





查看-增强会话
At Flipkart we’re using cutting edge technology to make it easier for the next 200 million users to adopt e-commerce. We’re focusing especially on those from smaller towns in India, where people often use their smartphone for communication and entertainment, but not yet for shopping. That’s why we’re on a journey to introduce voice solutions that will ease some of the challenges on platforms like ours.
在Flipkart,我们正在使用最先进的技术,使接下来的2亿用户更轻松地采用电子商务。 我们特别关注那些来自印度小城镇的人们,那里的人们经常使用智能手机进行通讯和娱乐,但尚未购物。 因此,我们正努力推出语音解决方案,以缓解诸如我们这样的平台上的一些挑战。
We believe voice can play an important role in bringing the clarity, comfort, and confidence these users need to shop online in their choice of language.
我们认为,语音可以在使这些用户以其选择的语言在线购物所需的清晰度,舒适度和信心方面发挥重要作用。
Understanding the diversity of the Indian market, our focus from the beginning has been that any voice-powered shopping experience we built would not only have to work well in multiple languages and dialects, but would also need to satisfy the expectations people have based on how they shop in the offline world.
了解印度市场的多样性之后,我们从一开始就将重点放在我们建立的任何语音购物体验上,不仅必须在多种语言和方言中都能很好地工作,而且还需要满足人们基于如何获得的期望他们在离线世界购物。
窥探我们的方法:语音驱动的对话式AI平台 (A peek into our approach: a voice-powered conversational AI platform)
To truly enable a voice-powered experience, we first concentrated on ensuring our solution would work well across various dimensions, such as channels and modality. This meant factoring in the multiple ways people access Flipkart, primarily through our Android app, as well as accounting for how the needs of Indian users vary across cohorts.
为了真正实现语音驱动的体验,我们首先专注于确保我们的解决方案能够在各种维度(例如渠道和模式)上正常运行。 这意味着要考虑人们主要通过我们的Android应用程序访问Flipkart的多种方式,并考虑到印度用户的需求在不同人群中的变化。
To make it easier for people who have never shopped online, we would stick to everyday language and give them a chance to use their own words, just like they can with a shopkeeper instead of using terms like cart or checkout.
为了使从未在网上购物的人们更容易使用,我们会坚持使用日常语言,让他们有机会使用自己的语言,就像他们与店主一样,而不是使用购物车或结帐之类的术语。
建立技术栈 (Building the tech stack)
We accelerated our efforts toward this goal first by onboarding the Liv team to Flipkart. Liv.ai had been working on speech recognition for more than 4 years and built a pioneering solution for ASR in 9 Indian languages, along with English. Over the last year we’ve invested further to create the platform we believe will truly redefine the experiences we can offer. The key building blocks for our solution are:
我们首先通过将Liv团队加入Flipkart来加快实现这一目标的努力。 Liv.ai致力于语音识别已经超过4年,并为9种印度语言以及英语建立了ASR的先驱解决方案。 在过去的一年中,我们进一步投资创建了平台,我们相信它将真正重新定义我们可以提供的体验。 我们解决方案的关键构建块是:
ASR (Automated Speech Recognition) which takes spoken audio as input and transcribes it into text
ASR(自动语音识别) ,将语音语音作为输入并将其转录为文本
NLP (Natural Language Processing) to interpret meaning from the recognized text
NLP(自然语言处理)以从识别的文本中解释含义
TTS (Text to Speech) for synthesizing speech when something needs to be said to the user
TTS(文本到语音),用于在需要向用户说某些内容时合成语音
Transliteration and Translation to enable mapping of text from one script to another (such as Roman to Devanagari) and translation between languages
音译和翻译功能可实现文本从一个脚本到另一个脚本的映射(例如从罗马到梵文 )以及语言之间的翻译
Dialog management to provide the intelligence behind the entire conversation
对话管理可提供整个对话背后的情报
These fit into our broader architecture:
这些适合我们更广泛的体系结构:
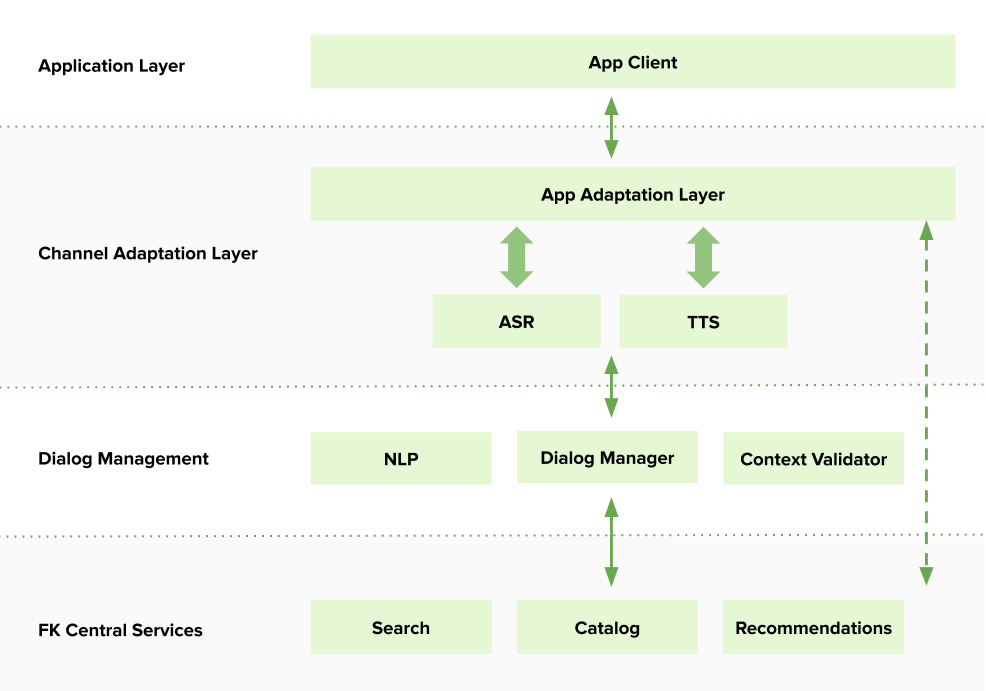
An appreciation of the deep complexities in each of the fields behind these components has informed our approach to delivering on the intricacies of human language and the conventions of conversation.
这些要素背后每个领域的深刻复杂性使我们了解了人类语言和对话惯例的复杂性。
自动语音识别(ASR) (Automated Speech Recognition (ASR))
कोस-कोस पर बदले पानी, चार कोस पर वाणी
ीबदलेबदलेीीीीीीीी
In India water changes every 1/8th of a mile and language changes every half mile
在印度,水的变化是每1/8英里,语言的变化是每半英里
Our ASR challenge has been at 3 different levels:
我们的ASR挑战分为3个不同级别:
Understanding multiple dialects
了解多种方言
Recognizing multiple dialects is one of the more challenging tasks when building an ASR for Indian languages. We’ve trained our system with data from a large set of users, across different regions of the country. This data has helped us formulate a robust model to handle the wide variation of acoustic properties across our users. For example, consider just one region for Hindi, where the dialect known as Braj Bhāshā is spoken in western parts of Uttar Pradesh, but changes to Khari Boli north and east of Delhi and becomes Awadhi as we move to eastern Uttar Pradesh. Then, heading further east and into western Bihar, Bhojpuri becomes the more prominent dialect.
为印度语言构建ASR时,识别多种方言是更具挑战性的任务之一。 我们已经使用来自全国不同地区的大量用户的数据对系统进行了培训。 这些数据帮助我们制定了一个健壮的模型,以处理整个用户声学特性的广泛变化。 例如,考虑一下印地语的一个地区,该语言在北方邦的西部地区被称为BrajBhāshā的方言,但在德里北部和东部变为Khari Boli ,并在我们移至北方邦东部时变为Awadhi 。 然后,向东延伸至比哈尔邦西部, 博普普里成为最著名的方言。
2. Understanding a combination of languages
2.理解多种语言
India is also a country of myriad regional languages intermixed with English. People often speak in more than one language in the same conversation, and frequently even within the same sentence. So we knew the ASR system we set out to build had to be smart enough to understand such multi-lingual sentences, thereby making code mixing (‘Do you have jacket dus barah saal ke ladke ki party waali?’) an integral part of our solution rather than an afterthought.
印度还是混有英语的多种地区语言的国家。 人们经常在同一对话中使用多种语言,甚至在同一句子中也经常使用。 因此,我们知道我们即将建立的ASR系统必须足够聪明,才能理解这种多语言的句子,从而使代码混合(“您有没有夹克衫吗?”)是我们不可或缺的一部分。解决方案,而不是事后思考。
Our model not only handles such combinations of languages, but it does so regardless of which display language the user has chosen within the interface. Further, we’ve integrated the ASR output with our transliteration layer (described below) to show the recognized text on the screen in the user’s chosen language. This means the user can speak in any supported language or combination thereof while also being in control of what language they see on the screen.
我们的模型不仅处理这种语言组合,而且不管用户在界面中选择了哪种显示语言,它都可以处理。 此外,我们将ASR输出与音译层(如下所述)集成在一起,以用户选择的语言在屏幕上显示可识别的文本。 这意味着用户可以使用任何受支持的语言或其组合来讲话,同时还可以控制他们在屏幕上看到的语言。
3. Understanding colloquial words created with merging of multiple languages
3.了解 由多种语言合并而成的 口语 单词
While working on solving for multiple languages, we also realized that there are colloquial variants of words which are created using merging of languages.
在解决多种语言时,我们还意识到使用语言合并创建的单词有口语变体。
An anecdote from our Product Manager Shrey Chaturvedi illustrates the commonplace occurrence of such patterns in daily Indian conversations. He says, “I was talking to one of my neighbour’s kids yesterday about his studies. He told me that ‘Bhaiya abhi to bookain hi nahi aayi in market’ (“Brother we don’t have books in the market yet”). He not only used both English and Hindi words fluently in a single sentence but also mixed both within a single word.”
我们产品经理Shrey Chaturvedi的轶事说明了这种模式在印度日常对话中的普遍现象。 他说:“昨天我正在和邻居的一个孩子谈论他的学业。 他告诉我, “ Bhaiya abhi to bookain hi nahi aayi在市场上” (“兄弟,我们现在还没有书在市场上”)。 他不仅在单个句子中流利地使用了英语单词和印地语单词,而且还在单个单词中混合使用了这两个单词。”
The combination word the boy used, bookain (pronounced ‘book-en’), refers to the plural of book, naturally combining the English word book with the Hindi word buken (बुकें), simply by adding -ain (ऐं) instead of -s.
该组合字的男孩使用,bookain(发音为“书恩”),是指书的多,自然结合与印地文单词布肯 (बुकें)英文单词的书籍 ,只要加入-而不是AIN(ऐं) - s 。
We have trained our model with such variants in their spoken and written forms. This has helped us understand colloquial forms of language in a better way.
我们已经通过口头和书面形式的此类变体训练了我们的模型。 这有助于我们更好地理解口语形式的语言。
自然语言处理(NLP) (Natural Language Processing (NLP))
Our custom Natural Language Processing (NLP) model works on multi-language input in Devanagari script. We anticipated more natural language queries for our assistant solution than when people type their entries. For example, when it comes to voice queries, in addition to asking for “aashirvaad atta,” we expect people to use phrases like “I want to buy aashirvaad atta 5 kilo waala”.
我们的自定义自然语言处理(NLP)模型可处理Devanagari脚本中的多语言输入。 与人们键入条目时相比,我们期望对助理解决方案的自然语言查询会更多。 例如,在语音查询中,除了要求“ aashirvaad atta”外,我们还希望人们使用“ 我想购买5公斤Waala的aashirvaad atta ”之类的短语。
Handling multi-language input together helps us identify the right intents and entities from user queries. In the above example, our NLP model will disseminate this user query into the following:
一起处理多语言输入有助于我们从用户查询中识别正确的意图和实体。 在上面的示例中,我们的NLP模型会将这个用户查询传播到以下内容中:
Intent: Buy (I want to buy)Entities: Aashirvaad (brand), atta (product), 5 kilo (weight)
目的 :购买(我要购买) 实体 :Aashirvaad(品牌),atta(产品),5公斤(重量)
文字转语音 (Text-to-Speech)
While choosing the right solution for Text-to-Speech (TTS) in the conversation design experience it was important for us to stay true to Flipkart’s core brand attributes as well as build something tailored for e-commerce use cases. We decided to develop our system with a voice assistant’s personality traits in mind, such as being optimistic, helpful, and sincere.
在对话设计经验中选择正确的文本语音转换(TTS)解决方案时,对我们而言,忠于Flipkart的核心品牌属性以及构建针对电子商务用例的定制产品非常重要。 我们决定在开发系统时要考虑语音助手的个性特征,例如乐观,乐于助人和真诚。
We also had to ensure that it works optimally while speaking both English and Hindi, even together within the same sentence, just like our users do. For this, we trained a single model with both English and Hindi data to be able to handle multi-language as part of our TTS output. We also used data specific to e-commerce when training the model to ensure it does well for our context.
我们还必须确保在说英语和北印度语的同时,即使在同一句子中一起使用,也能像我们的用户一样最佳地工作。 为此,我们使用英语和北印度语数据训练了一个模型,从而能够处理多语言,这是我们TTS输出的一部分。 在训练模型时,我们还使用了特定于电子商务的数据,以确保该模型对我们的环境适用。
音译 (Transliteration)
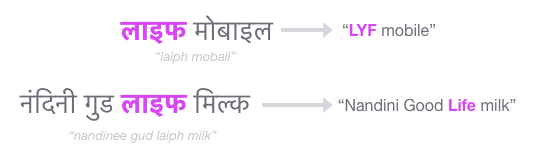
Another key component is the common language model we use in both our ASR and transliteration/translation. It makes it possible for our system to understand e-commerce queries within their context, thereby adding robustness when processing tricky elements such as homonyms. For example, consider having to distinguish that “लाइफ मोबाइल” (pronounced in phonetic Hindi as “laiph mobail”) should be transliterated to “LYF mobile” while “नंदिनी गुड लाइफ मिल्क” (pronounced “nandinee gud laiph milk”) should be transliterated to “Nandini Good Life Milk”.
另一个关键组成部分是我们在ASR和音译/翻译中使用的通用语言模型。 这使我们的系统能够在其上下文中理解电子商务查询,从而在处理诸如同音异义之类的棘手元素时增加了鲁棒性。 例如,考虑到必须区分“लाइफमोबाइल”(在北印度语发音为“ laiph mobail ”)应音译为“ LYF mobile”,而“नंदिनीगुडाइफमिल्मिल”(发音为“ nandinee gud laiph milk ”)应音译到“ Nandini好生活牛奶”。
It is through these advancements in data science modeling for ASR and transliteration components that we are building our foundation for broad language and dialect support as we continue to expand our full solution.
通过在ASR和音译组件的数据科学建模方面的这些进步,我们在继续扩展完整解决方案的同时,为广泛的语言和方言支持奠定了基础。
对话管理器 (Dialog Manager)
Dialog Manager is the central component which powers end-to-end conversations with our users in 3 ways:
对话管理器是中央组件,可通过3种方式促进与用户的端到端对话:
- It serves up the multi-modal experience with our assistant by driving functionality within the app’s interface. This makes it possible for users to see or hear results and interact directly with the screen during a voice conversation. Our novel approach gives them the flexibility to easily switch modality between talking and tapping to adapt the experience to their pace and comfort level. 通过在应用程序界面中驱动功能,它可以与我们的助手一起提供多模式体验。 这使用户可以在语音对话期间看到或听到结果并直接与屏幕进行交互。 我们新颖的方法使他们能够灵活地在通话和轻按之间切换模式,以使体验适应他们的步调和舒适度。
- It acts as an orchestrator between App Adapter (see diagram above) and other machine learning models like ASR, NLP, and TTS 它充当App Adapter(请参见上图)与其他机器学习模型(例如ASR,NLP和TTS)之间的协调器
- It also helps us keep conversations contextual through the Context Management module within it 它还可以帮助我们通过其中的“上下文管理”模块将对话保持上下文相关
Finally, we are concentrating on the problem of context management so that the conversation and visual elements can work synchronously, one of the biggest problems we have had to address. Consider how someone might say, “Give me the third product” or when our assistant asks, “Do you want to add this to your basket?”. Knowing what ‘the third product” and ‘this’ are referring to requires complex synchronization of screen, voice, and data elements. But it is challenges like these that we find exciting and well worth our continuous efforts.
最后,我们专注于上下文管理问题,以便对话和可视元素可以同步工作,这是我们必须解决的最大问题之一。 考虑一下有人会怎么说“给我第三种产品”,或者当我们的助手问“您要将它添加到购物篮中吗?”时,请考虑一下。 要知道“第三产品”和“这个”指的是什么,需要屏幕,语音和数据元素的复杂同步。 但是,正是这些挑战使我们感到振奋,值得我们继续努力。
下一步是什么? (What’s next?)
Our first milestone toward bringing voice-powered shopping to Flipkart users was to launch an end-to-end assistive voice experience for grocery shoppers on our Android app. Many of those using this feature are new to our platform and we are delighted to be part of their shopping journey.
我们向Flipkart用户提供语音购物的第一个里程碑是在我们的Android应用上为杂货店购物者提供端到端的辅助语音体验。 许多使用此功能的人是我们平台上的新手,我们很高兴能参与他们的购物之旅。
In the coming months we will be expanding our assistant and other voice-based features to support additional categories and make it possible for more users to access Flipkart with natural language.
在接下来的几个月中,我们将扩展我们的助手和其他基于语音的功能,以支持其他类别,并使更多的用户可以使用自然语言访问Flipkart。

This is only the beginning and we are grateful for every step of this journey to bring the ease and comfort of voice shopping to our users in this land of language.
这仅仅是开始,我们感谢在此语言世界中为用户提供语音购物的便捷性的旅程中的每一步。
翻译自: https://tech.flipkart.com/the-future-of-voice-powered-shopping-in-the-land-of-language-db50c99edd77
查看-增强会话
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









