





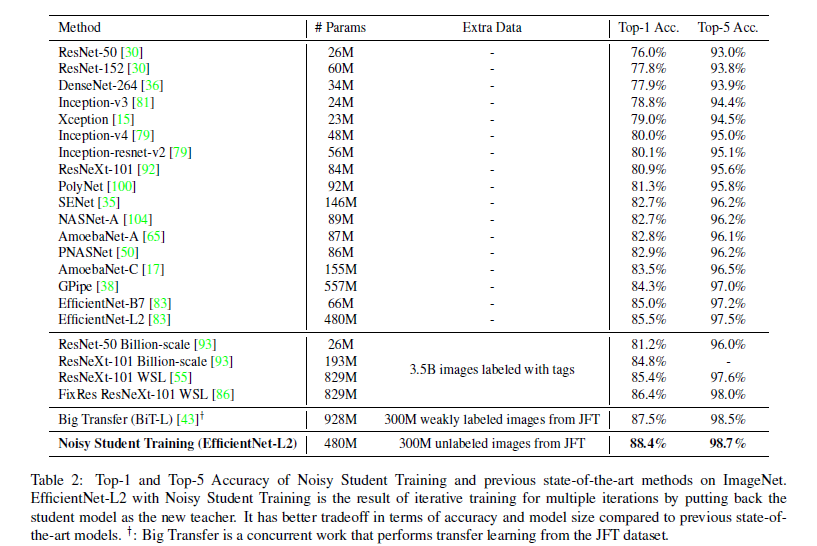
谷歌最新 imagenet
Image Classification algorithms have been getting better mostly by using more resources (data, computing power, and time). The best algorithms use an extra 3.5 Billion labeled images. This paper, written by Qizhe Xie et al bucks the trend. It is able to beat the current algorithms while using only an extra 300 M unlabeled images (both algorithms use the same labeled Dataset of images, on which we have the extra 3.5 B and 300 M images respectively). This means that the new method uses 12 times lesser images, while also not requiring those images to be labeled. Therefore it is many, many times cheaper while giving better results.
图像分类算法已经通过使用更多资源(数据,计算能力和时间)而变得越来越好。 最好的算法使用额外的35亿张带标签的图像。 谢启哲等人撰写的这篇论文逆势而上。 它仅使用额外的300 M未标记图像即可击败当前算法(两种算法均使用相同的标记数据集图像,在这些数据集上分别具有额外的3.5 B和300 M图像) 。 这意味着新方法使用的图像要少12倍 ,同时也不需要标记这些图像。 因此,它便宜很多很多倍,而且效果更好。
这个团队有什么不同之处? (What does this team do differently?)
On the surface, their approach seems to be standard SSL. The key to their superior performance lies in the steps taken before and during training. The unlabeled student model is larger than the teacher. The team also injects different types of noise into the data and models, ensuring that each student learns on more types of data distributions than their teachers. This combined with the Iterative Training is especially powerful since this makes use of the constantly improving teachers.
从表面上看,他们的方法似乎是标准的SSL。 它们出色表现的关键在于训练之前和训练期间所采取的步骤。 未贴标签的学生模型大于老师。 团队还向数据和模型中注入了不同类型的噪声 ,以确保每个学生都比老师学习更多类型的数据分布 。 这与迭代培训相结合特别有效,因为它利用了不断完善的教师。
关于那噪音 (All about that noise)
Since we have established the importance of noise in this training, it is important to understand the different kinds of noise involved. There are two broad categories of noise that can be implemented. Model noise refers to messing with the model during the training process. This prevents overfitting and might actually boost accuracy and robustness by allowing the model to evaluate the data with different “perspectives”. The other kind is called input noise where you inject noise to the input. The researchers specifically use RandAugment to achieve this. This serves a dual purpose of increasing the variety of data, and improving the accuracy of predictions (especially for real-world data, which is very noisy).
小号因斯我们建立在这个训练噪声的重要性,了解不同类型的噪声参与是很重要的。 可以实现两大类噪声。 模型噪声是指在训练过程中弄乱了模型。 通过允许模型以不同的“视角”评估数据,这可以防止过度拟合,并可能实际上提高准确性和鲁棒性。 另一种称为输入噪声 ,是在输入中注入噪声。 研究人员专门使用RandAugment实现了这一目标。 这具有增加数据种类和提高预测准确性的双重目的(尤其是对于嘈杂的现实数据)。

图表1:输入噪声的RandAug (Exhibit 1: RandAugment for Input Noise)

There are some really complicated noise functions in the world. RandAugment is not one of them. Don’t be fooled though, it is one of the most effective algorithms out there. It works in a really easy to understand way. Imagine there are N ways to distort an image. This can be anything, from changing some pixels to white, to shearing along an axis. RandAugment takes 2 inputs (n,m) where n is the number of distortions applied and m is the magnitude of the distortions. It returns the final image. The distortions are applied randomly, increasing the noise by adding variability.
世界上有一些非常复杂的噪声函数。 RandAugment不是其中之一。 但是,不要被愚弄了,它是最有效的算法之一。 它以一种非常容易理解的方式工作。 想象一下,有N种方法扭曲图像。 从将一些像素更改为白色到沿轴剪切,这可以是任何东西。 RandAugment接受2个输入(n,m),其中n是应用的失真数,m是失真的大小。 它返回最终图像。 失真是随机施加的,通过增加可变性来增加噪声。
In the image, we see RandAugment at work applying only 2 (fixed) transformations at varying magnitudes. Already these 3 samples are very different. It doesn’t take a genius to figure out how many you could get by varying both values across multiple images (answer: lots). The data augmentation should not be overlooked. It also ensures that the student model is always at least as big as the teacher, and therefore requires fewer
在图中,我们看到RandAugment在工作中仅应用了2个(固定的)变换,幅度不同。 这三个样本已经非常不同。 用天才的方法来找出通过在多个图像上同时改变两个值可以得到多少(答案:很多)。 数据扩充不容忽视。 它还可以确保学生模型总是至少与老师一样大,因此要求更少
图表2:模型噪声的下降 (Exhibit 2: Dropout for Model Noise)
Dropout is a process used on neural networks etc. Its process is very easy to describe: ignore some neurons every run of the network. Pictorially:
辍学是在神经网络等上使用的过程。它的过程非常容易描述:在网络的每次运行中都忽略一些神经元。 图示:
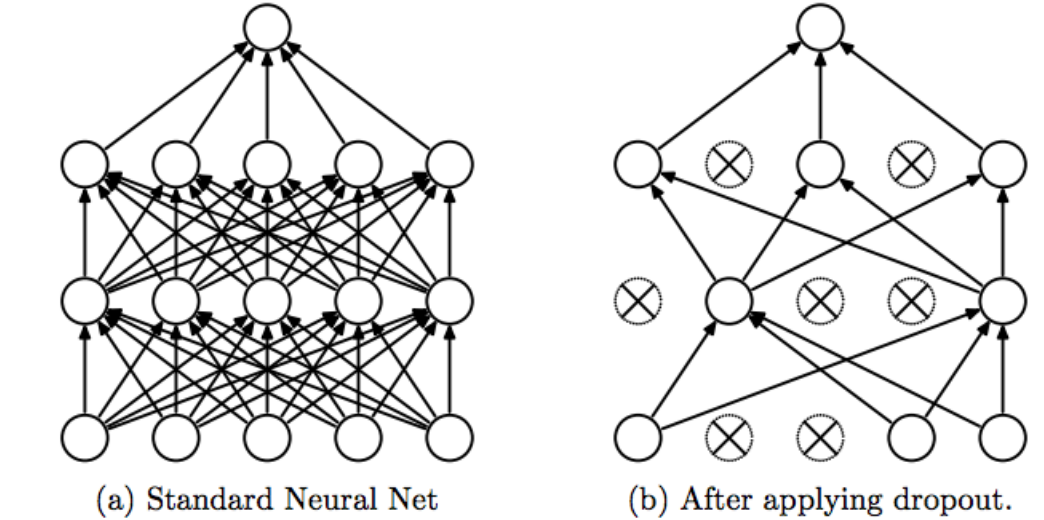
Dropout is applied because it stops overfitting. By ignoring different units, you change the output. The feedback allows it to generalize better. Additionally, dropout can be implemented to create a list of mini-learners from one network. By ensembling, the mini-learners can outperform the parent network.
应用Dropout是因为它会停止过度拟合。 通过忽略不同的单位,可以更改输出。 反馈使它可以更好地概括。 此外,可以实施辍学来从一个网络创建一个微型学习者列表。 通过整合,小型学习者可以胜过父网络。

图3:模型噪声的随机深度 (Exhibit 3: Stochastic Depth for Model Noise)
To be frank, I wasn’t super familiar with this concept. But hey that’s what Google is for. Reading into this was amazing. Probably my favorite thing this whole paper. If I had to restart life with only one memory, this would be it. Now that we have built up the hype…
坦率地说,我不是超级熟悉这个概念。 但这就是Google的目的。 读到这真是太神奇了。 整篇论文可能是我最喜欢的东西。 如果我只用一个内存就可以重启生活,那就可以了。 现在我们已经建立了炒作……
Stochastic Depth involves the following steps.
随机深度涉及以下步骤。
- Start with very deep networks 从非常深的网络开始
- During training, for each mini-batch, randomly drop a subset of layers and bypass them with the identity function. 在训练期间,对于每个小批量,随机放置一层子集并使用身份功能绕过它们。
- Repeat (if needed) 重复(如果需要)

This seems awfully similar to Dropout. And in a way it is. Think of it as a scaled-up version for deep networks. However, it is really effective. “ It reduces training time substantially and improves the test error significantly on almost all data sets that we used for evaluation. With stochastic depth we can increase the depth of residual networks even beyond 1200 layers and still yield meaningful improvements in test error (4.91 % on CIFAR-10).” Can’t argue with that. Will be delving into this soon. For now, look at this figure plotting error:
这似乎非常类似于Dropout。 在某种程度上,它是。 可以将其视为深度网络的扩展版本。 但是,它确实有效。 “它大大减少了训练时间,并且在我们用于评估的几乎所有数据集上都显着改善了测试错误。 使用随机深度,我们可以增加残留网络的深度,甚至超过1200层,并且仍然可以显着提高测试误差(在CIFAR-10上为4.91%)。” 不能与之争论。 不久将对此进行研究。 现在,看一下该图绘制错误:

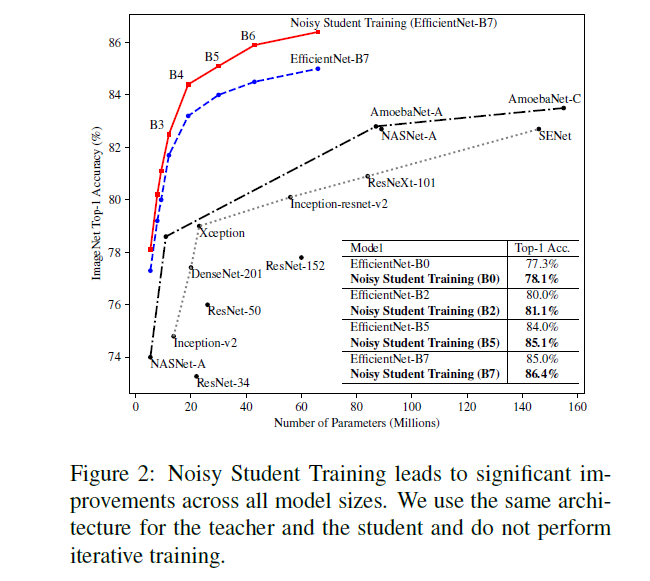
The 3 Kinds of Noise all contribute to the training in a unique way. And all 3 are amazing for adding robustness to predictions, by adding variation to input. This is what sets it apart in robustness from all the other State of the Art models. They are in fact so effective that even without the iterative training process, the process is able to improve current state of the art networks (more details on this in Pt 2).
三种噪音都以独特的方式为训练做出了贡献。 通过增加输入的变化量,这三种方法都为增强预测的鲁棒性带来了惊人的效果。 这就是它在鲁棒性方面与所有其他现有技术模型不同的地方。 实际上,它们是如此有效,以至于即使没有迭代的训练过程,该过程也能够改善当前的最新网络状态(Pt 2中对此有更多详细信息)。
训练过程 (Training Process)
Now that we understand how the different steps and adjustments improve the classification, we should look into some of the implementation details.
现在,我们了解了不同的步骤和调整如何改进分类,我们应该研究一些实现细节。

To me, the most significant part of the training comes in step 3. The researchers state that “Specifically, in our method, the teacher produces high-quality pseudo labels by reading in clean images, while the student is required to reproduce those labels with augmented images as input.” As we have seen, adding noise to the images (or models) can drastically change how they look. By forcing the student to work with augmented images, it allows the model to predict very unclear images with great accuracy. The details of this will be in Pt 2. but for now, here’s an example of how crucial this is in predicting ambiguous images.
对我而言,培训中最重要的部分是第3步。研究人员指出: “具体来说,在我们的方法中,老师通过阅读清晰的图像来生成高质量的伪标签,而 要求学生使用增强图像作为输入 。” 如我们所见,向图像(或模型)添加噪点会极大地改变它们的外观。 通过强迫学生处理增强图像,它使模型可以非常准确地预测非常模糊的图像。 其细节将在Pt 2中。但是现在,这是一个示例,说明在预测模糊图像方面有多么关键。

下一步 (Next Steps)
Please leave your feedback on this article below. If this was useful to you, please share it and follow me here. Additionally, check out my YouTube channel. I will be posting videos breaking down different concepts there. I will also be streaming on Twitch here. I will be answering any questions/having discussions there. Please go leave a follow there. If you would like to work with me email me here: devanshverma425@gmail.com or reach out to me LinkedIn. Follow my Instagram to keep up with me. Use my RobinHood Referral Link to get a free stock at the commission-free stock platform Robinhood.
请在下面留下您对本文的反馈。 如果这对您有用,请分享并在这里关注我。 此外,请访问我的YouTube频道 。 我将在那里发布分解不同概念的视频。 我还将在这里在Twitch上直播 。 我将在那里回答任何问题/进行讨论。 请去那里跟随。 如果您想和我一起工作,请给我发电子邮件:devanshverma425@gmail.com或与我联系(LinkedIn) 。 跟随我的Instagram跟上我。 使用我的RobinHood推荐链接可在免佣金的股票平台Robinhood上获得免费股票。
Here is the paper promised. Be sure to download and read it as I’ve defined important definitions and highlighted the crucial sections. It will help you understand the paper better.
这是承诺的文件。 在定义好重要定义并突出显示关键部分时,请确保下载并阅读它。 这将帮助您更好地理解本文。
谷歌最新 imagenet
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}