





Artificial Intelligence has been a hot topic throughout the last decade, and for good reason. It is what drives the most complicated things in our society, from self driving cars to classifying PET scans, AI has the potential to help in every field imaginable. For this reason, I have decided to publish this free series on Reinforcement Learning through sequential articles that build on each other. It will go into detail on different Reinforcement Learning algorithms and teach you how to implement them in Python. No prior knowledge of Reinforcement Learning is necessary, but some knowledge of Matrices, Calculus, and basic Python are recommended so that you can grasp certain concepts. I will be sharing all of my code and data used in this series on the Github. With that being said, lets get started!
过去十年来,人工智能一直是一个热门话题,这是有充分理由的。 从无人驾驶汽车到PET扫描分类,这是推动我们社会最复杂事物发展的因素,人工智能有潜力在可以想象到的每个领域提供帮助。 出于这个原因,我决定通过相互依存的连续文章来发布关于强化学习的免费系列。 它将详细介绍不同的强化学习算法,并教您如何在Python中实现它们。 无需事先具备强化学习知识,但建议您掌握一些矩阵,微积分和基本Python知识,以便您可以掌握某些概念。 我将在Github上共享本系列中使用的所有代码和数据。 话虽如此,让我们开始吧!
Reinforcement Learning is an approach to train AI through the use of three main things:
强化学习是一种通过使用以下三个主要方面来训练AI的方法:
- An Environment 一个环境
- An Agent 代理商
- A Reward Function 奖励功能
Each of these things are crucial to making sure that the AI can effectively learn to complete a task. For this article, I will be using the popular Atari game “Breakout” as an example to show certain concepts.
所有这些事情对于确保AI可以有效学习完成任务至关重要。 在本文中,我将以流行的Atari游戏“ Breakout”作为示例来展示某些概念。
The first part of Reinforcement Learning is the environment. The environment is the world within which the Reinforcement Learning is taking place. Most of the time the Reinforcement Learning environment is identical to the environment that you are training an AI to perform in. For us, the environment would simply be the game of Atari Breakout because the goal is to train an AI that can play Atari Breakout.
强化学习的第一部分是环境。 环境是进行强化学习的世界。 大多数时候,强化学习环境与您正在训练AI的环境相同。对于我们来说,该环境只是Atari Breakout的游戏,因为目标是训练可以玩Atari Breakout的AI。
The next part of Reinforcement Learning is known as the agent. The agent is the entity that interacts with and (hopefully) learns to correctly interact with the environment. In most Reinforcement Learning algorithms, the agent is simply the AI that will be trained. This holds true for our example of Atari Breakout.
强化学习的下一部分称为代理。 代理是与之交互并(希望)学会与环境正确交互的实体。 在大多数强化学习算法中,代理只是要训练的AI。 对于我们的Atari Breakout示例来说,这是正确的。
The last, but most vital, part of Reinforcement Learning is the reward function. The reward function is an algorithm that returns a reward based on some change in the environment. In Atari Breakout, we want our agent to simply achieve as high a score as possible. We could represent this by giving the agent a reward whenever its score goes up. Reward functions are often abstract and can be defined in many ways depending on what you want the agent to do and not do within an environment. The reward for some step t is represented with the notation Rₜ.
强化学习的最后但也是最重要的部分是奖励功能。 奖励函数是一种根据环境中的某些变化返回奖励的算法。 在Atari Breakout中,我们希望我们的探员简单地取得尽可能高的分数。 我们可以通过在代理商得分提高时给予代理商奖励来代表这一点。 奖励功能通常是抽象的,可以通过多种方式定义,具体取决于您希望代理在环境中执行或不执行的操作。 某些步骤t的奖励用符号Rₜ表示。
There are several other terms that you should be familiar with:
您还应该熟悉其他几个术语:
Step — The unit of “time” within an environment. The current step is represented using the variable t while the previous step would be t - 1 and next step, t +1. When using specific integers to represent step, it starts at step 0 and increments up from there. In Atari Breakout, a step will could be represented as one frame.
步骤—环境中“时间”的单位。 当前步骤使用变量t表示,而上一步将使用t-1,而下一个步骤t +1 。 当使用特定的整数表示步长时,它从步骤0开始并从那里开始递增。 在Atari Breakout中,一个步骤可以表示为一帧。
Action — A way in which the agent interacts with its environment. It is represented with the notation Aₜ. Where t is the step at which the action was taken. In Atari Breakout, an action would be some movement of the platform.
动作—代理与其环境交互的方式。 它被表示为符号甲ₜ。 其中t是采取措施的步骤。 在Atari Breakout中,动作将是平台的某些移动。
State — The state of an environment at some specific time. It is represented with the notation Sₜ. Where t is the step at which the environment is in this state. In Atari Breakout, the state would be the current display of the game.
状态-环境在特定时间的状态。 它用符号Sₜ表示。 其中t 是环境处于此状态的步骤。 在Atari Breakout中,状态将是游戏的当前显示。
Policy — The policy is some algorithm or function that takes in the current state and outputs an action. The Agent uses this policy in order to decide what action it will take during a certain step. The policy is represented with the notation 𝜋(Sₜ).
策略-策略是某种算法或函数,可以吸收当前状态并输出一个动作。 代理使用此策略来确定在特定步骤中将采取的操作。 该策略用符号表示 𝜋(Sₜ) 。
Based on these terms the current process of our Reinforcement Learning algorithm would look something like this:
基于这些术语,我们的强化学习算法的当前过程如下所示:
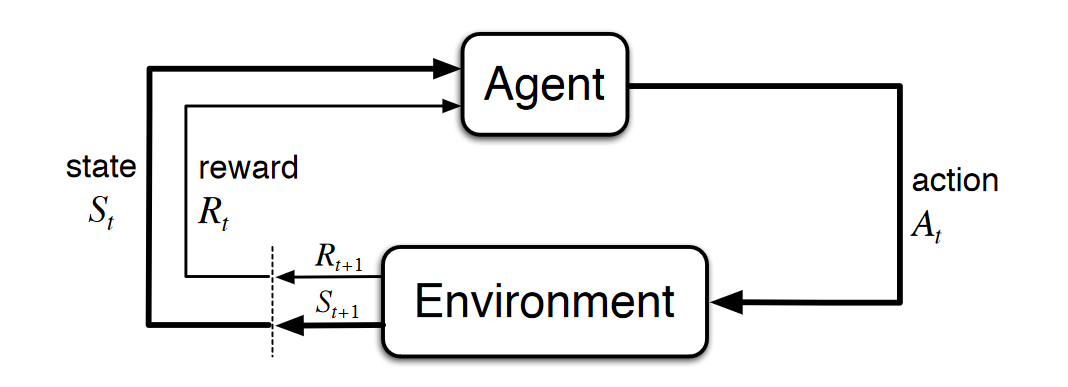
At step t the agent is given the state, Sₜ
在步骤t ,代理被赋予状态Sₜ
The agent plugs the state, Sₜ, into its policy and arrives at a selected action, aₜ. This is computed by the equation 𝜋(Sₜ) = Aₜ.
代理插入状态Sₜ , 纳入其政策并得出选定的动作aₜ 。 这由公式𝜋(Sₜ)=Aₜ计算 。
The agent takes the computed action, aₜ, within the environment.
代理在环境中采取计算出的动作aₜ 。
The environment’s state, Sₜ, is updated to Sₜ ₊ ₁, as a consequence of the action, Aₜ, and the reward, Rₜ ₊ ₁, is calculated using the user defined reward function.
作为动作Aₜ的结果,环境状态Sₜ更新为Sₜₜ ,并且使用用户定义的奖励函数来计算奖励Rₜ₊ 。
- Repeat. 重复。
You can probably already figure out the problem with this approach. The agent isn’t learning. The policy stays the same for all of the steps, so the agent will be stuck with its initial policy forever. Because of this, the agent also never makes use of the reward. In the next article, we will cover how the agent can learn and be optimized through value functions and the Bellman Equation.
您可能已经可以通过这种方法解决问题。 代理没有学习。 该策略在所有步骤中均保持不变,因此代理将永远停留在其初始策略上。 因此,代理也永远不会利用奖励。 在下一篇文章中 ,我们将介绍如何通过值函数和Bellman方程学习和优化代理。
翻译自: https://medium.com/swlh/introduction-to-reinforcement-learning-53b9caee364c















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









