





nlp自然语言处理应用
“Recipe Guru” uses NLP technologies to recommend similar recipes to the ones one might like, currently based on 18000 recipes out of Recipe 1M+. Under the hood, this web app uses Recipe 1M+ data and natural language processing (NLP) models to recommend recipes based on the ones the user likes.
“食谱大师”使用NLP技术来推荐与可能喜欢的食谱类似的食谱,目前基于1M +食谱中的18000种食谱。 在后台,此Web应用程序使用Recipe 1M +数据和自然语言处理(NLP)模型来根据用户喜欢的菜谱推荐菜谱。
It uses a similarity matrix to document similarities between recipes based on title, ingredients, and instructions. Bag of Words (BoW), Doc2Vec, and BERT (Bidirectional Encoder Representations from Transformers) models are used to estimate degrees of similarities between recipes and provide recipe recommendations. (Here is my medium blog post that talks about BERT and other recent NLP technologies, including XLNet. )
它使用相似性矩阵根据标题,成分和说明来记录配方之间的相似性。 单词袋(BoW),Doc2Vec和BERT(来自变压器的双向编码器表示)模型用于估计配方之间的相似度并提供配方建议。 (这是我的中级博客文章 ,讨论了BERT和其他最近的NLP技术,包括XLNet。)
关于数据集 (About the Data Set)
For this project, I used the Recipe 1M+ dataset from MIT researchers: a new large-scale, structured corpus of over one million cooking recipes and 13 million food images. The dataset can be used for NLP and CV projects. Here, we focus on the text recipes (comes in JSON) that include the following information: the recipe URL, title, id, ingredients, and instructions.
在这个项目中,我使用了麻省理工学院研究人员的Recipe 1M +数据集 :一个新的大规模结构化语料库,包含超过一百万种烹饪食谱和一千三百万种食物图像。 该数据集可用于NLP和CV项目。 在这里,我们重点介绍包含以下信息的文本食谱(JSON中的内容):食谱URL,标题,ID,成分和说明。
The preprocessing step combines title, ingredients, and instruction into one string for each of the 1M+ recipes and different Natural Language Processing techniques are applied on the clean dataset to generate embeddings and cosine similarity matrix.
对于每个1M +配方,预处理步骤将标题,成分和说明组合为一个字符串,并且在干净的数据集上应用了不同的自然语言处理技术以生成嵌入和余弦相似度矩阵。
余弦相似度矩阵 (Cosine Similarity Matrices)
Due to the large size of the cosine similarity matrix, rather than using the sklearn function “metrics.pairwise_distances” and scipy’s “spatial.distance.cosine” to get pairwise cosine similarity, I used TensorFlow and GPU to speed up the cosine similarity matrix calculation and also tried using Spark distributed computing.
由于余弦相似度矩阵的大小很大,而不是使用sklearn函数“ metrics.pairwise_distances”和scipy的“ spatial.distance.cosine”来获得成对的余弦相似度,我使用TensorFlow和GPU加快了余弦相似度矩阵的计算并尝试使用Spark分布式计算。
1.使用TensorFlow获取余弦相似度矩阵: (1. Getting the cosine similarity matrix with TensorFlow:)
import tensorflow as tf
# use tf rather than sklearn.metric
def compute_cosine_distances(a, b):
# x shape is n_a * dim
# y shape is n_b * dim
# results shape is n_a * n_b
normalize_a = tf.nn.l2_normalize(a,1)
normalize_b = tf.nn.l2_normalize(b,1)
distance = 1 - tf.matmul(normalize_a, normalize_b, transpose_b=True)
return distance
# similarity matrix (tensorflow.python.framework.ops.EagerTensor)
sim_matrix = 1 - compute_cosine_distances(recipes_vector, recipe_vector) # recipe vector shape: (18000, 5200)
sim_matrix = np.array(sim_matrix)
# replace all perfect matches (match with itself) to zero, fill diag with 0
# so the recipe closest to the target recipe won't be itself during ranking
np.fill_diagonal(sim_matrix, 0)
# for the 1st recipe, check sim_matrix[0]
recipe1 = sim_matrix[0]
# get the index of the top N recipes recommendations based of their closeness to recipe1
most_similar_recs = np.argpartition(recipe1, -N)[-N:]One side note about storing the large cosine similarity matrix (a few GB for a 20k * 20k matrix with information on 20k recipes), one way to efficiently store it is to keep the indices of non-zero entries by converting the matrix into a sparse matrix. You can check out more about handling sparse matrices in the SciPy docs.
关于存储大余弦相似度矩阵的注意事项(20k * 20k矩阵需要几GB的信息,其中包含20k配方的信息),有效存储它的一种方法是通过将矩阵转换为稀疏矩阵来保持非零项的索引矩阵。 您可以在SciPy文档中查看有关处理稀疏矩阵的更多信息。
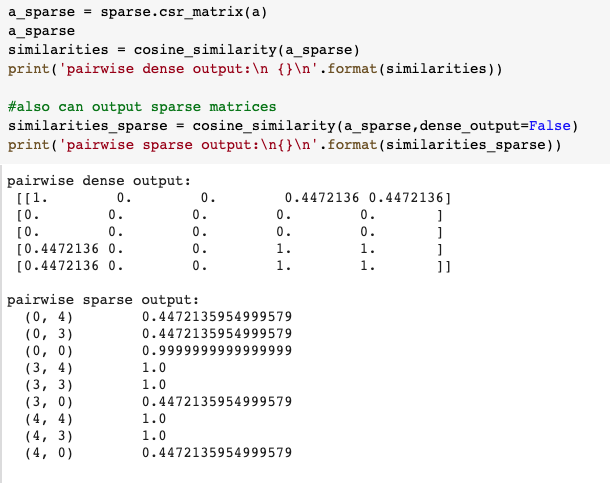
Since I am going to deploy the web app along with the pickled cosine similarity matrices, I am concerned about the large file sizes (1–2 GB). So before converting to csr_matrix, I set the similarity score of recipes with the target recipe to 0 if the score is not in the top 10. Then we only need to pickle ~recipe_num * 10 elements in the compressed sparse row formatted matrix. The file size goes from 1.67 GB to 2 MB :D. By the way, I ran into this medium post today on his journey of pickling large NLP data files, hopefully, it can also help you if you are facing similar deployment issues.
由于我将与腌制的余弦相似度矩阵一起部署Web应用程序,因此我担心文件较大(1-2 GB)。 因此,在转换为csr_matrix之前,如果得分不在前10位,则将与目标配方的相似度设置为0。然后,只需在压缩的稀疏行格式矩阵中腌制〜recipe_num * 10个元素即可。 文件大小从1.67 GB到2 MB:D。 顺便说一句,我就遇到了这个介质后的今天他的酸洗大NLP的数据文件,希望它也可以帮助你,如果你正面临类似的部署问题的旅程。
sparse.csr_matrix(sim_matrix)
# <18000x18000 sparse matrix of type '<class 'numpy.float32'>' with 202073252 stored elements in Compressed Sparse Row format># Let's keep top 10 elements of each row whose indices are of the recipes to be recommended.for i in range(len(sim_matrix)): row = sim_matrix[i] # cos sim of top 10th element threshold = heapq.nlargest(10, row)[-1]
row[row < threshold] = 0sparse.csr_matrix(sim_matrix)
# <18000x18000 sparse matrix of type '<class 'numpy.float32'>' with 202070 stored elements in Compressed Sparse Row format>2.使用PySpark计算余弦相似度: (2. Using PySpark to compute the Cosine similarities:)
Using distributed computing with PySpark in Colab using the following code:
使用以下代码在Colab中使用PySpark进行分布式计算:
# Runing Pyspark in Google Colab
!apt-get install openjdk-8-jdk-headless -qq > /dev/null
!wget -q http://apache.mirror.amaze.com.au/spark/spark-3.0.0/spark-3.0.0-bin-hadoop2.7.tgz
!tar xf spark-3.0.0-bin-hadoop2.7.tgz
!pip install -q findspark
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/content/spark-3.0.0-bin-hadoop2.7"
import pyspark
sc = pyspark.SparkContext(appName="doc2vec")
from pyspark.mllib.linalg.distributed import RowMatrix
# Convert to RowMatrix
rows = sc.parallelize(embeddings[:18000].T)
mat = RowMatrix(rows)
# Calculate exact and approximate similarities
spark_sim = mat.columnSimilarities()
# Output
spark_sim.entries.collect()To get the similarity matrices, three different NLP methods are used to represent the recipes:
为了获得相似性矩阵,使用三种不同的NLP方法来表示配方:
- Bag of words. 袋的话。
- Doc2Vec. Doc2Vec。
- BERT. BERT。
We will discuss these three methods in the following section.
我们将在下一节讨论这三种方法。
First, let’s take a peek at the main functionality of “Recipe Guru”:
首先,让我们看一下“ Recipe Guru”的主要功能:
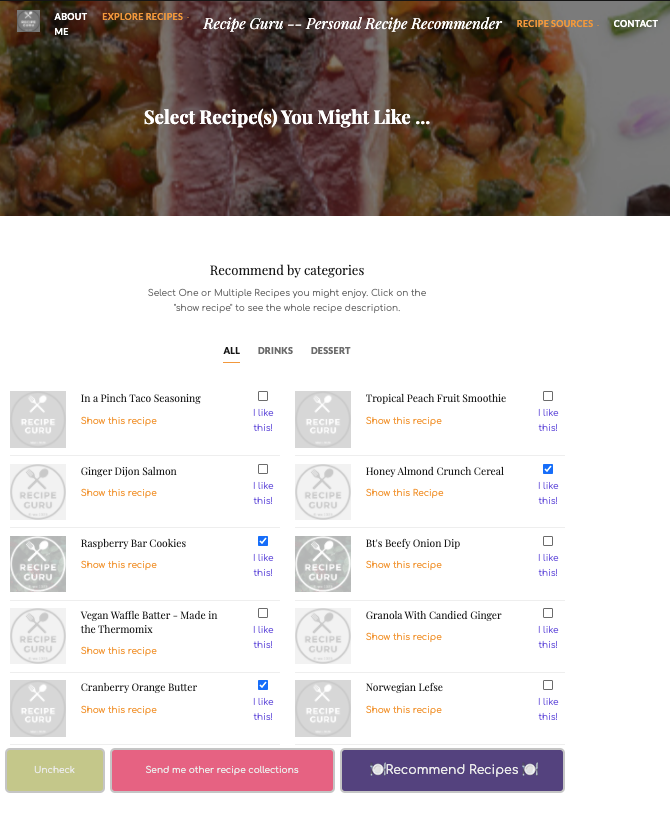
The main app first provides 10 randomly selected recipes from Recipe 1M+ dataset. The user can select one or more recipes and ask for recommendations. He or she can also ask for other recipe collections until seeing the ones that are interesting.
主应用程序首先从Recipe 1M +数据集中提供10个随机选择的食谱。 用户可以选择一个或多个食谱并提出建议。 他或她还可以要求其他食谱集合,直到看到有趣的集合为止。
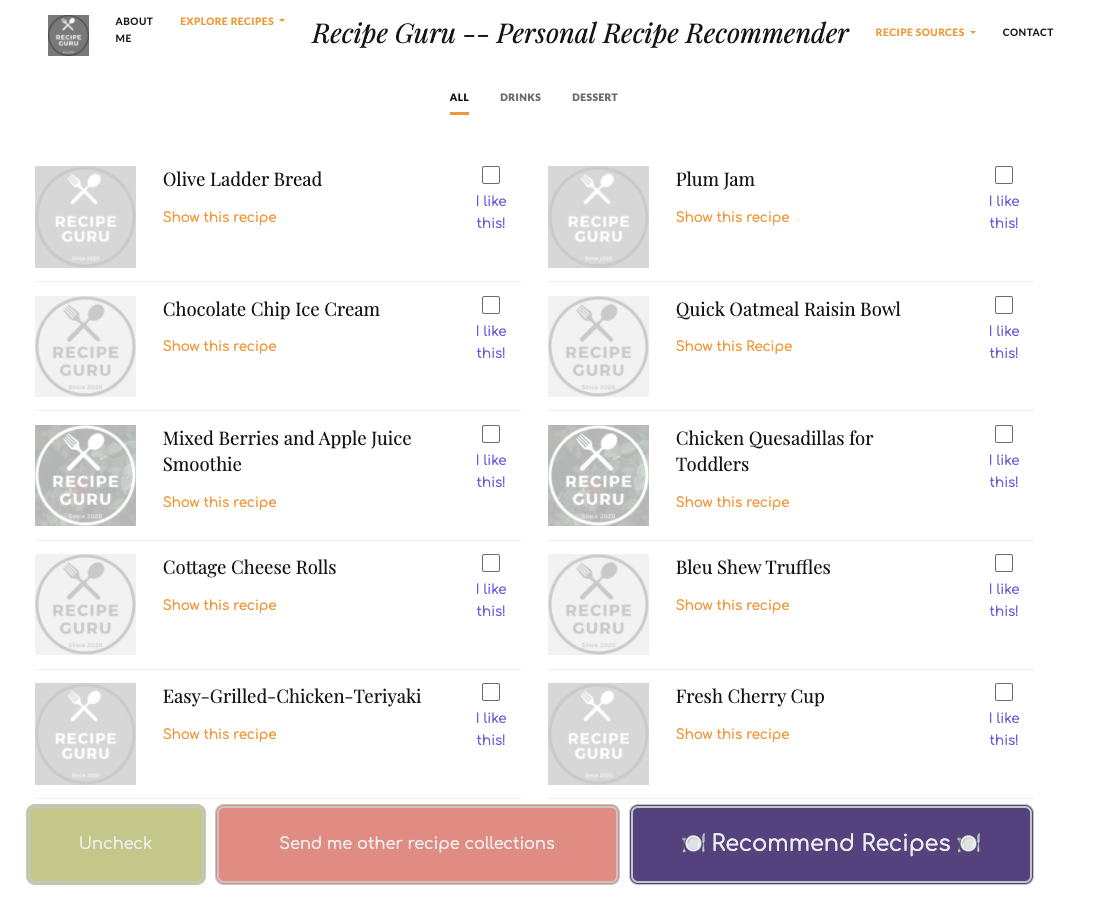
Here if we select “Chicken Teriyaki”, the bag of words model will bring us the following choices which you can continue selecting, based on these, the web app will push new recipe recommendations. As you can see, the suggested recipes are similar to the original choice.
在这里,如果我们选择“ Chicken Teriyaki”,单词袋模型将为我们带来以下选择,您可以继续选择这些选择,基于这些选择,Web应用程序将推送新的食谱建议。 如您所见,建议的食谱与原始选择相似。
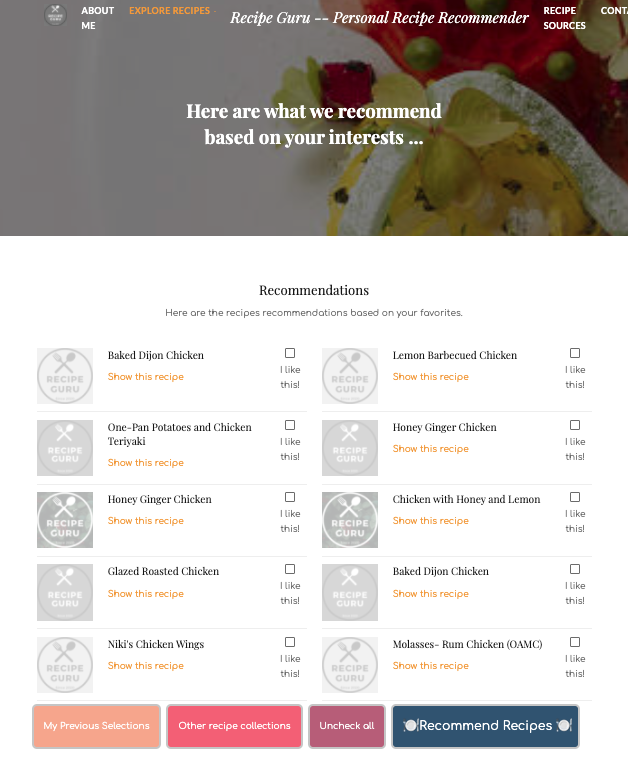
In the following example, I will pick 3 recipes I like and see what we will get:
在以下示例中,我将选择3个我喜欢的食谱,然后看看会得到什么:
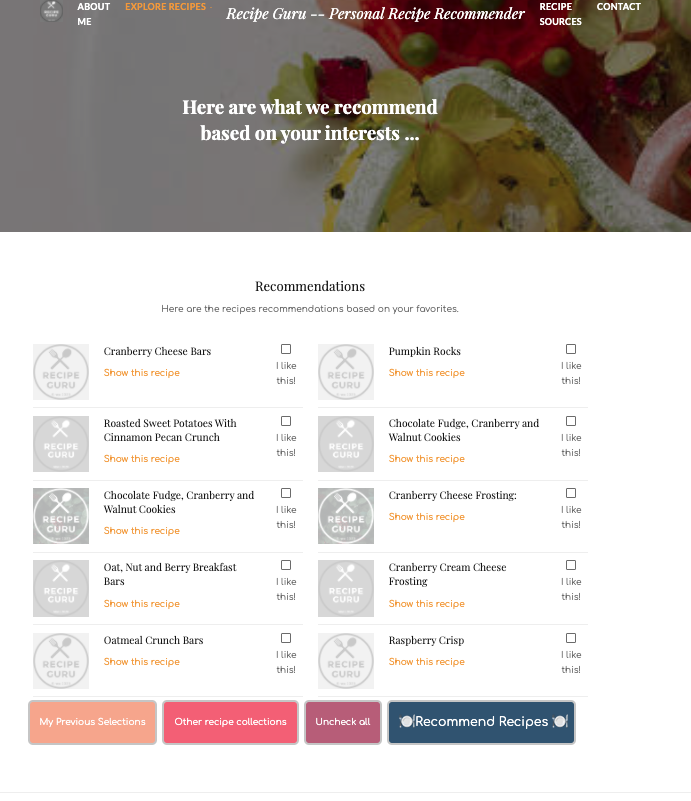
Nice, the recommended recipes are mostly desserts as well. The BoW is simple and effective in measuring the similarity of short text from different recipes using the BoW vector representation. In particular, the Count Vectorizer method is used to represent the recipes. One shortcoming, however, of BoW is that it loses information about the word order. I did not use bag of n-grams model which could help to capture local word order because of data sparsity and high dimensionality.
很好,推荐的食谱大多也是甜点。 BoW使用BoW向量表示,可以轻松有效地测量来自不同配方的短文本的相似性。 特别是,使用Count Vectorizer方法来表示配方。 但是,BoW的一个缺点是它会丢失有关单词顺序的信息。 由于数据稀疏性和高维性,我没有使用可帮助捕获本地单词顺序的n-gram袋模型。
Doc2Vec is another option to measure the similarity between two documents using unsupervised learning. It represents each document as a vector and provides a numerical representation of a text document. Unlike word2vec that represents word concepts, doc2vec generates vectors that attempt to represent the concept of the documents using fixed-length vectors for each document. Here, a different subset of the Recipe 1M+ data than the ones used by Doc2Vec is used, also including 18k recipes. The method is also fairly straightforward. I used Gensim’s Doc2Vec class to train on the dataset and get the embeddings, with a hidden layer size of 512 during training. The resulted matrix has a dimension of 1028702 * 512. For this project, I took the first 18k rows from the matrix as the embeddings for the recipes included in the Doc2Vec recipe recommender.
Doc2Vec是使用无监督学习来度量两个文档之间相似度的另一种选择。 它将每个文档表示为矢量,并提供文本文档的数字表示。 与代表单词概念的word2vec不同,doc2vec生成用于尝试使用每个文档的固定长度矢量表示文档概念的矢量。 在这里,使用的食谱1M +数据子集与Doc2Vec使用的子集不同,还包括18k食谱。 该方法也相当简单。 我使用Gensim的Doc2Vec类在数据集上进行训练并获得嵌入,在训练过程中隐藏层大小为512。 结果矩阵的尺寸为1028702 *512。对于该项目,我从矩阵的前18k行中提取了Doc2Vec食谱推荐器中所包含的食谱。
Unlike BoW’s recommendation which shows similar or identical words in the recipe names, Doc2Vec recommendations are more diverse. Here is an example:
BoW的建议在配方名称中显示相似或相同的单词,而Doc2Vec的建议则更加多样化。 这是一个例子:
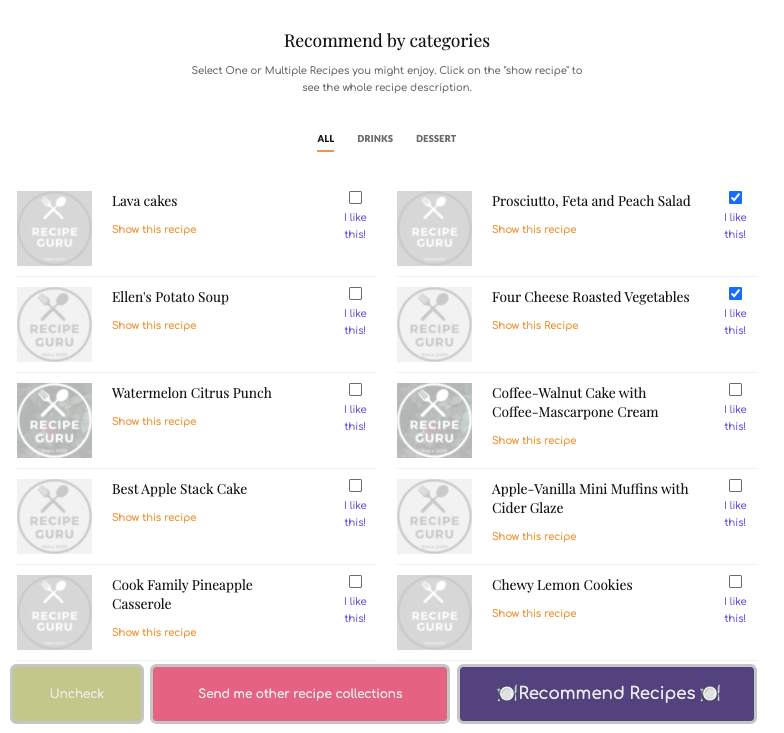
Here are the recommendations based on “Prosciutto, Feta and Peach Salad” and “Four Cheese Roasted Vegetables”. We can spot similarities more in terms of the recipe context/semantics.
以下是基于“意大利熏火腿,羊乳酪和桃色拉”和“四种奶酪烤蔬菜”的建议。 在配方上下文/语义方面,我们可以发现更多相似之处。
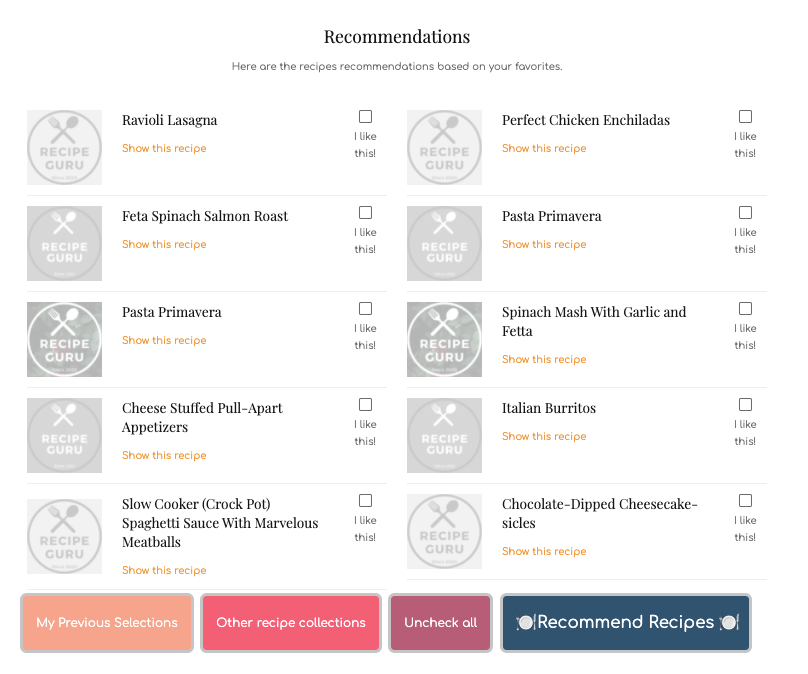
More on BERT to come while I am finalizing the app :D..
在我完成应用程序最终确定时,将会有更多关于BERT的信息:..
工作流程中的一些注意事项 (Some notes on the workflow)
The following standard Lang class is used to create a dictionary of words from the original recipes. It is useful in preprocessing the recipe sentence data.
以下标准Lang类用于从原始配方中创建单词词典。 在预处理配方语句数据中很有用。
class Lang:
def __init__(self, name):
# initialize containers to hold the words and corresponding index
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
def addSentence(self, sentence):
# split a sentence into words and add them to the container
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
# If the word is not in the container, the word will be added to it:
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
# else, update the word counter
else:
self.word2count[word] += 1For this project, Layer1.json file from Recipe 1M+ is used. The preliminary exploratory analysis shows there are 1029720 recipes, and the following plot shows the histogram of the number of words in recipes.
对于此项目,使用配方1M +中的Layer1.json文件。 初步探索性分析显示,有1029720个食谱,下图显示了食谱中单词数的直方图。
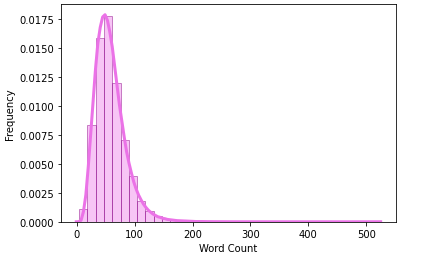
For the ease of analysis, 1029662 recipes with less than 300 words are used in downstream processing.
为了便于分析,在下游处理中使用了少于300个单词的1029662个配方。
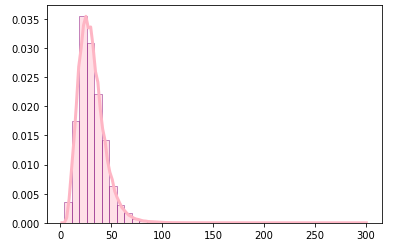
“det_ingrs.json” provides nutritional information on 51213 recipes, which I will be incorporating in the next step of the web app, so users can filter recipes based on nutritional requirements.
“ det_ingrs.json”提供了有关51213食谱的营养信息,我将在下一步的Web应用程序中纳入这些信息,因此用户可以根据营养需求过滤食谱。
The “Recipe Guru” web app is built using Flask.
“ Recipe Guru”网络应用是使用Flask构建的。
翻译自: https://towardsdatascience.com/recipe-guru-a-recipe-recommendation-web-app-based-on-nlp-a3290d79da2f
nlp自然语言处理应用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









