





aws python库
No matter to what extent you try, there are always parts of your business process which are hard to automate. Automation helps to improve the business pipeline in many dimensions such as speed, accuracy, reliability, and consistency. For instance, in today’s global market, nearly every company is feeling pressure to get goods and services to market quickly and efficiently and to be first to the market whenever possible.
无论尝试到什么程度,业务流程中总有一些部分很难自动化。 自动化有助于在许多方面改善业务管道,例如速度,准确性,可靠性和一致性。 例如,在当今的全球市场中,几乎每家公司都感到压力,要求它们Swift有效地将商品和服务推向市场,并尽可能地抢先进入市场。
Technology acts as an enabler to business process automation (BPA), which provides fully automated workflows or semi-automated processes in the majority of businesses within various domains. Any organization that must enter data from paper forms or electronic documents like PDF files into a database can get a very high return on investment by automating the data entry, which reduces the time spent significantly.
技术是业务流程自动化(BPA)的推动力,业务流程自动化(BPA)在各个域中的大多数业务中提供了完全自动化的工作流或半自动化流程。 任何必须从纸质表格或电子文档(例如PDF文件)中输入数据的组织都可以通过自动执行数据输入来获得很高的投资回报,从而显着减少了花费的时间。
It’s all about reducing the time you spend chasing paper, managing paper, and entering data so that you can have meaningful conversations with clients.
这一切都是为了减少您花费在购买纸张,管理纸张和输入数据上的时间,以便您可以与客户进行有意义的对话。
Those PDF files can be invoices, financial statements, or any other form of document. Data in these documents need to be processed. But in the workflow, manually entering these data into an automated process will create a bottleneck. If you really find out, you’ll be surprised about the time spent to feed these data to computer systems.
这些PDF文件可以是发票,财务报表或任何其他形式的文档。 这些文档中的数据需要处理。 但是在工作流程中,将这些数据手动输入到自动化过程中会产生瓶颈。 如果您真的找到了答案,您会惊讶于将这些数据提供给计算机系统所花费的时间。
If you are to automate this process, there are a few tasks that need to be carried out during the automation process:
如果要自动化此过程,则在自动化过程中需要执行一些任务:
- Scanned images/ PDF files are recognized with OCR. 使用OCR识别扫描的图像/ PDF文件。
- Matching algorithms locate data elements within the text. 匹配算法在文本中定位数据元素。
- Fields that fail validation checks are presented to the operators for manual review and correction. 未通过验证检查的字段将显示给操作员,以进行手动检查和更正。
- Once all errors are corrected, data is exported to the final destination for further processing or storing. 纠正所有错误后,数据将导出到最终目的地以进行进一步处理或存储。
Luckily, to make your lives easier, AWS has provided AWS Textract, a document text extraction service. As noted in the documentation:
幸运的是,为了使您的生活更轻松,AWS提供了文档文本提取服务AWS Textract 。 如文档中所述:
“Amazon Textract is based on the same proven, highly scalable, deep-learning technology that was developed by Amazon’s computer vision scientists to analyze billions of images and videos daily. You don’t need any machine learning expertise to use it.”
“ Amazon Textract基于相同的经过验证的,高度可扩展的深度学习技术,该技术由亚马逊的计算机视觉科学家开发,用于每天分析数十亿个图像和视频。 您不需要任何机器学习专业知识即可使用它。”
So usability is at a much higher level. It will lower the entry barriers to OCR technologies for day-to-day businesses.
因此,可用性处于更高的水平。 它将为日常业务降低OCR技术的进入壁垒。

AWS Textract consists of higher capabilities than the average optical character recognition (OCR) system. From files stored in an Amazon S3 bucket, it’s able to extract the contents of fields and tables and the context in which this information is presented, like names and social security numbers in tax forms or totals from photographed receipts. Textract supports such image formats as scans, PDFs, and photos, and it ingests a range of document formats, including those specific to financial services, insurance, and health care.
AWS Textract具有比普通光学字符识别(OCR)系统更高的功能。 从Amazon S3存储桶中存储的文件中,它可以提取字段和表格的内容以及显示此信息的上下文,例如税表中的名称和社会保险号,或从照相收据中获得的总计。 Textract支持诸如扫描,PDF和照片之类的图像格式,并且可以摄取多种文档格式,包括特定于金融服务,保险和医疗保健的文档格式。
Connecting with many other Amazon Web Services, you can automate the workflow of extraction, processing, and storing the relevant data or feed those into another pipeline. The diagram below is one of the ways you can use Textract in your to automate the process.
与许多其他Amazon Web Services连接后,您可以自动化提取,处理和存储相关数据的工作流程,或将这些数据馈入另一个管道。 下图是在您的过程中使用Textract自动化过程的一种方法。
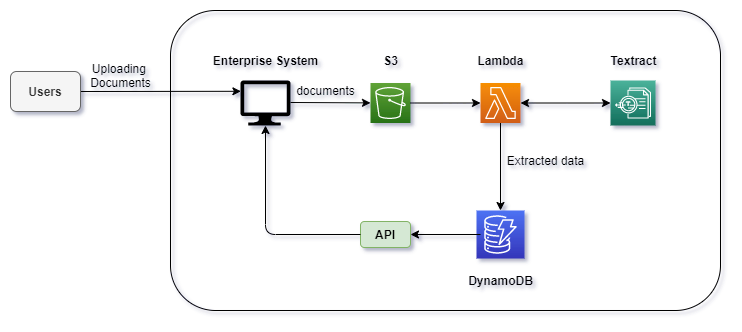
Instead of using Amazon DynamoDB, you can use MongoDB instance or even an S3 bucket itself to store the resulting data. Here a batch processing job will be running on AWS Lambda. You can easily replace that with an AWS Fargate instance according to your needs and constraints (e.g., if the job runs for more than 15 minutes). Instead, you can use AWS SNS in between the Lambda functions and the Textract service, which is a fully managed pub/sub messaging service that enables you to decouple services.
除了使用Amazon DynamoDB,您还可以使用MongoDB实例甚至S3存储桶本身来存储结果数据。 此处,批处理作业将在AWS Lambda上运行。 您可以根据自己的需要和约束条件(例如,如果作业运行超过15分钟),轻松地将其替换为AWS Fargate实例。 相反,您可以在Lambda函数和Textract服务之间使用AWS SNS,该服务是完全托管的发布/订阅消息服务,使您能够解耦服务。
When it comes to AWS Textract, there are three main types of results we can get. The first one is acquiring the resultant extraction in the form of raw text. The second method is to get the key-value pairs that happen to be in the corresponding documents. The third way is getting the table data extracted. The output will be a comma-separated values (CSV) file.
对于AWS Textract,我们可以得到三种主要类型的结果。 第一个是获取原始文本形式的结果提取。 第二种方法是获取恰好在相应文档中的键值对。 第三种方法是提取表数据。 输出将是逗号分隔值(CSV)文件。
1.提取原始文本 (1. Extract Raw Text)
Here is sample code in Python that can be used to extract text from PDF documents using AWS Textract. This supports multiple-page PDF files as well. This will suit as a method to extract freeform reports, tickets, and invoices.
这是Python中的示例代码,可用于使用AWS Textract从PDF文档提取文本。 这也支持多页PDF文件。 这将适合作为提取自由格式报告,票证和发票的方法。
If you want to extract the raw text data from an image file, the following code can be used. Using this kind of implementation would come in handy when it comes to the scanned documents in which the information needs to be stored in a more analyzable and organizable manner.
如果要从图像文件中提取原始文本数据,则可以使用以下代码。 当涉及到需要以更可分析和更可组织的方式存储信息的扫描文档时,使用这种实现方式将很方便。
2.提取键值对 (2. Extract Key-Value Pairs)
In automated form processing by extracting key-values pairs from a PDF file of a digitally filled form, Textract can be tremendously helpful. Setting aside manual checking, feeding the relevant data, and processing Textract help us to automated the whole pipeline without any significant human intervention. But in critical applications, as a practice, we can prompt the extracted information of the forms for the user to do any corrections, if necessary, and validate it before proceeding.
通过从数字填写的表单的PDF文件中提取键-值对来进行自动表单处理,Textract可能会非常有用。 搁置手动检查,提供相关数据以及处理Textract可以帮助我们自动化整个管道,而无需任何重大的人工干预。 但在关键应用中,作为一种实践,我们可以提示用户提取表格的信息,以便用户进行必要的更正,并在继续进行之前对其进行验证。
Note: You may use pdf2image or any Python package for if you want to convert the PDF files into images in order to run the above code snippet. (You may need to install Pillow as well. This might only work on Linux.)
注意:如果要将PDF文件转换为图像以便运行上述代码段,则可以使用pdf2image或任何Python软件包。 (您可能还需要安装Pillow 。这可能仅在Linux上有效。)
3.提取表数据 (3. Extract Table Data)
This is more suitable if your document consists of more tabular data. OCR Textract detects the tables in the document along with their content in an ordered manner. This helps to identify the relevant content with the formatting so that it returns the extracted information in the form of a CSV file. This is really helpful when it comes to handling PDF-based financial reports and invoices. This will pave the way to automate the process, resulting in the reduction of human intervention massively throughout the pipeline.
如果您的文档包含更多表格数据,则此方法更合适。 OCR Textract以有序的方式检测文档中的表格及其内容。 这有助于通过格式识别相关内容,从而以CSV文件的形式返回提取的信息。 在处理基于PDF的财务报告和发票时,这确实很有帮助。 这将为实现流程自动化铺平道路,从而减少整个管道中的人工干预。
Note: You may use pdf2image or any Python package for if you want to convert the PDF files into images in order to run the above code snippet. (You may need to install Pillow as well. This might only work on Linux.)
注意:如果要将PDF文件转换为图像以便运行上述代码段,则可以使用pdf2image或任何Python软件包。 (您可能还需要安装Pillow 。这可能仅在Linux上有效。)
结论 (Conclusion)
As described above, using AWS Textract would be a great way to reduce latency in the day-to-day processes in your business. According to your need, you can use one or more of the three methods of extractions. For example, in the rare case where Textract was unable to pick up certain tabular data or the value of a certain key, you could use raw-text extraction and some manual text mining using Python regex to extract those.
如上所述,使用AWS Textract将是减少企业日常流程中延迟的好方法。 根据您的需要,可以使用三种提取方法中的一种或多种。 例如,在极少数情况下,Textract无法获取某些表格式数据或某个键的值的情况下,您可以使用原始文本提取,并使用Python正则表达式进行一些手动文本挖掘来提取这些数据。
In addition to just mere extraction, Textract supports some NLP tasks as well, for when organizations need to localize their electronic documents, content, and websites for users that understand various languages. As a solution, Textract provides document translation integrated with extraction, which adds value to the original service.
除了纯粹的提取之外,Textract还支持一些NLP任务,以便组织需要将其电子文档,内容和网站本地化以供能理解各种语言的用户使用。 作为解决方案,Textract提供了与提取集成的文档翻译功能,从而为原始服务增加了价值。
See you in another interesting article!
在另一篇有趣的文章中见!
aws python库

















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









