






数据安全分类分级实施指南
重点 (Top highlight)
Balance within the imbalance to balance what’s imbalanced — Amadou Jarou Bah
在不平衡中保持平衡以平衡不平衡— Amadou Jarou Bah
Disclaimer: This is a comprehensive tutorial on handling imbalanced datasets. Whilst these approaches remain valid for multiclass classification, the main focus of this article will be on binary classification for simplicity.
免责声明:这是有关处理不平衡数据集的综合教程。 尽管这些方法对于多类分类仍然有效,但为简单起见,本文的主要重点将放在二进制分类上。
介绍 (Introduction)
As any seasoned data scientist or statistician will be aware of, datasets are rarely distributed evenly across attributes of interest. Let’s imagine we are tasked with discovering fraudulent credit card transactions — naturally, the vast majority of these transactions will be legitimate, and only a very small proportion will be fraudulent. Similarly, if we are testing individuals for cancer, or for the presence of a virus (COVID-19 included), the positive rate will (hopefully) be only a small fraction of those tested. More examples include:
正如任何经验丰富的数据科学家或统计学家都会意识到的那样,数据集很少会在感兴趣的属性之间均匀分布。 想象一下,我们负有发现欺诈性信用卡交易的任务-自然,这些交易中的绝大多数都是合法的,只有很小一部分是欺诈性的。 同样,如果我们正在测试个人是否患有癌症或是否存在病毒(包括COVID-19),那么(希望)阳性率仅是所测试者的一小部分。 更多示例包括:
- An e-commerce company predicting which users will buy items on their platform 一家电子商务公司预测哪些用户将在其平台上购买商品
- A manufacturing company analyzing produced materials for defects 一家制造公司分析所生产材料的缺陷
- Spam email filtering trying to differentiation ‘ham’ from ‘spam’ 垃圾邮件过滤试图区分“火腿”和“垃圾邮件”
- Intrusion detection systems examining network traffic for malware signatures or atypical port activity 入侵检测系统检查网络流量中是否存在恶意软件签名或非典型端口活动
- Companies predicting churn rates amongst their customers 预测客户流失率的公司
- Number of clients who closed a specific account in a bank or financial organization 在银行或金融组织中关闭特定帐户的客户数量
- Prediction of telecommunications equipment failures 预测电信设备故障
- Detection of oil spills from satellite images 从卫星图像检测漏油
- Insurance risk modeling 保险风险建模
- Hardware fault detection 硬件故障检测
One has usually much fewer datapoints from the adverse class. This is unfortunate as we care a lot about avoiding misclassifying elements of this class.
通常,来自不利类的数据点少得多。 这很不幸,因为我们非常在意避免对此类元素进行错误分类。
In actual fact, it is pretty rare to have perfectly balanced data in classification tasks. Oftentimes the items we are interested in analyzing are inherently ‘rare’ events for the very reason that they are rare and hence difficult to predict. This presents a curious problem for aspiring data scientists since many data science programs do not properly address how to handle imbalanced datasets given their prevalence in industry.
实际上,在分类任务中拥有完全平衡的数据非常罕见。 通常,我们感兴趣的项目本质上是“稀有”事件,原因是它们很少见,因此难以预测。 对于有抱负的数据科学家而言,这是一个令人好奇的问题,因为鉴于其在行业中的普遍性,许多数据科学程序无法正确解决如何处理不平衡的数据集。
数据集什么时候变得“不平衡”? (When does a dataset become ‘imbalanced’?)
The notion of an imbalanced dataset is a somewhat vague one. Generally, a dataset for binary classification with a 49–51 split between the two variables would not be considered imbalanced. However, if we have a dataset with a 90–10 split, it seems obvious to us that this is an imbalanced dataset. Clearly, the boundary for imbalanced data lies somewhere between these two extremes.
不平衡数据集的概念有些模糊。 通常,在两个变量之间划分为49-51的二进制分类数据集不会被认为是不平衡的。 但是,如果我们有一个90-10分割的数据集,对我们来说显然这是一个不平衡的数据集。 显然,不平衡数据的边界介于这两个极端之间。
In some sense, the term ‘imbalanced’ is a subjective one and it is left to the discretion of the data scientist. In general, a dataset is considered to be imbalanced when standard classification algorithms — which are inherently biased to the majority class (further details in a previous article) — return suboptimal solutions due to a bias in the majority class. A data scientist may look at a 45–55 split dataset and judge that this is close enough that measures do not need to be taken to correct for the imbalance. However, the more imbalanced the dataset becomes, the greater the need is to correct for this imbalance.
从某种意义上说,“不平衡”一词是主观的,由数据科学家自行决定。 通常,当标准分类算法(固有地偏向多数类(在上一篇文章中有更多详细信息))由于多数类的偏向而返回次优解时,则认为数据集不平衡。 数据科学家可以查看45–55的分割数据集,并判断该数据集足够接近,因此无需采取措施来纠正不平衡。 但是,数据集变得越不平衡,就越需要纠正这种不平衡。
In a concept-learning problem, the data set is said to present a class imbalance if it contains many more examples of one class than the other.
在概念学习问题中,如果数据集包含一个类别的实例多于另一个类别的实例,则称该数据集存在类别不平衡。
As a result, these classifiers tend to ignore small classes while concentrating on classifying the large ones accurately.
结果,这些分类器倾向于忽略小类别,而专注于准确地对大类别进行分类。
Imagine you are working for Netflix and are tasked with determining which customer churn rates (a customer ‘churning’ means they will stop using your services or using your products).
想象您正在为Netflix工作,并负责确定哪些客户流失率(客户“流失”意味着他们将停止使用您的服务或产品)。
In an ideal world (at least for the data scientist), our training and testing datasets would be close to fully balanced, having around 50% of the dataset containing individuals that will churn and 50% who will not. In this case, a 90% accuracy will more or less indicate a 90% accuracy on both the positively and negatively classed groups. Our errors will be evenly split across both groups. In addition, we have roughly the same number of points in both classes, which from the law of large numbers tells us reduces the overall variance in the class. This is great for us, accuracy is an informative metric in this situation and we can continue with our analysis unimpeded.
在理想的世界中(至少对于数据科学家而言),我们的训练和测试数据集将接近完全平衡,大约50%的数据集包含会搅动的人和50%不会搅动的人。 在这种情况下,90%的准确度将或多或少地表明在正面和负面分类组中都达到90%的准确度。 我们的错误将平均分配给两个组。 此外,两个类中的点数大致相同,这从大数定律可以看出,这减少了类中的总体方差。 这对我们来说非常好,在这种情况下,准确性是一个有用的指标,我们可以继续进行不受阻碍的分析。
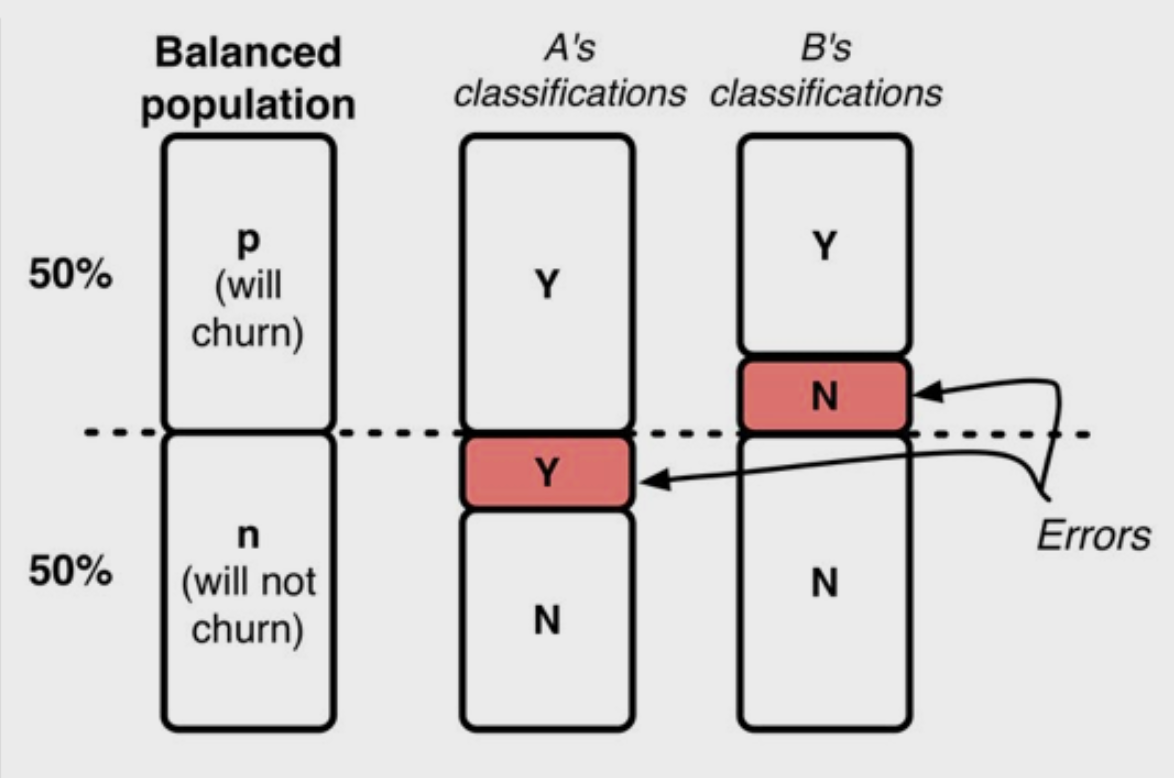
As you may have suspected, most people that already pay for Netflix don't have a 50% chance of stopping their subscription every month. In fact, the percentage of people that will churn is rather small, closer to a 90–10 split. How does the presence of this dataset imbalance complicate matters?
您可能会怀疑,大多数已经为Netflix付款的人没有50%的机会每月停止订阅。 实际上,会流失的人数比例很小,接近90-10。 这个数据集的不平衡如何使问题复杂化?
Assuming a 90–10 split, we now have a very different data story to tell. Giving this data to an algorithm without any further consideration will likely result in an accuracy close to 90%. This seems pretty good, right? It’s about the same as what we got previously. If you try putting this model into production your boss will probably not be so happy.
假设拆分为90-10,我们现在要讲一个非常不同的数据故事。 将此数据提供给算法而无需进一步考虑,可能会导致接近90%的精度。 这看起来还不错吧? 它与我们之前获得的内容大致相同。 如果您尝试将这种模型投入生产,您的老板可能不会很高兴。
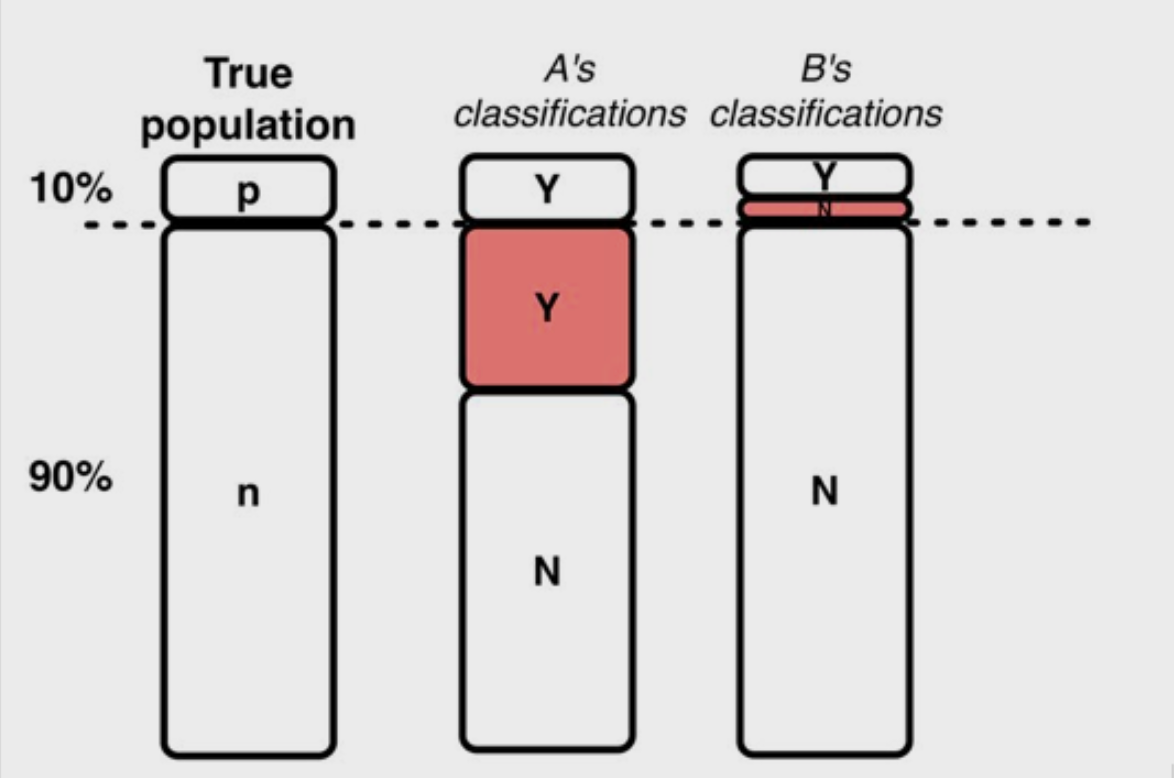
Given the prevalence of the majority class (the 90% class), our algorithm will likely regress to a prediction of the majority class. The algorithm can pretty closely maximize its accuracy (our scoring metric of choice) by arbitrarily predicting that the majority class occurs every time. This is a trivial result and provides close to zero predictive power.
给定多数类别(90%类别)的患病率,我们的算法可能会回归到多数类别的预测。 通过任意预测每次都会出现多数类,该算法可以非常精确地最大程度地提高其准确性(我们的选择评分标准)。 这是微不足道的结果,并提供接近零的预测能力。
Predictive accuracy, a popular choice for evaluating the performance of a classifier, might not be appropriate when the data is imbalanced and/or the costs of different errors vary markedly.
当数据不平衡和/或不同错误的成本明显不同时,预测准确性是评估分类器性能的一种普遍选择,可能不合适。
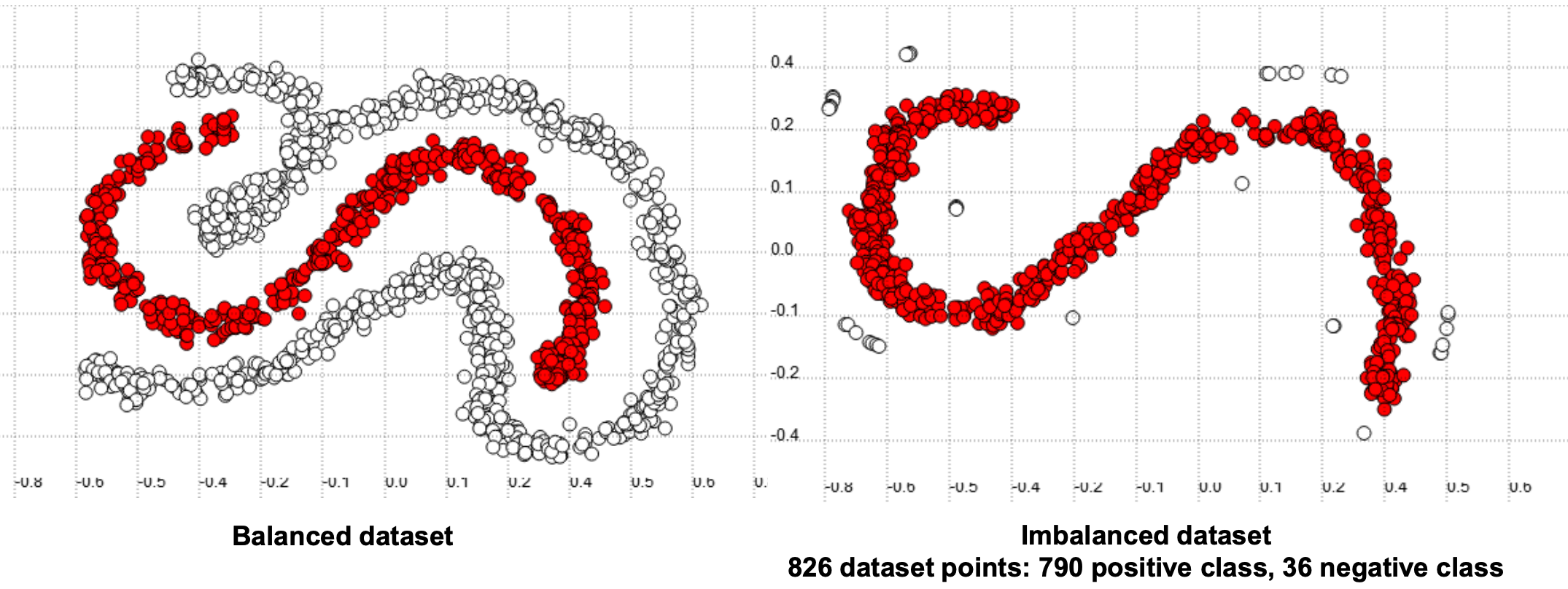
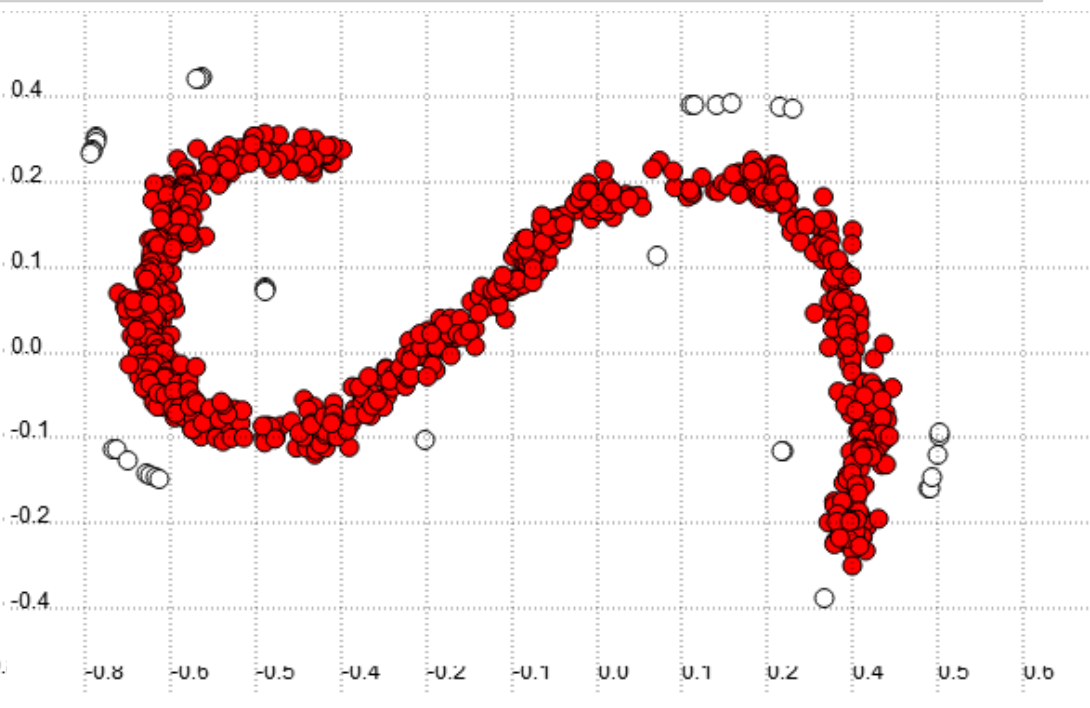
Visually, this dataset might look something like this:
从视觉上看,该数据集可能看起来像这样:
Machine learning algorithms by default assume that data is balanced. In classification, this corresponds to a comparative number of instances of each class. Classifiers learn better from a balanced distribution. It is up to the data scientist to correct for imbalances, which can be done in multiple ways.
默认情况下,机器学习算法假定数据是平衡的。 在分类中,这对应于每个类的比较实例数。 分类器从均衡的分布中学习得更好。 数据科学家可以纠正不平衡,这可以通过多种方式来完成。
不同类型的失衡 (Different Types of Imbalance)
We have clearly shown that imbalanced datasets have some additional challenges to standard datasets. To further complicate matters, there are different types of imbalance that can occur in a dataset.
我们已经清楚地表明,不平衡的数据集对标准数据集还有一些其他挑战。 更复杂的是,数据集中可能会出现不同类型的失衡。
(1) Between-Class
(1)课间
A between-class imbalance occurs when there is an imbalance in the number of data points contained within each class. An example of this is shown below:
当每个类中包含的数据点数量不平衡时,将发生类间不平衡。 下面是一个示例:
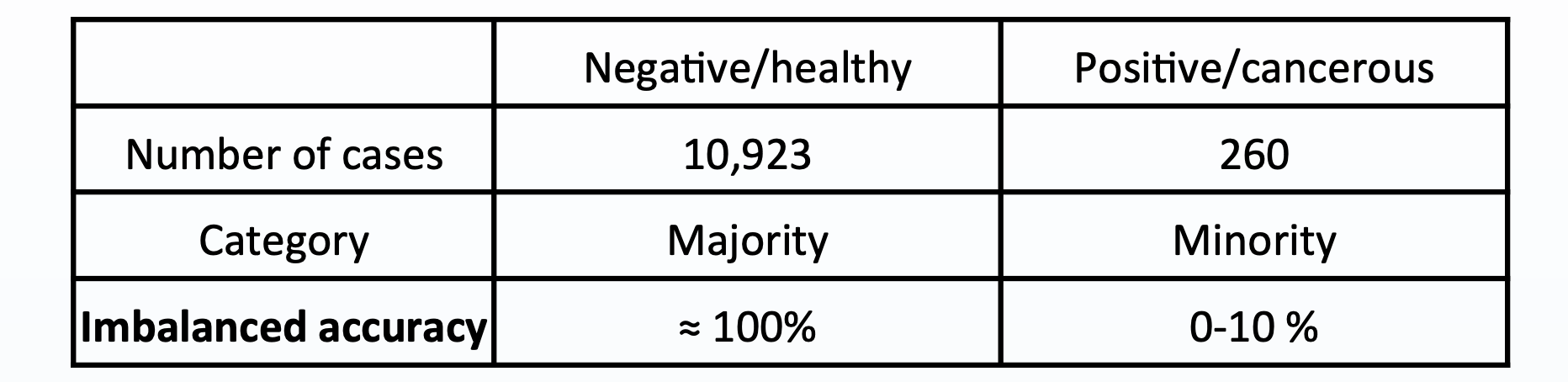
An example of this would be a mammography dataset, which uses images known as mammograms to predict breast cancer. Consider the number of mammograms related to positive and negative cancer diagnoses:
这样的一个例子是乳腺X射线摄影数据集,它使用称为乳腺X线照片的图像来预测乳腺癌。 考虑与阳性和阴性癌症诊断相关的乳房X线照片数量:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









