





qt 操纵access
By Emily Saltz (PAI), Pedro Noel (First Draft), Claire Leibowicz (PAI), Claire Wardle (First Draft), Sam Gregory (WITNESS)
埃米莉·萨尔茨 (PAI), 佩德罗·诺埃尔 ( Pedro Noel) (初稿), 克莱尔·莱博维奇 ( Claire Leibowicz) (PAI), 克莱尔·沃德 ( Claire Wardle) (初稿), 萨姆·格雷戈里 ( Sam Gregory) (WITNESS)
“The real question for our time is, how do we scale human judgment? And how do we keep human judgment local to human situations?”
“我们时代的真正问题是,我们如何扩展人类的判断力? 以及我们如何使人类的判断仅限于人类的处境?”
–Maria Ressa, Filipino-American journalist and founder of Rappler, speaking on “Your Undivided Attention.” (Note: Ressa was found guilty of ‘cyberlibel’ in the Philippines on June 15, 2020 for Rappler’s investigative journalism in what is seen by many as a major blow to the free press.)
–菲律宾裔美国记者兼Rappler创始人玛丽亚·里莎(Maria Ressa) 谈到“您的全神贯注”。 (注: 丽莎 ( Ressa)于 2020年6月15日在菲律宾因拉普尔(Rappler)的调查性新闻工作被判犯有``网络自由'' ,这在许多人看来是对新闻界的重大打击。)
什么是MediaReview,以及为何如此重要 (What is MediaReview, and why it matters)
Digital platforms have a manipulated media problem: mis/disinformation through the use of misleading videos, memes, and photographs is the most common communication strategy for political actors to influence public opinion around the world, according to a 2019 Global Inventory of Organized Social Media Manipulation report from Oxford’s Computational Propaganda Research Project. As platforms face the daunting challenge of addressing the onslaught of these media, they turn to human and technological solutions that can help them better categorize and automate this content. In response, the Duke Reporters’ Lab has created MediaReview in collaboration with fact-checking partners and other constituencies, such as schema.org and The Washington Post. MediaReview is a schema, or tagging system, that will allow fact-checkers to alert partnering tech platforms about false videos and fake images.
数字平台存在一个可操纵的媒体问题:根据2019年有组织社交媒体操纵全球清单,通过使用误导性视频,模因和照片引起的误导/误导信息是政治参与者影响全球舆论的最常见传播策略报告由牛津大学的计算宣传部研究项目。 随着平台面临着应对这些媒体冲击的艰巨挑战,他们转向了人力和技术解决方案,可以帮助他们更好地对这些内容进行分类和自动化。 作为回应,杜克记者实验室与事实检查合作伙伴和其他选区(例如schema.org和《华盛顿邮报》)合作创建了MediaReview 。 MediaReview是一种架构或标记系统,允许事实检查人员向合作伙伴技术平台发出有关虚假视频和虚假图像的警报。
At the Partnership on AI, with consultation from the Reporters’ Lab and partners in media, civil society, and technology on the AI and Media Integrity Steering Committee, we’ve been assessing the implications of developing and deploying the MediaReview schema as a case study for thinking about automating manipulated media evaluations more broadly. Rating highly contestable and context-specific media is a complex and subjective endeavor even for trained fact-checkers analyzing individual posts, and extending those ratings via automation has risks and benefits that warrant serious consideration prior to widespread adoption.
在AI合作伙伴关系中,在记者实验室以及AI,媒体诚信指导委员会的媒体,公民社会和技术合作伙伴的咨询下,我们一直在评估开发和部署MediaReview模式作为案例研究的意义。考虑更广泛地自动化受控媒体评估。 即使对于训练有素的事实检查人员分析单个职位,对具有高度竞争性和特定于上下文的媒体进行评级也是一项复杂而主观的工作,并且通过自动化扩展这些评级具有一定的风险和利益,因此有必要在广泛采用之前进行认真考虑。
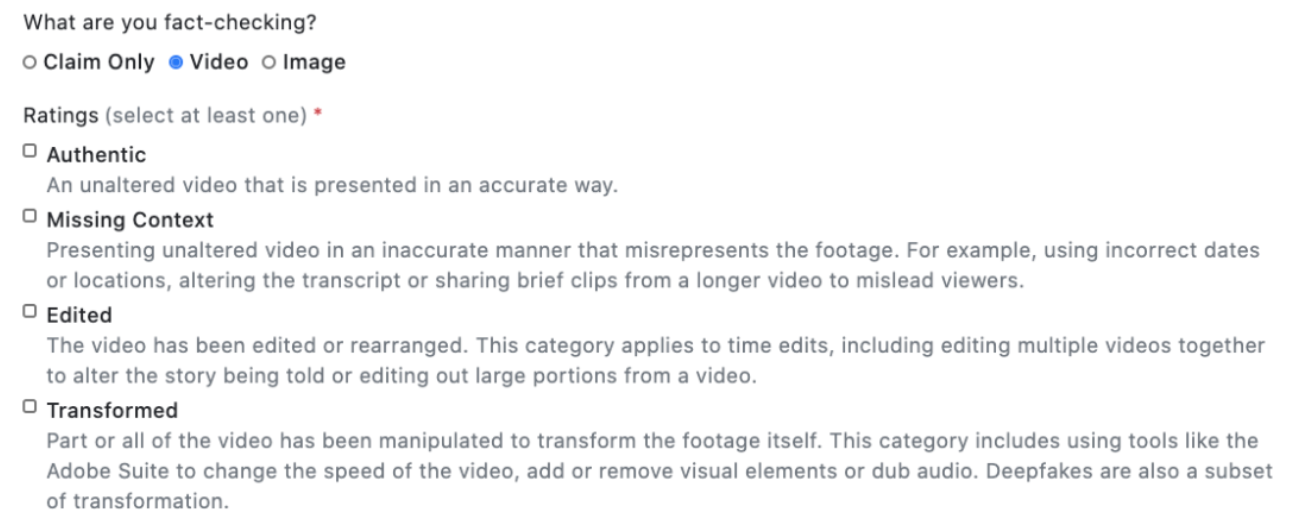
Specifically, MediaReview currently allows fact-checkers to tag video and image posts according to predefined categories such as “Missing Context,” “Edited Content,” “Transformed,” and “Authentic” in a format that can then be ingested and used by platforms to inform content moderation policies and audience-facing explanations. Google and Facebook are supporting the development of the schema, which is currently in testing with fact-checkers with an eye toward eventual adoption by platforms, who are rightly moving with urgency to address disinformation campaigns and misleading content ahead of the 2020 US Presidential election in November.
具体来说,MediaReview当前允许事实检查人员根据预定义的类别(例如“缺少上下文”,“编辑内容”,“已转换”和“真实”)标记视频和图像帖子,其格式随后可被平台提取和使用告知内容审核政策和面向受众的说明。 谷歌和Facebook正在支持该架构的开发,该架构目前正在接受事实检查人员的测试 ,以期最终被平台采用。在2020年美国总统大选之前,这些平台理所当然地急于解决虚假信息宣传活动和误导性内容。十一月。
We describe urgent considerations for deploying a media rating schema across five areas: 1) Manipulated Media Categories, 2) Relationship of Ratings to Harm, 3) Archiving of Manipulated Media, 4) Automated Image and Video Matching Technology, and 5) Global User Experience Design:
我们描述了在五个领域中部署媒体评级方案的紧急考虑:1)操纵的媒体类别,2)评级与危害的关系,3)操纵的媒体归档,4)自动化的图像和视频匹配技术以及5)全球用户体验设计:
1. Manipulated Media Categories: We need a set of robust categories for manipulated or misleading media.
1.操纵的媒体类别:我们需要一套可靠的类别来操纵或误导媒体。
1.1. Any set of categories should only be deployed once an inter-coder reliability threshold has been hit.
1.1。 仅在达到编码器间可靠性阈值后,才应部署任何类别的集合。
1.2. As new tactics emerge, will the categories evolve?
1.2。 随着新策略的出现,类别会发展吗?
2. Relationship of Ratings to Harm: We need to consider the ways in which potential harm intersects with manipulated media.
2.评级与危害的关系:我们需要考虑潜在危害与受控媒体相交的方式。
2.1. If platforms are using ‘harm’ to justify decisions as outlined in many policies (flagging, de-ranking, take-downs) definitions of harm need to be clear to those fact-checking the content as well as audiences. They can not be opaque or ad-hoc.
2.1。 如果平台使用“损害”来证明许多政策(举报,降级,删除)中概述的决定的合理性,则对于那些对内容和受众进行事实检查的事实,必须明确损害的定义。 它们不能是不透明的或临时的。
2.2. We need clearer explanations of the ways in which harm is measured in specific local contexts, for example, the threat of immediate real-world harms, such as media inciting violence, versus longer-term harms, like anti-vaccine conspiracies.
2.2。 我们需要对在特定的本地环境中衡量危害的方式进行更清晰的解释,例如,直接现实世界的危害(如煽动暴力的媒体)的威胁与长期危害(如反疫苗的阴谋)的威胁。
3. Archiving of Manipulated Media: We need to consider who owns the archive of rated manipulated media, and how access can be responsibly provided to the public without unintended consequences.
3.操纵媒体的存档:我们需要考虑谁拥有额定操纵媒体的档案,以及如何以负责任的方式向公众提供访问权限,而不会产生意想不到的后果。
3.1. Provide public archives of rated media to enable critical inquiry, analysis, and evidentiary use by third-parties.
3.1。 提供受评级媒体的公共档案,以便第三方进行关键的查询,分析和证据使用。
3.2. Create archives with ownership, access controls, and oversight mechanisms as informed by civil society.
3.2。 根据民间社会的信息,创建具有所有权,访问控制和监督机制的档案。
4. Automated Image and Video Matching Technology: We need to consider the impact of automated matching technologies — for example, if an authentic video of police brutality is shared by one user with a misleading caption, it risks being rated as “false” across all matching videos on a platform, even when shared with accurate context.
4.自动化图像和视频匹配技术:我们需要考虑自动化匹配技术的影响,例如,如果一个用户共享的真实的警察暴行视频带有误导性的标题,则可能在所有情况下被评为“假”在平台上匹配视频,即使与准确的上下文共享也是如此。
4.1. Harm-assessment should be made at the level of a post in context, rather than as an inherent property of a media asset that can always be extended across all instances.
4.1。 危害评估应在上下文中的职位级别进行,而不是作为媒体资产的固有属性进行评估,该资产可以始终扩展到所有实例中。
4.2. Fact-checkers need more context on where matches appear across platforms and should be able to understand and control how their ratings will propagate across matched media.
4.2。 事实检查人员需要更多有关匹配在各个平台上出现的位置的上下文,并且应该能够理解和控制其评分如何在匹配的媒体上传播。
5. Global User Experience Design: We need to consider how these ratings might feed into audience-facing user interface interventions, across platforms, and the effects of those interventions on the public sphere.
5.全球用户体验设计:我们需要考虑这些评分如何跨平台面向面向受众的用户界面干预,以及这些干预对公共领域的影响。
5.1. The schema is designed for fact-checkers, not end-users. Platforms need to work together to understand the effects of displaying ratings on audience beliefs and behaviors, globally.
5.1。 该架构是为事实检查人员而不是最终用户设计的。 各平台需要共同努力,以了解全球范围内显示收视率对受众信仰和行为的影响。
5.2. Users need to have opportunities to appeal manipulated media ratings.
5.2。 用户需要有机会呼吁操纵媒体评级。
Alongside these concerns, we outline immediate recommendations for platforms, as well as a call for platforms to transparently communicate their plans for using the schema to ensure accountability from the public and civil society.
除了这些担忧之外,我们还概述了针对平台的即时建议,并呼吁平台透明地交流其使用该模式的计划,以确保公众和民间社会的问责制。
1.操纵的媒体类别 (1. Manipulated Media Categories)
1.1只有达到内部编码器可靠性阈值后,才应部署任何类别的类别。 (1.1 Any set of categories should only be deployed once an intercoder reliability threshold has been hit.)
Schema development is iterative. The Reporters’ Lab rightfully recognizes that defining manipulated media categories is a process that never truly ends, only adapts to evolving media. Yet in the short-term, if the MediaReview schema is to be used as input into content moderation decisions, it is crucial to ensure that fact-checkers deciding categorization have proper training and input to ensure that any categories are both meaningfully and consistently applied.
模式开发是迭代的。 记者实验室正确地认识到,定义可操纵的媒体类别是一个永远不会真正结束的过程,只会适应不断发展的媒体。 然而,在短期内,如果要将MediaReview模式用作内容审核决策的输入,那么确保决定类别的事实检查人员必须接受适当的培训和输入,以确保有意义且一致地应用任何类别,这一点至关重要。
For example, if a fact-checking organization in India tags one video of a protest as “Edited” and another in the United States would tag the same protest video as “Transformed,” that means that platforms can not reliably depend on the schema to provide a systematic understanding of the rated media for their global users. Further, these ratings say nothing of the relative harm or misleading nature of the content–evaluations that may also differ from person to person and in different geographies. Before deployment, platforms need to continue to support researchers, both internally and at institutions like the Reporters’ Lab, in order to ensure rigorous intercoder reliability testing with fact-checkers internationally on a range of mis/disinformation issues.
例如,如果印度的事实检查组织将抗议视频的一个视频标记为“已编辑”,而美国的另一个视频组织将同一抗议视频标记为“已转换”,则意味着平台无法可靠地依赖该架构来为全球用户提供对评级媒体的系统了解。 此外,这些分级还没有说明内容的相对危害或误导性-评估可能因人而异,并且在不同地区也有所不同。 在部署之前,平台需要继续在内部以及在诸如Reporters'Lab之类的机构中为研究人员提供支持,以确保在国际范围内使用事实检查器针对各种错误/虚假信息进行严格的编码器可靠性测试 。
1.2随着新策略的出现,类别会发展吗? (1.2 As new tactics emerge, will the categories evolve?)
In addition, recognizing the shifting nature of these mis/disinformation categories, the schema would benefit from supporting the tagging of specific tactics beyond high-level categories like “Missing Context” and “Edited.” Many recent examples highlight the need for a schema to flexibly account for a range of evolving media manipulation techniques and their relative harms in various contexts. The Reporters’ Lab is currently accepting feedback on categories, and should build in mechanisms to continually assess categories over time in order to adapt to new tactics.
此外,认识到这些错误/虚假信息类别的变化性质,该模式将受益于支持对特定策略的标记,这些标记除了“缺少上下文”和“已编辑”等高级类别之外。 最近的许多例子都强调了一种模式的需求,该模式可以灵活地应对一系列不断发展的媒体操纵技术及其在各种情况下的相对危害。 记者实验室目前正在接受有关类别的反馈 ,并且应建立机制以随着时间的推移不断评估类别,以适应新的策略。
These tactics should be defined not as static, top-down categories, but rather as categories that are emergent from the bottom-up patterns observed directly on the ground by fact-checkers within local contexts, given that the intents and types of manipulations may look very different in Europe, compared to the United States, compared to the Global South, and so on. Emerging tactics include: “Lip-sync deepfakes” created for political purposes, as seen in a Belgian deepfake of Donald Trump, or translation purposes, such as an Indian politician translating speeches; “face-swapping,” as seen in a video where Jordan Peele use AI to make Barack Obama deliver a PSA about fake news; audio-splicing satire: satire that could reasonably be seen as authentic, as seen in the Bloomberg campaign’s “crickets” post; image quoting, or mis-contextualizing a quote through association with an image, as seen in numerous fake Trump quotes; and misleading subtitles, as seen in a video with a woman in Wuhan with misleading claims that she was a nurse. Currently, all of these manipulation types would be captured only through an “Original Media Context” field for describing the media in MediaReview, making structured analysis and interventions difficult.
不应将这些策略定义为静态的,自上而下的类别,而应将其定义为由事实检查人员在本地上下文中直接从实地观察到的自下而上的模式中出现的类别,因为可能会发现操纵的意图和类型在欧洲,与美国相比,与全球南方相比,差异很大,依此类推。 新兴的策略包括:为政治目的而创建的“口型同步深造”,如比利时唐纳德·特朗普的深造 ,或翻译目的,例如印度政客翻译演讲 ; 在视频中看到“交换面Kong”, 乔丹·皮尔(Jordan Peele)使用AI让巴拉克·奥巴马(Barack Obama)提供有关假新闻的PSA ; 音频拼接讽刺:如彭博社竞选“板球”一文中所见,可以合理地视为真正的讽刺; 图片引用,或通过与图片的关联将引用误解为上下文,如大量假特朗普引用所示 ; 以及带有误导性字幕的视频,如在与一名武汉妇女的视频中看到的那样,该视频误导了她是一名护士 。 当前,所有这些操作类型都只能通过“原始媒体上下文”字段捕获,以在MediaReview中描述媒体,这使得结构化分析和干预变得困难。
In summary, insufficiently precise or consistent ratings become a poor “ground truth” or foundation in training data for use in automation, with the potential to lead to harmful downstream effects. These categories, in turn, should have transparent connections to proposed content moderation policies.
总而言之,不够精确或不一致的评级将成为可用于自动化的培训数据的较差的“基础事实”或基础,并有可能导致有害的下游影响。 反过来,这些类别应该与提议的内容审核策略具有透明的联系。
2.等级与危害的关系 (2. Relationship of Ratings to Harm)
2.1如果平台使用“损害”来证明许多政策(举报,降级,删除)中概述的决定是合理的,则对于那些对内容和受众进行事实检查的事实,必须明确损害的定义。 它们不能是不透明的或临时的。 (2.1 If platforms are using ‘harm’ to justify decisions as outlined in many policies (flagging, de-ranking, take-downs) definitions of harm need to be clear to those fact-checking the content as well as audiences. They cannot be opaque or ad-hoc.)
Manipulation type alone tells you little about the harm of an instance of manipulated media in a given context. Because MediaReview categories like “Edited” do not neatly lend themselves to explicit mappings of harm or the extent to which content misleads, they may carry a dangerous implicit assumption that they are all equally harmful — an assumption whose harms would then be further amplified when ratings are automatically extended to apply to all detected instances of matching images and videos.
在给定的上下文中,仅使用操纵类型就无法告诉您操纵介质实例的危害。 由于MediaReview类别(例如“ Edited”(编辑))不能巧妙地将其自身映射到危害的明确映射或内容误导的程度,因此它们可能带有危险的隐性假设,认为它们都是同等有害的-当收视率分级时,其危害会进一步放大会自动扩展为适用于所有检测到的匹配图像和视频实例。

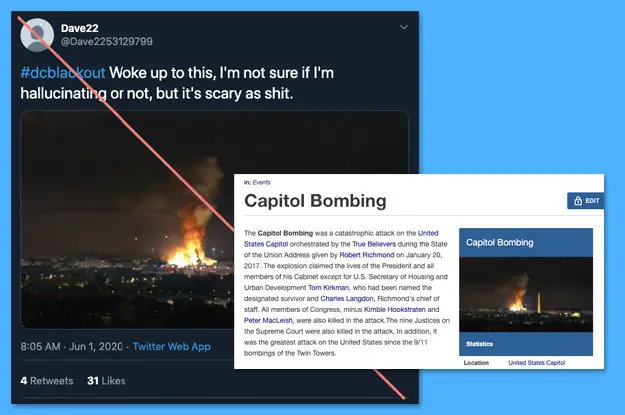
Consider that one of the most damaging media manipulation disinformation tactics doesn’t even require opening a photo-editing platform, such as a recent “Missing Context” example which falsely claims that a screenshot from the TV show “Designated Survivor” is a photo of protests in D.C. (example 27): a post with the potential to incite real world violence in support of an invented reality. On the other end of the spectrum, many “Transformed” examples of technically-sophisticated deepfakes pose minimal harm, such as a user’s satirical face-swapping of Jennifer Lawrence and Steve Buscemi. In other words, it is not safe to assume “the more edited, the more harmful.” However ratings play into moderation, it is clear that they require human review about distinct intents and harms of media, from satirical to malicious, within specific cultural contexts.
考虑到最具破坏性的媒体操纵虚假信息策略之一甚至不需要打开照片编辑平台,例如最近的“缺失上下文”示例错误地声称电视节目“指定幸存者”中的屏幕截图是哥伦比亚特区的抗议活动(示例27) :具有煽动现实世界暴力以支持虚构现实的潜力的帖子。 另一方面,许多技术上深造的“变形”示例带来的危害最小,例如用户对珍妮弗·劳伦斯和史蒂夫·布塞米的讽刺性表情。 换句话说,假设“编辑越多越有害”是不安全的。 但是,评级要适度,很明显,它们需要人工审查媒体在特定文化背景下从讽刺到恶意的不同意图和危害。
2.2 We need clearer explanations of the ways in which harm is measured in specific local contexts, for example, the threat of immediate real-world harms, such as media inciting violence, versus longer-term harms, like anti-vaccine conspiracies.
2.2我们需要对在特定的本地情况下衡量危害的方式进行更清晰的解释,例如,直接现实世界的危害(如煽动暴力的媒体)的威胁与长期危害(如反疫苗的阴谋)的威胁。
These examples point to a need for a much deeper investment in both defining a theory of harm about instances of both manipulated media, as well as human moderation and oversight of how those media are displayed or not displayed to end-users, adapted to specific, local contexts. Currently, platforms lack consistent and clear theories of harm for any content on their platforms, and this inconsistency would extend to MediaReview ratings.
这些示例表明,需要在定义关于两种受控媒体实例的伤害的理论以及人为调节和监督这些媒体如何向最终用户展示或不展示(针对特定用户,当地情况。 当前,平台对平台上的任何内容缺乏一致而明确的危害理论,这种矛盾将扩展到MediaReview评级。
In formulating theories of harm, platforms can turn to civil society for inspiration, such as the Rabat Principles, drafted to inform law about content that might incite hatred. The Principles outline six thresholds to assess hate speech: (i) the social and political context, (ii) the speaker, for example his or her status and influence, (iii) the intent of the speech, (iv) the content or form of the speech, (v) the extent of the speech (vi) the likelihood and imminence of actually causing harm. This sentiment has been echoed by David Kaye, UN Special Rapporteur on Freedom of Expression, who called the principles “a valuable framework for examining when the specifically defined content — the posts or the words or images that comprise the post — merits a restriction.” Additional analyses from the human rights space include Article 19’s “hate speech pyramid”, or the Dangerous Speech Project’s dangerous speech framework.
在制定伤害理论时,平台可以求助于民间社会,例如拉巴特原则 ( Rabat Principles) ,其起草目的是将可能煽动仇恨的内容告知法律。 原则概述了评估仇恨言论的六个阈值:(i)社会和政治背景;(ii)演讲者,例如他或她的地位和影响;(iii)演讲的意图;(iv)内容或形式(v)演讲的范围(vi)实际造成伤害的可能性和迫在眉睫。 联合国言论自由问题特别报告员戴维·凯(David Kaye)对此表示赞同 ,他称该原则“是审查特定定义的内容-帖子或组成帖子的文字或图像何时应受限制的宝贵框架。” 人权领域的其他分析包括第19条的“仇恨言论金字塔” ,或“危险言论计划”的危险言论框架 。
Article 19 hate speech pyramid outlining treatment of harmful content that is consistent with international human rights law
第19条 仇恨言论金字塔 概述了符合国际人权法的有害内容的处理
Any moderation decision around manipulated media should be considered alongside an analysis of its harms of the claims associated with the media, and not based on the type of manipulation alone. How might content moderation take both the media manipulation and claim ratings into account toward responsible policies? As platforms consider how MediaReview ratings relate to harm, it may be helpful to reference the ClaimReview ratings nested within MediaReview, which provide fact-checks for specific claims associated with the media.
关于操纵媒体的任何适度决策都应与对其与媒体相关的主张的危害的分析一起考虑,而不应仅基于操纵的类型。 对于负责任的政策,内容审核如何将媒体操纵和索赔评级都考虑在内? 当平台考虑MediaReview评分与伤害之间的关系时,参考嵌套在MediaReview中的ClaimReview评分可能会有所帮助, MediaReview评分为与媒体相关的特定声明提供事实检查。
3.操纵媒体的存档 (3. Archiving of Manipulated Media)
3.1提供受评级媒体的公共档案,以使第三方能够进行关键的查询,分析和证据使用。 (3.1 Provide public archives of rated media to enable critical inquiry, analysis, and evidentiary use by third-parties.)
Additional questions raised by MediaReview: how should MediaReview data be stored, who holds the key to that data, and who gets to benefit from it? The schema currently has fields including the posts in question, original media URLs, and articles with detailed fact-checks. MediaReview does not yet provide a way to store the images/videos that are fact-checked, only URLs. The Reporters’ Lab team is in the process of assessing storage options.
MediaReview提出的其他问题:MediaReview数据应如何存储,谁拥有该数据的密钥,谁能从中受益? 该模式当前具有字段,包括相关的帖子,原始媒体URL和带有详细事实检查的文章。 MediaReview尚不提供一种方法来存储经过事实检查的图像/视频,仅存储URL。 记者实验室团队正在评估存储选项。
Archiving this content is a complex but crucial challenge for MediaRevia to address from a technical, ethical, and legal perspective, with many stakeholders to consider, including journalists, fact-checkers, researchers, regulators, and the general public.
对于MediaRevia来说,从技术,道德和法律角度解决此内容是一个复杂而关键的挑战,要考虑许多利益相关者,包括记者,事实检查人员,研究人员,监管人员和公众。
Access to these archives is important for multiple use cases. First, lack of access affects fact-checkers, who often need to see if an item has already been checked, or need access to past fact-checked media in order to defend their own work. These access needs are often urgent and time-sensitive — for example, the need to view recycled imagery that continues to reappear and spread during recurring contexts like natural disasters, despite repeated debunking. In addition, there is a strong public interest argument for archiving the data: access to manipulated media and ratings could better equip legislators, regulators, and other third parties to respond to critical moments for information flow, such as during natural disasters, terrorist attacks, public health crises, and elections. Finally, these archives are invaluable to understanding hate speech, human rights claims, and other investigations–even when the footage is no longer publicly visible due to removal by platforms or users.
对于多个用例,访问这些档案很重要。 首先,缺乏访问权限会影响事实检查人员,事实检查人员通常需要查看某个项目是否已被检查,或者需要访问过去的事实检查媒体以捍卫自己的作品。 这些访问需求通常是紧急的且对时间敏感的,例如,需要查看回收的图像,该图像在自然灾害等重复发生的情况下会不断出现并散布 ,尽管它们屡屡遭到破坏。 此外,对于存档数据存在强烈的公共利益论据:对受控媒体和评级的访问可以使立法者,监管机构和其他第三方更好地应对信息流的关键时刻,例如在自然灾害,恐怖袭击,公共卫生危机和选举。 最后,这些档案对于理解仇恨言论,人权主张和其他调查具有无价的作用,即使这些镜头由于平台或用户删除而不再公开可见。
3.2创建具有公民社会告知的所有权,访问控制和监督机制的档案。 (3.2 Create archives with ownership, access controls, and oversight mechanisms as informed by civil society.)
There are two key elements to consider in assessing models for archives: ownership and access controls.
在评估档案模型时,需要考虑两个关键要素:所有权和访问控制。
What is the content of the archive, and who stands to gain from access to that content? The archive will contain media with a range of harms and legality, from memes about The Cure to violent and/or sexually explicit imagery (a 2019 report Deeptrace found that 96% of the deepfake videos they identified contained pornographic content). When and how to provide access to these media should ultimately be a question assessed in coordination with human rights, archival and civil society groups with nuanced consideration of archival practices, free speech protections, privacy, consent, and additional unintended consequences.
档案的内容是什么,谁能从访问该内容中受益? 该档案库将包含各种危害和合法性的媒体,从有关治愈的模因到暴力和/或露骨的色情图像(2019年的报告Deeptrace发现,他们确定的Deepfake视频中有96%包含色情内容)。 何时,如何以及如何提供这些媒体的访问权,应最终与人权,档案和民间社会团体协调评估,并仔细考虑档案做法,言论自由保护,隐私权,同意以及其他意想不到的后果。
Although uncommon, archiving services have also been misused by malicious actors, who have used it as a way to get around flagging by platforms and actually further amplify the harmful content. For example, some users who’ve had posts removed by platforms like Medium and YouTube for containing false and unsubstantiated claims about COVID-19 have found ways to re-share content through other avenues, such as Google Drive and Internet Archive links. (For their part, Internet Archive recently responded by displaying their own warning in an archived version of the article containing unsubstantiated claims.)
归档服务虽然不常见,但也遭到恶意行为者的滥用,他们将其用作绕过平台进行标记并实际上进一步放大有害内容的一种方式。 例如,一些用户因包含虚假且未经证实的关于COVID-19的声明而被Medium和YouTube等平台删除了帖子的用户,已经找到了通过其他途径(例如Google Drive和Internet Archive链接)重新共享内容的方法。 (就其本身而言,Internet存档最近做出了回应,在包含未经证实的声明的文章的存档版本中显示了自己的警告。)
Yet, with appropriate access restrictions in place, the data has powerful potential to support investigations in the public interest. Some options include an embargoed archive, in which archive contents become public after a certain period of time; an “evidence locker,” an archive that is not public but accessible under certain circumstances, for example, for approved reviewers or academics; or public datasets with some amount of friction, such as email sign-up, similar to Twitter’s Transparency Report. Additionally, MediaReview can take inspiration from existing examples of how civil society organizations maintain repositories containing sensitive content that it is in the public interest, such as Mnemonic’s Syrian Archive.
但是,由于适当的访问限制,数据具有强大的潜力来支持出于公共利益的调查。 一些选择包括禁运档案,其中档案内容在一定时间后会公开; “证据储物柜” ,是不公开的档案,但在某些情况下(例如,经批准的审阅者或学者)可以访问的档案; 或公开数据集,如Twitter的透明度报告 ,可能会产生一些摩擦,例如电子邮件注册。 此外,MediaReview可以从现有示例中汲取灵感,这些示例涉及民间社会组织如何维护包含公共利益的敏感内容的存储库,例如Mnemonic的叙利亚存档 。
In terms of ownership, there are many questions around which parties might own the archive, and the governance rules for those parties. The archive could be owned by one or several partners, decentralized so that ownership is distributed across multiple organizations, or completely decentralized, as in the Tor network where anyone is able to maintain and deploy a “Tor node”, or serverless as in the BitTorrent p2p file-sharing protocol. Regardless of the exact ownership model, it is crucial that no one party be able to monopolize and benefit from the archive’s data.
在所有权方面,存在许多问题,哪些方可能拥有档案,以及这些方的治理规则。 档案可以由一个或几个合作伙伴拥有,可以分散以使所有权分散到多个组织中,也可以完全分散,例如在Tor网络中,任何人都可以维护和部署“ Tor节点 ”,或者在BitTorrent中是无服务器的p2p文件共享协议 。 不管确切的所有权模型如何,至关重要的是,任何一方都不能垄断档案数据并从中受益。
Ultimately, this is a complex question and demands considering all of the relevant stakeholders and threat models for providing access to media before making a decision. However, we believe that the data should not be monopolized by platforms, but rather either maintained in a decentralized way without a single owner, or in coordination with one or more third-parties who might serve as a responsible steward for data over the long-term.
最终,这是一个复杂的问题,需要在决策之前考虑所有相关的利益相关者和威胁模型,以提供对媒体的访问。 但是,我们认为,数据不应由平台垄断,而应以分散的方式进行维护,而不需要一个所有者,或者与一个或多个第三方协作,这些第三方可能长期负责数据的管理。术语。
4.自动图像和视频匹配技术 (4. Automated Image and Video Matching Technology)
4.1危害评估应在相关背景下的职位级别进行,而不是作为媒体资产的固有属性进行评估,该资产可以始终扩展到所有实例中。 (4.1 Harm-assessment should be made at the level of a post in context, rather than as an inherent property of a media asset that can always be extended across all instances.)
From a framework of the relative harms of instances of posts containing manipulated media, it is further important to consider how those assessments might be extended through automated detection of duplicate media. Currently, platforms such as Facebook use “local feature-based instance matching” to detect all instances of images and videos across the platform and apply relevant interventions. While this technique seems to offer the potential for effective triage of false and misleading media, there are profound risks to applying interventions based on media detection alone.
从包含操纵媒体的帖子实例的相对危害的框架来看,考虑如何通过自动检测重复的媒体来扩展这些评估更为重要。 当前,诸如Facebook之类的平台使用“基于本地特征的实例匹配”来检测整个平台上图像和视频的所有实例并采取相关干预措施。 尽管此技术似乎提供了对错误和误导性媒体进行有效分类的潜力,但仅基于媒体检测的干预措施仍存在巨大风险。
Crucially, the matching approach is problematic because it assumes that ratings are an inherent property of media that can always be extended across all instances, rather than that ratings are applied for specific media shown in specific contexts. Even if images or videos themselves are identical, different user contexts can drastically change the meaning. As a result, when platforms automatically extend the application of a fact-check based only on a media asset, they often end up showing warnings on media shared in legitimate contexts.
至关重要的是,匹配方法存在问题,因为它假定评级是媒体的固有属性,可以始终将其扩展到所有实例中,而不是将评级应用于特定上下文中显示的特定媒体。 即使图像或视频本身是相同的,不同的用户上下文也可以极大地改变含义。 结果,当平台仅基于媒体资产自动扩展事实检查的应用时,它们通常最终会在合法上下文中共享的媒体上显示警告。
This is a current problem with the potential to be extended with MediaReview’s implementation, if media ratings are used in matching processes. For example, in March 2020, a video depicting police brutality in Hong Kong in 2019 was later shared and fact-checked with a false claim related to COVID-19. The video then rippled through the platform with a “false” label, so that even when others tried to share with accurate context, it was still flagged. The “false positive” of flagging this legitimate media as false invites abuse and denial of actual events in Hong Kong.
如果在匹配过程中使用了媒体评级,则这是当前的问题,可能会随着MediaReview的实现而扩展。 例如,在2020年3月,一段视频描述了2019年香港警察的暴行,后来被分享并进行了事实检查,并提出了与COVID-19有关的虚假声明。 然后,视频在平台上波动,并带有“假”标签,因此即使其他人尝试在准确的上下文中共享视频, 也仍会对其进行标记 。 将该合法媒体标记为“假”的“假阳性”招致滥用和否认香港的实际事件。
In summary, neither a claim rating associated with media, nor the technical properties of a visual asset (e.g. pixel content) can be reliably used as a proxy for its harm across all media instances. As we’ve seen in 2.1, technical manipulation properties, such as whether a video employs face-swapping technologies vs. audio distortion, tell you little about that media’s potential to cause harm. Context detection must go hand-in-hand with duplicate media detection. Contextual, human judgments are integral to making responsible policy decisions that protect human rights and prevent abuse internationally.
总而言之,与媒体关联的索赔评级或视觉资产的技术属性(例如像素内容)都不能可靠地用作代理其在所有媒体实例中的危害的代理。 正如我们在2.1中所看到的那样,技术操纵属性(例如,视频是否采用面部交换技术还是音频失真)几乎无法告诉您该媒体可能造成伤害的可能性。 上下文检测必须与重复的媒体检测齐头并进。 在做出负责任的政策决定时,必须根据上下文进行人为的判断,以保护人权并防止国际上的滥用。
4.2事实检查人员需要更多关于跨平台出现在哪里的上下文,并且应该能够理解和控制他们的评分如何在整个比赛中传播。 (4.2 Fact-checkers need more context on where matches appear across platforms, and should be able to understand and control how their ratings will propagate across matches.)
If ratings are to be used to trigger interventions in concert with matching technologies, platforms need to more deeply, ethically, and systematically invest in the role of human moderators and fact-checkers to prevent displaying inappropriate interventions for duplicate media. Matching can first be used to provide humans with the results of matches across platforms in order to help them understand the context of media they’re rating. Further, it is crucial that these humans can understand and exercise localized editorial judgement in the usage of their ratings by platforms, and the social impacts in terms of how their ratings might be used to label, downrank, or remove that media on platforms.
如果要使用评级来与匹配技术一起触发干预,则平台需要更深入,更道德地,更系统地投资于人类主持人和事实检查者的角色,以防止对重复媒体显示不当干预。 匹配可以首先用于为人们提供跨平台的匹配结果,以帮助他们了解所评估媒体的环境。 此外,至关重要的是,这些人必须了解并运用平台在使用其评级时的本地化编辑判断,以及在如何使用其评级在平台上标记,降级或删除该媒体方面的社会影响。
Why is localized judgement so important? Consider that a fact-checker in Brazil reviewing content may have very different needs from the needs of a fact-checker in India, given their unique understandings of the relevant actors, media frames, and threats of the posts they’re rating. Moderation policies should take into account the different media environments of countries, and active feedback from moderators and fact-checkers can help in this evaluation.
为什么本地化的判断如此重要? 考虑到巴西的事实检查人员在审查内容方面的需求可能与印度的事实检查人员的需求截然不同,因为他们对相关演员,媒体框架以及所评级帖子的威胁有着独特的理解。 审核政策应考虑到国家/地区的不同媒体环境,版主和事实检查员的积极反馈可以帮助进行此评估。
Fact-checkers are on the frontlines of social networks: often their knowledge about the nature of the information flow in their countries, as well as in which context the information they are tagging is inserted, is deeper than platforms’ policy makers. That means fact-checkers should have an understanding of the impacts of their ratings and be able to provide the platforms with feedback on those in a way that is beneficial to both parties. Human moderators and fact-checkers should be appropriately consulted in automation decisions, and acknowledged and compensated for the profound editorial value they provide in informing these systems.
事实检查人员处于社交网络的最前沿:通常,他们对自己国家/地区信息流的性质以及在其插入的背景信息的了解要比平台的政策制定者要深。 这意味着事实检查人员应该了解其评级的影响,并能够以对双方都有利的方式向平台提供有关这些评级的反馈。 在自动化决策中,应适当咨询人类主持人和事实检查者,并承认和补偿他们为这些系统提供的深刻编辑价值。
5.全球用户体验设计 (5. Global User Experience Design)
5.1该架构是为事实检查人员而非最终用户设计的。 各平台需要共同努力,以了解全球范围内显示收视率对受众信仰和行为的影响。 (5.1 The schema is designed for fact-checkers, not end-users. Platforms need to work together to understand the effects of displaying ratings on audience beliefs and behaviors, globally.)
Finally, platforms need to work together to understand the effects of displaying ratings on audience beliefs and behaviors, globally. How can platforms better collaborate in conducting and sharing research about how they might display the schema to end-users in order to reduce the spread of false/misleading information across platforms? Without explicit consideration of how platforms intend to surface or not surface the schema to end-users, we risk building infrastructure that will be harder to adapt toward these ends after they’re built and deployed.
最后,平台需要共同努力,以了解全球范围内显示收视率对受众信念和行为的影响。 平台如何更好地协作进行和共享有关如何向最终用户显示架构的研究,以减少跨平台的错误/误导性信息的传播? 如果没有明确考虑平台打算如何向最终用户显示或不显示模式,我们将冒着建立基础设施的风险,这些基础设施在构建和部署之后将很难适应这些目标。
Inappropriate design choices may have the opposite of the intended effects for clarity in the public sphere. For example, in the Hong Kong police riot with a false claim related to COVID-19 was fact-checked and then displayed on Instagram with a “False” rating from Indian fact-checker Boom Live. Comments around the post note confusion about what the rating means, who the fact-checkers were, and why this was applied for what they knew to be legitimate media. This treatment negatively affects both users and fact-checkers.
为了在公共领域清晰起见,不合适的设计选择可能会与预期的效果相反。 例如,在香港警方骚乱中,对与COVID-19相关的虚假声明进行了事实检查,然后在Instagram上以印度事实检查员Boom Live的“假”等级进行了显示。 围绕该帖子的评论混淆了该评分的含义,谁是事实检查者以及为什么将其用于他们知道是合法媒体的内容。 这种处理方式对用户和事实检查者都具有负面影响。
As a result, for platforms who adopt the MediaReview schema, we caution against opportunistic use of these categories as UI labels without first defining and testing against goals that expressly reference societal effects, and designing interventions from a community-oriented lens. Additionally, platforms should commit to design processes that incorporate community-based design principles, and meaningfully engage external stakeholders, especially at-risk and marginalized groups. Examples of such principles include MIT’s design justice principles or BSR’s 5 steps for stakeholder engagement. For example, how might platforms systematically commit to connecting with communities through these engagement steps in order to enact principles like 10: “Before seeking new design solutions, we look for what is already working at the community level. We honor and uplift traditional, indigenous, and local knowledge and practices?” This means working directly with affected communities in order to build upon practices that they are already using to educate and protect each other from the tangible harms of mis/disinformation within specific contexts.
因此,对于采用MediaReview架构的平台,我们告诫不要在未首先明确定义和测试明确引用社会影响的目标并从社区取向的角度设计干预措施的情况下,机会主义地将这些类别用作UI标签。 此外,平台应致力于结合基于社区的设计原则的设计过程,并有意义地吸引外部利益相关者,尤其是处于风险和边缘化群体。 此类原则的示例包括MIT的设计正义原则或BSR的涉众参与的5个步骤 。 例如,平台如何通过这些参与步骤系统地致力于与社区联系,以制定10之类的原则:“在寻求新的设计解决方案之前,我们会寻找在社区层面已经有效的方法。 我们尊重并提升传统,本地和当地的知识和实践吗?” 这意味着直接与受影响的社区合作,以在他们已经用于在特定情况下教育和保护彼此免受错误/虚假信息的明显伤害的实践的基础上,开展工作。
5.2用户需要有机会对人为操纵的媒体评级产生吸引力。 (5.2 Users need to have opportunities to appeal manipulated media ratings.)
Crucially, given the subjective nature of these judgments, as well as the known adversarial dynamics described above in 3.1, users should have opportunities to appeal ratings. While current appeal systems exist, they are often impersonal, opaque, and insufficiently slow to meet the needs of end-users dealing with sensitive, time-critical media.
至关重要的是,考虑到这些判断的主观性以及上面3.1中描述的已知对抗性动态,用户应该有机会对评分进行上诉。 尽管存在当前的申诉系统 ,但它们通常不具个性,不透明且运行缓慢,无法满足处理敏感且时间紧迫的媒体的最终用户的需求。
Specific Recommendations
具体建议
All of this said, we recognize the extraordinary urgency of addressing the unprecedented amount of harmful manipulated media flooding platforms. Many of the issues presented here are complex — or even intractable — problems given the current scale and diversity of users participating on platforms. And while we don’t want perfect to be the enemy of the good, we also believe there are several specific, immediate steps platforms can prioritize in order to ensure responsible deployment of a rating schema that aims to balance the risks and benefits.
综上所述,我们认识到解决前所未有的有害操纵媒体泛滥平台的紧迫性。 鉴于当前参与平台的用户规模和多样性,此处提出的许多问题都是复杂的,甚至是棘手的问题。 尽管我们不希望完美成为商品的敌人,但我们也相信平台可以优先考虑几个具体的即时步骤,以确保负责任地部署旨在平衡风险和收益的评级架构。
These recommendations include:
这些建议包括:
Manipulated Media Categories
操纵的媒体类别
- Invest in rigorous testing across international fact-checking organizations to understand intercoder reliability and ensure media forensics and manipulation detection capacity for fact-checkers across a variety of examples 在国际事实检查组织中进行严格的测试,以了解编码器的可靠性,并确保各种示例中事实检查者的媒体取证和操纵检测能力
- Provide options for fact-checkers to select and suggest modifications to the schema in order to add structured data on a variety manipulation tactics, such as lip-sync deepfakes and face-swapping 为事实检查人员提供选项,以选择方案并建议对方案进行修改,以便根据各种操纵策略(例如口形同步的深造和换脸)添加结构化数据
Relationship of Ratings to Harm
等级与危害的关系
- Transparently communicate a theory of harm for manipulated media types based on international human rights guidelines 根据国际人权准则透明地传达对操纵媒体类型的伤害理论
Archiving of Manipulated Media
操纵媒体的存档
- Provide archives of rated media to enable critical inquiry, analysis, and evidentiary use by third-parties, with access controls, ownership, and oversight mechanisms as informed by civil society 提供额定媒体的档案,以使第三方能够进行关键性的查询,分析和证据使用,并具有民间社会告知的访问控制,所有权和监督机制
Automated Image and Video Matching Technology
图像和视频自动匹配技术
- Provide fact-checkers with transparency and control over where and how exactly their ratings will be used by platforms across instances of media 为事实检查人员提供透明度,并控制跨媒体实例的平台在何处以及如何准确使用其评级
Global User Experience Design
全球用户体验设计
- Before deploying interventions, test their effects on audience beliefs and behaviors, globally 在部署干预措施之前,请在全球范围内测试其对受众信念和行为的影响
- Incorporate community-based design principles that meaningfully engage external stakeholders, especially at-risk and marginalized groups 结合基于社区的设计原则,有意义地吸引外部利益相关者,尤其是处于风险和边缘化群体
- Ensure that users have access to fast and reasonable appeal mechanisms to flag false positives for manipulated media 确保用户有权使用快速合理的申诉机制,以标记对受控媒体的误报
A Call for Transparent, Multi-Stakeholder Strategy
呼吁采取透明的,多利益相关方战略
In terms of longer-term strategy, platforms need to share enough information to allow oversight from third parties to assess progress. In particular, platforms should commit to and share their plans for UX testing, moderation of categories, and any use of automated matching as it applies to MediaReview. These plans should include specifics, for example, a threshold for intercoder reliability of categories before deployment.
在长期战略方面,平台需要共享足够的信息,以允许第三方的监督来评估进度。 特别是,平台应致力于并共享其UX测试计划,类别审核以及适用于MediaReview的任何自动匹配的使用计划。 这些计划应包括细节,例如,部署之前类别间编码器可靠性的阈值。
As the Partnership on AI continues assessing this space through its AI and Media Integrity area, we aim to help facilitate coordination between platforms in order to make progress on these issues as they evolve over time in order to ensure the responsible deployment of a manipulated media rating schema.
随着AI合作伙伴关系继续通过其AI和媒体完整性领域评估该领域,我们旨在帮助促进平台之间的协调,以便随着这些问题的发展而在这些问题上取得进展,以确保负责任地部署可操纵的媒体评级模式。
With thanks to: Jonathan Stray (PAI), Marlena Wisniak (PAI), Dia Kayyali (WITNESS), Tommy Shane (First Draft), Victoria Kwan (First Draft), the AI & Media Integrity Steering Committee at PAI, The Duke Reporters’ Lab
感谢: Jonathan Stray (PAI), Marlena Wisniak (PAI), Dia Kayyali (WITNESS), Tommy Shane (初稿), Victoria Kwan (初稿),PAI的AI和媒体诚信指导委员会 , 《杜克大学记者》实验室
qt 操纵access


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









