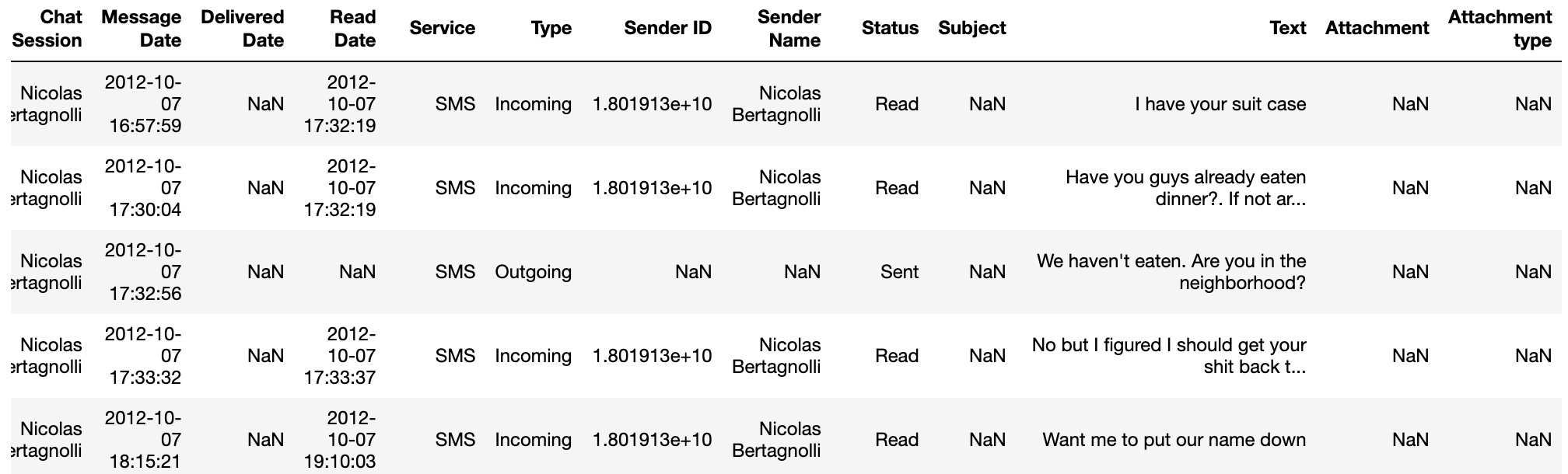
That will extract a CSV of all past texts saved on your phone between you and everyone in the conversation. The CSV has a number of fields as you can see below but we only need three of them for this project Message Date, Text, and Sender Name.
这将提取您和对话中每个人之间手机上保存的所有过去文本的CSV。 CSV具有许多字段,如下所示,但是对于该项目,“ 消息日期” ,“ 文本 ”和“ 发件人姓名” ,我们只需要其中三个即可。
准备训练数据 (Preparing the Data for Training)
Our task here is to construct example conversations to train our chatbot. The first thing is loading in the data. The below code snippet will take care of that. This code is pretty straightforward. We load in the CSV, do a little renaming and data formatting for ease of use and voila. One thing to note is that I fill in the null entries in the speaker column with a provided receiver_name. iMazing doesn’t do an amazing job of writing down who the owner of the phone is in a conversation. It leaves that position blank. So everywhere there is a missing value we can fill it in with the person who owns the phone.
我们的任务是构建示例对话以训练我们的聊天机器人。 第一件事是加载数据。 下面的代码片段将解决这个问题。 这段代码非常简单。 我们加载了CSV文件,进行了一些重命名和数据格式化,以便于使用和确认。 需要注意的一件事是,我在扬声器列中的空条目中输入了一个receiver_name. iMazing在写下通话中谁是手机所有者方面做得并不出色。 它使该位置空白。 因此,到处都有缺失的值,我们可以用手机的所有者来填充它。
With our data loaded in we now need to condense texts from the same speaker into a single line. Notice how in the first three lines of the dataset in Figure 3 I text twice to complete one thought. We need to compile all of those together so that each row of our data frame is a different speaker. This will make processing the data easier. We can use the following code to do this:
加载数据后,我们现在需要将来自同一发言人的文本压缩为一行。 请注意,在图3的数据集的前三行中,我两次输入文本以完成一个想法。 我们需要将所有这些编译在一起,以便数据帧的每一行都是不同的说话者。 这将使处理数据更加容易。 我们可以使用以下代码执行此操作:
This is a little tricky so let me walk through it. We use shift() to make a copy of the DataFrame but offset by a single row. Then we can compare every row’s sender name to it’s offset sender name. If they are different then we know we’ve transitioned speakers. We create a group_key to represent these distinct spans of text. Then we can group on this key, the date, and the sender name to get our compiled spans of text.
这有点棘手,所以让我逐步了解一下。 我们使用shift()制作DataFrame的副本,但只偏移一行。 然后,我们可以将每一行的发件人名称与其偏移的发件人名称进行比较。 如果他们不同,那么我们知道我们已经更换了发言人。 我们创建一个group_key来表示这些不同的文本范围。 然后,我们可以对该键,日期和发件人名称进行分组,以获取编译后的文本范围。
The last thing we need to do is split the data. It’s useful to have a small validation set to get a sense of generalization while training.
我们需要做的最后一件事是拆分数据。 进行训练时,有一个小的验证集很有用,以获得一种泛化感。
Here we get all of the distinct dates and then split them into either a training set or a validation set. Then we merge these splits back into the original DataFrame. This makes sure that texts that occur in the same conversation don’t end up in both the training and validation set.
在这里,我们得到所有不同的日期,然后将它们分为训练集或验证集。 然后,我们将这些拆分合并回原始的DataFrame中。 这样可以确保同一对话中出现的文本不会同时出现在训练和验证集中。
格式化用于拥抱人脸模型的数据 (Formatting the Data for Hugging Face Model)
We will be using the excellent hugging face conversational ai for this project. Facebook just released Blender which would be another cool option as your base chatbot if you have a supercomputer, but I don’t so I’m going to stick with models I can fine-tune in finite time : ).
我们将在这个项目中使用出色的拥抱式对话式人工智能 。 Facebook刚刚发布了Blender ,如果您有一台超级计算机, Blender将是您的基础聊天机器人的另一个不错的选择,但是我没有,所以我坚持使用可以在有限时间内进行微调的模型。
The data format for the Hugging Face transformer model seemed a bit confusing at first, but it was fairly easy to generate. The training data needs to be a JSON file with the following signature:
起初,Hugging Face转换器模型的数据格式似乎有些混乱,但生成起来却相当容易。 训练数据必须是具有以下签名的JSON文件:
{
"train": [
{
"personality": [
"sentence",
"sentence"
],
"utterances": [
{
"candidates": [
"candidate 1",
"candidate 2",
"true response"
],
"history": [
"response 1",
"response 2",
"etc..."
]
}
]
}
],
"valid": ...
}Let’s break this down a little bit. The larger JSON object has two main keys. “train” and “valid”. Train is the training data and is a list of personality, utterances pairs. Valid is the same but for the validation set. The personality is a list of sentences defining the personality of the speaker. See the Hugging Face tutorial for more details on this. For my model, I made the personality the name of the individual that my dad was talking to. The candidates section holds a list of possible responses to the input. This list contains some non-optimal responses to the history of the conversation where the last sentence is the ground truth response. Lastly, we have to define the history of the conversation. This is a list of strings where each position holds a new talk turn. If you want another example of how to format the data, Hugging Face has a good one in the repository you can find here.
让我们分解一下。 较大的JSON对象具有两个主键。 “培训”和“有效”。 火车是训练数据,并且是个性,言语对的列表。 有效是相同的,但对于验证集。 人格是定义说话者人格的句子列表。 有关更多详细信息,请参见“拥抱脸”教程。 对于我的模特,我将人格命名为与父亲交谈的个人的名字。 候选部分保存了对输入的可能响应的列表。 此列表包含对会话历史的一些非最佳响应,其中最后一句话是地面真相响应。 最后,我们必须定义对话的历史记录。 这是一个字符串列表,其中每个位置都有一个新的通话转弯。 如果您想了解如何格式化数据的另一个示例,那么Hugging Face在存储库中有一个不错的示例,您可以在此处找到。
训练模型 (Training the Model)
The fine people over at hugging face put together a docker container for us so setting up model training is a breeze! Simply run make build to construct the convai docker container, then run make run to enter the container in interactive mode.
善于拥抱人的人为我们放了一个docker容器,因此设置模型培训非常容易! 只需运行make build来构建convai docker容器,然后运行make run以交互方式进入该容器。
From inside the container, we can train our model. We just navigate to our project folder from inside docker and run:
从容器内部,我们可以训练模型。 我们只是从docker内部导航到我们的项目文件夹并运行:
python3 train.py --dataset_path {data-path}.json --gradient_accumulation_steps=4 --lm_coef=2.0 --max_history=4 --n_epochs=3 --num_candidates=4 --train_batch_size=2 --personality_permutations 2This took about 10 hours to train on my CPU. It should be trained on a GPU but since running it overnight is convenient enough for me I haven’t gone through the effort of setting this up on my GPUs yet.
在我的CPU上训练大约花了10个小时。 应该在GPU上对其进行培训,但是由于隔夜运行对于我来说足够方便,因此我还没有进行将其设置在GPU上的工作。
与死者说话(或者在这种情况下不死) (Speak to the Dead (Or not so dead in this case))
The last step is interacting with our conversational agent. Again the convai repository has done most of the heavy lifting for us. I made a convenience wrapper around it with make so we can simply run:
最后一步是与我们的对话代理进行交互。 再次,convai存储库为我们完成了大部分繁重的工作。 我用make对其进行了方便包装,因此我们可以简单地运行:
make interact CHECKPOINT_DIR={path-to-checkpoint} DATA={path-to-training-data}This will open up an interactive terminal where you can chat with your newly created bot. Just make sure that your models and data are in the same directory or a subdirectory of the one where the Makefile is located. What I’ve learned is that my dad and I don’t really have meaningful conversations via text. It seems like we mostly share bits of information, small talk about our day, or schedule things. The model is super good at scheduling.
这将打开一个交互式终端,您可以在其中与新创建的机器人聊天。 只要确保您的模型和数据在Makefile所在目录的同一目录或子目录中即可。 我了解到的是,我和父亲实际上并没有通过文字进行有意义的对话。 似乎我们大部分时间都在共享信息,闲聊或安排事情。 该模型非常擅长调度。
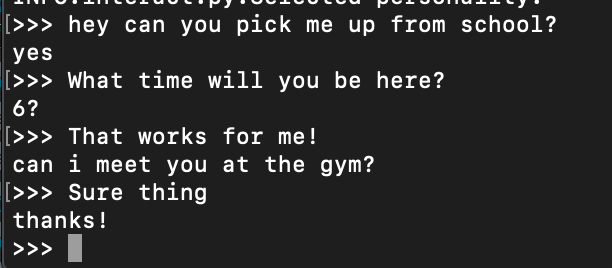
It’s not great at having a heartfelt conversation, but it does capture my dad’s writing texting style accurately. It still feels like briefly chatting with him if the conversations are short and in a domain that we would normally text about.
进行诚挚的交谈不是很好,但是它确实能够准确地捕捉到我父亲的发短信风格。 如果对话很短并且处于我们通常会发短信的领域,那感觉仍然像和他聊天。

Then again sometimes it surprises me.
然后有时又让我感到惊讶。

下一步 (Next Steps)
For short conversations inside our normal texting domain, this chatbot can feel a bit like my father. I’m going to spend the next year trying to have some deeper conversations over text and then redo this experiment next fall. I hope I can capture a little bit more information by having longer more intricate text-based conversations. As an alternate project, you could try to train a chatbot of yourself. With a you-bot, it might be fun to automate simple text conversations using something like Twilio.
对于我们普通短信领域内的简短对话,此聊天机器人可能有点像我的父亲。 我将在明年度过,试图通过文字进行更深入的对话,然后在明年秋天重做该实验。 我希望我可以通过进行更长或更复杂的基于文本的对话来捕获更多信息。 作为替代项目,您可以尝试训练自己的聊天机器人。 使用您的机器人,使用Twilio之类的工具自动进行简单的文本对话可能会很有趣。
翻译自: https://towardsdatascience.com/speak-to-the-dead-with-deep-learning-a336ef88425d
对话生成 深度强化学习
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









