





 本文介绍了Python的-v选项,它能提供运行时的详细信息,帮助开发者调试和理解Python解释器的工作方式。
本文介绍了Python的-v选项,它能提供运行时的详细信息,帮助开发者调试和理解Python解释器的工作方式。
python -v
This is part 5 of the series. To go back to part 1, click here.
这是本系列的第5部分。 要返回第1部分,请点击此处 。
This section aims to build on the foundations built in the course so far to create some small but helpful programs that show the power of Python. This is the beauty of Python and programming, in general; you can easily build on the work of people before you to create some truly amazing things.
本节的目的是在到目前为止的课程中建立基础,以创建一些小的但有用的程序,这些程序可以显示Python的功能。 总的来说,这就是Python和编程的美。 在创建一些真正令人惊奇的东西之前,您可以轻松地基于人们的工作。
All the code here is available in this Github Repository. Working with Github is outside of the scope of this tutorial but you can just download the zip file from the site. Some of the code here may seem complex at first, but I assure you it’s nothing to be afraid of. All of it was built line by line and seeing it all at once makes it look scarier than it is. Take it one line at a time, read the explanations following the code, and go back to the previous parts of the series if needed.
此处的所有代码均可在此Github存储库中找到 。 使用Github不在本教程的讨论范围内,但是您可以从站点下载zip文件。 首先,这里的某些代码可能看起来很复杂,但是我向您保证,不用担心。 所有这些都是逐行构建的,一次看到它会使它看起来比实际更可怕。 一次一行 , 阅读代码后的解释,然后返回本系列的前面部分 如果需要的话。
资金经理 (Money Manager)
There are a plethora of budget apps on Android and iOS built using Java and Swift. We’re going to build a simple budget app that we can tailor to our needs in the future.
Android和iOS上有大量使用Java和Swift构建的预算应用程序。 我们将构建一个简单的预算应用程序,将来可以根据需要进行调整。
Let’s try to plan out a solution. Remember that in all cases, it’s really helpful to understand the problem first. Thankfully, I’m your client and I can tell you exactly what I want.
让我们尝试制定解决方案。 请记住,在所有情况下,首先了解问题确实很有帮助。 值得庆幸的是,我是您的客户,我可以准确地告诉您我想要什么。
I want the program to:
我希望程序执行以下操作:
- Allow me to input a variable salary and variable expenses. 请允许我输入可变工资和可变费用。
- Deduct the expenses and add the salary to the budget. 扣除费用,然后将工资加到预算中。
- Let me view the updated budget. 让我查看更新后的预算。
- Save the budget for future use. 保存预算以备将来使用。
Try to implement your solution to this problem and show it to me in the comments!
尝试实施您对这个问题的解决方案,并在评论中向我展示!
资金管理 (Money Managed)
Before we begin, we need to install Pandas (bundled with Miniconda), a nifty data analysis library. We’re only going to be using it to store CSV files so it’s similar to using a gaming PC for browsing the internet. Open up Anaconda prompt or the terminal and type in conda install pandas and press enter. You might have to press Y on your keyboard to continue the installation.
在开始之前,我们需要安装Pandas(与Miniconda捆绑在一起),一个漂亮的数据分析库。 我们将仅使用它来存储CSV文件,因此它类似于使用游戏机浏览互联网。 打开Anaconda提示符或终端,然后键入conda install pandas ,然后按Enter。 您可能必须按键盘上的Y才能继续安装。
After you’re done installing, start VS Code and make a new file. Name it whatever you want and type the following blocks of code serially on the editor. Remember that, for you, the terminal will mainly be used to run your code not edit it.
安装完成后,启动VS Code并制作一个新文件。 随意命名,然后在编辑器上依次键入以下代码块。 请记住,对您而言, 终端将主要用于运行代码而不是对其进行编辑。
# Some Helpful Libraries
import pandas as pdNext, we need to see if we already have a stored budget file. If we don’t, we can create a new budget variable and then save it after we’re done.
接下来,我们需要查看是否已经存储了预算文件。 如果没有,我们可以创建一个新的预算变量,然后在完成后保存它。
# Try opening the csv file
try:
# if file found open the file and set the budget column to the
# budget variable
df = pd.read_csv("budget.csv", index_col=None)
budget = df.loc[0, "Budget"]
except FileNotFoundError:
# If file is not found, set budget to 0 and create a dataframe
# with our budget and savings
budget = 0
df = pd.DataFrame({"Budget": [0]})The try and except block is a way to find out if there are any errors in our code and do something if there is. The first (try) part tries something and if it runs into an error, it goes into the second (except) part. We can specify what type of error we want to catch in the except block by putting the name of the error beside it. I only know the name of the error because I tried running the code without the error catcher.
try和except块是一种找出我们的代码中是否有错误并进行一些处理的方法。 第一部分(尝试)尝试执行某些操作,如果遇到错误,则进入第二部分(除外)。 我们可以通过将错误名称放在错误块旁边来指定要在except块中捕获的错误类型。 我只知道错误的名称,因为我尝试在没有错误捕获器的情况下运行代码。
Inside the try block, we create a variable called df and store a dataframe object. This is a special object that Pandas provides us and it’s optimized for spreadsheets and tables. pd.read_csv()reads a CSV file and turns it into a dataframe. It also works with a multitude of other file types. We also specify that we don’t have an index column.
在try块内,我们创建一个名为df的变量并存储一个dataframe对象 。 这是熊猫提供给我们的特殊对象,并且已针对电子表格和表格进行了优化。 pd.read_csv()读取CSV文件并将其转换为数据框。 它还可以与多种其他文件类型一起使用。 我们还指定我们没有索引列。
We then look for the budget, contained in the 1st row (Pandas indexes start from 0 just like Python) and the column called “Budget” using the df.loc[row, column] method. This is similar to selecting an element from a list. Note that you can override the default index in Pandas and make your index using strings, numbers, etc. Then the row should refer to your newly made index. So, we type in df.loc[0, “budget”].
然后,我们使用df.loc[row, column]方法查找包含在第一行(与Python一样,Pandas索引从0开始)和“预算”列中包含的预算。 这类似于从列表中选择元素。 请注意,您可以覆盖Pandas中的默认索引,并使用字符串,数字等来创建索引。然后,该row应引用您新创建的索引。 因此,我们输入df.loc[0, “budget”] 。
If the file isn’t found, we just set our budget to 0 and create a new Pandas dataframe, which has only one column and one row, using the pd.DataFrame({key: [value, value2...], key2: [value3, value4...]...}) method. This is similar to the creation of a dictionary with the keys just being column names.
如果找不到该文件,则只需将预算设置为0,然后使用pd.DataFrame({key: [value, value2...], key2: [value3, value4...]...})方法。 这类似于使用键只是列名的字典的创建。
# Take user input and store it in an integer
user_intent = ""while user_intent != "quit": user_intent = str.lower(input('''What would you like to do
today?\n''')) if user_intent == "expense":
expense = int(input("How much did you spend?\n"))
budget -= expense
print(f"Expense of BDT {expense} deducted\n")
elif user_intent == "salary":
salary = int(input("How much did you get?\n"))
budget += salary
print(f"Salary payment of BDT {salary} added\n")
elif user_intent == "budget":
print(f"Your current budget is {budget}\n")
elif user_intent == "quit":
print("Quitting the application")
df.loc[0, "Budget"] = budget
df.to_csv("budget.csv", index=False)
else:
print("You typed something wrong.\n")This part seems complex at first, but breaking it down shows a pretty simple user input system. We first create an empty string and initialize a while loop. As long as the user doesn’t type “quit”, the while loop will keep going.
首先,这部分看起来很复杂,但将其分解显示出一个非常简单的用户输入系统。 我们首先创建一个空字符串并初始化while循环。 只要用户不输入“quit” ,while循环就会继续进行。
At the start of the loop, it’ll ask the user to input something. str.lower() turns the input into all lowercase. This is in case the user messes up and types any letter uppercase. \n in a string works similar to pressing enter in a document. This has the added annoyance that typing “\” doesn’t put a forward slash inside strings and you’ll need to type "\\" instead.
在循环开始时,它将要求用户输入一些内容。 str.lower()将输入变成小写。 这是在用户弄乱并键入任何大写字母的情况下。 字符串中的\n的作用类似于在文档中按Enter键。 这就增加了烦恼,即键入“\”不会在字符串中加上正斜杠,而您需要键入"\\" 。
If the input is “expense”, then we ask the user to input the expense amount and deduct the value from our budget. Note that we could return an error if the user types in anything that isn’t a number. Try implementing it yourself.
如果输入为“expense” ,则我们要求用户输入费用金额并从我们的预算中扣除该金额。 请注意,如果用户输入的不是数字,我们可能会返回错误。 尝试自己实施。
If the input is “salary”, then we ask the amount and add it to our budget.
如果输入是“salary” ,则我们要求该金额并将其添加到我们的预算中。
If the input is “budget”, then we show the current budget to the user.
如果输入为“budget” ,那么我们向用户显示当前预算。
If the input is “quit”, then we save our budget variable inside the dataframe and save it our computer (in the same directory as the Python script we’re running) using the dataframe.to_csv(name) method. We also tell Pandas to discard the index as it’s automatically created when the file is opened. Note that when we opened the dataframe, we called the read_csv method on Pandas itself: pd.read_csv(name) and on closing, we’re calling the method on the dataframe:df.to_csv(name). Typing in "quit" also stops the loop.
如果输入为“quit” ,那么我们将预算变量保存在数据框中,并使用dataframe.to_csv(name)方法将其保存在我们的计算机中(与我们正在运行的Python脚本位于同一目录中dataframe.to_csv(name) 。 我们还告诉Pandas放弃索引,因为打开文件时会自动创建该索引。 请注意,当打开数据框时,我们在Pandas本身上调用了read_csv方法: pd.read_csv(name) ,在关闭时,我们在数据df.to_csv(name)上调用了方法: df.to_csv(name) 。 输入"quit"也将停止循环。
If the input is anything else, then we return an error message.
如果输入是其他任何内容,那么我们将返回错误消息。
The full code is given below and also available on the aforementioned Github repo:
完整的代码在下面给出,也可以在前面提到的Github存储库中找到 :
# A helpful Libraries
import pandas as pd
# Try opening the csv file
try:
# if file found open the file and set the budget column to the budget variable
df = pd.read_csv("budget.csv", index_col=None)
budget = df.loc[0, "Budget"]
except FileNotFoundError:
# If file is not found, set budget to 0 and create a dataframe with our budget and savings
# Our budget variable
budget = 0
df = pd.DataFrame(
{"Budget": [0]})
# Take user input and store it in an integer
user_intent = ""
while user_intent != "quit":
user_intent = str.lower(input('''What would you like to do today?
You can type "help" to get commands\n'''))
if user_intent == "expense":
expense = int(input("How much did you spend?\n"))
budget -= expense
print(f"Expense of BDT {expense} deducted\n")
elif user_intent == "salary":
salary = int(input("How much did you get?\n"))
budget += salary
print(f"Salary payment of BDT {salary} added\n")
elif user_intent == "budget":
print(f"Your current budget is {budget}\n")
elif user_intent == "quit":
print("Quitting the application")
df.loc[0, "Budget"] = budget
df.to_csv("budget.csv", index=False)
else:
print("You typed something wrong.\n")资金管理得更好 (Money Managed Better)
To illustrate how easy it is to add to our program, I also decided to add a savings component, fixed salaries that are easy to input, a help system, and a reset system for a negative budget. Make sure to go through this step-by-step and try to figure out what each line of code does.
为了说明添加到我们的程序中有多么容易,我还决定添加一个储蓄部分,易于输入的固定薪水,帮助系统以及负预算的重置系统。 确保逐步完成此步骤,并尝试找出每一行代码的作用。
# A Helpful Libraries
import pandas as pd
# Try opening the csv file
try:
# if file found open the file and set the budget column to the budget variable
df = pd.read_csv("budget.csv", index_col=None)
budget = df.loc[0, "Budget"]
lifetime_savings = df.loc[0, "Lifetime_Savings"]
except FileNotFoundError:
# If file is not found, set budget to 0 and create a dataframe with our budget and savings
# Our budget variable
budget = 0
# lifetime_savings
lifetime_savings = 0
df = pd.DataFrame(
{"Budget": [0], "Lifetime_Savings": [0]})
# Monthly Salary
salary = 30000
# Take user input and store it in an integer
user_intent = ""
while user_intent != "quit":
if budget < 0:
print('''You're over your budget. Setting it to previous value.
Please retype your transactions.''')
budget = df.loc[0, "Budget"]
user_intent = str.lower(input('''What would you like to do today?
You can type "help" to get commands\n'''))
if user_intent == "help":
print('''
List of commands:
"expense" : Type out expenditure and automatically deducts it from your budget
"salary" : Adds salary to your budget
"gig" : Type out your gig payment and adds it to your budget
"quit" : Quits the program
"budget" : Tells you how much money you have left
"save" : Transfers money from budget to lifetime savings
''')
elif user_intent == "expense":
expense = int(input("How much did you spend?\n"))
budget -= expense
print(f"Expense of BDT {expense} deducted\n")
elif user_intent == "salary":
budget += salary
print("Salary added\n")
elif user_intent == "gig":
gig = int(input("How much did you get?\n"))
budget += gig
print(f"Gig payment of BDT {gig} added\n")
elif user_intent == "budget":
print(f"Your current budget is {budget}\n")
elif user_intent == "save":
saved = int(
input("How much would you like to transfer to lifetime savings?\n"))
lifetime_savings += saved
budget -= saved
print(f"You transfered BDT {saved} to savings\n")
elif user_intent == "quit":
print("Quitting the application")
df.loc[0, "Budget"] = budget
df.loc[0, "Lifetime_Savings"] = lifetime_savings
df.to_csv("budget.csv", index=False)
else:
print("Please refer to the help command and check if you made a typo.\n")For an even better system, we could add online storage in the form of Google Sheets (future article?) or go all out and use a fully-featured online database such as Google Cloud. We could even add a GUI and make it more like a computer app.
为了获得更好的系统,我们可以以Google表格的形式添加在线存储(将来的文章?),或者全力以赴并使用功能齐全的在线数据库,例如Google Cloud。 我们甚至可以添加GUI,使其更像计算机应用程序。
Other use cases include having to calculate the tab after VAT and service charge and dividing it among my friends at restaurants, seeing how many days I have before I run out of money due to my excessive spending and visualizing my spending habits. All of these are possible with Python and are surprisingly easy too!
其他用例包括必须计算增值税和服务费后的标签,然后将其分配给餐馆的朋友,查看由于过度支出而用完多少天后才能形象化支出习惯。 所有这些都可以通过Python实现,而且也非常容易!
Excel文件合并 (Excel File Merger)
I don’t know about you but for some reason, I’ve had to merge upwards of 50 excel files at times during my two internships at two firms. While some of the other interns got annoyed at the non-use of Google Sheets, I just made a small script to do this for me. This script also works for other file types with slight modifications. The code here was heavily inspired by this article from this fantastic blog called Practical Business Python.
我不了解您,但是由于某些原因,在两家公司的两次实习期间,我有时不得不合并多达50个excel文件。 尽管其他一些实习生因不使用Google表格而感到恼火,但我只是编写了一个小脚本来为我做这件事。 对该脚本进行少量修改后,它也可用于其他文件类型。 此处的代码在很大程度上来自于这个名为“ 实用业务Python”的出色博客的这篇文章的启发。
We will create a script that takes:
我们将创建一个包含以下内容的脚本:
An input directory containing all the files we need, combined in a CSV format.
输入目录包含我们需要的所有文件,并以CSV格式组合。
- An output directory. 输出目录。
- A file name for the combined CSV file. 合并的CSV文件的文件名。
The script will ignore the header row (1st row) and just combine the content of all the datasets. So ideally, we have CSV files with a similar number of columns and same column names in the same order. Although, with a bit more work, you could get rid of these restrictions!
该脚本将忽略标题行(第一行) ,仅合并所有数据集的内容。 因此,理想情况下,我们的CSV文件具有相似的列数和相同的列名,且顺序相同。 虽然,只要多做一些工作,您就可以摆脱这些限制!
Let’s import some libraries. Pathlib allows us to use the Path function which is useful because filepaths vary between Mac, Windows, and Linux. The OS module will be used to list all the files in a directory.
让我们导入一些库。 Pathlib允许我们使用Path函数,该函数很有用,因为Mac,Windows和Linux之间的文件路径有所不同。 OS模块将用于列出目录中的所有文件。
# Some helpful libraries
from pathlib import Path
import pandas as pd
import osNext, we create a function that combines the files taking in 3 inputs: the source directory, the output directory, and the name of the output file.
接下来,我们创建一个函数,将输入3个文件组合在一起:源目录,输出目录和输出文件的名称。
def combine_excel(source, destination, output_file):
# make an empty dataframe
df_combined = pd.DataFrame()
# Create a path variable from the source directory name and
# use the listdir function from the os library
input_dir = os.listdir(Path(source)) for files in input_dir:
df = pd.read_csv(Path(source + '/' + files))
df_combined = pd.concat([df_combined,df],ignore_index=True) df_combined.to_csv(
Path(destination + '/' + output_file + ".csv"), index=False) print("File Saved")os.listdir(path) allows us to create a list of all the filenames inside a folder. We then read the names of the files making sure to add the name of the source directory with a / and the name of the file. To illustrate why this is required, consider this example: our source directory is E:\Excelmerger and the files inside it are b.csv and c.csv. When we iterate over the files, we take the source (E:\Excelmerger), add a /and the name of the current file (b.csv) to get E:\Excelmerger\b.csvwhich is the correct path of the file.
os.listdir(path)允许我们创建文件夹内所有文件名的列表。 然后,我们读取文件的名称,确保添加带有/的源目录的名称以及文件的名称。 为了说明为什么需要这样做,请考虑以下示例:我们的源目录为E:\Excelmerger ,其中的文件为b.csv和c.csv 。 遍历文件时,我们使用源( E:\Excelmerger ),添加一个/和当前文件的名称( b.csv ),以获得E:\Excelmerger\b.csv ,这是文件的正确路径。文件。
The keen-eyed probably noticed that I added a forward slash,/, and the filepath still turned out to have a backward slash,\. On Mac, this stays as a forward slash. This is the magic of the Path() function, which directly refers to locations, so make sure to use / if you’re using Path().
敏锐的眼睛可能注意到我添加了一个正斜杠/ ,并且文件路径仍然显示为反斜杠\ 。 在Mac上,此符号为正斜杠。 这是Path()函数的神奇之处,该函数直接引用位置,因此,如果要使用Path() ,请确保使用/ 。
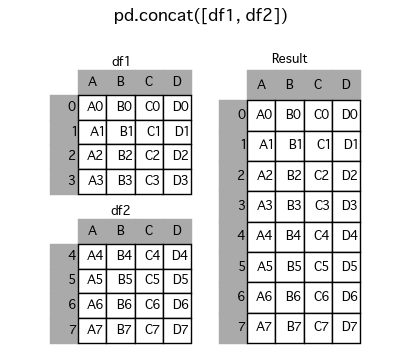
pd.concat([df1, df2, df3…]) function from the Pandas library is used to concatenate two dataframes. This will create a new dataframe that, by default, assumes the header is the same and merges the rows. We also tell it to ignore the index since order doesn’t matter for our case; we just need the data in the files to appear one after another(it would matter if we needed a specific order between multiple datasets).
Pandas库中的pd.concat([df1, df2, df3…])函数用于连接两个数据帧。 这将创建一个新的数据框,默认情况下,它假定标题相同并且合并行。 我们还告诉它忽略索引,因为顺序对我们的情况无关紧要; 我们只需要文件中的数据一个接一个地显示(如果我们需要多个数据集之间的特定顺序就很重要)。
While saving the file, take care to add the extension at the end.
保存文件时,请务必在最后添加扩展名。
We should also take into account possible errors that can occur and make a new function to validate the errors.
我们还应该考虑可能发生的错误,并提供一个新功能来验证错误。
def validate_inputs(source, destination, output_file):
# Assume there are no errors & error message is nonexistent
errors = False
error_message = [] # Path turns the source directory into a path variable that has
# a method called exists() that checks if its valid
# If the path doesn't exist, there is an error
if not (Path(source)).exists():
errors = True
error_message.append("Please select an input directory") # This is similar to the above but for output directory
if not (Path(destination)).exists():
errors = True
error_message.append("Please select an output directory") # This checks if the length of the output file is less than 1
# if it is 0 characters, that means field is empty
if len(output_file) < 1:
errors = True
error_message.append("Please enter a file name") # This returns the errors boolean and the error message string
return(errors, error_message)New functions used include the Path.exists() which checks if the filepath is valid and str.append() which allows us to add words to a string. We also use the len(string) function to find out if the user typed something.
使用的新函数包括Path.exists()用于检查文件路径是否有效)和str.append() (允许我们向字符串中添加单词)。 我们还使用len(string)函数来查找用户是否键入了某些内容。
# These take the inputs from the intent
source = input("Input_Directory: \n").replace('"', '')
destination = input("Output_Directory: \n").replace('"', "")
output_file = input("Output_Name: \n").replace('"', "")
# This triggers the validate input function
errors, error_message = validate_inputs(source, destination, output_file)
# If validate inputs returns an error, show the error message
# corresponding to that error
if errors:
print("Error: " + error_message)
else:
combine_excel(source, destination, output_file)Note that we add a str.replace('old', 'new')when we take the input. This removes any “ in our filepath which occurs when we drag and drop folders onto the terminal. Yes, you can drag and drop the input and output directories to the terminal window if you don’t feel like typing!
注意,当我们接受输入时,我们添加了一个str.replace('old', 'new') 。 这将删除在我们将文件夹拖放到终端上时在文件路径中出现的所有“ 。 是的,如果您不想打字,可以将输入和输出目录拖放到终端窗口中!
# Some helpful libraries
from pathlib import Path
import pandas as pd
import os
def validate_inputs(source, destination, output_file):
# Assume there are no errors and the error message is nonexistent
errors = False
error_message = []
# Path turns the source directory into a path variable that has a method
# called exists() that checks if its valid
# If the path doesn't exist, there is an error
if not (Path(source)).exists():
errors = True
error_message.append("Please select an input directory")
# This is similar to the above but for output directory
if not (Path(destination)).exists():
errors = True
error_message.append("Please select an output directory")
# This checks if the length of the output file is less than 1
# if it is less than 1 or 0 characters, that means the field is empty
if len(output_file) < 1:
errors = True
error_message.append("Please enter a file name")
# This returns the errors and the message
return(errors, error_message)
def combine_excel(source, destination, output_file):
# make an empty dataframe
df_combined = pd.DataFrame()
# Create a path variable from the source directory name and
# use the listdir function from the os library
input_dir = os.listdir(Path(source))
for files in input_dir:
df = pd.read_csv(Path(source + '/' + files))
df_combined = pd.concat(
[df_combined, df], ignore_index=True)
df_combined.to_csv(
Path(destination + '/' + output_file + ".csv"), index=False)
print("File Saved")
# These take the inputs from the intent
source = input("Input_Directory: \n").replace('"', "")
destination = input("Output_Directory: \n").replace('"', "")
output_file = input("Output_Name: \n").replace('"', "")
# This triggers the validate input function defined below to check for errors
errors, error_message = validate_inputs(
source, destination, output_file)
# If validate inputs returns an error, show that message to the user
if errors:
print("Error: " + error_message)
else:
combine_excel(source, destination, output_file)黏糊糊的怎么样? (How about a gooey?)
Remember that GUI we kept talking about? Let’s add it. We’ll leverage an easy to use library called appJar. Install it by typing pip install appjar in the Anaconda command prompt or terminal.
还记得我们一直在谈论的GUI吗? 让我们添加它。 我们将利用一个易于使用的库appJar 。 通过在Anaconda命令提示符或终端中键入pip install appjar进行pip install appjar 。
The code below has a lot of improvements: an error checker that makes sure all the files inside the source directory are CSV files and general improvements that a GUI adds, such as a quit button, traditional selection of filepaths (when you install a software and it asks for the installation directory) and so on.
下面的代码有很多改进:一个错误检查器,可确保源目录中的所有文件均为CSV文件以及GUI添加的常规改进,例如退出按钮,传统的文件路径选择(安装软件时,它要求安装目录),依此类推。
To fully understand how the code below works, you might need to look at the appJar documentation.
为了完全理解下面的代码是如何工作的,您可能需要查看appJar文档 。
# Some helpful libraries
from appJar import gui
from pathlib import Path
import pandas as pd
import os
# When button is pressed, check if its quit or combine
def press(button):
if button == "Combine":
# These take the inputs from the button
source = app.getEntry("Input_Directory")
destination = app.getEntry("Output_Directory")
output_file = app.getEntry("Output_Name")
# This triggers the validate input function defined below to check for errors
errors, error_message = validate_inputs(
source, destination, output_file)
# If validate inputs returns an error, show that message to the user
if errors:
app.errorBox("Error", "\n".join(error_message))
# If no errors trigger the combine excel function which takes 3 arguments
# source directory, destination directory and output file name
else:
combine_excel(source, destination, output_file)
elif button == "Quit":
# exit command on appjar
app.stop()
def validate_inputs(source, destination, output_file):
# Assume there are no errors and the error message is nonexistent
errors = False
error_message = []
# Path turns the source directory into a path variable that has a method
# called exists() that checks if its valid
# If the path doesn't exist, there is an error
if not (Path(source)).exists():
errors = True
error_message.append("Please select an input directory")
# This is similar to the above but for output directory
if not (Path(destination)).exists():
errors = True
error_message.append("Please select an output directory")
# This checks if the length of the output file is less than 1
# if it is less than 1 or 0 characters, that means the field is empty
if len(output_file) < 1:
errors = True
error_message.append("Please enter a file name")
# This checks all the files in the input directory to see if
# they're all csv files or not
# Create a path variable from the source directory name and
# use the listdir function from the os library to allow
# the program to iterate over all the files in the input directory
input_dir = os.listdir(Path(source))
csv_error_message = ''
for files in input_dir:
# Create an error message if the suffix of the file is not .csv
if Path(files).suffix.lower() != ".csv":
errors = True
csv_error_message = "Please select a directory with only csv files"
# Note that this is out of the loop because I don't want to repeat the
# error message in the loop
error_message.append(csv_error_message)
# This returns the errors and the message
return(errors, error_message)
def combine_excel(source, destination, output_file):
# make an empty dataframe
df_combined = pd.DataFrame()
input_dir = os.listdir(Path(source))
# Similar iteration to the error message iteration before
# reads through all the files in the directory and adds
# that dataframe to our main dataframe
for files in input_dir:
df = pd.read_csv(Path(source + '/' + files))
df_combined = pd.concat(
[df_combined, df], ignore_index=True)
# Saves the dataframe to our output directory
df_combined.to_csv(
Path(destination + '/' + output_file + ".csv"), index=False)
if(app.questionBox("File Saved", "Output csv files saved. Do you want to quit?")):
app.stop()
# Name of the app and the theme and size
app = gui("Excel File Merger", useTtk=True)
app.setTtkTheme("clam")
app.setSize(500, 200)
# The first button with input directory
app.addLabel("Choose Folder with CSV Files to be Merged")
app.addDirectoryEntry("Input_Directory")
# The second button with output directory
app.addLabel("Select Output Directory")
app.addDirectoryEntry("Output_Directory")
# Output file name entry
app.addLabel("Output File Name")
app.addEntry("Output_Name")
# Two buttons at the end
app.addButtons(["Combine", "Quit"], press)
# Start the app
app.go()If all of this was a bit too much to take in, I’d recommend going over the previous parts of the series and some Python programming problems online to get used to the syntax. These applications are fairly simple to understand as long as you get a hold of the syntax.
如果所有这些都太多了,我建议您回顾一下本系列的前几部分,以及一些在线的Python编程问题,以习惯语法。 只要掌握了语法,这些应用程序的理解就相当简单。
You should also try to implement these blocks of code yourself and look up anything that you found confusing in this article on the library docs, Stack Overflow, or just plain old Google. Learning through examples, implementation of the code by yourself, and fixing errors is a key skill and the next section is all about these!
您还应该尝试自己实现这些代码块,并在库文档Stack Overflow或普通的Google上查找本文中发现令人困惑的任何内容。 学习示例,自己实现代码以及修复错误是一项关键技能,下一节将介绍所有这些内容!

翻译自: https://medium.com/intelligentmachines/pragmatic-python-v-32fd894b3898
python -v
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









