





ai人工智能面相测试
One of the long-standing goals of artificial intelligence is to develop machines with abstract reasoning capabilities equal to or better than humans. Though there has also been substantial progress in both reasoning and learning in neural networks, the extent to which these models exhibit anything like general abstract reasoning is the subject of much debate.
人工智能的长期目标之一是开发具有等于或优于人类的抽象推理能力的机器。 尽管在神经网络的推理和学习方面也取得了长足的进步,但这些模型在多大程度上表现出类似于一般抽象推理的能力仍是许多争论的主题。
Neural networks have perfected the technique to identify cats in images and translating from one language to another. Is that intelligence or they are just great at memorizing? How can we measure the intelligence of neural networks?
神经网络完善了识别图像中猫并从一种语言翻译成另一种语言的技术。 那是智慧还是他们擅长记忆? 我们如何测量神经网络的智能?
Some researchers have been developing ways to evaluate neural networks’ intelligence. It’s not using mean squared error or entropy loss. But they are giving neural networks an IQ test, high school mathematics questions, and comprehension problems.
一些研究人员一直在开发评估神经网络智能的方法。 它没有使用均方误差或熵损失。 但是他们给神经网络一个智商测试,高中数学问题和理解问题。
模式匹配 (Pattern Matching)
A human’s capacity for abstract reasoning can be estimated using a visual IQ test developed by psychologist John Raven in 1936: the Raven’s Progressive Matrices (RPMs). The premise behind RPMs is simple: one must reason about the relationships between perceptually obvious visual features, such as shape positions or line colors, and choose an image that completes the matrix.
可以使用心理学家约翰·拉文(John Raven)在1936年开发的视觉智商测验( Raven's Progressive Matrices ,RPM)来估计人的抽象推理能力。 RPM的前提很简单:必须推理出视觉上明显的视觉特征(例如形状位置或线条颜色)之间的关系,并选择可以完成矩阵的图像。

Since one of the goals of AI is to develop machines with similar abstract reasoning capabilities to humans, researchers at Deepmind proposed an IQ test for AI, designed to probe their abstract visual reasoning ability. In order to succeed in this challenge, models must be able to generalize well for every question.
由于AI的目标之一是开发具有与人类相似的抽象推理能力的机器,因此Deepmind的研究人员提出了一种AI智商测试,旨在探究他们的抽象视觉推理能力。 为了成功应对这一挑战,模型必须能够很好地概括每个问题。

In this study, they compared the performance of several standard deep neural networks and proposed two models that include modules that specially designed for abstract reasoning:
在这项研究中 ,他们比较了几种标准深度神经网络的性能,并提出了两个模型,其中包括专门为抽象推理设计的模块:
- standard CNN-MLP: (four-layers convolutional neural network with batch normalization and ReLU) 标准CNN-MLP :(具有批处理归一化和ReLU的四层卷积神经网络)
ResNet-50: as described in He et al. (2016)
- LSTM: 4 layers CNN followed by LSTM LSTM:4层CNN,然后是LSTM
Wild Relation Network (WReN): answers are selected and evaluated using a Relation Network designed for relational reasoning
Wild Relation Network(WReN):使用专为关系推理设计的Relation Network选择和评估答案
- Wild-ResNet: variant of the ResNet that is designed to provide a score for each answer Wild-ResNet:ResNet的变体,旨在为每个答案提供分数
Context-Blind ResNet: ResNet-50 model with eight multiple-choice panels as input without considering the context
上下文盲ResNet:具有八个选择面板的输入的ResNet-50模型, 无需考虑上下文
The IQ test questions aren’t challenging enough; so they added various shapes, lines of varying thickness, and colors, as distractions.
智商测试的问题还不够挑战。 因此他们添加了各种形状,粗细不同的线条和颜色,以分散注意力。

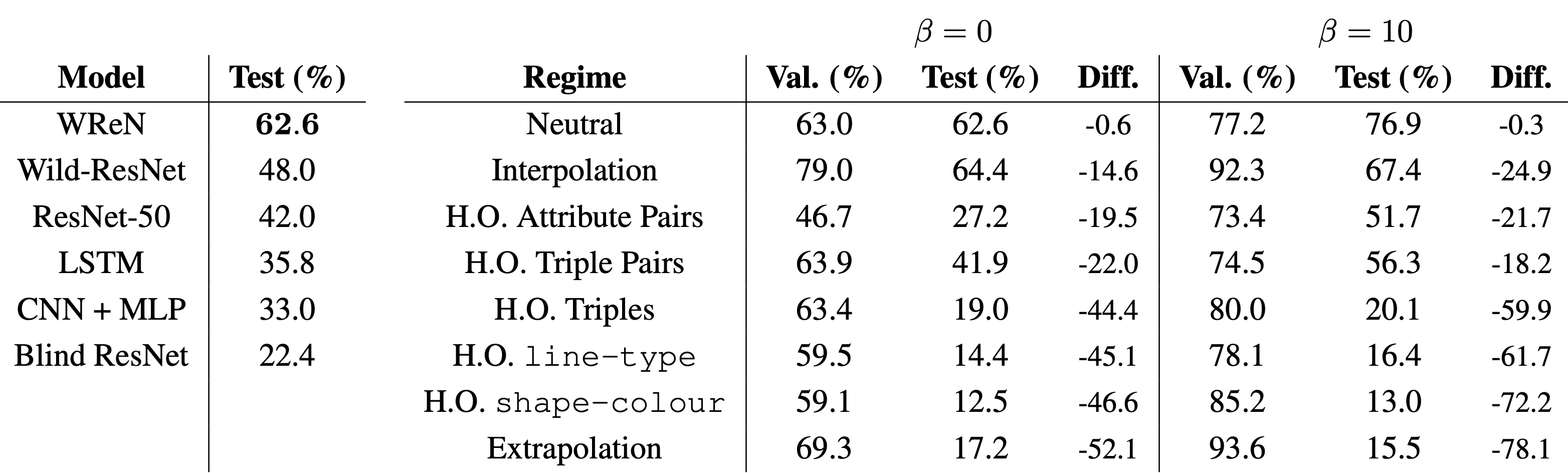
The best performing model is the WReN model! This is due to the Relation Network module designed explicitly for reasoning about the relations between objects. After removing distractions, the WReN model performed notably better at 78.3%, compared with 62.6% with distractions!
表现最好的模型是WReN模型! 这是由于“关系网络”模块明确设计用于推理对象之间的关系。 消除干扰后,WReN模型的表现明显更好,为78.3%,相比之下,干扰为62.6%!
数学推理 (Mathematical Reasoning)
Mathematical reasoning is one of the core abilities of human intelligence. Mathematics presents some unique challenges as humans do not primarily understand and solve mathematical problems based on experiences. Mathematical reasoning is also based on the ability to infer, learn, and follow symbol manipulation rules.
数学推理是人类智力的核心能力之一。 由于人类并不首先根据经验来理解和解决数学问题,因此数学提出了一些独特的挑战。 数学推理也基于推理,学习和遵循符号操作规则的能力。
Researchers are Deepmind released a dataset consisting of 2 million mathematics questions. These questions are designed for neural networks for measuring mathematical reasoning. Each question is limited to 160 characters in length, and answers to 30 characters. The topics include:
Deepmind研究人员发布了一个包含200万个数学问题的数据集 。 这些问题是为测量数学推理的神经网络设计的。 每个问题的长度限制为160个字符,最多可以回答30个字符。 主题包括:
- algebra (linear equations, polynomial roots, sequences) 代数(线性方程,多项式根,序列)
- arithmetic (pairwise operations and mixed expressions, surds) 算术(成对运算和混合表达式,surds)
- calculus (differentiation) 微积分(微分)
- comparison (closest numbers, pairwise comparisons, sorting) 比较(最接近的数字,成对比较,排序)
- measurement (conversion, working with time) 测量(转换,需要时间)
- numbers (base conversion, remainders, common divisors and multiples, primality, place value, rounding numbers) 数字(基数转换,余数,公因数和倍数,素数,位值,舍入数)
- polynomials (addition, simplification, composition, evaluating, expansion) 多项式(加法,简化,合成,求值,扩展)
- probability (sampling without replacement) 概率(不更换样本)

The dataset comes with two sets of tests:
数据集包含两组测试:
interpolation (normal difficulty): a diverse set of question types
插值( 普通难度 ):各种各样的问题类型
extrapolation (crazy mode): difficulty beyond those seen during training dataset, with problems involving larger numbers, more numbers, more compositions, and larger samplers
外推法( 疯狂模式 ):难度超出训练数据集期间遇到的困难,问题涉及更大的数字,更多的数字,更多的成分和更大的采样器
In their study, they investigated a simple LSTM model, Attentional LSTM, and Transformer. Attentional LSTM and Transformer architectures parse the question with an encoder and the decoder will produce the predicted answers one character at a time.
在他们的研究中 ,他们研究了一个简单的LSTM模型,Attentional LSTM和Transformer 。 注意LSTM和Transformer架构使用编码器解析问题,解码器将一次生成一个字符的预测答案。
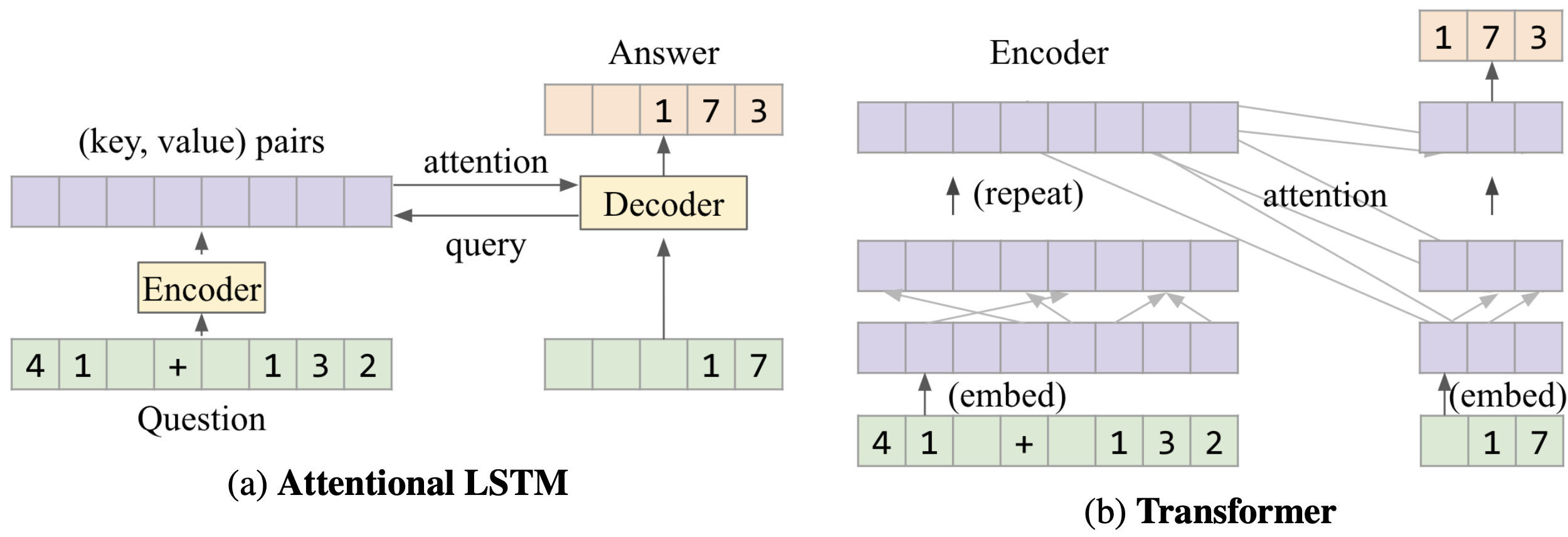
They also replaced LSTM with relational memory core, which consists of multiple memory slots that interact via attention. In theory, these memory slots seem useful for mathematical reasoning as models can learn to use the slots to store mathematical entities.
他们还将LSTM替换为关系内存核心 ,该核心内存由多个内存插槽组成,这些内存插槽通过注意力进行交互。 从理论上讲,这些内存插槽对于数学推理而言似乎很有用,因为模型可以学习使用插槽来存储数学实体。
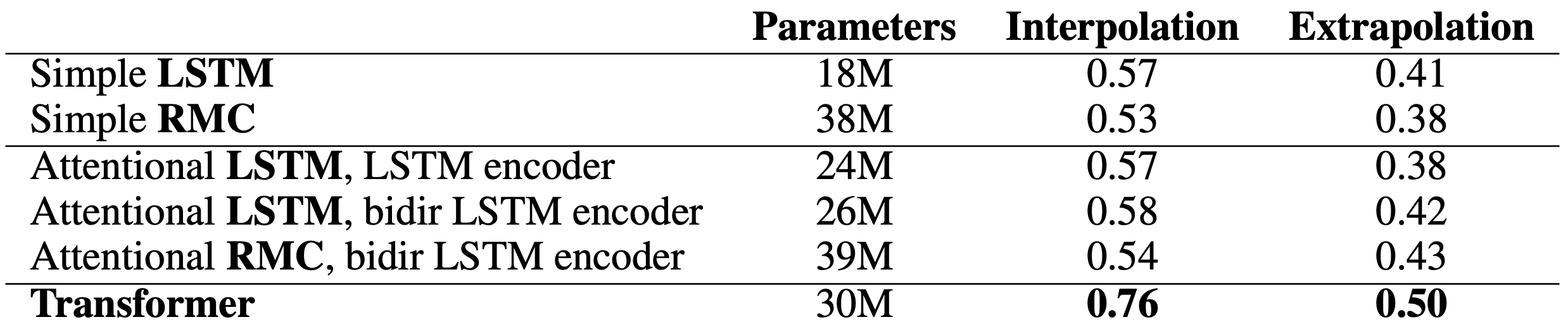
This is what they have found:
这是他们发现的:
- The relational memory core did not help in performance. They reasoned that perhaps it is challenging to learn to use slots for manipulating mathematical entities. 关系内存核心对性能没有帮助。 他们认为,学习使用插槽来操纵数学实体也许具有挑战性。
- Both simple LSTM and Attentional LSTM have similar performance. Perhaps the attention modules are not learning to parse the question algorithmically. 简单LSTM和注意力LSTM都具有相似的性能。 注意力模块也许没有学会通过算法解析问题。
- The Transformer outperforms other models as perhaps more similar to sequential reasoning of how a human solve mathematical problems. Transformer的表现优于其他模型,这可能与人类如何解决数学问题的顺序推理更相似。
语言理解 (Language Understanding)
In recent years, there has been notable progress across many natural language processing methods, such as ELMo, OpenAI GPT, and BERT.
近年来,许多自然语言处理方法(例如ELMo , OpenAI GPT和BERT)取得了显着进步。
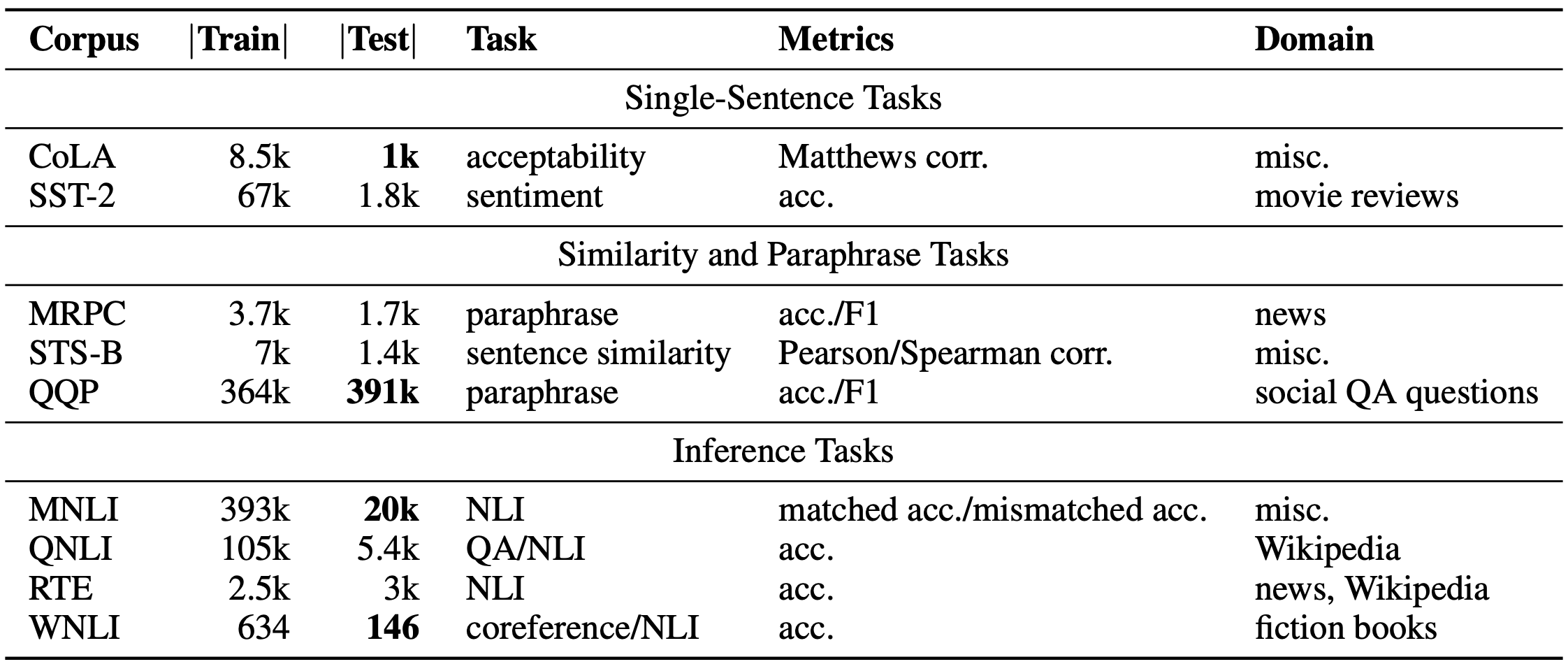
Researchers introduced the General Language Understanding Evaluation (GLUE) benchmark in 2019, designed to evaluate the performance of models across a nine English sentence understanding tasks, such as question answering, sentiment analysis, and textual entailment. These questions cover a broad range of domains (genres) and difficulties.
研究人员于2019年推出了通用语言理解评估(GLUE)基准,旨在评估九个英语句子理解任务(例如问题回答,情感分析和文本蕴涵)中模型的性能。 这些问题涵盖了广泛的领域(类型)和困难。
With human performance at 1.0, these are the GLUE score for each language model. Within the same year that GLUE was introduced, researchers have developed methods that surpass human performance. It seems like GLUE is too easy for neural networks; thus, this benchmark is no longer suitable.
在人类绩效为1.0的情况下,这些是每种语言模型的GLUE得分。 在引入GLUE的同一年,研究人员开发了超越人类性能的方法。 对于神经网络来说,GLUE似乎太容易了。 因此,该基准不再适合。

SuperGLUE was introduced as a new benchmark designed to pose a more rigorous test of language understanding. The motivation of SuperGLUE is the same as GLUE, to provide a hard-to-game measure of progress toward general-purpose language understanding technologies for the English language.
SuperGLUE是作为新基准引入的,旨在对语言理解进行更严格的测试。 SuperGLUE的动机与GLUE相同,目的是为通向英语通用语言理解技术的发展提供难以衡量的指标。

Researchers have evaluated the BERT-based models and find that they still lag behind humans by nearly 20 points. Given the difficulty of SuperGLUE, further progress in multi-task, transfer, and unsupervised/self-supervised learning techniques will be necessary to approach human-level performance on the benchmark.
研究人员评估了基于BERT的模型,发现它们仍然落后于人类近20点。 鉴于SuperGLUE的困难性,在基准上接近人类水平的表现时,在多任务,传输和无监督/自我监督学习技术方面的进一步进步将是必要的。
Let us see how long it takes before machine learning models surpass human capability again, such that new tests have to be developed.
让我们看看机器学习模型再次超过人类能力需要多长时间,因此必须开发新的测试。



ai人工智能面相测试


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









