






机器学习 深度学习 ai
介绍 (Introduction)
Online learning methods are a dynamic family of algorithms powering many of the latest achievements in reinforcement learning over the past decade. Belonging to the sample-based learning class of reinforcement learning approaches, online learning methods allow for the determination of state values simply through repeated observations, eliminating the need for explicit transition dynamics. Unlike their offline counterparts, online learning approaches such as Temporal Difference learning (TD), allow for the incremental updates of the values of states and actions during episode of agent-environment interaction, allowing for constant, incremental performance improvements to be observed.
Øn线段学习方法的算法很多强化学习,在过去十年中的最新成果供电的动态家庭。 属于强化学习方法的基于样本的学习类别,在线学习方法允许简单地通过重复观察来确定状态值,从而无需显式的转换动力学。 与离线离线 方法不同 , 在线学习方法(如时差学习(TD))允许在代理程序与环境交互的过程中逐步更新状态和动作的值,从而可以观察到持续不断的性能改进。
Beyond TD we’ve discussed the theory and practical implementations of Q-learning, an evolution of TD designed to allow for incrementally more precise estimations state-action values in an environment. Q-learning has been made famous as becoming the backbone of reinforcement learning approaches to simulated game environments, such as those observed in OpenAI’s gyms. As we’ve already covered theoretical aspects of Q-learning in past articles, they will not be repeated here.
除TD之外,我们还讨论了Q学习的理论和实际实现 ,Q学习是TD的发展,旨在允许逐步更精确地估计环境中的状态作用值。 Q学习已经成为模拟游戏环境中强化学习方法的骨干,例如在OpenAI的体育馆中观察到的。 由于我们已经在过去的文章中介绍了Q学习的理论方面,因此这里不再赘述。
In our previous article, we explored how Q-learning can be applied to training an agent to play a basic scenario in the classic FPS game Doom, through the use of the open-source OpenAI gym wrapper library Vizdoomgym. We’ll build upon that article by introducing a more complex Vizdoomgym scenario, and build our solution in Pytorch. This is the first in a series of articles investigating various RL algorithms for Doom, serving as our baseline.
在上一篇文章中 ,我们探讨了如何通过使用开源的OpenAI健身房包装库Vizdoomgym将Q-learning应用于训练代理在经典FPS游戏Doom中扮演基本场景的行为 。 我们将通过介绍更复杂的Vizdoomgym场景来构建该文章,并在Pytorch中构建我们的解决方案。 这是研究Doom的各种RL算法的系列文章的第一篇,这是我们的基线。
实作 (Implementation)
The environment we’ll be exploring is the Defend The Line-scenario of Vizdoomgym. The environment has the agent at one end of a hallway, with demons spawning at the other end. Some characteristics of the environment include:
我们将探索的环境是Vizdoomgym的Defend The Line场景。 环境在走廊的一端具有代理,而恶魔的另一端则产生。 环境的一些特征包括:
- An action space of 3: fire, turn left, and turn right. Strafing is not allowed. 3个动作空间,开火,向左转,再向右转。 禁止随行。
- Brown monsters that shoot fireballs at the player with a 100% hit rate. 以100%的命中率向玩家射击火球的棕色怪物。
- Pink monsters that attempt to move close in a zig-zagged pattern to bite the player. 试图以锯齿状移动的方式咬住玩家的粉红色怪物。
- +15 points for killing 16 monsters. 杀死16个怪物时获得+15分。
- +1 point for killing a monster 杀死怪物+1点
- - 1 for dying. -1死。
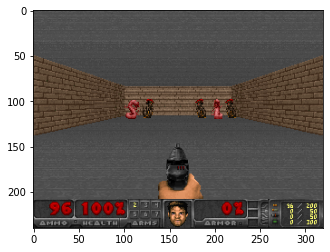
Implicitly, success in this environment requires balancing the multiple objectives: the ideal player must learn prioritize the brown monsters, which are able to damage the player upon spawning, while the pink monsters can be safely ignored for a period of time due to their travel time. This setup is in contrast to our previous Doom article, where single objectives were presented.
隐含地,在这种环境中的成功需要平衡多个目标 :理想的玩家必须学习区分棕色怪物的优先级,棕色怪物会在产卵时损坏玩家,而粉色怪物由于其旅行时间而可以安全地忽略一段时间。 此设置
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









