





pytorch flask
During the last weeks I have implemented an item-to-item image recommender system that uses PyTorch’s pretrained Resnet18 convolutional neural network to generate comparability through feature vectors, a database to manage the images and top-k lists and a user interface.
在过去的几周中,我实现了一个逐项图像推荐系统,该系统使用PyTorch的预训练的Resnet18卷积神经网络通过特征向量,用于管理图像和前k个列表的数据库以及用户界面来产生可比性。
The developed solution and steps for the deployment on Heroku are presented in this article and the code is available on GitHub.
本文介绍了开发的解决方案和在Heroku上进行部署的步骤,并且代码可在GitHub上获得 。
I have set and fulfilled the following requirements for this project
我已经为此项目设定并满足以下要求
1. The web app is accessible on the internet.
1.可在Internet上访问该Web应用程序。
2. The application has a gallery of images with pagination, loading only the relevant data for the page.
2.该应用程序具有分页图像的图像库,仅加载页面的相关数据。
3. The data for the gallery and the recommendations is fetched from a database.
3.从数据库中获取图库和建议的数据。
4. The recommendations are most similar images from a possibly large image set. They must appear instantaneously; this means that the similarity calculation happens offline.
4.建议是来自可能较大图像集中的最相似图像。 它们必须立即出现。 这意味着相似度计算是离线进行的。
5. The gallery is responsive.
5.画廊ReactSwift。
6. The Flask application is suitably packaged for future extensions/reuse.
6. Flask应用程序已适当打包,以供将来扩展/重用。
In my last post already parts of the requirements were realized as prototype, in particular 2 and 4. A Jupyter notebook is available at GitHub for the Resnet18 PyTorch recommender that takes an image as input and gives out most similar images from the same image set. To use the Flask app this notebook should be used to generate Pandas dataframes that are stored as pickle files. These are used as static content in the app.
在我的上 一篇 文章中,部分需求已经实现为原型,特别是2和4。原型在GitHub上有一个Jupyter笔记本,用于Resnet18 PyTorch推荐器,该推荐器将图像作为输入并从同一图像集中给出最相似的图像。 要使用Flask应用程序,应使用此笔记本生成存储为pickle文件的Pandas数据框。 这些用作应用程序中的静态内容。
In this post we will show how to realize also all other requirements, how to use an SQLite database locally and PostgreSQL on Heroku, how to use it for pagination, how to clean-up the work and to deploy it to Heroku to make it available on the internet via browser on PCs or smartphones.
在这篇文章中,我们将展示如何实现所有其他要求,如何在本地使用SQLite数据库以及在Heroku上使用PostgreSQL,如何将其用于分页,如何清理工作并将其部署到Heroku以使其可用通过PC或智能手机上的浏览器访问互联网。
You can access and test the demo app with a few images on Heroku through the following link:
您可以通过以下链接在Heroku上使用一些图像来访问和测试演示应用程序:

This post is structured in the following sections:
这篇文章的结构分为以下几节:
1. The features of the app are described
1.描述了应用程序的功能
2. The calculation of similarities between images is revisited
2.重新讨论图像之间的相似度计算
3. The packaging structure for the application is described
3.描述了应用程序的包装结构
4. The SQL model is presented
4.介绍了SQL模型
5. The backend application logic is introduced
5.引入了后端应用程序逻辑
6. The templates are introduced
6.模板介绍
7. All steps for the Heroku deployment are explained
7.说明了Heroku部署的所有步骤
8. A conclusion is made
8.得出结论
Note, for this article I was using a Windows 10 machine and Python 3.5.4. I have left out any exception handling.
请注意,对于本文,我使用的是Windows 10计算机和Python 3.5.4。 我没有任何异常处理。
1.该应用程序的功能 (1. Features of the app)
To get a better understanding what the implementation is for, let me briefly explain the features of the application.
为了更好地理解实现的目的,让我简要解释一下应用程序的功能。
Image gallery:
图片库:
One can browse a set of images in a self-written gallery, showing all the images from the initial input set (a small test set generated from my private image repository), as depicted below:
可以浏览自写图库中的一组图像,显示来自初始输入集(从我的私有图像存储库生成的一个小型测试集)的所有图像,如下所示:

The gallery has a custom design that was created with stylesheets. It defines the sizing of the header, the mouse reactions, the images, the text overlay, and pagination number appearance.
画廊具有使用样式表创建的自定义设计。 它定义了标题的大小,鼠标的React,图像,文本覆盖和分页号外观。
Pagination:
分页 :
You can see the numbers below the images in the gallery. These allow to select a page with images. To not load all data at once I moved away from a JavaScript based approach that lead to hiding more information, but it was still loading all images. With the presented implementation, only the relevant data is loaded.
您可以在图库中的图像下方看到数字。 这些允许选择带有图像的页面。 为了不一次加载所有数据,我放弃了使用基于JavaScript的方法来隐藏更多信息的方法,但是它仍在加载所有图像。 使用提出的实现,仅加载相关数据。
Image recommendations:
图片建议:
To each image from a possibly large image set, similar images with similarity values are fetched and presented in a second route. A one-to-many relationship is used for that end to show the most similar images to a selected input. The approach allows to change the number of sought recommendations. We use four, due to the small, artificial image set.
对于可能较大的图像集中的每个图像,将提取具有相似性值的相似图像并在第二条路径中显示。 为此,使用一对多关系来显示与所选输入最相似的图像。 该方法允许更改所寻求建议的数量。 由于人为图像较小,我们使用四个。

As the images are truncated you can further click and enlarge them in a modal to see the complete images, this modal uses some basic JavaScript.
当图像被截断时,您可以进一步单击并以模态形式放大它们以查看完整的图像,该模态使用一些基本JavaScript。

Responsiveness:
响应能力 :
The gallery and the recommendations are responsive, this means that you can use it on a smartphone and the image selection and proposals are user friendly on such devices.
图库和建议是响应性的,这意味着您可以在智能手机上使用它,并且图像选择和建议在此类设备上对用户友好。

Database commands:
数据库命令:
I prepared some test data and used a dictionary to use it in an earlier prototype. This is reused for an import command. One can use the console to create or clear the database, and to import data described in such a dictionary. This works locally for the SQLite, but also for the PostgreSQL database at Heroku. The commands are included as Blueprint module.
我准备了一些测试数据,并使用了字典以在较早的原型中使用它。 这可用于导入命令。 可以使用控制台创建或清除数据库,以及导入此类词典中描述的数据。 这对于SQLite在本地有效,但对于Heroku上的PostgreSQL数据库也有效。 这些命令包含在“蓝图”模块中。
2.离线计算推荐 (2. Calculating recommendations offline)
In a previous article I explained in detail how one can easily generate a similarity matrix and top-k lists (for each image, the k most similar other images). An implementation was presented in a separate post. Hence check-out these posts for details.
在上一篇文章中,我详细说明了如何轻松生成相似度矩阵和前k个列表(对于每个图像,k个最相似的其他图像)。 一个实现在单独的帖子中介绍 。 因此,请查看这些帖子以获取详细信息。
What we do, briefly:
我们的工作简要如下:
- Preprocess images from an image input folder 预处理图像输入文件夹中的图像
- To each image create feature vectors with Resnet18 from PyTorch 对于每个图像,使用PyTorch的Resnet18创建特征向量
- Compare feature vectors and store top-k lists 比较特征向量并存储前k个列表
This is done in one Jupyter notebook, where I now added two lines to store the dataframes with similar image names and similarity values as pickle files. These are used as static content for the recommender application presented here. You can check-out the repository with the test images and it should run without efforts.
这是在一个Jupyter笔记本中完成的 ,我现在在其中添加了两行以将具有相似图像名称和相似值的数据帧存储为pickle文件。 这些用作此处介绍的推荐器应用程序的静态内容。 您可以使用测试映像检出存储库,它可以轻松运行。
What we need to add is the import of these results — the actual recommendations — to an SQL database.
我们需要添加的是将这些结果(实际建议)导入SQL数据库。
For the online processing the backend process only queries the most similar images for rendering the proper html.
对于在线处理,后端过程仅查询最相似的图像以呈现适当的html。
3.打包应用 (3. Packaging the app)
The following application structure has been used:
使用了以下应用程序结构:
~/imageRecommender
|-- requirements.txt # All packages to run the app
|-- Procfile # file needed to use gunicorn
|-- run.py # starts the application
|-- .flaskenv # sets environment variables
|__ env # virtual environment – not in vc
|__ /imageRecommender # The application package
|-- __init__.py # Application factory method
|-- config.py # Configuration file for dev/prod
|-- models.py # Database models
|__ /commands # For import to database
|-- __init__.py # Application factory
|-- commands.py # Commands for DB creation/import
|__ /main # For routes
|-- __init__.py # Application factory
|-- routes.py # Business logic, fctns for routes
|__ /static # All static data
|__ /css # Stlyesheets
|__ /javascript # Java Script code for modal
|__ /pickles # The top-k lists in pickle format
|__ /site_imgs # The images for the app
|-- favicon.ico # The favicon
|__ /templates # All templates
|-- home.html # Home route
|-- layout.html # General layout
|-- recommend.html # Recommend routeThe __init__.py files make the folders that they are contained into modules. These modules can be registered as Blueprints. Only the __init__.py file on the imageRecommender level is non-empty in this application.
__init__.py文件使它们包含在模块中的文件夹。 这些模块可以注册为蓝图。 在此应用程序中,只有imageRecommender级别上的__init__.py文件为非空。
4.数据模型 (4. The data model)
We store the image information in an SQL database. Therefore, we use Flask-SQLAlchemy, a library that helps using Flask with SQLAlchemy — which again is a Flask SQL toolkit that gives you the possibility to use SQL with Flask.
我们将图像信息存储在SQL数据库中。 因此,我们使用Flask-SQLAlchemy ,该库可帮助将Flask与SQLAlchemy结合使用-这又是一个Flask SQL工具包,使您可以将SQL与Flask一起使用。
3.1. Getting started with SQL for Flask
3.1。 SQL for Flask入门
The package supporting SQL databases is flask-sqlalchemy, version 2.4.4 is in the requiremets.txt file. With this we can import it to the application in the factory for the imageRecommender application factory __init__.py.
支持SQL数据库的软件包是flask-sqlalchemy ,版本2.4.4在requiremets.txt文件中。 这样,我们可以将其导入imageRecommender应用程序工厂__init__.py的工厂应用程序中。
We configure the SQLite database for the Flask application locally and a Postgres database (everything is stored in one file then) for Heroku in the config.py file
我们在本地为Flask应用程序配置SQLite数据库,并在config.py文件中为Heroku配置Postgres数据库(所有内容都存储在一个文件中)。
import os
class developmentConfig:
SECRET_KEY = '[\xaa$I"*\xdd$85]D\x11\x02\x8d\x97\xf0\x1fU\xb7\x8c\rA\xe8'
SQLALCHEMY_DATABASE_URI = 'sqlite:///gallery.db'
class productionConfig:
SECRET_KEY = os.environ.get('SECRET_KEY')
SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URL')Dependent on the use-case (development or production on Heroku) the right configuration is chosen. The secret key in production needs to be unique for security and the URL for the database needs to be set.
根据用例(Heroku上的开发或生产),选择正确的配置。 为了安全起见,生产中的密钥必须是唯一的,并且需要设置数据库的URL。
3.2. The data model
3.2。 数据模型
We create a class for the images for the gallery and a related class for the images to be recommended.
我们为图库的图像创建一个类,并为要推荐的图像创建一个相关的类。
from imageRecommender import db
class Galleryimages(db.Model):
id = db.Column(db.Integer, primary_key=True)
imageName = db.Column(db.String(50), unique=True, nullable=False)
imageDescription = db.Column(db.String(150), unique=False, nullable=False, default='n.a.')
imageRecs = db.relationship('Imagerecommendations', backref='galleryimages', lazy=True)
def __repr__(self):
return "(%s, %s, %s)" % (self.id, self.imageName, self.imageDescription)
class Imagerecommendations(db.Model):
id = db.Column(db.Integer, primary_key=True)
recommendedID = db.Column(db.Integer, db.ForeignKey('galleryimages.id'), nullable=False)
recommendedName = db.Column(db.String(50), unique=False, nullable=False)
similarityValue = db.Column(db.Float, unique=False, nullable=False)
def __repr__(self):
return "(%s, %s, %s, %s)" % (self.id, self.recommendedID, self.recommendedName, self.similarityValue)Some remarks to this model:
此模型的一些说明:
The id identifiers for both tables are set automatically and uniquely as default
默认情况下,两个表的ID标识符自动且唯一地设置
imageName and imageDescription are strings for the metadata of the images
imageName和imageDescription是图像元数据的字符串
imageRecs is the relationship to the recommendations, these are needed for the recommend route
imageRecs是与推荐的关系,推荐路线需要这些
The Imagerecommendations class contains the related ID from the queried image, the name of the recommended image and its similarity value. It denormalizes the normal form with respect to the image name
Imagerecommendations类包含查询图像的相关ID,推荐图像的名称及其相似性值。 它将关于图像名称的规范形式归一化
We can now create the database and import data.
现在,我们可以创建数据库并导入数据。
3.3 Database commands
3.3数据库命令
There are three simple commands:
有三个简单的命令:
- to drop the database 删除数据库
- to create it 创建它
- to import data 导入数据
The app is packaged as described above such that the commands.py script has access to the application — we will see that when talking about Blueprints later.
该应用程序如上所述进行了打包,以便commands.py脚本可以访问该应用程序-我们稍后将在讨论蓝图时看到这一点。
def getNames(inputName, similarNames, similarValues):
[…]
return inputName, images[0:numRec], values[0:numRec]
def getImages(inputImage):
[…] (load from pickles)
return getNames(inputImage, similarNames, similarValues)
cmd = Blueprint('db', __name__)
@cmd.cli.command('createDB')
def createDB():
db.create_all()
@cmd.cli.command('dropDB')
def dropDB():
db.drop_all()
@cmd.cli.command('importDB')
def importDB():
# would work nicer with a JSON file
images = [
{
'name':'buildings0.jpg',
'caption': 'Lisboa'
},
[…] (many more images here)
{
'name': 'trees4.jpg',
'caption': 'Forrest 5'
}
]
for image in images:
img = Galleryimages(imageName=image['name'], imageDescription=image['caption'])
db.session.add(img)
db.session.commit()
inputImage, images, values = getImages(image['name'])
recArray = []
for j in range(0, numRec):
rec = Imagerecommendations(recommendedID = img.id, recommendedName=images[j], similarityValue=values[j])
db.session.add(rec)
db.session.commit()
db.session.close()After running the import one has already a database that one can test, e.g. by creating queries.
运行导入后,已经有一个可以测试的数据库,例如通过创建查询。
5.后端应用程序逻辑 (5. The backend application logic)
It was already described in my last article what Flask is and how to set-it up.
我的上一篇文章已经描述了Flask是什么以及如何设置。
The solution is packaged to the imageRecommender package, and we call it with the run.py script
该解决方案打包到imageRecommender包中,我们使用run.py脚本对其进行调用
from imageRecommender import createApp
app = createApp()
if __name__ == '__main__':
app.run(debug=True)The createApp method is in the __init__.py application factory, and it becomes useful to work with it when extending the application, e.g. by tests that require several instances of the app.
createApp方法位于__init__.py应用程序工厂中,在扩展应用程序时(例如,通过需要多个应用程序实例的测试),使用该方法很有用。
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from imageRecommender.config import developmentConfig, productionConfig
import os
db = SQLAlchemy()
def createApp():
app = Flask(__name__)
if os.environ['FLASK_ENV'] == "development":
app.config.from_object(developmentConfig)
else:
app.config.from_object(productionConfig)
db.init_app(app)
from imageRecommender.main.routes import main
from imageRecommender.commands.commands import cmd
app.register_blueprint(main)
app.register_blueprint(cmd, cli_group=None)
return appFor the imports the configurations are loaded, these were described earlier. The app needs to be created in this __init__.py file via app = Flask(__name__).
对于导入,将加载配置,这些已在前面进行了描述。 需要通过app = Flask(__ name__)在此__init__.py文件中创建应用。
- After the object is created the environment variable is validated for the right use-case and the suitable configuration is loaded. 创建对象后,将针对正确的用例验证环境变量,并加载适当的配置。
- The database object is created, and two Blueprints are registered for the main application and the database commands. cli_group=None merges the commands to application level, so that they are just callable by flask <command name> in the Heroku console. 创建数据库对象,并为主应用程序和数据库命令注册了两个蓝图。 cli_group = None不会将命令合并到应用程序级别,以便可以通过Heroku控制台中的flask <command name>调用它们。
The main Blueprint contains the main backend application logic in the routes.py file. Let’s go through this file set-by step:
主蓝图在routes.py文件中包含主后端应用程序逻辑。 让我们逐步了解此文件:
from flask import render_template, request, Blueprint
from imageRecommender.models import GalleryimagesWe work with templates that are used for html page generations through the render_template package.
我们通过render_template包处理用于html页面生成的模板。
- Via request we get the name of the selected image and the page that we are on in the gallery. 通过请求,我们获得所选图像的名称以及画廊中的页面。
- As we use Blueprints for modularizing the application, Blueprint is imported. 当我们使用蓝图对应用程序进行模块化时,蓝图即被导入。
To the queried image we get the similar images via the Imagerecommendations related class, and therefore we work with our Galleryimages class.
对于查询的图像,我们通过Imagerecommendations相关类获得了相似的图像,因此我们使用Galleryimages类。
main = Blueprint('Fmain', __name__)The blueprint Fmain is registered.
蓝图Fmain已注册。
@main.route("/")
@main.route("/home")
def home():
page = request.args.get('page', 1, type=int)
gImages = Galleryimages.query.paginate(page=page, per_page=8)
return render_template('home.html', images = gImages)- The main and home route give access to the gallery. 主要路线和到达路线可通往画廊。
Via the home.html template we render the images given within the render_template call.
通过home.html模板,我们渲染render_template调用中给出的图像。
It takes as input the images from gImages. Here the pagination feature is used. With per_page it can be set how many images are to be shown on one page of the gallery, and page is the default page to be opened, in this case the first page of the gallery with the first eight images.
它接受来自gImages的图像作为输入。 这里使用了分页功能。 使用per_page可以设置在画廊的一页上显示多少张图像,而page是要打开的默认页面,在这种情况下,画廊的第一页包含前八张图像。
@main.route("/recommend")
def recommend():
selectedImage = request.args.get('selectedImage')
imageEntry = Galleryimages.query.filter_by(imageName=selectedImage)
images = []
values = []
for image in imageEntry:
for recommendation in image.imageRecs:
images.append(recommendation.recommendedName)
values.append(recommendation.similarityValue) return render_template('recommend.html', title='Recommendations', customstyle='recommend.css', inputImage=selectedImage, similarImages=images, similarityValues = values)if __name__ == '__main__':
app.run(debug=True)- The recommend route is called with the corresponding recommend function that requests the user’s selectedImage. 使用相应的推荐功能调用推荐路线,该推荐功能请求用户的selectedImage。
- It is queried from our database, and we iterate all recommendations from the related class. 从我们的数据库中查询它,并且我们迭代相关类中的所有建议。
- The image and value arrays are filled with corresponding information. 图像和值数组填充有相应的信息。
- All required information is passed to render the recommend.html page. 传递了所有必需的信息以呈现“ recommended.html”页面。
6.模板 (6. The templates)
We saw two calls to render html pages from templates:
我们看到了两个从模板渲染html页面的调用:
render_template('home.html', images = gImages)render_template('recommend.html', title='Recommendations', customstyle='recommend.css', inputImage=selectedImage, similarImages=images, similarityValues = values)Let us have a look on the relevant sections of the home.html and recommend.html files
让我们对home.html的和recommend.html文件的相关章节来看看
The application uses a layout template layout.html to maximize reuse of html code. The important part is that the body of the template has a block content that is specified within the other two html files.
该应用程序使用布局模板layout.html来最大程度地重用html代码。 重要的是模板的主体具有在其他两个html文件中指定的块内容。
<body>
…
{% block content %} {% endblock %}
</body>The home.html file is used for the gallery
home.html文件用于画廊
{% extends "layout.html" %}
{% block content %}
<section class="gallery">
<div class="galleryWrapper">
<div class="galleryContent">
{% for image in images.items %}
<div class="item">
<a href="{{ url_for('main.recommend', selectedImage='') }}{{image.imageName }}">
<img src="{{ url_for('static', filename='site_imgs/images/') }}{{image.imageName}}" alt="{{image.imageName}}" id="showSimilarInPopup">
<div class="caption">
{{image.imageDescription}}
</div>
</a>
</div>
{% endfor %}
</div>
<div class="pagination">
{% for page_num in images.iter_pages(left_edge=2, right_edge=2, left_current=1, right_current=2) %}
{% if page_num %}
{% if images.page == page_num %}
<a class="currentpage" href="{{ url_for('main.home', page=page_num) }}">{{ page_num }}</a>
{% else %}
<a class="otherpages" href="{{ url_for('main.home', page=page_num) }}">{{ page_num }}</a>
{% endif %}
{% else %}
...
{% endif %}
{% endfor %}
</div>
</div>
</section>
{% endblock content %}It consists mainly of two parts:
它主要包括两个部分:
1. The images in the gallery that are iterated via {% for image in images.items %} and
1.通过{%为images.items%}中的image迭代画廊中的图像,然后
2. The pagination elements in the pagination div section. Here the most interesting part is the iter_pages method that allows to set how many numbers are shown to the left and right edges, and in the middle of the number block
2.分页div部分中的分页元素。 这里最有趣的部分是iter_pages方法,该方法允许设置在数字块的中间和左右边缘显示多少个数字
{% for page_num in images.iter_pages(left_edge=2, right_edge=2, left_current=1, right_current=2) %}
{images.iter_pages(left_edge = 2,right_edge = 2,left_current = 1,right_current = 2)中page_num的百分比%}
The recommend.html template is used to show the query and the most similar images:
describe.html模板用于显示查询和最相似的图像:
{% extends "layout.html" %}
{% block content %}
<section class="gallery">
<div class="galleryWrapper">
<div class="originalImage">
<h3> INPUT IMAGE</h3>
<img src="{{ url_for('static', filename='site_imgs/images/') }}{{inputImage}}" alt="{{similarImages[0]}}" id="showSimilarInPopup">
</div>
<div class="galleryContent">
<h3> SIMILAR IMAGES</h3>
{% for image in similarImages %}
<div class="item">
<img id="popupImage{{loop.index}}" onclick="imageClicked(this.id)" src="{{ url_for('static', filename='site_imgs/images/') }}{{image}}" alt="{{image}}" id="showSimilarInPopup">
</div>
{% endfor %}
</div>
</div>
</section>
<!-- The Modal for showing a selected image enlarged -->
<div id="myModal" class="modal">
<span class="close">×</span>
<img class="modal-content" id="thePopupImageID">
</div>
<script src="{{ url_for('static', filename='js/imagemodal.js') }}"></script>
{% endblock content %}The modal at the end and the inclusion of the only JavaScript code in this app are for the pop-up that enlarge the similar images if wanted.
最后的模态以及此应用程序中唯一JavaScript代码都包含在弹出窗口中,以便在需要时放大相似的图像。
Responsiveness:
响应能力:
To properly show the gallery on a smartphone some design elements need different sizing and the gallery shall have only one column. This can all be realized with stylesheets by adding a corresponding section
为了在智能手机上正确显示图库,某些设计元素需要使用不同的大小,并且图库应只有一列。 通过添加相应的部分,可以使用样式表全部实现
@media only screen and (max-device-width : 640px) {and for the gallery content we have set for example the column-count to one in this section
对于图库内容,我们在本节中将例如列数设置为一
.gallery .galleryContent .item{
float: left;
width: 100%;
height: 100%;
position: relative;
cursor: pointer;
column-count: 1;
}7. Heroku部署 (7. Heroku deployment)
The .flaskenv file contains two entries and it works when python-dotenv is installed
.flaskenv文件包含两个条目,并且在安装python-dotenv时有效
FLASK_APP=run.py
FLASK_ENV=developmentso that flask run lets you test the application locally on http://localhost:5000/
这样,flask运行可让您在http:// localhost:5000 /本地测试应用程序
Now it is time to deploy the package and make it accessible through the internet.
现在是时候部署该软件包并使其可以通过Internet进行访问了。

Heroku is a platform that allows to easily deploy and host applications. It spares most efforts, no usual system administration, webserver, firewall set-up tasks etc. are needed. A free tier allows simple tests and the presented demo runs on such a free host. We want to deploy the application to Heroku as it offers free cloud web hosting services that are optimal for a demo as this one.
Heroku是一个可以轻松部署和托管应用程序的平台。 它不遗余力,不需要常规的系统管理,Web服务器,防火墙设置任务等。 免费套餐允许进行简单的测试,并且所展示的演示可以在这样的免费主机上运行。 我们希望将应用程序部署到Heroku,因为它提供了免费的云虚拟主机服务,这对于本次演示来说是最佳的。
The following steps are tested and working in August 2020 on Heroku.com.
以下步骤已在2020年8月在Heroku.com上进行了测试和运行 。
For a simple deployment to Heroku push your code to GitHub. Create a repository. Use the URL you received to push the repository to GitHub.
为了将其简单部署到Heroku,请将您的代码推送到GitHub。 创建一个存储库。 使用您收到的URL将存储库推送到GitHub。
Therefore, you need to visit https://www.heroku.com/ and create an account with the primary development language Python.
因此,您需要访问https://www.heroku.com/并使用主要开发语言Python创建一个帐户。
To install the Heroku CLI follow the instructions on https://devcenter.heroku.com/articles/heroku-cli.
要安装Heroku CLI,请按照https://devcenter.heroku.com/articles/heroku-cli上的说明进行操作。
You can carry out many of the following steps with the Heroku CLI, however, if possible, I present UI based configuration steps.
您可以使用Heroku CLI执行以下许多步骤,但是,如果可能的话,我将介绍基于UI的配置步骤。
In Heroku click on “Create a new app”. It requests you to give it a name, let us set here image-recommender-demo and the region Europe.
在Heroku中,点击“创建新应用”。 它要求您给它起个名字,让我们在这里设置image-recommender-demo和欧洲区域。
Confirm and you get to a next screen, where you can select your deployment method
确认并进入下一个屏幕,您可以在其中选择部署方法

As we pushed the code to GitHub, we select the GitHub option, after which we need to “Connect to GitHub” and authorize Heroku to access your GitHub repository.
在将代码推送到GitHub时,我们选择GitHub选项,此后我们需要“连接到GitHub”并授权Heroku访问您的GitHub存储库。
Next, we enter the name of the corresponding repository image-recommender-demo, search for it and connect to it.
接下来,我们输入相应存储库image-recommender-demo的名称 ,搜索并连接到它。
You can select to automatic deploy each change, e.g. to your master branch, which is very handy for such demo use-cases,
您可以选择自动将每个更改(例如部署到您的master分支)部署,对于此类演示用例来说非常方便,
For the start we deploy it once manually (there is another button to be pushed for that end). You can now see your solution being built and the state of success
首先,我们手动部署一次(为此需要按下另一个按钮)。 现在,您可以看到正在构建的解决方案以及成功的状态
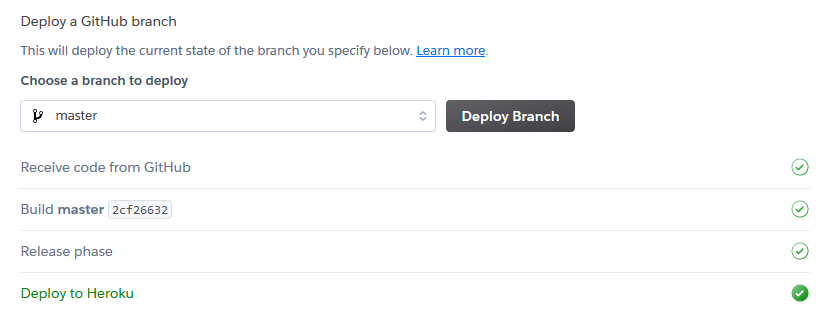
On top of the site you can find a button
在网站顶部,您可以找到一个按钮

That leads us in this case to our recommender system on
在这种情况下,这导致我们进入了推荐系统
https://image-recommender-demo.herokuapp.com/
https://image-recommender-demo.herokuapp.com/
Until now the logs will show that no web processes are running, therefore a Procfile needs to be created, this is used by Heroku to understand how to run the application. It contains only the line
到目前为止,日志将显示没有任何Web进程正在运行,因此需要创建一个Procfile ,Heroku使用它来了解如何运行该应用程序。 它仅包含行
web: gunicorn run:appweb specifies that a web worker is used. An application server is needed, therefore gunicorn is used and it needs to be installed — version 20.0.4 is referenced in the requirements.txt file. gunicorn is the command needed to run the web process, such that the python code can communicate to the webserver. run refers to the run.py file containing the application object, app refers to the name of the application object.
web指定使用网络工作者。 需要一个应用程序服务器,因此使用gunicorn并需要安装它-在requirements.txt文件中引用了20.0.4版。 gunicorn是运行Web进程所需的命令,以便python代码可以与Web服务器通信。 run是包含应用程序对象的run.py文件, app是应用程序对象的名称。
After this is committed, one needs to set FLASK_ENV. As mentioned I use the .flaskenv file locally. In production the configuration is set manually via the Heroku CLI
提交后,需要设置FLASK_ENV。 如前所述,我在本地使用.flaskenv文件。 在生产中,通过Heroku CLI手动设置配置
heroku config:set FLASK_ENV=production --app image-recommender-demoIf you are not yet logged in, Heroku will request a login first.
如果您尚未登录,Heroku将首先请求登录。
Now running the app still leaves you with an internal server error as the database is not set-up yet.
现在,运行该应用程序仍会导致内部服务器错误,因为尚未设置数据库。
We want to work with PostgreSQL. Click on “overview” in the Heroku UI, select “Configure Add-ons”, search for “Postgres”; select “Heroku Postgres”. I use the free version for this demo.
我们想使用PostgreSQL。 在Heroku用户界面中单击“概述”,选择“配置附件”,搜索“ Postgres”; 选择“ Heroku Postgres”。 我为此演示使用免费版本。
Now this database is already attached to the app image-recommender-demo! You can see it now under “Settings”, “Config Vars” with its URL.
现在,此数据库已附加到应用程序image-recommender-demo ! 您现在可以在“设置”,“配置变量”及其URL下看到它。
If psycopg2 was not yet installed Heroku will tell us again an error and the logs reveal that the module “psycopg2” was not found. Therefore, psycopg2==2.8.5 in the requirements.txt file gets the right package.
如果尚未安装psycopg2,则Heroku会再次告诉我们一个错误,并且日志显示未找到模块“ psycopg2”。 因此,在requirements.txt文件psycopg2 == 2.8.5得到正确的包。
The tables still do not exist, so we will still see an error after this adjustment on Heroku.
这些表仍然不存在,因此在Heroku上进行此调整后,我们仍然会看到错误。
To create the missing tables and import some data we use the commands from the command.py file explained earlier.
为了创建丢失的表并导入一些数据,我们使用前面解释的来自command.py文件的命令 。
We shall set the FLASK_APP variable such that the commands are recognized in the Heroku con
我们将设置FLASK_APP变量,以便在Heroku con中识别命令
heroku config:set FLASK_APP=run.py --app image-recommender-demoNow we can call the console in Heroku and use the commands presented earlier
现在我们可以在Heroku中调用控制台并使用前面介绍的命令
flask createDB
flask importDBThat’s it, the application is deployed, online and the database contains relevant data!
就是这样,应用程序已在线部署并且数据库包含相关数据!
8.结论 (8. Conclusions)
With this and the PyTorch recommender post you have everything at hand to
有了这个和PyTorch推荐器帖子,您就可以掌握一切
- Run machine learning code offline and store the results 离线运行机器学习代码并存储结果
- Create a Flask based web application 创建基于Flask的Web应用程序
- Use the machine learning results in the web application 在Web应用程序中使用机器学习结果
- Use a PostgreSQL database with Flask 在Flask中使用PostgreSQL数据库
- Deploy your application to Heroku 将您的应用程序部署到Heroku
You are not bound to use these programming insights for this particular demo app, you can become creative with other ideas once you understood all the steps.
您不必一定要针对特定的演示应用程序使用这些编程见解,一旦您理解了所有步骤,就可以在其他想法中发挥创意。
There are still further aspects to be considered as described in my last article to aim for production.
如我的上一篇文章所述,还有其他方面可以考虑用于生产。
We could invest some more work and make the recommendations itself an API service with suitable endpoints for adding, deleting, and updating the entries.
我们可以投入更多的工作,并使建议本身成为具有适当端点的API服务,用于添加,删除和更新条目。
This kind of service could be a part of a production system like a larger online shop. Note that in this case the images should be moved from the static folder to for example some object storage.
这种服务可能是生产系统(例如较大的网上商店)的一部分。 请注意,在这种情况下,应将图像从静态文件夹移至某些对象存储。
谢谢阅读! 喜欢这个话题吗? (Thanks for reading! Liked the topic?)
If you found the read interesting, you might want to catch up on two of my previous articles on the topic that this article extends upon:
如果您发现阅读内容很有趣,那么您可能想补习一下我之前关于该主题扩展的两篇文章:
pytorch flask















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









