





jarvis oj
Carsales.com, the company I work for, is holding a hackathon event. This is an annual event where everyone (tech or non tech) comes together to form a team and build anything — anything at all. Well, preferably you would build something that has a business purpose, but it is really up to you. This idea for this chatbot actually came from Jason Blackman, our Chief Information Officer at carsales.com.
我工作的公司Carsales.com正在举办黑客马拉松活动。 这是一年一度的活动,每个人(技术人员或非技术人员)齐心协力,组成一个团队,建立一切—一切。 好吧,最好您将构建具有业务目的的东西,但这确实取决于您。 这个聊天机器人的想法实际上来自carales.com的首席信息官Jason Blackman。
Given that our next hackathon is an online event, thanks to COVID-19, wouldn’t it be cool if we could host a Zoom webinar, where any carsales.com employee could jump in to hang out and chat with an AI bot which we could call Jarvis, who would always be available to chat with you.
鉴于我们的下一次黑客马拉松是在线活动,这要归功于COVID-19,如果我们可以举办Zoom网络研讨会,那不是很酷的事情,任何carales.com员工都可以参与其中并与我们聊天的AI机器人聊天可以打电话给Jarvis,他将始终可以与您聊天。
集思广益 (Brainstorming)
After tossing around ideas, I came up with a high-level scope. Jarvis would need to have a visual presence, just as would a human webinar participant. He needs to be able to listen to what you say and respond contextually with a voice.
在讨论想法之后,我提出了一个高层次的研究范围。 贾维斯(Jarvis)需要像人类网络研讨会参与者一样具有视觉形象。 他需要能够听您说的话,并用声音进行上下文响应。
I wanted him to be as creative as possible in his replies and to be able to generate a reply on the fly. Most chatbot systems are retrieval based, meaning that they have hundreds or thousands of prepared sentence pairs (source and target), which form their knowledge bases. When the bot hears a sentence, it will then try to find the most similar source sentence from its knowledge base and simply return the paired target sentence. Retrieval based bots such as Amazon Alexa and Google Home are a lot easier to build and work very well to deliver specific tasks like booking a restaurant or turning the lights on or off, whereas the conversation scope is limited. However, for entertainment purposes like casual chatting, they lack creativity in their replies when compared to the generative counterpart.
我希望他在他的回复中尽可能地富有创造力,并能够即时产生回复。 大多数聊天机器人系统都是基于检索的,这意味着它们具有成百上千个准备好的句子对(源和目标),构成了知识库。 当机器人听到一个句子时,它将尝试从其知识库中查找最相似的源句子,然后简单地返回配对的目标句子。 诸如Amazon Alexa和Google Home之类的基于检索的机器人很容易构建,并且可以很好地完成特定任务,例如预订餐厅或打开或关闭电灯,但是对话范围有限。 但是,出于娱乐目的(例如休闲聊天),与生成聊天对象相比,他们的答复缺乏创造力。
For that reason, I wanted a generative based system for Jarvis. I am fully aware that it is likely I will not achieve a good result. However, I really want to know how far the current generative chatbot technology has come and what it can do.
出于这个原因,我想要Jarvis基于生成的系统。 我完全意识到,我可能不会取得良好的成绩。 但是,我真的很想知道当前的聊天机器人技术已经走了多远,它能做什么。
建筑 (Architecture)
Ok, so I knew what I wanted. Now it was time to really contemplate how on earth I was going to build this bot.
好吧,所以我知道我想要什么。 现在是时候真正考虑一下我将如何构建这个机器人了。
We know that the first component needed is a mechanism to route audio and video. Our bot needed to be able to hear conversations on Zoom, so we needed a way to route the audio from Zoom into our bot. This audio would then need to be passed into a speech recognition module, which would give us the conversation as text. We would then need to pass this text into our generative AI model to get a reply, which would be turned into speech by using text-to-speech tech. While the audio reply is being played, we would need an animated avatar, which, apart from fidgeting, could also move his lips in sync with the audio playback. The avatar animation and audio playback needed to be sent back to Zoom for all meeting participants to hear and see. Wow! It was indeed a pretty complex system.
我们知道,需要的第一个组件是路由音频和视频的机制。 我们的机器人需要能够在Zoom上听到对话,因此我们需要一种将音频从Zoom路由到我们的机器人的方法。 然后,需要将此音频传递到语音识别模块,该模块会将文本作为对话提供给我们。 然后,我们需要将此文本传递到生成的AI模型中以得到答复,然后通过使用文本转语音技术将其转换为语音。 在播放音频回复时,我们需要一个动画化身,除了烦躁不安之外,还可以使他的嘴唇与音频播放同步。 需要将化身动画和音频播放发送回Zoom,以使所有会议参与者都能听到和看到。 哇! 这确实是一个非常复杂的系统。

To summarise, we needed the following components:
总而言之,我们需要以下组件:
- Audio/video routing 音频/视频路由
- Speech recognition 语音识别
- Generative AI model 生成式AI模型
- Text to Speech 文字转语音
- Animated avatar 动画头像
- Controller 控制者
音频/视频路由 (Audio/video routing)
I love it when someone else has done the hard work for me. Loopback is an audio tool that allows you to redirect audio from any application into a virtual microphone. All I needed were two audio routings. The first one was to route the audio from the Zoom app into a virtual microphone, from which my bot would listen.
当别人为我完成艰苦的工作时,我会喜欢它。 环回是一种音频工具,可让您将音频从任何应用程序重定向到虚拟麦克风。 我需要的只是两个音频路由。 第一个是将音频从“缩放”应用程序路由到虚拟麦克风,我的机器人将在该麦克风中收听。

The second routing was to route the chatbot audio output into yet another virtual microphone, where both the Zoom app and our avatar tool would listen to. It is obvious that Zoom would need to listen to this audio. However, why would our avatar tool need this audio? For lip-syncing, so that our avatar could move his lips according to the audio playback. You will see more details on this in later sections of this blog.
第二个路由是将聊天机器人的音频输出路由到另一个虚拟麦克风,“缩放”应用程序和我们的头像工具都将在其中收听。 很明显,Zoom需要收听此音频。 但是,为什么我们的头像工具需要此音频? 为了进行唇形同步,以便我们的化身可以根据音频播放来移动嘴唇。 您将在此博客的后续部分中看到有关此内容的更多详细信息。

语音识别 (Speech Recognition)
This module is responsible for processing incoming audio from Zoom via a virtual microphone and turning it into a text. There were a couple of offline and online speech recognition frameworks to choose from. The one I ended up using was Google Speech API. It is an online API with an awesome python interface that delivers superb accuracy, and more importantly, allows you to stream and recognise audio in chunks, which minimises the processing time significantly. I would like to emphasise that latency (how long it takes for the bot to respond to a query) is very critical for a chat bot. A slow responding bot can look very robotic and unrealistic.
该模块负责通过虚拟麦克风处理来自Zoom的传入音频并将其转换为文本。 有两种离线和在线语音识别框架可供选择。 我最终使用的是Google Speech API。 它是一个在线API,具有令人敬畏的python接口,可提供出色的准确性,更重要的是,它使您可以分批传输和识别音频,从而最大程度地减少了处理时间。 我想强调一下,延迟(机器人响应查询需要多长时间)对于聊天机器人至关重要。 响应缓慢的漫游器看起来非常机器人化且不切实际。
Most of the time, the Google Speech API returns a response in less than a second after a sentence is fully heard.
大多数情况下,在完整听到句子后不到一秒钟的时间内,Google Speech API就会返回响应。
生成式AI模型 (Generative AI Model)
This is the part that I spent most of my time on. After spending a day or two catching up with the recent developments in generative chatbot techniques, I found out that Neural Machine Translation models seemed to have been quite popular recently.
这是我大部分时间都花在的部分。 在花了一两天的时间来追随生成型聊天机器人技术的最新发展之后,我发现神经机器翻译模型最近似乎非常流行。
The concept was to feed an encoder-decoder LSTM model with word embedding from an input sentence, and to be able to generate a contextual output sentence. This technique is normally used for language translation. However, given that the job is simply mapping out one sentence to another, it can also be used to generate a reply to a sentence (in theory).
其概念是使用从输入句子中嵌入单词的方式为编码器-解码器LSTM模型提供数据,并能够生成上下文输出句子。 此技术通常用于语言翻译。 但是,鉴于该工作只是将一个句子映射到另一个句子,因此它也可以用于生成对句子的答复(理论上)。
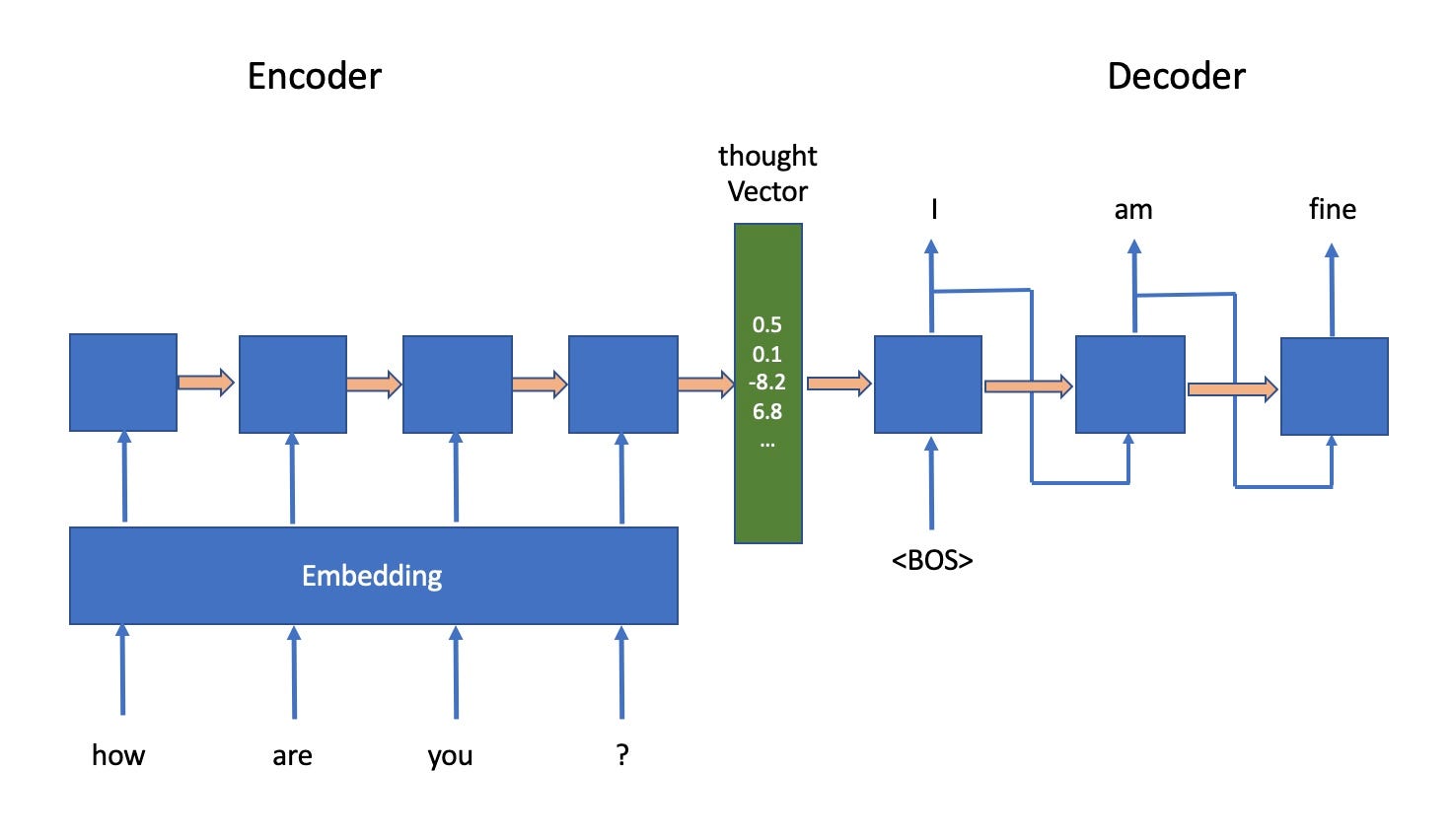
In layman’s terms, an input sentence is broken up into words. Each word is then mapped into an integer id, which is then passed into an embedding layer. During training, the embedding layer learns to turn this list of ids into a list of embedding vectors, which are ‘x’ dimension in size. This vector is constructed in such a way that words with similar meanings yield similar vectors, which will provide deeper information, rather than just a single integer value. These vectors are then passed into an LSTM encoder layer that turns them into a thought vector (some call them a latent vector), which contains information about the whole input sentence. Please note that there is a popular misconception that there are many LSTM layers or blocks, when in fact there is only one. The many blocks in the diagram above show the same LSTM block being called one-time step after another processing word by word.
用外行的术语来说,输入句子被分解成单词。 然后将每个单词映射到一个整数id,然后将其传递到嵌入层。 在训练过程中,嵌入层学习将ID列表转换为嵌入向量列表,这些嵌入向量的尺寸为“ x”维。 构造此向量的方式是,具有相似含义的单词会产生类似的向量,这些向量将提供更深的信息,而不仅仅是单个整数值。 然后将这些向量传递到LSTM编码器层,该层将它们转变为思想向量(有人称它们为潜在向量),其中包含有关整个输入句子的信息。 请注意,存在一个普遍的误解,认为实际上有很多LSTM层或块,而实际上只有一层。 上图中的许多块显示同一LSTM块被逐个单词逐个处理,一次调用。
The decoder on the right-hand side of the model is responsible for turning this thought vector into an output sentence. A special beginning of sentence <BOS> word is passed as an initial input to the LSTM layer, together with the thought vector, to generate the first word, which is forwarded to the same LSTM layer as an input to generate the next word, and so on and so forth.
模型右侧的解码器负责将此思想向量转换为输出语句。 句子<BOS>单词的特殊开头作为初始输入与思想向量一起传递到LSTM层,以生成第一个单词,该单词作为输入转发到同一LSTM层以生成下一个单词,并且等等等等。
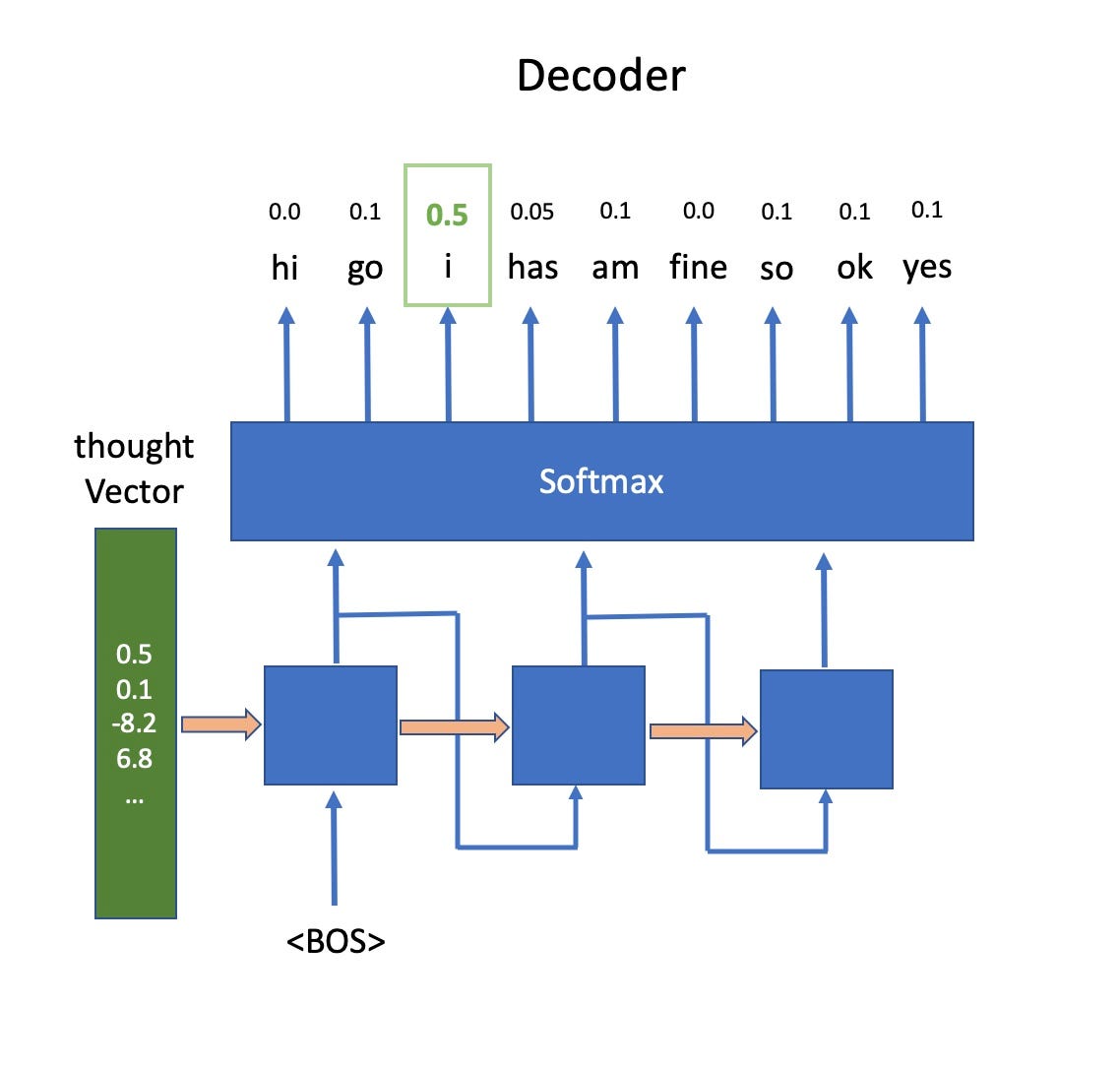
Going slightly deeper into technical realms, the output of an LSTM decoder unit is actually a number that is passed into a softmax (classification) layer, which returns the probability of each possible word in our vocabulary. The word with the highest probability (in the case above it is ‘I’) is the one picked as an output word, and also passed on as an input to the LSTM decoder layer to generate the next word.
深入技术领域,LSTM解码器单元的输出实际上是一个传递到softmax(分类)层的数字,该数字返回我们词汇表中每个可能单词的概率。 具有最高概率的单词(在上面的示例中为“ I”)是被选作输出单词的单词,并且还作为输入传递给LSTM解码器层以生成下一个单词。
There are a few examples online on how to build this model architecture. However, why build one if someone else has already done the hard work for you? Introducing: The Amazon SageMaker! Amazon SageMaker is a collection of tools and a pipeline to expedite building ML models, and comes with vast array of amazing built-in algorithms such as image classification, object detection, neural style transfer and seq2seq, which is a close variant of the Neural Machine Translation but with an extra attention mechanism.
在线上有一些有关如何构建此模型架构的示例。 但是,如果别人已经为您完成了艰苦的工作,为什么还要建造一个呢? 简介: Amazon SageMaker ! Amazon SageMaker是加快ML模型构建的工具和管道的集合,并附带了许多惊人的内置算法,例如图像分类,对象检测,神经样式传递和seq2seq,这是Neural Machine的近似变体翻译,但具有额外的注意机制。

The Amazon SageMaker seq2seq model is highly customisable. You can choose how many LSTM units are used, the number of hidden cells, embedding vector dimensions, the number of LSTM layers, etc., which gives me more than enough flexibility to experiment with different parameters to achieve better results.
Amazon SageMaker seq2seq模型是高度可定制的。 您可以选择使用多少LSTM单位,隐藏单元的数量,嵌入矢量尺寸,LSTM层的数量等,这为我提供了足够的灵活性来尝试不同的参数以获得更好的结果。
获取培训集 (Getting the Training Set)
The selection of the training set is crucial to the success of your chatbot responding with contextual and meaningful replies. The training set needs to be a collection of conversation exchanges between two parties. Specifically, we needed to construct a pair, a source sentence and a target sentence for each entry. For example, ‘Source: How are you?’ ‘Target: I am fine.’ ‘Source: Where do you live?’ ‘Target: I live in Australia’. This type of training set is very hard to get without a significant manual clean-up effort. The most popular dataset that people use is the Cornell Movie Dialogue Corpus Dataset, which is not great (you will see why a little later), but is the best you can get right now.
训练集的选择对于您的聊天机器人成功响应上下文和有意义的答复至关重要。 训练集必须是两方之间对话交流的集合。 具体来说,我们需要为每个条目构建一个对,一个源语句和一个目标语句。 例如,“来源:您好吗?” “目标:我很好。” 来源:你住在哪里? “目标:我住在澳大利亚”。 如果没有大量的手动清理工作,很难获得这种训练集。 人们使用的最受欢迎的数据集是康奈尔电影对话语料库数据集 ,虽然它不是很好(稍后您会看到为什么),但是现在可以得到最好的数据集 。

This data set consists of 220k lines of conversations taken from a movie dialogue. Each line comprises dialogue from one or more persons. The three example lines below show you some good examples where the conversation starts with a question (in bold) from one person and is followed by an answer from another.
该数据集包含来自电影对话的22万行对话。 每行包括一个或多个人的对话。 下面的三个示例行显示了一些很好的示例,其中对话以一个人的问题(粗体)开始,然后是另一个人的答案。
You know French? Sure do … my Mom’s from Canada
你会法语吗? 当然可以...我妈妈来自加拿大
And where’re you going? If you must know, we were attempting to go to a small study group of friends.
那你要去哪里 如果您必须知道,我们正在尝试去一个由朋友组成的小型学习小组。
How many people go here? Couple thousand. Most of them evil
有多少人去这里? 几千。 他们大多数是邪恶的
However, there are many more bad examples of lines where the follow up sentence does not make sense because you need the context of the prior conversation or a visual reference for it to make sense. For example, see the following:
但是,还有很多不好的例子,其中后续句子没有意义,因为您需要先前对话的上下文或视觉参考才能使之有意义。 例如,请参见以下内容:
What’s the worst? You get the girl.
最糟糕的是什么? 你得到那个女孩。
No kidding. He’s a criminal.
别开玩笑了。 他是罪犯。
It’s a lung cancer issue. Her favorite uncle
这是肺癌的问题。 她最喜欢的叔叔
There is no easy way to remove the bad lines without putting in manual labour, which I was not really prepared to do. And even if I did, I would have ended up with much less dataset; not enough to train my AI model with. Hence, I decided to proceed regardless and see how far I could get with this.
没有人工,没有简单的方法可以消除不良的线条,而我并没有为此做好准备。 即使我这样做了,我最终也会得到更少的数据集。 不足以训练我的AI模型。 因此,我决定继续进行下去,看看我能做到多远。
I generated multiple pairs of source and target sentences from each conversation line and from each two consecutive sentences, regardless of who said the sentence.
我从每个对话行和两个连续的句子中生成了多对源句和目标句,无论是谁说的。
‘What’s the worst? You are broke? What to do next?’ will be turned into two pairs of conversation lines.
'最糟糕的是什么? 你破产了吗 接下来做什么?' 将变成两对对话线。
What’s the worst? You are broke?
最糟糕的是什么? 你破产了吗
You are broke? What to do next?
你破产了吗 接下来做什么?
This way, I managed to enlarge my dataset. I was fully aware that I could potentially and mistakenly pair a source and target sentence spoken by the same person. However, half of the time, the target sentence still made sense if it was in a reply from others, as shown in the example below.
这样,我设法扩大了数据集。 我完全意识到,我可能会错误地将同一人说的源句和目标句配对。 但是,有一半的时间,如果目标句子是在其他人的答复中,它仍然是有意义的,如下例所示。
What’s the worst? You are broke? What do do next?
最糟糕的是什么? 你破产了吗 下一步做什么?
Tokenising/splitting sentences can be done in two lines of code using the nltk library.
可以使用nltk库以两行代码完成标记/拆分语句。
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
sentences = tokenizer.tokenize(text)I also trimmed a sentence if it was longer than 20 words, as my model could only read an input of up to 20 words and an output of 20 words. Besides this, longer sentences mean a greater context and higher variation, which is a lot harder for an AI model to learn given the size of our training set is not that big.
如果句子的长度超过20个单词,我也会对其进行修剪,因为我的模型只能读取最多20个单词的输入和最多20个单词的输出。 除此之外,更长的句子意味着更大的上下文和更高的变异性,鉴于我们训练集的规模并不大,这对于AI模型而言要学习起来要困难得多。
With the above methods, I managed to get 441k pairs of conversation lines.
通过上述方法,我设法获得了441k对对话线路。
预处理训练集 (Pre-processing the Training Set)
The next step was to pre-process this training set further, which involved several steps.
下一步是进一步预处理此训练集,其中涉及几个步骤。
The first step was to remove and replace unwanted strings from the pairs such as all the xml and html tags and multiple dots and dashes.The next step was to expand the contraction words, for example, ‘you’ll’ was expanded to ‘you will’, ‘I’m’ to ‘I am’, etc., which increased my AI model accuracy. The reason for this is that in later steps, sentences would be turned into lists of words by splitting against delimiter characters like spaces, new lines or tabs. All unique words would form our vocabulary. Contractions like ‘I’m’ would be considered as a new word in the vocabulary, which would increase our vocabulary size unnecessarily, and reduce the effectiveness of our training sets due to fragmentation; hence making it harder for our AI to learn.
第一步是删除和替换成对的字符串,例如所有的xml和html标签以及多个点和破折号。下一步是扩展紧缩字,例如,“ you'll ”被扩展为“ you”从 ',' 我 '到' 我是 '等,这提高了我的AI模型的准确性。 这样做的原因是,在后面的步骤中,通过与分隔符(例如空格,换行或制表符)分开,句子将变成单词列表。 所有独特的词都将构成我们的词汇表。 像“我是”这样的紧缩词在词汇表中被认为是一个新词,这会不必要地增加词汇量,并由于分散而降低训练集的有效性; 因此使我们的AI难以学习。
I used a very handy python framework called ‘contractions’, which expanded contractions in a sentence with one line of code.
我使用了一个非常方便的python框架,称为“ contractions”,该框架用一行代码扩展了句子中的收缩。
text = contractions.fix(text)Punctuation was the next thing to tackle. I separated the punctuation from sentences (e.g., ‘How are you?’ was turned into ‘How are you ?’) This was done for similar reasons as for the contractions; to make sure that the punctuation itself would be considered as a word, and that it wouldn’t be merged together with the previous word as a new word, such as ‘you?’ in the example above.
标点是接下来要解决的问题。 我把标点符号和句子分开(例如,“你好吗?”变成了“你好吗?”)。 以确保标点符号本身将被视为一个单词,并且不会与前一个单词合并为一个新单词,例如“您?” 在上面的示例中。
By going through all the steps above, I gained about 441k pairs of training sets and 56k words for the vocabulary.
通过上述所有步骤,我获得了约441k对训练集和56k个单词。
As a final step, I added a vocabulary pruning so that I could control what the maximum number of words was to support in the vocabulary. The pruning was easily done by removing less frequently used words. A smaller vocabulary size and a larger training set are more favourable. This make sense — imagine the difficulties of teaching your kids five new words by giving them 100 sample sentences, as opposed to 100 new words with the same 100 sample sentences. Using fewer words more frequently in more sentences will of course help you learn better.
作为最后一步,我添加了词汇修剪功能,以便可以控制词汇中支持的最大单词数。 通过删除不常用的单词,可以轻松完成修剪。 较小的词汇量和较大的培训内容更为有利。 这是有道理的-想象给孩子们五个新单词的困难,方法是给他们100个例句,而不是给100个带有相同100个例句的新单词。 当然,在更多的句子中更频繁地使用更少的词会帮助您更好地学习。

From my many experiments, I found that a vocabulary of 15k words gave me the best results, which yielded 346k training sets, equal to a ratio of 23 as opposed to the original 441k/56k =7.9.
从我的许多实验中,我发现15k单词的词汇量给了我最好的结果,产生了346k训练集,等于23的比例,而不是原始的441k / 56k = 7.9。
训练Seq2Seq模型 (Training the Seq2Seq Model)
Kick starting the training was super easy thanks to Amazon SageMaker, which already provided an example Jupyter notebook on how to train a Seq2Seq model.
借助Amazon SageMaker,开始培训非常容易,它已经提供了Jupyter笔记本示例来说明如何训练Seq2Seq模型。
I just needed to customise the S3 bucket, where my training file was located, and add my data pre-processing code. Next, I will show you how easy it is to train a seq2seq model in SageMaker, by showing you snippet of coding here and there. Check out my jupyter notebook if you want to see the complete source code.
我只需要自定义训练文件所在的S3存储桶,并添加数据预处理代码。 接下来,通过向您展示此处和此处的代码片段,我将向您展示在SageMaker中训练seq2seq模型有多么容易。 如果您想查看完整的源代码,请查看我的jupyter笔记本 。
First, you need to let SageMaker know which built-in algorithm you want to use. Each algorithm is containerised and available from a specific URL.
首先,您需要让SageMaker知道要使用哪种内置算法。 每种算法都是容器化的,可以从特定的URL获得。
from sagemaker.amazon.amazon_estimator import get_image_uri
container = get_image_uri(region_name, 'seq2seq')Next, you need to construct the training job description which provides a few important information you need to set about the training job. First, you need to set the location of the training set and where you store the final model.
接下来,您需要构造培训工作描述,其中提供了一些需要设置的有关培训工作的重要信息。 首先,您需要设置训练集的位置以及最终模型的存储位置。
"InputDataConfig": [
{
"ChannelName": "train",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://{}/{}/train/".format(bucket, prefix),
"S3DataDistributionType": "FullyReplicated"
}
},
},
....
"OutputDataConfig": {
"S3OutputPath": "s3://{}/{}/".format(bucket, prefix)
},After this, you need to choose what machine or instance you want to run this training on. Seq2seq is quite a heavy model, so you need a GPU machine. My recommendation is ml.p3.8xlarge, which has four NVIDIA V100 GPUs.
之后,您需要选择要在其上运行此培训的计算机或实例。 Seq2seq是一个很重的模型,因此您需要一台GPU机器。 我的建议是ml.p3.8xlarge,它具有四个NVIDIA V100 GPU。
"ResourceConfig": {
"InstanceCount": 1,
"InstanceType": "ml.p3.8xlarge",
"VolumeSizeInGB": 50
}Finally, you need to set the hyper-parameters. This is where I spent 30% of my time, a close second to experimenting with data preparation strategy. I built various models under different settings and compared their performances to come up with the best configuration.
最后,您需要设置超参数。 在这里,我花费了30%的时间,仅次于尝试数据准备策略。 我在不同的设置下构建了各种模型,并比较了它们的性能以得出最佳配置。
Remember, I chose to limit my sentences to 20 words. The first two lines below are the reason why. My LSTM model was only trained to recognise an input of up to 20 words and an output of up to 20 words.
请记住,我选择将句子限制为20个单词。 下面的前两行是原因。 我的LSTM模型仅经过训练,可以识别最多20个单词的输入和最多20个单词的输出。
"HyperParameters": {
"max_seq_len_source": "20",
"max_seq_len_target": "20",
"optimized_metric": "bleu",
"bleu_sample_size": "1000",
"batch_size": "512",
"checkpoint_frequency_num_batches": "1000",
"rnn_num_hidden": "2048",
"num_layers_encoder": "1",
"num_layers_decoder": "1",
"num_embed_source": "512",
"num_embed_target": "512",
"max_num_batches": "40100",
"checkpoint_threshold": "3"
},Normally, the larger your batch-size (if your GPU RAM can handle it), the better, as you can train more data in one go to speed up the training process. 512 seems to be the max size for p3.8xlarge. Some people may argue that different batch sizes produce slightly different accuracies, however I was not aiming to win a Nobel prize here, so small accuracy differences did not really matter much to me.
通常,批大小(如果您的GPU RAM可以处理)越大,越好,因为您可以一次性训练更多数据以加快训练过程。 512似乎是p3.8xlarge的最大大小。 有人可能会争辩说,不同的批量大小会产生略有不同的精度,但是我的目标并不是在这里获得诺贝尔奖,因此,小的精度差异对我而言并没有太大的意义。
I used one layer for each encoder and decoder, each having 2,048 hidden cells with the word embedding size of 512. A checkpoint and evaluation were then performed at each batch of 1,000, which was equal to 1,000 x 512 samples per batch (512k pair samples). So, the training would go to 1.5x the overall training sets (346k in total) until it performed an evaluation against this model. At each checkpoint, the best evaluated model was kept and then, finally, saved into our output S3 bucket. SageMaker also has the capability to early termination. For example, if the model does not improve after three consecutive checkpoints (‘checkpoint_threshold’), the training will stop.
我对每个编码器和解码器使用一层,每个编码器和解码器具有2,048个隐藏单元,其单词嵌入大小为512。然后对每1,000个批次执行检查点和评估,这等于每批次1,000 x 512个样本(512k对样本) )。 因此,训练将达到整个训练集的1.5倍(总共34.6万),直到针对该模型执行评估。 在每个检查点,都保留了评估最好的模型,然后最终将其保存到我们的输出S3存储桶中。 SageMaker还具有提前终止的能力。 例如,如果在三个连续的检查点('checkpoint_threshold')之后模型仍未改善,则训练将停止。
Also, ‘max_num_batches’ is a safety net that can stop the training regardless. In the case that your model keeps improving forever (which is a good thing), this will protect you so that the training cost won’t break your bank (which is not a good thing)
同样,“ max_num_batches”是一个安全网,无论如何都可以停止训练。 如果您的模型一直持续改进(这是一件好事),这将为您提供保护,从而使培训成本不会破坏您的资金(这不是一件好事)
训练模型 (Training the Model)
It only takes two lines of code to kick start the training. Then you just have to wait patiently for a few hours, depending on the instance type you use. It took me one and a half hours using p3.8xlarge instance.
只需两行代码即可开始培训。 然后,您只需要耐心等待几个小时,这取决于您使用的实例类型。 使用p3.8xlarge实例花了我一个半小时。
sagemaker_client = boto3.Session().client(service_name='sagemaker')
sagemaker_client.create_training_job(**create_training_params)As you can see below, the validation metrics found the best performing model at checkpoint number eight.
如下所示,验证指标在第八个检查点找到了性能最佳的模型。

模型评估 (Model Evaluation)
I intentionally skipped the discussion of the ‘optimized_metric’ earlier, as it is worth having its own section to explain it properly. Evaluating a generative AI Model is not a straightforward task. Often, there isn’t a one to one relationship between a question and an answer. For example, ten different answers are equally good for a question, which leads to a very broad scope of mapping. For a language translation task, the mapping is much narrower. However, for a chatbot, the scope is increased dramatically, especially when you use a movie dialogue as a training set. An answer to ‘Where are you going?’ could be any of the following:
我有意略过了对“ optimized_metric”的讨论,因为值得在其自己的部分中进行适当的解释。 评估生成的AI模型并不是一项简单的任务。 通常,问题和答案之间没有一对一的关系。 例如,十个不同的答案对于一个问题同样有效,这导致了非常广泛的映射范围。 对于语言翻译任务,映射要窄得多。 但是,对于聊天机器人,范围会大大增加,尤其是当您使用电影对话作为训练集时。 回答“ 你要去哪里? '可以是以下任意一种:
- Going to hell 地狱
- Why do you ask? 你为什么要问?
- I am not going to tell you. 我不会告诉你。
- What? 什么?
- Can you say again? 你能再说一遍吗?
There are two popular evaluation metrics to choose from for seq2seq algorithm in Amazon SageMaker: perplexity and bleu. Perplexity evaluates the generated sentences by taking random samples word by word using the probability distribution model in our training set, which is very well explained in this article.
对于Amazon SageMaker中的seq2seq算法,有两种流行的评估指标可供选择:困惑度和青色。 困惑是通过使用我们训练集中的概率分布模型逐字抽取随机样本来评估生成的句子, 本文对此进行了很好的解释。
Bleu evaluates the generated sentence against the target sentence by scoring the word n-gram match and penalising a generated sentence if it is shorter than the target sentence. This article explains how it works and advises against using it, with an excellent justification. On the contrary, I found that it works better than perplexity because the quality of the generated sentences strongly correlates to bleu’s score upon manual inspection.
Bleu通过对单词n-gram匹配评分并对生成的句子短于目标句子的句子进行惩罚,从而针对目标句子评估生成的句子。 本文以充分的理由说明了它的工作原理,并建议不要使用它。 相反,我发现它比困惑更有效,因为生成的句子的质量与人工检查时的bleu评分密切相关。
测试模型 (Testing the Models)
When the training is completed, you can create an endpoint for inference. From there, generating a text with inference can be done with a few lines of code.
训练完成后,您可以创建一个推断端点。 从那里,可以用几行代码来生成具有推理的文本。
response = runtime.invoke_endpoint(EndpointName=endpoint_name,
ContentType='application/json',
Body=json.dumps(payload))
response = response["Body"].read().decode("utf-8")
response = json.loads(response)
for i, pred in enumerate(response['predictions']):
print(f"Human: {sentences[i]}\nJarvis: {pred['target']}\n")The results will not win me a medal (roughly 60% of the responses were out of context and 20% were passable). However, what excites me is that the other 20% were surprisingly good. It answered with correct context and grammar. Consequently, it showed me that it could learn the English language to a certain extent and could even swear like us. It’s a good reminder too, of what your kids can learn from movies.
结果不会为我赢得一枚奖章(大约60%的回答是不合情理的,而20%的回答是可以通过的)。 但是,令我兴奋的是,另外20%的产品出奇地好。 它以正确的上下文和语法回答。 因此,它告诉我它可以在一定程度上学习英语,甚至可以像我们一样发誓。 这也很好地提醒了您的孩子可以从电影中学到什么。
One of my favourite examples is when the bot was asked, ‘who is your best friend?’ he answered, ‘my wife’. I have checked, and most of these sentences were not even in the training set, so the AI model indeed learned a little bit of creativity and did not just memorise the training sets.
我最喜欢的例子之一是当机器人被问到“谁是你最好的朋友?” 他回答说, “我的妻子” 。 我检查了一下,其中大多数句子甚至不在训练集中,因此AI模型确实学到了一些创造力,而不仅仅是记住训练集中。
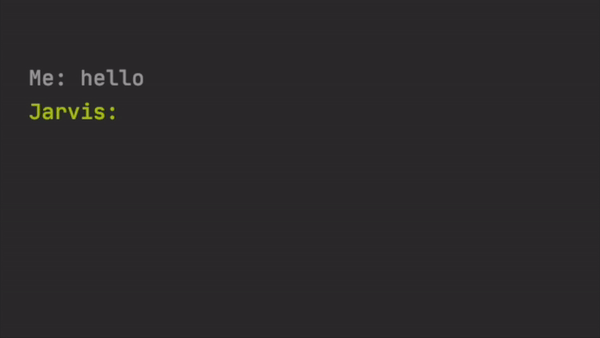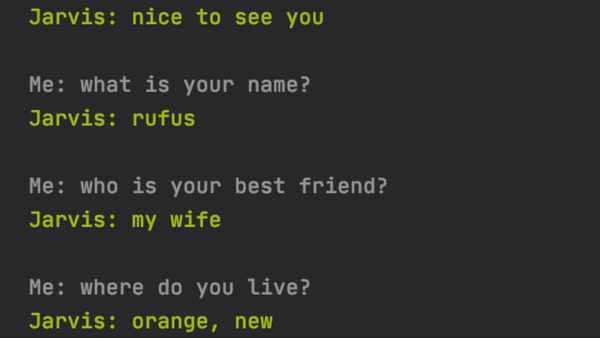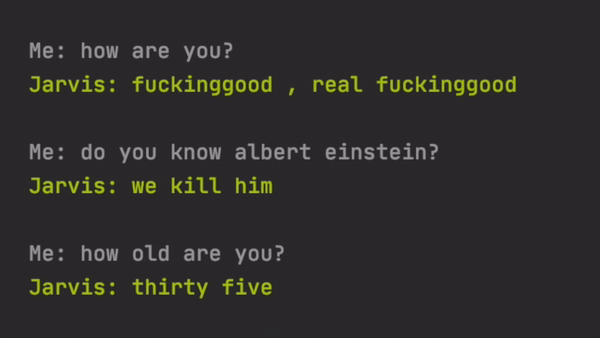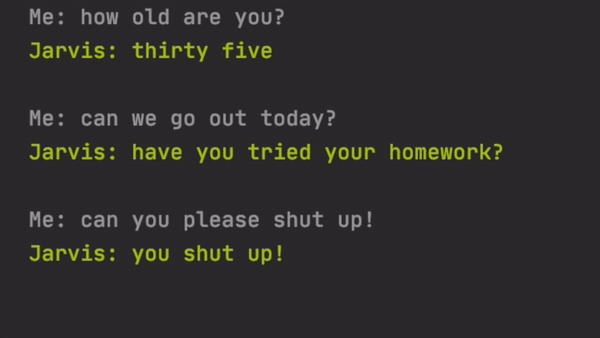
Here are some of the bad ones.
这是一些不好的。

From experimenting with several different hyper-parameters, I found that:
通过试验几个不同的超参数,我发现:
- Adding more encoder and decoder layers made it worse. Interestingly, the sentence structure that was generated was more complex. However, the relevancy of the answers to the questions was poor. 添加更多的编码器和解码器层会使情况变得更糟。 有趣的是,生成的句子结构更加复杂。 但是,这些问题的答案相关性很差。
- Reducing the word embedding size also dropped the generation quality. 减少单词嵌入的大小也会降低生成质量。
- Reducing the vocabulary size of up to 15k words increased the quality, whilst further reduction reduced the quality. 减少多达15k个单词的词汇量可以提高质量,而进一步减少则可以降低质量。
- Expanding on word contractions and separating punctuation definitely increased the quality of responses. 扩大词的紧缩和分隔标点的确提高了答复的质量。
Though it’s probably more of a pre-processing step rather than a hyper-parameter settings. It is worth to mention that adding Byte Pair Encoding (as suggested by SageMaker notebook) drops the quality of responses.
尽管这可能更多是预处理步骤,而不是超参数设置。 值得一提的是,添加字节对编码 (如SageMaker笔记本所建议)会降低响应质量。
语音生成和动画头像 (Speech Generation and Animated Avatar)
The next modules I needed were a text to speech and an animated avatar. I used an awesome Amazon Polly for text to speech generation. Again, it is an online API. However, it has a super lighting respond time (less than 300ms most of the time) and high-quality speech that sounds natural.
我需要的下一个模块是文本转语音和动画化身。 我使用了很棒的Amazon Polly来生成文本到语音。 同样,它是一个在线API。 但是,它具有超强的照明响应时间(大多数时间少于300毫秒)和听起来自然的高质量语音。

Given my previous work as a Special Effect and Motion Capture Software Engineer, I was very tempted to build the animated avatar myself. I did actually build a simple avatar system on a separate project: Building a Bot That Plays Videos for my Toddler. Thankfully, the better part of me realised how long this would take me if I were to pursue this journey rather than to use an awesome 3D avatar software, Loom.ai, which comes with audio lip-sync capability! All you need to do is send an audio clip to the Loom.ai app and it will animate a 3D avatar to lip-sync to the provided audio. How awesome is that? The app also comes with a fake video camera driver, which streams the rendered output. I just needed to select the fake video camera in the Zoom app settings, so that I could include the animation in the Zoom meeting.
考虑到我之前作为特效和动作捕捉软件工程师的工作,我非常想自己创建动画化身。 实际上,我确实在一个单独的项目上构建了一个简单的化身系统: 构建一个为我的蹒跚学步的人播放视频的机器人 。 值得庆幸的是,我的大部分时间都意识到,如果我继续这一旅程而不是使用令人敬畏的3D头像软件Loom.ai ,它会花多长时间? Loom.ai具有音频口型同步功能! 您需要做的就是将音频剪辑发送到Loom.ai应用程序,它将为3D化身制作动画,使其与提供的音频进行口型同步。 那有多棒? 该应用程序还附带一个假冒的摄像机驱动程序,该驱动程序将渲染的输出进行流式处理。 我只需要在“缩放”应用程序设置中选择伪造的摄像机,即可将动画包含在“缩放”会议中。

结果 (Results)
With all the modules completed, all I needed to do was build a controller system that would combine everything. The first test ran quite well, except that Jarvis stole all the conversation. He impolitely interjected and replied to every single sentence spoken by anyone in the video conference which annoyed everyone. Well, that’s one thing I forgot to train Jarvis in — manners and social skills!
完成所有模块后,我要做的就是构建一个将所有内容组合在一起的控制器系统。 第一次测试运行得很好,只是Jarvis偷走了所有对话。 他无礼地插话并回答了视频会议中任何人都说的每一句话,这使每个人都感到恼火。 好吧,那是我忘了训练贾维斯的一件事-举止和社交技巧!
Rather than building another social skill module, which I had no clue how to start, an easy fix to this was to teach Jarvis to start and stop talking by a voice command. When he heard ‘Jarvis, stop talking’ he stopped responding until he heard ‘Jarvis, start talking’. With this new and important skill, everyone started to like Jarvis more.
除了构建另一个我不知道如何开始的社交技能模块外,一个简单的解决方法是教贾维斯通过语音命令开始和停止讲话。 当他听到“ Jarvis,停止讲话”时,他停止回应,直到听到“ Jarvis,开始讲话”。 有了这项重要的新技能,每个人都开始更喜欢Jarvis。
This generative model was fun to talk to for the first few exchanges as with some of his answers, he amazed us with his creativity and his rudeness. However, the novelty wore off quickly because the longer the conversation went on, the more we heard out of context responses, until eventually we came to the realisation that we were not engaged in a meaningful conversation at all. For this reason, I ended up using a pattern-based chatbot tech driven by the AIML language model, which surprisingly offered much better creativity than a normal retrieval-based model and could recall context from past information! This article explains clearly what it is, and perhaps it will be a story for me to tell another day.
在最初的几次交流中,这种生成模式很有趣,他的一些回答使他惊讶,他的创造力和粗鲁无礼使我们惊讶。 但是,新颖性很快消失了,因为对话持续的时间越长,我们从上下文响应中听到的内容就越多,直到最终我们意识到我们根本没有进行有意义的对话。 因此,我最终使用了由AIML语言模型驱动的基于模式的聊天机器人技术,该技术令人惊讶地提供了比基于常规检索的模型更好的创造力,并且可以从过去的信息中回忆上下文! 这篇文章清楚地解释了它的含义,也许这对我来说将是一个故事。
With the help of my super awesome Hackathon team members, we even extended Jarvis’ capability to be an on demand meeting assistant who can help taking down notes, action points assigned to relevant individuals, emailing them to meeting participants and scheduling a follow up meeting.
在我超赞的Hackathon团队成员的帮助下,我们甚至扩展了Jarvis的能力,使其成为按需开会的助理,可以帮助记下笔记,分配给相关个人的行动要点,通过电子邮件将其发送给与会人员并安排后续会议。
结论 (Conclusion)
Sometimes the quality of the generated text from the bot was good. However, from just two conversation exchanges (even with the good ones), you could clearly tell that something was off and unnatural.
有时,从漫游器生成的文本的质量很好。 但是,仅通过两次对话交换(即使是与善良的对话),您也可以清楚地看出有些事情是不自然的和不自然的。
- It did not have past context. Each response was generated from the context of the question asked. It did not consider prior conversations, which most humans can do very easily. Obviously, the technology is not there yet to build a model that can consider past conversation history. I have not heard of one yet at least. 它没有过去的背景。 每个回答都是从所问问题的上下文中生成的。 它没有考虑以前的对话,大多数人可以很容易地做到这一点。 显然,该技术尚未建立可以考虑过去对话历史的模型。 至少我还没有听说过。
- For more than half of the time, it gave an irrelevant response. Although a better model architecture may also be needed, however my biggest suspect is the training set. Movie dialogue has broad topics, which makes it very hard for the AI model to learn, especially when the source and target sentences sometimes do not make sense (e.g., no prior context, requiring visual reference or being incorrectly paired). A training set like a restaurant booking dialogue may work better as the scope is very limited in restaurant booking. However, the conversation exchanges will likely be less entertaining. 在超过一半的时间里,它没有给出任何回应。 尽管可能还需要更好的模型架构,但是我最大的怀疑是训练集。 电影对话具有广泛的主题,这使得AI模型很难学习,尤其是在源句子和目标句子有时没有意义的情况下(例如,没有先验上下文,需要视觉参考或配对不正确)。 像餐厅预订对话这样的培训集可能会更好,因为餐厅预订的范围非常有限。 但是,对话交流的娱乐性可能会降低。
Given the above, I believe a fully practical, generative chatbot is still years or decades away. I can now totally understand why it takes years for us to learn a language.
鉴于以上所述,我认为距离实际应用,生成聊天机器人尚需数年或数十年之久。 我现在可以完全理解为什么我们要花几年的时间来学习一门语言。

Nevertheless, this was a very fun project and I learned a lot from it.
但是,这是一个非常有趣的项目,我从中学到了很多。
The code for this project is available from github.
该项目的代码可从github获得 。
翻译自: https://towardsdatascience.com/building-jarvis-the-generative-chatbot-with-an-attitude-a833f709f46c
jarvis oj















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









