





mc2180 刷机方法
深层加固学习介绍— 14 (DEEP REINFORCEMENT LEARNING EXPLAINED — 14)
In this new post of the “Deep Reinforcement Learning Explained” series, we will improve the Monte Carlo Control Methods to estimate the optimal policy presented in the previous post. In the previous algorithm for Monte Carlo control, we collect a large number of episodes to build the Q-table. Then, after the values in the Q-table have converged, we use the table to come up with an improved policy.
在“ 深度强化学习解释 ”系列的这一新文章中,我们将改进蒙特卡洛控制方法,以估计前一文章中提出的最佳策略。 在以前的蒙特卡洛控制算法中,我们收集了大量事件以构建Q表。 然后,在Q表中的值收敛之后,我们使用该表提出一种改进的策略。
However, Monte Carlo prediction methods can be implemented incrementally, on an episode-by-episode basis and this is what we will do in this post. Even though the policy is updated before the values in the Q-table accurately approximate the action-value function, this lower-quality estimate nevertheless still has enough information to help propose successively better policies.
但是, 可以在逐集的基础上逐步实现 Monte Carlo预测方法,这是我们在本文中将要做的。 即使在Q表中的值准确地逼近行动值函数之前就更新了策略,但此较低质量的估算仍然有足够的信息来帮助提出相继更好的策略。
Furthermore, the Q-table can be updated at every time step instead of waiting until the end of the episode using Temporal-Difference Methods. We will review them also in this post.
此外,可以使用时间差异方法在每个时间步 更新 Q表,而不必等到情节结束 。 我们还将在这篇文章中对其进行审查。
蒙特卡洛控制的改进 (Improvements to Monte Carlo Control)
In the previous post we have introduced how the Monte Carlo control algorithm collects a large number of episodes to build the Q-table ( policy evaluation step). Then, once the Q-table closely approximates the action-value function qπ, the algorithm uses the table to come up with an improved policy π′ that is ϵ-greedy with respect to the Q-table (indicated as ϵ-greedy(Q) ), which will yield a policy that is better than the original policy π (policy improvement step).
在上一篇文章中,我们介绍了蒙特卡洛控制算法如何收集大量情节以构建Q表( 策略评估步骤)。 然后,一旦Q表紧密接近动作值函数qπ ,该算法就会使用该表提出一个改进的策略π' ,相对于Q表为ϵ -greedy(表示为ϵ-greedy( Q) ),这将产生比原始策略π ( 策略改进步骤)更好的策略。
Maybe would it be more efficient to update the Q-table after every episode? Yes, we could amend the policy evaluation step to update the Q-table after every episode of interaction. Then, the updated Q-table could be used to improve the policy. That new policy could then be used to generate the next episode, and so on:
也许在每个情节之后更新Q表会更有效吗? 是的,我们可以修改策略评估步骤,以在每次互动之后更新Q表。 然后,可以使用更新后的Q表来改进策略。 然后可以使用该新策略来生成下一集,依此类推:

The most popular variation of the MC control algorithm that updates the policy after every episode (instead of waiting to update the policy until after the values of the Q-table have fully converged from many episodes) is the Constant-alpha MC Control.
在每个情节之后更新策略(而不是等到Q表的值已从许多情节完全收敛之后才更新策略)的MC控制算法中,最流行的变体是Constant-alpha MC Control。
恒定alpha MC控制 (Constant-alpha MC Control)
In this variation of MC control, during the policy evaluation step, the Agent collects an episode
在MC控制的这种变化中,在策略评估步骤中,代理收集事件

using the most recent policy π. After the episode finishes in time-step T, for each time-step t, the corresponding state-action pair (St, At) is modified using the following update equation:
使用最新策略π 。 在时间步长T中完成情节结束之后,对于每个时间步长t ,使用以下更新方程式修改相应的状态-动作对(St,At) :
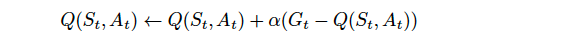
where Gt is the return at time-step t, and Q(St,At) is the entry in the Q-table corresponding to state St and action At.
其中Gt是在时间步t处的返回值 ,而Q(St,At)是Q表中与状态St和动作At相对应的条目。
Generally speaking, the basic idea behind this update equation is that the Q(St,At) element of Q-table contains the Agent’s estimate for the expected return if the Environment is in state St and the Agent selects action At. Then, If the return Gt is not equal to the expected return contained in Q(St,At), we “push” the value of Q(St,At) to make it agree slightly more with the return Gt. The magnitude of the change that we make to Q(St,At) is controlled by the hyperparameter α that acts as a step-size for the update step.
一般而言,此更新方程背后的基本思想是,如果环境处于状态St且Agent选择动作At ,则Q表的Q ( St , At )元素包含Agent对预期回报的估计。 然后,如果返回亿吨不等于预期收益包含在Q(街,在),我们的“推” Q(ST,在)的值,使之与回报亿吨略微同意。 我们对Q(St,At)所做的更改的大小由用作更新步长的超参数α控制。
We always should set the value for α to a number greater than zero and less than (or equal to) one. In the outermost cases:
我们始终应将α的值设置为大于零且小于(或等于)一的数字。 在最外层情况下:
If α=0, then the action-value function estimate is never updated by the Agent.
如果α = 0,则行动价值函数估算值永远不会由代理更新。
If α=1, then the final value estimate for each state-action pair is always equal to the last return that was experienced by the Agent.
如果α = 1,则每个状态-动作对的最终值估计始终等于代理所经历的最后一次收益。
厄普西隆贪婪政策 (Epsilon-greedy policy)
In the previous post we advanced that random behavior is better at the beginning of the training when our Q-table approximation is bad, as it gives us more uniformly distributed information about the Environment states. However, as our training progresses, random behavior becomes inefficient, and we want to use our Q-table approximation to decide how to act. We introduced Epsilon-Greedy policies in the previous post for this purpose, a method that performs such a mix of two extreme behaviors which just is switching between random and Q policy using the probability hyperparameter ϵ. By varying ϵ , we can select the ratio of random actions.
在上一篇文章中,我们提出,当我们的Q表近似值不好时,在训练开始时随机行为会更好,因为它为我们提供了有关环境状态的更均匀分布的信息。 但是,随着训练的进行,随机行为变得效率低下,我们希望使用Q表近似值来决定如何采取行动。 为此,我们在上一篇文章中介绍了Epsilon-Greedy策略,该方法执行两种极端行为的混合,仅使用概率超参数ϵ在随机策略和Q策略之间切换。 通过改变ε,我们可以选择随机行动的比率。
We will define that a policy is ϵ-greedy with respect to an action-value function estimate Q if for every state,
我们将定义一个策略 ,对于每个状态而言,对于行动值函数估计值Q 都是ϵ-贪婪 ,
with probability 1−ϵ, the Agent selects the greedy action, and
以概率1-ε,代理选择贪婪的动作,和
with probability ϵ, the Agent selects an action uniformly at random from the set of available (non-greedy and greedy) actions.
以概率ε,代理均匀地随机从所述一组可用(非贪婪和贪婪)动作中选择的动作。
So the larger ϵ is, the more likely you are to pick one of the non-greedy actions.
因此,较大的ε,越有可能你是要挑非贪婪行动之一。
To construct a policy π that is ϵ-greedy with respect to the current action-value function estimate Q, mathematically we will set the policy as
为了构建一个策略π是ε-greedy相对于当前的行动值函数估计Q,数学上,我们将设置政策

if action a maximizes Q(s,a). Else
如果动作a使Q ( s , a )最大化。 其他

for each s∈S and a∈A(s).
对于每个s∈S 和 ∈A( 多个 )。
In this equation, it is included an extra term ϵ/∣A(s)∣ for the optimal action (∣A(s)∣ is the number of possible actions) because the sum of all the probabilities needs to be 1. Note that if we sum over the probabilities of performing all non-optimal actions, we will get (∣A(s)∣−1)×ϵ/∣A(s)∣, and adding this to 1−ϵ+ϵ/∣A(s)∣ , the probability of the optimal action, the sum gives one.
在此等式中,由于最佳概率的总和必须为1,因此为最佳动作包含了额外项ϵ / ∣A( s )∣(∣A( s )∣是可能动作的数量)。如果我们总结执行所有非最佳动作的概率,我们将得到(getA(s)∣-1)×ϵ / ∣A(s)∣,并将其加到1− ϵ + ϵ / ∣A( s )∣,最佳行动的概率,总和为1。
设置Epsilon的值 (Setting the Value of Epsilon)
Remember that in order to guarantee that MC control converges to the optimal policy π∗, we need to ensure the conditions Greedy in the Limit with Infinite Exploration (presented in the previous post) that ensure the Agent continues to explore for all time steps, and the Agent gradually exploits more and explores less. We presented that one way to satisfy these conditions is to modify the value of ϵ , making it gradually decay, when specifying an ϵ-greedy policy.
请记住,为了确保MC控制收敛到最佳策略π ∗,我们需要确保无限探索中的贪婪条件(如上一篇文章所述),以确保Agent继续探索所有时间步长,而Agent会逐渐开发更多资源,而更少探索。 我们提出,要满足这些条件的一种方法是修改ε值,使得它逐渐衰减,指定ε-greedy策略时。
The usual practice is to start with ϵ = 1.0 (100% random actions) and slowly decrease it to some small value ϵ > 0 (in our example we will use ϵ = 0.05) . In general, this can be obtained by introducing a factor ϵ-decay with a value near 1 that multiply the ϵ in each iteration.
通常的做法是,以开始与ε= 1.0(100%随机动作)然后缓慢下降到一些小值ε> 0(在我们的例子中,我们将使用ε= 0.05)。 通常,这可以通过引入因子ϵ衰减来实现,该因子的衰变值接近1,并在每次迭代中将multiply相乘。
伪码 (Pseudocode)
We can summarize all the previous explanations with this pseudocode for the constant-α MC Control algorithm that will guide our implementation of the algorithm:
我们可以概括所有与此伪代码恒αMC控制算法,将引导我们实现算法的前面的解释:

一个简单的MC控制实现 (A simple MC Control implementation)
In this section, we will write an implementation of constant-𝛼 MC control that can help an Agent recover the optimal policy the Blackjack Environment following the pseudocode introduced in the previous post.
在本节中,我们将按照上一篇文章中介绍的伪代码编写一个常量𝛼 MC控制的实现,该实现可以帮助Agent恢复二十一点环境的最佳策略。
The entire code of this post can be found on GitHub and can be run as a Colab google notebook using this link.
二十一点环境的MC控制算法 (MC Control algorithm for Blackjack Environment)
In the previous post, we implemented a policy where the player almost always sticks if the sum of her cards exceeds 18 for the BlackJack Environment. In this case, the function generate_episode sampled an episode using this defined policy by the programmer.
在上一篇文章中,我们实施了一项政策,即在BlackJack Environment中,如果玩家的卡牌总数超过18张,玩家几乎总是会坚持。 在这种情况下,函数generate_episode使用程序员定义的策略对情节进行了采样。
Here, instead of being the policy hardcoded by the programmer, the MC Control algorithm will estimate and return an optimal policy, together with the Q-table:
在这里,MC控制算法将取代Q策略表,而不是由程序员对策略进行硬编码,从而估算并返回最佳策略:
env = gym.make('Blackjack-v0')
num_episodes=1000000
alpha = 0.02
eps_decay=.9999965
gamma=1.0policy, Q = MC_control(env, num_episodes, alpha, eps_decay, gamma)Specifically, policy is a dictionary whose key corresponds to a states (a 3-tuple indicating the player’s current sum, the dealer’s face-up card, and whether or not the player has a usable ace) and the value of the corresponding entry indicates the action that the Agent chooses after observing this state following this policy.
具体地说, policy是字典,其关键字对应于状态s (表示玩家当前金额的三元组,发牌人的面朝上卡以及玩家是否具有可用的ace),相应条目的值表示遵循此策略后,代理在观察此状态后选择的操作。
Remember that the other dictionary returned by the function, the Q-tableQ, is a dictionary where the key of a given entry in the dictionary corresponds to a states and the value of the corresponding entry contains an array of dimension equal to the number of actions (2 dimensions in our case) where each element contains the estimated action-value for each action.
请记住,函数返回的另一个字典Q-table Q是一个字典,其中字典中给定条目的键对应于状态s并且对应条目的值包含一个维数组,该数组等于数字动作(在我们的示例中为2维),其中每个元素都包含每个动作的估算动作值。
As input this MC Control algorithm has the following arguments:
作为输入,此MC控制算法具有以下参数:
env: The instance of an OpenAI Gym Environment.env:OpenAI Gym环境的实例。num_episodes: The number of episodes that are generated.num_episodes:生成的情节数。alpha: The step-size parameter for the update step.alpha:更新步骤的步长参数。eps_decay: The decay factor for the update of the epsilon parameter.eps_decay:epsilon参数更新的衰减因子。gamma: The discount rate.gamma:折扣率。
设置Epsilon的值 (Setting the Value of Epsilon)
Before starting to program, a code based on the previously presented pseudocode takes a moment to see how we modify the value of ϵ , making it gradually decay when specifying an ϵ-greedy policy. Remember that this is important to guarantee that MC control converges to the optimal policy π∗.
在开始编程之前,基于先前提供的伪代码的代码需要花一点时间来看看我们如何修改ϵ的值,从而在指定ϵ -greedy策略时使其逐渐衰减。 请记住,这对于确保MC控制收敛到最佳策略π ∗很重要。
With the following code that sets the value for ϵ in each episode and monitor its evolutions with a print we can check that selecting an eps_decay=0.9999965 we can obtain the gradual decay of ϵ:
用下面的代码,用于设置每一集为ε的值并监视其与演进print我们可以检查选择eps_decay = 0.9999965我们可以得到ε的逐渐衰减:
eps_start=1.0
eps_decay=.9999965
eps_min=0.05epsilon = eps_start
for episode in range(num_episodes):
epsilon = max(epsilon*eps_decay, eps_min)
if episode % 100000 == 0: print(“Episode {}
-> epsilon={}.”.format(episode, epsilon))
Before entering the loop over episodes, we initialize the value of epsilon to one. Then, for each episode, we slightly decay the value of Epsilon by multiplying it by the value eps_decay. We don’t want Epsilon to get too small because we want to constantly ensure at leans some small amount of exploration throughout the process.
在进入情节循环之前,我们将epsilon的值初始化为1。 然后,对于每个情节,我们通过将Epsilon的值乘以eps_decay稍微衰减它的值。 我们不希望Epsilon变得太小,因为我们希望在整个过程中不断确保精益勘探中的少量勘探。
主功能 (Main function)
Let’s start to program a code based on the previously presented pseudocode. The first thing, following the pseudocode, is to initialize all the values in the Q-table to zero. So Qis initialized to an empty dictionary of arrays with the total number of actions that are in the Environment:
让我们开始基于先前提供的伪代码对代码进行编程。 伪代码之后的第一件事是将Q表中的所有值初始化为零。 因此,将Q初始化为一个空的数组字典,其中包含环境中动作的总数:
nA = env.action_space.n
Q = defaultdict(lambda: np.zeros(nA)After that, we loop num_episodesover episodes, and then with each episode we compute the corresponding ϵ, construct the corresponding ϵ-greedy policy with respect to the most recent estimate of the Q-table, and then generate an episode using that ϵ-greedy policy. Finally, we update the Q-table using the update equation presented before:
之后,我们在情节上循环num_episodes ,然后针对每个情节计算对应的ϵ,针对最新的Q表估计构建相应的ϵ-贪心策略,然后使用该ϵ-贪心生成一个情节政策。 最后,我们使用前面介绍的更新公式更新Q表:
for episode in range(1, num_episodes+1):
epsilon = max(epsilon*eps_decay, eps_min)
episode_generated=generate_episode_from_Q(env,Q,epsilon,nA)
Q = update_Q(env, episode_generated, Q, alpha, gamma)After finishing the loop of episodes, the policy corresponding to the final Q-table is calculated with the following code:
完成情节循环后,将使用以下代码来计算与最终Q表相对应的策略:
policy=dict((state,np.argmax(actions)) \
for state, actions in Q.items())That is, the policy indicates for each state which action to take, which just corresponds to the action that has the maximum action-value in the Q-table.
即,该策略为每个状态指示要采取的操作,该操作恰好对应于Q表中具有最大操作值的操作。
See the GitHub for the complete code the main algorithm of our Constant-α MC Control method.
见 完整代码的GitHub是我们的Constant-αMC Control方法的主要算法。
使用Q表和epsilon-greedy策略生成剧集 (Generate episodes using Q-table and epsilon-greedy policy)
The construction of the corresponding ϵ-greedy policy and the generation of an episode using this ϵ-greedy policy are wrapped up in the generate_episode_from_Q function instantiated in the previous code.
相应的ε-贪婪策略并使用该ε-greedy政策一个插曲的产生的结构被在包裹起来generate_episode_from_Q在前面的代码实例化的功能。
This function takes as input the Environment, the most recent estimate of the Q-table, the value of current Epsilon and the number of actions. As an output, it returns an episode.
此函数将环境,Q表的最新估计,当前Epsilon的值和操作数作为输入。 作为输出,它返回一个情节。
The Agent will use the Epsilon-greedy policy to select actions. We have implemented that using the random.choicemethod from Numpy, which takes as input the set of possible actions and the probabilities corresponding to the Epsilon greedy policy. The obtention of the action probabilities corresponding to ϵ-greedy policy will be done using this code:
代理将使用Epsilon-greedy策略选择操作。 我们已经使用Numpy的random.choice方法实现了该方法,该方法将与Epsilon贪婪策略相对应的可能动作集和概率作为输入。 使用以下代码来完成与ϵ -greedy策略对应的动作概率的获得:
def get_probs(Q_s, epsilon, nA):
policy_s = np.ones(nA) * epsilon / nA
max_action = np.argmax(Q_s)
policy_s[max_action] = 1 — epsilon + (epsilon / nA)
return policy_sIf you take a look at get_probsfunction code, it implements the epsilon-greedy policy detailed in the previous section.
如果您看一下get_probs函数代码,它将实现上一节中详细介绍的epsilon-greedy策略。
Obviously, if the state is not already in Q-table, we randomly choose one action using the action_space.sample(). The complete code for this function that generates an episode following the epsilon-greedy policy is coded as follows:
显然,如果状态不在Q表中,则可以使用action_space.sample().随机选择一个动作action_space.sample(). 遵循epsilon-greedy策略生成此情节的此功能的完整代码编码如下:
def generate_episode_from_Q(env, Q, epsilon, nA):
episode = []
state = env.reset()
while True:
probs = get_probs(Q[state], epsilon, nA)
action = np.random.choice(np.arange(nA), p=probs) \
if state in Q else env.action_space.sample()
next_state, reward, done, info = env.step(action)
episode.append((state, action, reward))
state = next_state
if done:
break
return episode更新Q表 (Update Q-table)
Once we have the episode we just look at each state-action and we apply the update equation:
一旦有了情节,我们只需查看每个状态动作,然后应用更新公式:

The code that programs this equation is
对该方程进行编程的代码是
def update_Q(env, episode, Q, alpha, gamma):
states, actions, rewards = zip(*episode)
discounts=np.array([gamma**i for i in range(len(rewards)+1)])
for i, state in enumerate(states):
old_Q = Q[state][actions[i]]
Q[state][actions[i]] = old_Q + alpha \
(sum(rewards[i:]*discounts[:-(1+i)]) — old_Q)
return Q绘制状态值函数 (Plot state-value function)
As in the example of the previous post, we can obtain the corresponding estimated optimal state-value function and plot it:
如前一篇文章的示例,我们可以获得相应的估计最佳状态值函数并将其绘制成图:

Remember there are two plots corresponding to whether we do or don’t have a usable ace.
请记住,有两个图对应于我们是否具有可用的ace。
With a simple visual analysis of the graphs of this post and those of the previous post, we can see that the policy obtained with the MC Control presented here is better since the state-value values are much higher.
通过对这篇文章和以前文章的图形进行简单的视觉分析,我们可以看到,由于状态值更高,因此使用此处介绍的MC Control获得的策略更好。
时差法 (Temporal-Difference Methods)
The methods called Temporal-Difference (TD) learning are a combination of Monte Carlo (MC) ideas and dynamic programming (DP) ideas. Like MC methods, TD methods can learn directly from raw experience without a model of the Environment’s dynamics. However, like DP, TD methods update estimates based in part on other learned estimates, without waiting for a final outcome.
称为时差(TD)学习的方法是蒙特卡罗(MC)思想和动态编程(DP)思想的结合。 像MC方法一样,TD方法可以直接从原始经验中学习,而无需建立环境动力学模型。 但是,像DP一样,TD方法会部分基于其他学习的估计来更新估计,而无需等待最终结果。
Remember that the update equation for Monte Carlo Control after a complete episode is:
请记住, 完整的情节之后,蒙特卡洛控制的更新公式为:
In this update equation , we look up the current estimate Q(St,At) from the Q-table and compare it to the return Gt that we actually experienced after visiting the state-action pair. We use that new return Gt to make our Q-table a little more accurate. The only real difference between TD methods and MC methods is that TD methods update the Q-table at every time step instead of waiting until the end of the episode.
在这个更新方程中,我们从Q表中查找当前估计值Q ( St , At ),并将其与访问状态-动作对之后我们实际经历的收益Gt进行比较。 我们使用新的收益Gt来使我们的Q表更加准确。 TD方法和MC方法之间的唯一真正区别是TD方法在每个时间步更新Q表,而不必等到情节结束 。
There are three main variations called, Sarsa, Sarsamax, and Expected Sarsa, that implement three versions of the update equation. With the exception of this new update step, all the rest of the code is identical to what we saw in the Monte Carlo Control Method. Let’s see each one of them.
有三种主要变体,称为Sarsa,Sarsamax和Expected Sarsa,它们实现了更新方程的三个版本。 除了这个新的更新步骤外,其余所有代码与我们在“蒙特卡洛控制方法”中看到的相同。 让我们看看其中每个。
莎莎 (Sarsa)
With this method, we begin by initializing all action-values to zero in constructing the corresponding Epsilon Greedy policy. Then, the Agent begins interacting with the environment and receives the first state S0. Next, it uses the policy to choose the action A0. Immediately after it, it receives a reward R1 and next state S1. Then, the agent again uses the same policy to pick the next action A1. After the sequence
使用这种方法,我们在构建相应的Epsilon Greedy策略时首先将所有操作值初始化为零。 然后,代理开始与环境交互并接收第一状态S0 。 接下来,它使用策略选择动作A0 。 在此之后,它立即收到奖励R1和下一个状态S1 。 然后,代理再次使用相同的策略来选择下一个动作A1 。 顺序之后

the method updates the action-value Q-table corresponding to the previous state-action pair. However, instead of using the return as an alternative estimate for updating the Q-table, we use the sum of the immediate reward R1 and the discounted value of the next state action pair Q(S1, A1) multiplied by gamma factor:
该方法更新对应于先前状态-动作对的动作值Q表。 但是,我们没有使用回报作为更新Q表的替代估计,而是使用即时奖励R1和下一个状态动作对Q ( S1 , A1)的折现值的总和乘以伽马因子:
The update equation expressed more generally is:
更一般地表示的更新方程为:
Remember that with the exception of this new update step, the rest of the code is identical to what we did in the Monte Carlo Control case. In particular, we will use the ϵ-greedy(Q) policy to select actions at every time step.
请记住,除了这个新的更新步骤外,其余代码与我们在“蒙特卡洛控制”案例中所做的相同。 特别是,我们将使用ϵ-greedy(Q)策略在每个时间步选择动作。
Following, the reader can find a global scheme that summarizes what has been explained:
接下来,读者可以找到一个概述了所解释内容的全局方案:

萨尔萨克斯 (Sarsamax)
Another TD control method is Sarsamax, also known as Q-Learning, that works slightly differently from de Sarsa.
另一种TD控制方法是Sarsamax (也称为Q学习) ,其工作原理与de Sarsa略有不同。
This method begins with the same initial values for the action-values and the policy of Sarsa. The agent receives the initial state S0, the first A0 action is still chosen from the initial policy. But then, after receiving the reward R1 and next state S1, instead of using the same policy to pick the next action A1 (the action that was selected using the Epsilon Greedy policy), we’ll update the policy before choosing the next action.
该方法从动作值和Sarsa策略的初始值相同开始。 代理收到初始状态S0 ,仍然从初始策略中选择第一个A0动作。 但是,然后,在收到奖励R1和下一个状态S1之后 , 与其使用相同的策略选择下一个操作A1(使用Epsilon Greedy策略选择的操作), 而是在选择下一个操作之前更新策略行动 。
In particular, for the estimation, we will consider the action using a Greedy policy, instead of the Epsilon Greedy policy. That means that the will use the action that maximizes the Q(s,a) value for a given action. So the update equation for Sarsamax will be:
特别是,为了进行估算,我们将考虑使用“贪婪”策略而不是“ Epsilon贪婪”策略。 这意味着,对于给定的动作,将使用最大化Q(s,a)值的动作。 因此,Sarsamax的更新公式为:
where we rely on the fact that the greedy action corresponding to a state is just the one that maximizes the action values for that state.
我们依赖于这样一个事实,即与一个状态相对应的贪婪行为只是使该状态的行为值最大化的行为。
And so what happens is after we update the action value for time step zero using the greedy action, we then select A1 using the Epsilon greedy policy corresponding to the action values we just updated. And this continues when we received a reward and next state. Then, we do the same thing we did before where we update the value corresponding to S1 and A1 using the greedy action, then we select A2 using the corresponding Epsilon greedy policy, and so on. Following the same schematization made with sarsa, it can be visually summarized as:
因此,发生什么情况是在我们使用贪婪操作更新时间步为零的操作值之后,然后使用与刚更新的操作值相对应的Epsilon贪婪策略选择A1。 当我们获得奖励和下一个状态时,这种情况会继续。 然后,我们做与之前相同的事情,我们使用贪婪操作更新与S1和A1对应的值,然后使用相应的Epsilon贪婪策略选择A2,依此类推。 遵循与sarsa相同的模式化,可以将其直观地概括为:

预期的莎莎 (Expected Sarsa)
A final version of the update equation is Expected Sarsa. While Sarsamax takes the maximum over all actions of all possible next state-action pairs, Expected Sarsa uses the expected value of the next state-action pair, where the expectation takes into account the probability that the Agent selects each possible action from the next state:
更新方程式的最终版本是Expected Sarsa。 当Sarsamax对所有可能的下一个状态-动作对的所有动作取最大值时,Expected Sarsa使用下一个状态-动作对的期望值,其中期望值考虑了Agent从下一个状态中选择每个可能动作的概率:
Below there is a summary of the three TD update equations (and MC):
下面是三个TD更新方程式(和MC)的摘要:

All three TD methods converge to the optimal action-value function q∗ (and so yield the optimal policy π∗) if the value of ϵ decays in accordance with the Greedy in the Limit with Infinite Exploration (GLIE) conditions, and the step-size parameter α is sufficiently small.
所有这三种方法TD收敛到最优动作值函数Q *(因此产生最优策略π*)如果ε衰变按照价值与无限探索的限制贪婪 (GLIE)的条件下,与步长参数α足够小。
自举方法 (Bootstrapping Methods)
Note that TD Methods update their estimates based in part on other estimates. They learn a guess from a guess, they bootstrap. In TD methods the return starting from a state-action pair is estimated while in MC we use the exact return Gt.
请注意,TD方法部分基于其他估算值来更新其估算值。 他们从猜测中学到一个猜测,然后进行引导 。 在TD方法中,从状态动作对开始的收益是估算的,而在MC中,我们使用精确的收益Gt 。
Bootstrapping in RL can be read as “using estimated values in the update step for the same kind of estimated value”.
RL中的引导可以理解为“在更新步骤中使用相同种类的估计值的估计值”。
Neither MC methods nor one-step TD methods are always the best. The n-step Bootstrapping Methods unify the MC Methods and TD Methods, that generalize both methods so that one can shift from one to the other smoothly as needed to meet the demands of a particular task. These methods are out of the scope of this series, however, if the reader is interested in further details, he or she can start with Chapter 5 of the textbook Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto.
MC方法和单步TD方法都不总是最好的。 n步自举方法将MC方法和TD方法统一起来,将这两种方法通用化,以便一种方法可以根据需要从一个平稳地转换到另一个,以满足特定任务的需求。 这些方法不在本系列的范围之内,但是,如果读者对进一步的细节感兴趣,则可以从Richard S. Sutton和Andrew G. Barto撰写的《 强化学习:入门 》教科书的第5章开始。
策略上与策略外的方法 (On-policy vs off-policy methods)
Let’s use these presented methods to delve into one of the widely used concepts for classifying methods in Reinforcement Learning: On-policy and off-policy methods.
让我们使用这些提出的方法来研究强化学习中用于分类方法的广泛使用的概念之一:策略上和策略外的方法。
We say that Sarsa and Expected Sarsa are both on-policy TD control algorithms. In this case, the same (ϵ-greedy) policy that is evaluated and improved is also used to select actions.
我们说Sarsa和Expected Sarsa都是基于策略的 TD控制算法。 在这种情况下,也将使用经过评估和改进的相同( ϵ -greedy)策略来选择操作。
On the other hand, Sarsamax is an off-policy method, where the (greedy) policy that is evaluated and improved is different from the (ϵϵ-greedy) policy that is used to select actions.
在另一方面,Sarsamax是断开策略方法,其中被评估的和改进的(贪婪)策略是从用于选择动作(εε-greedy)策略不同。
接下来是什么? (What is next?)
We have reached the end of this post!. So far, we have presented solution methods that represent the action values in a small table, the Q-table. In the next post, we will introduce you to the idea of using neural networks to expand the size and complexity of the problems that we can solve with reinforcement learning. See you in the next post!
我们已经到了这篇文章的结尾! 到目前为止,我们已经提出了解决方法,这些方法在一张小表Q表中表示动作值。 在下一篇文章中 ,我们将向您介绍使用神经网络来扩展可以通过强化学习解决的问题的规模和复杂性的想法。 下篇再见!
翻译自: https://towardsdatascience.com/mc-control-methods-50c018271553
mc2180 刷机方法















 2505
2505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









