





人工智能的应用现状
Applied AI continues to accelerate, largely fueled by the maturation of tooling and infrastructure. Couple this infrastructure with a strong pool of talent and enthusiasm, readily accessible capital, and high customer willingness to adopt AI/ML and you’ve got something special. We’re turning the corner into a new decade where AI/ML will create real value for both the consumer and the enterprise at an accelerating pace.
在工具和基础设施日趋成熟的推动下,应用人工智能技术继续加速发展。 将此基础架构与强大的人才库和热情,易于获得的资金以及客户采用AI / ML的高度意愿相结合,您将获得一些特别的东西。 我们正在转弯进入新的十年,在这个新的十年中,AI / ML将以更快的速度为消费者和企业创造真正的价值。
定义术语 (Defining Terms)
Applied AI: anything to do with taking AI research from the lab to a use-case and everything in-between. From the infrastructure and tooling, to the hardware, to the deployment surfaces in industry, to the models themselves, it takes a village to get a bleeding edge advance in AI research to a use-case. One great test for maturation in our field is the time it takes for a new advance to get from paper to production. Even just a few years ago you could skim some of the major advances in the field and struggle to find real use-cases; this is quickly starting to change.
应用的AI:与将AI研究从实验室转移到用例有关的一切。 从基础架构和工具,到硬件,再到行业中的部署面,再到模型本身,需要花费大量时间才能使AI研究在用例领域取得前沿进展。 从纸质到生产的新进展需要在我们领域中进行成熟的一项伟大考验。 即使在几年前,您也可以浏览该领域的一些重大进展,并努力寻找真正的用例。 这很快就开始改变。
Some choice examples:
一些选择示例:
- Convolutional Neural Network research enabling self-driving cars (Tesla, Cruise, Waymo, etc.) 卷积神经网络研究可实现自动驾驶汽车(特斯拉,克鲁斯,Waymo等)
- NLP like BERT and GPT-2/3 improving search and assistants (Google Search, Siri, Google Assistant, SoundHound, Clinc) 像BERT和GPT-2 / 3这样的NLP改进了搜索和助手(Google搜索,Siri,Google助手,SoundHound,Clinc)
- Reinforcement Learning helping many companies realize the lofty promises of AI in industrial robotics (Covariant, FogHorn, Rethink) 强化学习帮助许多公司实现了AI在工业机器人技术中的崇高承诺(Covariant,FogHorn,Rethink)
- ML for fraud detection and consumer outcomes helping banks, credit cards, and lenders work to limit fraud and manage risk (Fraud departments at banks and credit cards, Verifi, Ravelin, Stripe) ML用于欺诈检测和消费者结果,可帮助银行,信用卡和贷方限制欺诈和管理风险(银行和信用卡欺诈部门,Verifi,Ravelin,Stripe)
- GANs enabling generating fresh content, realistic faces, and improve photo quality (generated.photos, rosebud.ai, RunwayML) GAN可以生成新鲜的内容,逼真的面Kong并改善照片质量(generated.photos,rosebud.ai,RunwayML)
To get from research into production takes far more than just a model. It takes a village of both research and engineering efforts in tandem to make these things work. It takes hardware, it takes scalable hosting, it takes DevOps, it takes great data science, and much more. Thankfully, more and more startups are building solutions for each building block, and big players (Uber and Netflix come to mind) are joining in as they open source more and more of their tooling.
从研究到生产要花费的不仅仅是模型。 要使这些工作正常进行,需要大量研究和工程工作共同努力。 它需要硬件,可扩展的托管,DevOps,出色的数据科学等等。 值得庆幸的是,越来越多的初创公司正在为每个构建模块构建解决方案,而且随着开源工具越来越多,大型企业( Uber和Netflix想到了)也加入了进来。
We’ll remember the all-stars who came up with new models, but the engineers turning it all into production code, the labelers creating your next dataset, and the mob vocally opposing the next breach of security and human rights should all be remembered for their contributions to our field.
我们会记住提出新模型的全明星,但是工程师都应该记住,他们将所有这些都变成了生产代码,贴标签者创建了您的下一个数据集,以及反对下一次违反安全和人权的暴民。他们对我们领域的贡献。
为什么现在? (Why now?)
We’re seeing huge opportunities for AI use-cases popping up in all industries. As tooling and infrastructure mature, new opportunities are becoming accessible to anyone that can write a few lines of code. Both disruption of existing markets and creation of new markets are being driven by adoption.
我们看到在所有行业中出现大量AI用例的机会。 随着工具和基础架构的成熟,可以编写几行代码的任何人都可以利用新的机会。 采用既驱动现有市场的破坏,又创造新市场。
We’ve already seen the proliferation of Machine Learning into your search engine, fraud detection on your credit card, the camera in your smartphone, and modern marketplaces. And we’re starting to see enterprise adoption as legacy companies invest in the tools and teams necessary to augment their products and processes with ML.
我们已经看到机器学习在搜索引擎中的普及,信用卡欺诈的检测,智能手机中的摄像头以及现代市场。 随着传统公司投资于使用ML扩展其产品和流程所需的工具和团队,我们开始看到企业的采用 。
In this essay we’ll cover not only the ways Applied AI has enabled some of our favorite products and features in the digital world, but we’ll also explore how Applied AI is changing workflows, creating new opportunities, and freeing up labor in fields like manufacturing, construction, supply chains, and commerce. We’ll go in depth on current trends in our field, while also taking some stances on where things are going.
在本文中,我们不仅将介绍应用人工智能在数字世界中实现一些我们最喜欢的产品和功能的方式,还将探讨应用人工智能如何改变工作流程,创造新机会并释放现场劳动力例如制造,建筑,供应链和商业。 我们将深入探讨该领域的当前趋势,同时对事情的发展趋势也持某些立场。
We can typically identify waves of innovation as enabled by some new technology or event. And in the past decade we have seen the inflection point for AI take us from a bundle of hype to real use-cases driving value across industry.
通常,我们可以将创新浪潮识别为某种新技术或新事件带来的影响。 在过去的十年中,我们已经看到AI的拐点将我们从一堆炒作转移到了在整个行业推动价值的实际用例。
So why is now the inflection point for a new wave of value in AI/ML?
那么,为什么现在是AI / ML的新一波价值转折点呢?
- Maturation of tooling and infrastructure 工具和基础设施的成熟
- Accessibility to training and serving at scale 无障碍获得大规模培训和服务
- Large-scale models as APIs 大型模型作为API
- Continued access to risk capital, research grants, and government interest 继续获得风险资本,研究经费和政府利益
工具和基础设施的成熟 (Maturation of tooling and infrastructure)
As best practices, tooling, and infrastructure start to mature, accessibility is dramatically increasing. In infrastructure and tooling an advanced team or large open source effort remain the norm. While in practical applications we are seeing successful startups built by junior engineers, budding statisticians, and entrepreneurs willing to sift through the mud to make their application work. And say hello to the flood of MBAs interested in taking part in this wave of opportunity.
随着最佳实践,工具和基础架构的成熟,可访问性正在急剧增加。 在基础架构和工具中,高级团队或大型开源工作仍然是常态。 在实际应用中,我们看到了由初级工程师,崭露头角的统计学家和企业家创建的成功创业公司,他们愿意在泥泞中筛选自己的应用程序。 并向有兴趣参加这一机会浪潮的MBA学员问好。
Additionally, an influx of talent, better coursework and training programs, and overall massive hype behind the movement has made hiring a good Data Scientist or Machine Learning Engineer less of a mission to outer space. Because of better tooling, Data Scientists and ML Engineers can go more narrow + deep and be very effective. And most MVPs can be built with either an off-the-shelf model or using one of the beautiful and highly accessible libraries like Scikit-Learn or Keras. We can make all the jokes we want about clf.fit(), but the fact actual models with real value are getting built in just a few lines is a good thing. When senior members of a field start to gripe about all the ‘fake engineers’ and ‘fake data scientists,’ what they really mean to say is, “I’m annoyed that junior people are doing in a few hours what used to take me a few weeks.”
此外,人才的涌入,更好的课程工作和培训计划以及运动背后的总体炒作,使得聘请优秀的数据科学家或机器学习工程师的工作不再像执行太空任务那样。 由于使用了更好的工具,数据科学家和ML工程师可以更加狭窄和深入,并且非常有效。 而且,大多数MVP都可以使用现成的模型或使用Scikit-Learn或Keras之类的美观且易于访问的库之一来构建。 我们可以就clf.fit()进行所有的笑话,但实际上只需几行就可以构建具有实际价值的实际模型,这是一件好事。 当某个领域的高级成员开始为所有“假工程师”和“假数据科学家” 所困扰时,他们真正要说的是:“我很生气,初级人员在几个小时内干了过去几个星期。”
And access to hardware is no longer a blocker. There are plenty of free compute hours lying around for the enterprising individual. Where early MVPs may have previously required a bit of bootstrapping or help from an angel, most non-research ideas can get off the ground with the primary blocker being access to data. This is a VERY GOOD THING. It’s fair to celebrate primary blockers to training models no longer being a niche skillset or access to expensive infrastructure.
而且,访问硬件不再是障碍。 有进取心的人们有很多免费的计算时间。 在早期的MVP可能以前需要一些引导或天使帮助的情况下,大多数非研究性的想法都可以通过获取数据的主要障碍而起步。 这是一件非常好的事情。 公平地庆祝主要的阻碍者接受不再是利基技能组或昂贵的基础设施的培训模型。
We’re seeing general consolidation in infrastructure around a handful of core products. AWS, GCP, and Azure remain the clear winners in this wave, with hardware from Nvidia and Intel dominating the data center. We’re also seeing companies pop into the space that take on more niche approaches like cleaner training + deployment (see Paperspace and FloydHub).
我们看到了围绕少数核心产品的基础架构的总体整合。 AWS,GCP和Azure在这一浪潮中显然是赢家,其中Nvidia和Intel的硬件主导着数据中心。 我们还看到公司进入这个领域,采取更利基的方法,例如更清洁的培训+部署(请参阅Paperspace和FloydHub)。
We’re obviously all intimately familiar with TensorFlow, PyTorch, Scikit-Learn and the other major modeling tools. Across industry we’re seeing the continued dominance of Jupyter and various clones for most modeling workflows. There’s also a clear split between more Data Science heavy workflows and ML Engineering workflows, where ML Engineers spend their time in their IDE of choice, while modelers spend more time in Jupyter and projects like Colab, Deepnote, Count, and others with their specific advantages.
我们显然都非常熟悉TensorFlow,PyTorch,Scikit-Learn和其他主要建模工具。 在整个行业中,我们看到Jupyter和各种克隆在大多数建模工作流程中仍占主导地位。 在更多的数据科学繁重的工作流程和ML Engineering工作流程之间也存在明显的区分,其中ML工程师将时间花在他们选择的IDE上,而建模人员则将更多时间花在Jupyter和诸如Colab,Deepnote,Count等具有其特定优势的项目上。
And these tools remain core to the ecosystem. But perhaps the biggest enabler in the last 5 years has been around deployments and serving. Docker and Kubernetes remain core to the ecosystem, while a number of tools have jumped in with their own unique value props. Kubeflow is quickly gaining steam, while TensorFlow Serving, MLFlow, BentoML, Cortex and others vie for similar chunks of the market by trying to enable all modelers to get their model into production with minimal effort. “Deploy models in just a few lines of code” is the tagline of numerous projects. Ease of deployment is great for customer acquisition; scaling and maintaining is what keeps customers in the long-term.
这些工具仍然是生态系统的核心。 但是,过去五年来最大的推动力可能是部署和服务。 Docker和Kubernetes仍然是生态系统的核心,同时许多工具也加入了自己独特的价值支持。 KubeflowSwift获得发展动力,而TensorFlow Serving,MLFlow,BentoML,Cortex和其他公司则试图通过使所有建模者以最小的努力使其模型投入生产来争夺类似的市场。 “仅用几行代码即可部署模型”是众多项目的口号。 易于部署对于吸引客户非常有用; 扩展和维护是保持客户长期利益的原因。
This innovation was to be expected, as the average Data Scientist and less engineering heavy ML Engineer likely isn’t terribly interested in spending too much time on DevOps, container orchestration, scaling, etc. And lots of teams are skipping out on hiring much engineering talent when building their initial core team. Mileage may vary.
这项创新是意料之中的,因为普通的数据科学家和工程量较小的ML工程师可能对在DevOps,容器编排,扩展等方面花费过多时间并不十分感兴趣。而且许多团队都在跳槽招聘许多工程人员建立最初的核心团队时的人才。 里程可能会有所不同。
I tend to look at Machine Learning efforts broadly in the following ladder. In the past we were forced to build many of these rungs ourselves or neglect certain steps entirely (messy versioning, nonexistent CI, manual scaling, only maintaining when the model is clearly broken). Thankfully plenty of teams are working to simplify our lives at almost every step:
我倾向于在以下阶梯中广泛地研究机器学习的工作。 过去,我们不得不自己构建许多梯级,或者完全忽略某些步骤(混乱的版本控制,不存在的CI,手动缩放,仅在模型明显损坏时才进行维护)。 值得庆幸的是,许多团队正在努力简化我们的生活,几乎每个步骤:
- Data management, schema, dataset versioning 数据管理,架构,数据集版本控制
- Model definitions, training, and evaluating 模型定义,培训和评估
- Serialization, serving 序列化,服务
- Deploying, CI/CD, and model versioning 部署,CI / CD和模型版本控制
- Monitoring and maintaining 监控与维护
In some cases the above efforts are very separate. In others, the same tool handles multiple steps in the process. For example, we might see a tool for serving also easily handle serialization. In other cases the library for training might be tightly integrated with serializing (pickle, joblib, dill, onnx, etc.). The interesting part of the ecosystem is how tooling is maturing to the point where you can have a full-service tool like BentoML, but you also have plenty of other options with additional customization if needed. More engineering heavy teams might not spend any time using Bento, Cortex, or other services that are intended for less technical audiences. Whereas I personally love tools like BentoML and Cortex because they save tons of time for our small team. MLOps is coming a long way.
在某些情况下,上述工作是非常分开的。 在其他情况下,同一个工具可以处理流程中的多个步骤。 例如,我们可能会看到一个可以轻松处理序列化的工具。 在其他情况下,用于培训的库可能与序列化紧密结合在一起(棘手,joblib,dill,onnx等)。 生态系统中有趣的部分是工具的成熟程度,使您可以拥有像BentoML这样的全方位服务工具,但是如果需要,您还可以通过其他自定义方式获得很多其他选择。 更多工程繁忙的团队可能不会花任何时间使用Bento,Cortex或其他旨在降低技术受众的服务。 我个人喜欢BentoML和Cortex之类的工具,因为它们可以为我们的小型团队节省大量时间。 MLOps将会走很长一段路。
It seems like the piece we’re missing the most in our space is monitoring and maintaining.
似乎我们空间中最缺少的部分是监视和维护。
Christopher Samiullah very nicely summarizes this here.
Christopher Samiullah很好地总结了这一点。
Obviously this list is incredibly biased towards tools I’ve used in the past or actively am using. Some tools which aren’t ML specific are excluded. For example, Airflow is a key part of many workflows but was exempted in this case. You’ll additionally see a clear bias for the Python ecosystem, perhaps to the chagrin of some. We also exclude databases, versioning, etc. Obviously data collection and cleaning are core to our workflows, but much of this process is not new to software engineering and is covered to far more depth elsewhere than I could ever cover here.. We mostly covered tooling excluded to modelers and ML Engineers, not Data Engineers, analysts, or BI heavy Data Science workflows.
显然,此列表非常偏向于我过去使用或正在积极使用的工具。 排除了一些不是ML专用的工具。 例如,气流是许多工作流程中的关键部分,但在这种情况下可以免除。 此外,您还会看到对Python生态系统的明显偏见,也许有些人对此感到cha恼。 我们还排除了数据库,版本控制等问题。显然,数据收集和清理是我们工作流程的核心,但是此过程中的大部分对于软件工程而言都不是新事物,而且在其他地方所涉及的范围比我在此所能涵盖的范围要深得多。建模人员和ML工程师(而不是数据工程师,分析师或BI繁重的数据科学工作流)排除的工具。
大规模通用模型作为API (Large scale generalized models as an API)
Let’s talk about the hype of GPT-3. I’m perhaps less excited about the outcomes of GPT-3 than I am about the approach as a model for the rest of the industry.
让我们谈谈GPT-3的炒作。 对于GPT-3的成果,我可能不如对作为行业其他模型的方法感到兴奋。
It seems likely that we’re gearing up for an arms race for the biggest and best (general purpose) models. Compute at that scale isn’t realistic for smaller companies and startups. Smaller efforts will have to favor clever optimizations and research overthrowing more and more compute at problems. A combination of the two seems to be the obvious winner here, and I’m expecting a general consolidation of the leading modeling efforts around a small group of companies with massive war chests that can afford the compute and fund the research. We will then see a few dominant players serving those models which are public and don’t require highly specialized data to work. These use-cases can be consumed by all sorts of products globally. Let’s visualize this.
看来我们可能正在为最大和最佳(通用)型号进行军备竞赛。 对于较小的公司和初创公司来说,如此规模的计算是不现实的。 较小的努力将必须支持聪明的优化和研究,从而推翻越来越多的问题计算。 两者的结合在这里似乎是明显的赢家,我希望围绕具有少量作战能力,能够负担计算能力并为研究提供资金的一小群公司,对领先的建模工作进行总体整合。 然后,我们将看到一些主导角色为那些公开的,不需要高度专业化数据的模型提供服务。 这些用例可以在全球范围内被各种产品使用。 让我们将其可视化。
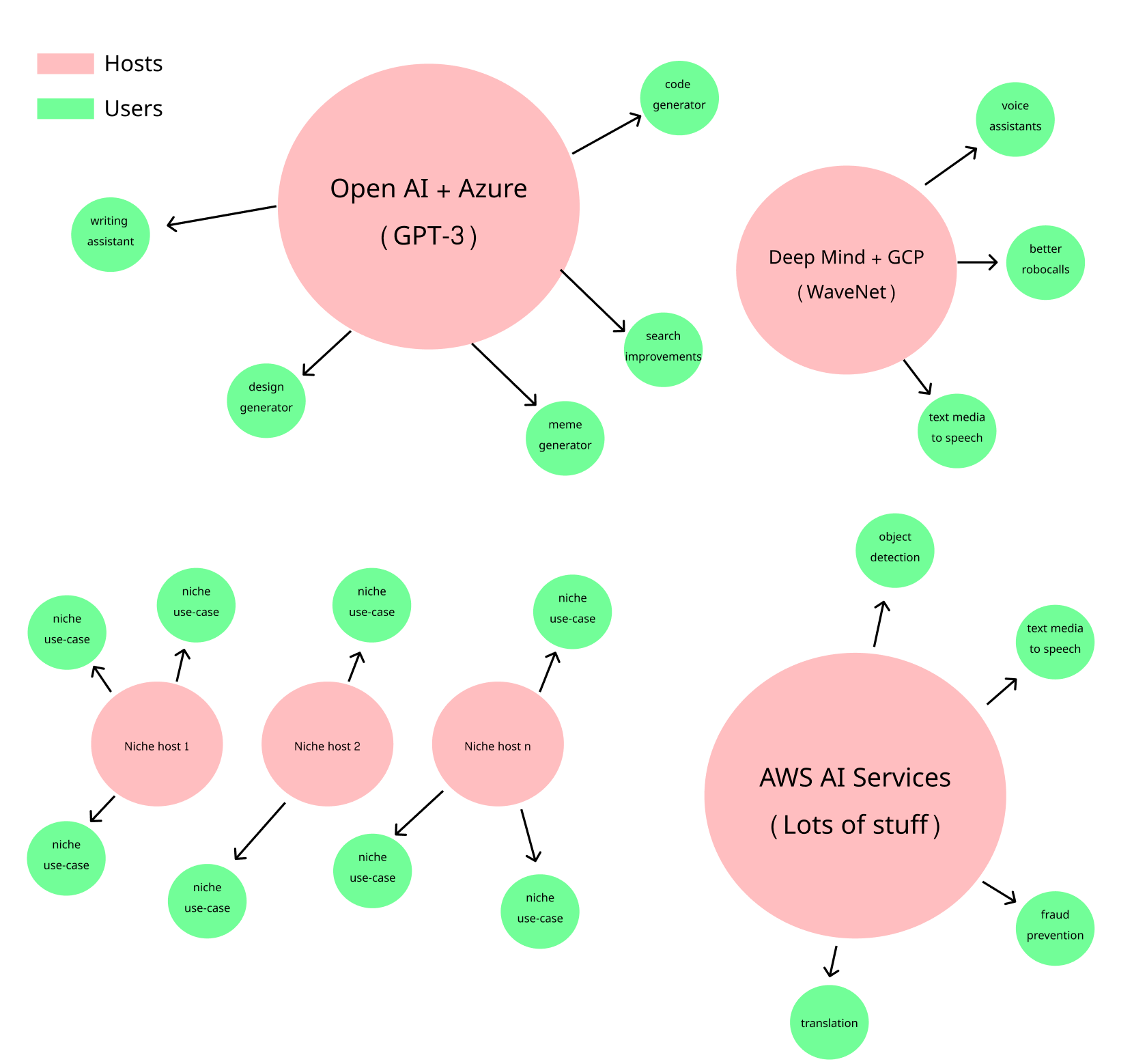
GPT-3 is a great example of where this trend is likely headed. In just a few short weeks the Open AI API is already being accessed by dozens of great use-cases.
GPT-3是这种趋势可能走向的一个很好的例子。 在短短的几周内,数十种出色的用例就已经可以访问Open AI API。
And across the ecosystem we’re seeing similar efforts. This model for development isn’t limited to NLP. Over in vision, a handful of autonomous driving startups with a focus on the software/hardware will likely enable the incumbents who don’t wish to do their own R&D to keep up with those who do. The general enablement of a company to tap into these massive efforts without having to perform R&D is a major win. Expect to see all sorts of models offered as a service. The large-scale models will fuel the bulk of innovation, and smaller and smaller pieces of the pie will get cut out by more niche players. As models get better and better at generalizing, expect less reliance on custom modeling efforts. And those business-specific use-cases aren’t in optimizing models as much as gathering specialized application-specific datasets. Data rules everything around me.
在整个生态系统中,我们看到了类似的努力。 这种开发模型不仅限于NLP。 从远景来看,少数专注于软件/硬件的自动驾驶初创公司将可能使不希望自己进行研发的现有公司跟上那些这样做的公司。 使公司无需进行研发即可投入大量精力的总体能力是一项重大胜利。 期望看到作为服务提供的各种模型。 大型模型将推动大量创新,而越来越少的细分市场将淘汰越来越小的一块蛋糕。 随着模型在通用化方面越来越好,期望减少对自定义建模工作的依赖。 而且那些特定于业务的用例并没有像收集特定于应用程序的专用数据集那样在优化模型上进行优化。 数据支配着我周围的一切。
在(旧式)公司中的部署 (Deployment at (legacy) corporations)
Many walled gardens will be opposed to lack of security guarantees presented by semi-private APIs. There’s a massive opportunity here for companies that can optimize large models, compress models, and make growing data lakes manageable. It’s hard to believe that legacy corporations will all demand on-premises deployment of the next-generation of 175 billion+ parameter models. But don’t put it past them.
许多围墙花园将反对缺乏半私有API所提供的安全保证。 对于可以优化大型模型,压缩模型并使不断增长的数据湖可管理的公司而言,这是一个巨大的机会。 很难相信,传统公司都将要求在内部部署下一代1750亿多个参数模型。 但是不要把它丢在他们后面。
Things start to get especially interesting when we introduce PII into the mix. Don’t be surprised by companies that laugh in your face at the mention of sending their data off their internal network to some new and trendy API. Companies that can compress models and get similar results from smaller models will remain relevant as long as compute and storage remains an expense. Cost of training and serving continues to get slashed, but deployment costs can still be pretty heavy. AI companies continue to have inferior margins to traditional SaaS companies, largely for this reason.
当我们将PII引入组合时,事情开始变得特别有趣。 当公司提到将其数据从内部网络发送到一些新的和流行的API时,您会为您大笑,不要感到惊讶。 可以压缩模型并从较小模型中获得相似结果的公司将保持相关性,只要计算和存储仍然是一项支出即可。 培训和服务成本继续大幅下降,但部署成本仍然可能很高。 正是由于这个原因,人工智能公司的利润率仍然低于传统的SaaS公司。
“Anecdotally, we have seen a surprisingly consistent pattern in the financial data of AI companies, with gross margins often in the 50–60% range — well below the 60–80%+ benchmark for comparable SaaS businesses.” — a16z
“有趣的是,我们发现人工智能公司的财务数据出现了令人惊讶的一致模式,毛利率通常在50-60%的范围内-远低于可比SaaS业务的60-80%以上的基准。” — a16z
不要小看小数据 (Don’t underestimate small data)
Big models with billions of parameters will continue to get tons of love. And massive datasets will continue to drive the hyped models. In the reality of industry, smaller models are essential in many use-cases. You’re presented with two core decisions when building in edge scenarios:
具有数十亿参数的大型模型将继续获得无数的爱。 大量的数据集将继续推动被炒作的模型。 在工业现实中,较小的模型在许多用例中都是必不可少的。 在边缘场景中进行构建时,您将获得两个核心决策:
- Smaller or compressed models (i.e. TensorFlow Lite) 较小或压缩的模型(即TensorFlow Lite)
- Remote connectivity to compute 远程连接以进行计算
We can deploy to edge devices using solutions like TensorFlow lite. And better hardware for edge and consumer devices is coming out of companies like Hailo, Kneron, and Perceive. The pace of innovation in hardware might outpace the need for small models.
我们可以使用TensorFlow lite之类的解决方案部署到边缘设备。 Hailo,Kneron和Perceive等公司也推出了用于边缘和消费设备的更好的硬件。 硬件创新的步伐可能会超过对小型模型的需求。
When remote connectivity is an option, we can always consider performing compute off-chip, though there are plenty of blockers and common constraints like connectivity concerns and time to compute. In environments like manufacturing this may be preferable as connectivity may have higher guarantees due to the stationary nature of the process. We’re already seeing 5G factories pop up where remote control systems are getting installed. Wireless sensors communicate back to the control system wirelessly. It stands to reason remote inference will be part of this transition. There are also plenty of use-cases where we can submit our data, complete some other task, and use our results downstream. Think of manufacturing where you might take a picture of a product upstream, perform transformations, and then downstream match the quality check to the product. This obviously isn’t an option in real-time scenarios like autonomous driving.
当选择远程连接时,尽管存在很多障碍和常见限制,例如连接问题和计算时间,但我们始终可以考虑在芯片外执行计算。 在像制造这样的环境中,这可能是可取的,因为由于过程的固定性,连接性可能会得到更高的保证。 我们已经看到5G工厂如雨后春笋般出现在安装远程控制系统的地方。 无线传感器以无线方式与控制系统通讯。 可以推断,远程推理将成为此过渡的一部分。 在许多用例中,我们可以提交数据,完成其他任务并在下游使用我们的结果。 想想制造,您可以在上游拍摄产品图片,执行转换,然后在下游将质量检查与产品进行匹配。 在自动驾驶等实时场景中,这显然不是一个选择。
Small data is also incredibly attractive. To perform a successful Proof of Concept we may be tolerant of a liberal amount of Type 1 Errors, depending on the industry and use-case. Sensors can also oftentimes be invasive and the less time we need to gather the data the better. An example of a company with this stuff in mind is Instrumental, looking to solve manufacturing quality problems with minimal examples.
小数据也极具吸引力。 为了成功执行概念验证,我们可能会容忍大量的Type 1错误,具体取决于行业和用例。 传感器通常也可能具有侵入性,而我们收集数据所需的时间越短越好。 考虑到这些东西的公司的一个示例是Instrumental,它希望通过最少的示例来解决制造质量问题。
Don’t underestimate small data!
不要小看小数据!
获得资金 (Access to capital)
Risk capital, particularly VCs remain a primary gatekeeper to the future of innovation. And thankfully the tap is wide open on funding AI businesses. Tangentially, enterprise data businesses are also getting healthy rounds, measured by both size of rounds and pure volume of rounds.
风险资本,尤其是风险资本仍然是创新未来的主要守门人。 值得庆幸的是 ,此举可以为AI业务提供资金。 切线地,企业数据业务也获得了健康的回合,无论是回合的大小还是纯粹的回合数量。
For the common builder, bootstrapping a Machine Learning business continues to become easier and easier. A rough landing page, access to GPT-3 (or any other pre-trained model), a few cloud compute credits, and a clever tweet or two will get you everything you need to build and test your proof of concept.
对于普通的构建者来说,引导机器学习业务变得越来越容易。 粗略的登录页面,对GPT-3(或任何其他预训练模型)的访问,一些云计算学分以及一两个巧妙的推文将为您提供构建和测试概念证明所需的一切。
All that said, any halfway decent PoC will quickly enable access to VC money, so most will quickly forfeit their ambitions of bootstrapping to profitability. And for good reason. Rounds are closing quicker, an increasing number of active angels and micro funds is enabling faster movement in pre-seed and seed rounds.
话虽如此,任何半途而废的PoC都将Swift使人们获得VC资金,因此大多数人将很快丧失其追求利润的野心。 并且有充分的理由。 回合收盘更快,活跃天使基金的数量越来越多,微型基金使预种子和种子回合的移动速度更快。
Corporate VCs (Google Ventures, Salesforce Ventures, Samsung Ventures, Intel Capital, etc.) are also especially active in Applied AI and general Data Science businesses. And it makes sense. Developing this stuff in-house is hard. Corporate VCs can help the mothership find synergies with the AI startups they invest in. And some executives still view AI as a risky bet and not worth building an organization around. If they change their mind, these investments in AI startups present both a potential way to onboard new technologies they’re missing out on, but also as a healthy source of talent in an industry where talent acquisition isn’t always the easiest. Check the recent investments of a Corporate VC like Intel Capital and you’ll see AI and general enterprise data companies up and down their deal flow.
企业VC(Google Ventures,Salesforce Ventures,Samsung Ventures,Intel Capital等)也特别活跃于Applied AI和通用Data Science业务。 这是有道理的。 内部开发这些东西很困难。 企业风投可以帮助母公司找到与其投资的AI初创公司的协同效应。一些高管仍然将AI视为冒险的赌注,不值得建立一个组织。 如果他们改变主意,那么对AI初创公司的这些投资不仅可以成为采用他们所缺少的新技术的潜在方式,而且还可以作为人才获取并非总是最容易的行业的健康人才来源。 查看英特尔风险投资公司(Intel Capital)等企业VC的最新投资, 您会看到AI和一般企业数据公司的交易量上下波动。
跨技术的机会 (Opportunities across technologies)
Advances in vision enabled the self-driving revolution, manufacturing breakthroughs, and much more. Advances in NLP have improved search, translation, knowledge understanding, and more. And we’ve only recently started to realize the possibilities of Reinforcement Learning, the potential of GANs, and much more.
视觉的进步实现了自动驾驶革命,制造突破等。 NLP的进步已经改善了搜索,翻译,知识理解等等。 而且,我们直到最近才开始意识到强化学习的可能性,GAN的潜力等等。
Let’s explore some of the opportunities in a technology-specific approach. Afterwards, we will explore opportunities in an industry-specific approach. It’s interesting to observe the choices startups may make to create a broad technical solution vs taking their technical solution to a specific industry.
让我们探索特定于技术的方法中的一些机会。 之后,我们将以特定于行业的方式探索机会。 有趣的是,观察初创公司为创建广泛的技术解决方案而做出的选择,而不是将其技术解决方案带入特定行业。
These are by no means exhaustive lists or even scratch the surface. They should, however, serve as inspiration and give you a high level view of the landscape. We intentionally skip RNNs, autoencoders, and certain other models for brevity’s sake.
这些绝不是详尽的清单,甚至都不是表面。 但是,它们应作为灵感,并为您提供景观的高层次视图。 为了简洁起见,我们特意跳过了RNN,自动编码器和某些其他模型。
计算机视觉(CV) (Computer Vision (CV))
Key Technologies & Buzzwords: Convolutional Neural Networks, Dropout, Object Detection (classification + location)
关键技术和流行语:卷积神经网络,辍学,对象检测(分类+位置)
Frontier Uses: Classification, Scene Understanding, Tracking, Motion, Estimation, Reconstruction
前沿用途:分类,场景理解, 跟踪,运动,估计,重建
Dominant Industries: Automotive, Medicine, Military, Photography
主导产业:汽车,医药,军事,摄影
Sample Companies: Cruise, Cognex
样本公司: Cruise, 康耐视
自然语言处理(NLP) (Natural Language Processing (NLP))
Key Technologies & Buzzwords: GPT, BERT, DistilBERT, XLNet, RoBERTa, Transformer-XL
关键技术和流行词: GPT,BERT,DistilBERT,XLNet,RoBERTa,Transformer-XL
Frontier Uses: Speech Recognition, Text Generation, Language Understanding, Translation, Question Answering
前沿用途:语音识别,文本生成,语言理解,翻译,问题解答
Dominant Industries: Hard to imagine industries where NLP can’t play a role of some kind. (Though I’m not an NLP maximalist!)
主导产业:很难想象NLP无法发挥某种作用的产业。 (尽管我不是NLP的最高主义者!)
Sample Companies: Open AI, HuggingFace
样本公司:开放式AI,HuggingFace
强化学习(RL) (Reinforcement Learning (RL))
Key Technologies & Buzzwords: Markov Decision Processes, Temporal Difference Learning, Monte Carlo, Deep RL, Q-Learning
关键技术和流行语:马尔可夫决策过程, 时间差异学习,蒙特卡洛,深度学习, Q学习
Frontier Uses: Games, Markets, Controls, Scheduling
前沿用途:游戏,市场,控制,调度
Dominant Industries (relatively unused): Robotics, Markets & Economics, Industrial Automation (primary use-case for robotics)
主导产业(相对未使用):机器人技术,市场与经济学,工业自动化(机器人技术的主要用例)
Sample Companies: DeepMind, Open AI, Covariant
样本公司: DeepMind,Open AI,协变
生成网络 (Generative Networks)
Key Technologies & Buzzwords: Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), CycleGAN, DCGAN, cGAN, StyleGAN, Generator, Discriminator, Game Theory
关键技术和流行词:变分自动编码器(VAE),生成对抗网络(GAN),CycleGAN,DCGAN,cGAN,StyleGAN,生成器,鉴别器,博弈论
Frontier Uses: Photo generation, deepfakes, super resolution, image-to-image translation
前沿用途:照片生成,深度伪造,超分辨率,图像到图像翻译
Dominant Industries: Creative & media, modeling, photography, video
主导产业:创意与媒体,建模,摄影,视频
Sample Companies: RunwayML, Rosebud.ai, Generative.photos
样本公司: RunwayML,Rosebud.ai,Generative.photos
跨行业的机会 (Opportunities across industries)
Every industry stands to gain from Applied ML. Finance has largely tackled issues of fraud, manufacturing has solved some of the looming questions in automation that traditional controls couldn’t solve, e-commerce continues to evolve from recommendation systems. All fields are ripe for disruption. Here are some interesting use-cases and companies in sample industries.
每个行业都将从Applied ML中受益。 财务在很大程度上解决了欺诈问题,制造业已经解决了传统控件无法解决的一些迫在眉睫的自动化问题,电子商务继续从推荐系统发展而来。 所有领域都已经成熟,可以被破坏了。 以下是示例行业中一些有趣的用例和公司。
制造业 (Manufacturing)
Key Technologies: Computer Vision, Reinforcement Learning, Process Optimization
关键技术:计算机视觉,强化学习,过程优化
Use-Cases: Quality Assurance, Industrial Automation, Process Improvement, Predictive Maintenance
用例:质量保证,工业自动化,过程改进,预测性维护
Sample Companies: Covariant, Instrumental, FogHorn Systems (additionally the incumbents like Siemens and Rockwell, Cognex, and others are actively investing in and performing their own R&D to play defense)
样本公司:协变量,工具,FogHorn系统(此外,西门子和罗克韦尔,康耐视等现有公司正在积极投资并进行自己的研发以发挥防御作用)
商业 (Commerce)
Key Technologies: Recommendation Systems, Fraud Detection, Order Matching, Personalization
关键技术:推荐系统,欺诈检测,订单匹配,个性化
Use-Cases: Quality Assurance, Industrial Automation, Process Improvement
用例:质量保证,工业自动化,过程改进
Sample Companies: Amazon’s recommendation kingdom is the most obvious sample, massive live marketplaces like Uber optimize live matching with dynamic pricing and routing, payment processors like Stripe and Square rely on Fraud Detection
样本公司:亚马逊的推荐王国是最明显的样本,像Uber这样的大型实时市场通过动态定价和路由来优化实时匹配,Stripe和Square等支付处理器依赖欺诈检测
药物 (Medicine)
Key Technologies: Computer Vision, Sequencing, RNNs & LSTMs, Reinforcement Learning
关键技术:计算机视觉,排序,RNN和LSTM,强化学习
Use-Cases: Classification of X-Rays and other imaging, Drug Discovery, Genomics, Mapping the Brain (and much more!)
用例: X射线和其他成像的分类,药物发现,基因组学,绘制大脑图(还有更多!)
Sample Companies: Insitro, Sophia Genetics, Flatiron Health, Allen Institute (non-profit),
样本公司: Insitro, 索菲亚遗传学, 艾伦研究所(非营利组织)熨斗健康部
自动驾驶 (Autonomous Driving)
Key Technologies: Computer Vision, Object Detection, Semantic Segmentation/Scene Understanding
关键技术:计算机视觉,目标检测,语义分割/场景理解
Use-Cases: Autonomous Driving
用例:自动驾驶
Sample Companies: Tesla, Waymo, Cruise, and many others
样本公司: Tesla,Waymo,Cruise等
施工 (Construction)
Key Technologies: Computer Vision
关键技术:计算机视觉
Use-Cases: Safety, Mapping, Visualizing, Autonomy in Machinery
用例:安全,制图,可视化,机械自主
Sample Companies: Intsite, Kwant, Buildot
样本公司: Intsite,Kwant, Buildot
创意与媒体 (Creative & Media)
Key Technologies: NLP, GANs, Computer Vision
关键技术: NLP, GAN,计算机视觉
Use-Cases: Text Generation, Video Generation, Song and Story Writing, Assistants, Speech Generation, Modeling, Deepfakes
用例:文本生成,视频生成,歌曲和故事写作,助手,语音生成,建模,Deepfakes
Sample Companies: RunwayML, Rosebud, Persado
样本公司: RunwayML,Rosebud,Persado
军事与国家监视 (Military & State Surveillance)
Key Technologies: Let’s not encourage an AI arms race.
关键技术:不要鼓励AI军备竞赛。
Use-Cases: Let’s not encourage an AI arms race.
用例:不要鼓励AI军备竞赛。
Sample Companies: Let’s not encourage an AI arms race.
样本公司:我们不要鼓励AI军备竞赛。
能源 (Energy)
Key Technologies: Computer Vision, Reinforcement Learning, Process Optimization
关键技术:计算机视觉,强化学习,过程优化
Use-Cases: Predictive Maintenance, Optimizing the Grid
用例:预测性维护,优化网格
Sample Companies: Stem, Origami, Infinite Uptime
样本公司: Stem,Origami,无限正常运行时间
金融 (Finance)
Key Technologies: NLP, Anomaly Detection, Traditional ML
关键技术:自然语言处理,异常检测,传统机器学习
Use-Cases: Automated Banking Experiences, Fraud Detection, Personalization, Risk Management, Wealth Management, Trading
用例:自动银行体验,欺诈检测,个性化,风险管理,财富管理,交易
Sample Companies: Ravelin, Tala, Verifi, Suplari, every major bank and their service providers, Quantopian
样本公司: Ravelin,Tala,Verifi,Suplari,各大银行及其服务提供商,Quantopian
翻译自: https://towardsdatascience.com/the-state-of-applied-ai-41393faad013
人工智能的应用现状


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









