





最长重复子串 java
Do you like the picture? Is the color pretty? Now take a deep look.
你喜欢那张照片吗? 颜色漂亮吗? 现在深入了解。
What do you see?
你看到了什么?
Two lists of integers.
两个整数列表。
So today we are going to talk about an algorithm involving two lists of integers and a very clever and widely applicable dynamic programming technique.
因此,今天我们要讨论一种涉及两个整数列表的算法,以及一种非常聪明且广泛适用的动态编程技术。
What we are going to do is try to find the longest duplicated substring within the two given strings. In the above picture, it’s easy to see that the longest duplicated string is [1, 2, 3], and the length is 3. (The deep look helped!)
我们要做的是尝试在两个给定的字符串中找到最长的重复子字符串。 在上面的图片中,很容易看到最长的重复字符串是[1、2、3],长度是3。(深深的外观很有帮助!)
如何计算最长的重复字符串? (How do we go about counting the longest duplicate string?)
Well, a naive approach would be looping through every position in list 1 (ls1), and for each position, i, in list 1, loop through every position, j, in list 2, and for each (i, j), count the longest duplicate string at that position:
好吧,一个幼稚的方法将循环遍历列表1(ls1)中的每个位置,对于每个位置i,在列表1中,循环遍历列表2中的每个位置j,对于每个(i,j),计数在该位置的最长重复字符串:

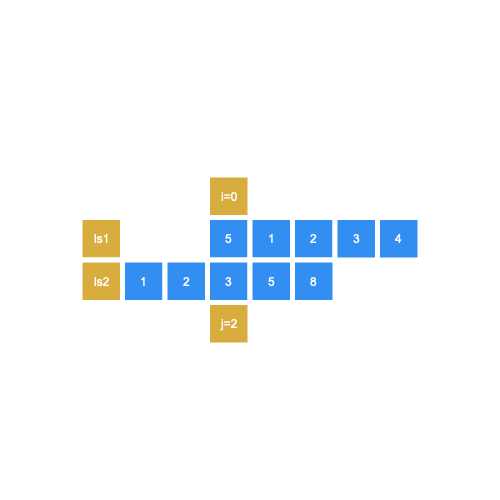
Eventually, you’ll reach:
最终,您将达到:
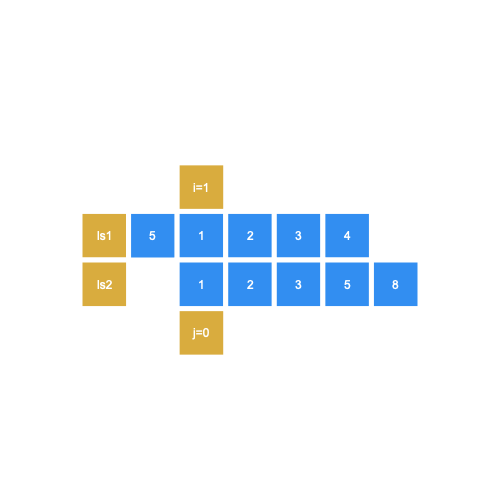
At this position, you’ll find the longest duplicate substring [1, 2, 3], and return the length, 3.
在此位置,您将找到最长的重复子字符串[1、2、3],并返回长度3。
Below is an implementation of this:
下面是此实现:
def longest_duplicate(a, b):
# count the duplicate string length
# with start position = (i0, j0)
def count_duplicate(i0, j0):
i = i0
j = j0
count = 0
while i < len(a) and j < len(b) and a[i] == b[j] :
count = count + 1
i = i + 1
j = j + 1
return count
# loop through every start position combination
max_count = 0
for i in range(len(a)):
for j in range(len(b)):
max_count = max(max_count,
count_duplicate(i, j))
return max_counta = [5, 1, 2, 3, 4]
b = [1, 2, 3, 5, 8]
>>> print(longest_duplicate(a, b))
3Now this is simple enough, but is it fast enough?
现在这很简单,但是足够快吗?
Think about it, you are looping through the arrays in a nested loop, if size of list 1 is n and size of list 2 is m, the complexity is around O(n * m), within it, you are doing a duplicate_count, which theoretically can be the entire length of one of the strings, so the total complexity is O(n * m * min(n, m)).
想想看,您正在嵌套循环中遍历数组,如果列表1的大小为n而列表2的大小为m,则复杂度约为O(n * m),在其中,您正在执行重复计数,从理论上讲,它可以是字符串之一的整个长度,因此总复杂度为O(n * m * min(n,m))。
if n = m, that’s O(n³)!
如果n = m,则为O(n³)!
That’s too slow…
太慢了...
Fortunately there is a way to speed it up, and it comes from a very clever observation:
幸运的是,有一种加速它的方法,它来自一个非常聪明的观察:
Take a deep, deep, look at this picture again, but this time think, do I really need to count from 1 to 2, and 2 to 3, in order to figure out the duplicate substring length is 3?
深入了解,再次看一下这张图片,但是这次想想,我真的需要从1到2,再从2到3计数,以便找出重复的子字符串长度是3吗?
What information would I need to figure out the duplicate string length at (1, 0), so that I don’t have to do comparison of each element in the string?
我需要什么信息来找出(1,0)处重复的字符串长度,这样就不必对字符串中的每个元素进行比较了?
Well, I can think of one, if I know the length of duplicates at position (2, 1), which is 2, then since position (1, 0) has starting values that are equal (1 equals 1):
好吧,我可以想到一个,如果我知道位置(2,1)的重复项的长度为2,那么由于位置(1,0)的起始值相等(1等于1):
duplicate_length_of_(1, 0) = 1 + duplicate_length_of_(2, 1)
duplicate_length_of_(1, 0) = 1 + duplicate_length_of_(2, 1)
Now this is a very important revelation, because in our algorithm, we loop through every combination of (i, j), so at some point we’ll encounter (2, 1), if we have some way of saving down the result at (2, 1), we don’t have to count again at (1, 0)!
现在这是一个非常重要的启示,因为在我们的算法中,我们遍历(i,j)的每个组合,因此,如果我们有某种方法可以节省结果,则有时会遇到(2,1)。 (2,1),我们不必再从(1,0)开始计数!
So let’s add a map to save down results so we don’t count the same positions over and over:
因此,让我们添加一张地图来保存结果,以免重复计算相同的位置:
def longest_duplicate(a, b):
# map to store calculated duplicate counts
duplicate_map = [[-1 for j in range(len(b))]
for i in range(len(a))]
def count_duplicate(i0, j0):
if i0 >= len(a) or j0 >= len(b):
return 0
if duplicate_map[i0][j0] >= 0:
return duplicate_map[i0][j0]
if a[i0] != b[j0]:
duplicate_map[i0][j0] = 0
else:
duplicate_map[i0][j0] = \
1 + count_duplicate(i0 + 1, j0 + 1)
return duplicate_map[i0][j0]
# loop through every start position combination
max_count = 0
for i in range(len(a)):
for j in range(len(b)):
max_count = max(max_count,
count_duplicate(i, j))
return max_count
a = [5, 1, 2, 3, 4]
b = [1, 2, 3, 5, 8]
>>> print(longest_duplicate(a, b))
3In this new version of the algorithm, we have added a map to store the intermediate results, duplicate_map, which is a matrix of dimension n*m, initialized at -1.
在此算法的新版本中,我们添加了一个映射以存储中间结果,即“重复映射”,它是维度n * m的矩阵,初始化为-1。
Each time we need to find the duplicate substring length at a position (i, j), we recursively find the duplicate substring length at position (i + 1, j +1), add 1 to it and store the result in the map for later use.
每次我们需要在位置(i,j)上找到重复的子串长度时,我们递归地在位置(i + 1,j +1)上找到重复的子串长度,将其加1并将结果存储在映射中以后使用。
Since we don’t actually ever count the length of duplicate substring anymore at each position, and the look up to the map is O(1), constant operation, the complexity now comes down to O(n * m).
由于实际上我们不再计算每个位置的重复子字符串的长度,并且查找映射为O(1),因此进行常量运算后,复杂度现在降至O(n * m)。
This technique of saving down intermediate results to speed up calculation is part of a general technique called dynamic programming, once you understand what it’s trying to do (saving down results of calculations that will later be reused), you’ll see it everywhere, database caching, people jogging down notes in a hurry, cheating on finals. It’s literally everywhere.
节省中间结果以加快计算速度的这项技术是称为动态编程的通用技术的一部分,一旦您了解了它的工作意图(节省了计算结果供以后重用),您将在数据库中随处可见缓存时,人们急着慢跑,在决赛中作弊。 它无处不在。
翻译自: https://medium.com/python-in-plain-english/longest-duplicate-substring-2f1959472e6d
最长重复子串 java















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









