





php 数据表每月统计数据
重点 (Top highlight)
Any data scientist can glean information from a dataset — any good data scientist will know that it takes a solid statistical underpinning to glean useful and reliable information. It’s impossible to perform quality data science without it.
任何数据科学家都可以从数据集中收集信息-任何优秀的数据科学家都将知道,扎实的统计基础可以收集有用和可靠的信息。 没有它,就不可能进行高质量的数据科学。
But statistics is a huge field! Where do I start?
但是统计是一个巨大的领域! 我从哪说起呢?
Here are the top five statistical concepts every data scientist should know: descriptive statistics, probability distributions, dimensionality reduction, over- and under-sampling, and Bayesian statistics.
以下是每个数据科学家都应该知道的前五个统计概念:描述性统计,概率分布,降维,过采样和欠采样以及贝叶斯统计。
Let’s start with the most simple one.
让我们从最简单的一个开始。
描述性统计 (Descriptive statistics)
You’re sitting in front of a dataset. How can you get a high-level description of what you’ve got? Descriptive statistics is the answer. You’ve probably heard of some of these: mean, median, mode, variance, standard deviation …
您正坐在数据集的前面。 您如何对所拥有的东西进行高级描述? 描述性统计就是答案。 您可能已经听说过其中的一些: 平均值 , 中位数 , 众数 , 方差 , 标准差 …
These will quickly identify key features of your dataset and inform your approach no matter the task. Let’s take a look at some of the most common descriptive stats.
这些将快速识别您的数据集的关键特征,并在您执行任务时通知您的方法。 让我们看一些最常见的描述性统计数据。
意思 (Mean)
The mean (also known as “expected value” or “average”) is the sum of values divided by the number of values. Take this example set:
平均值(也称为“期望值”或“平均值”)是值的总和除以值的数量。 采取以下示例集:

The mean is calculated as follows:
平均值计算如下:
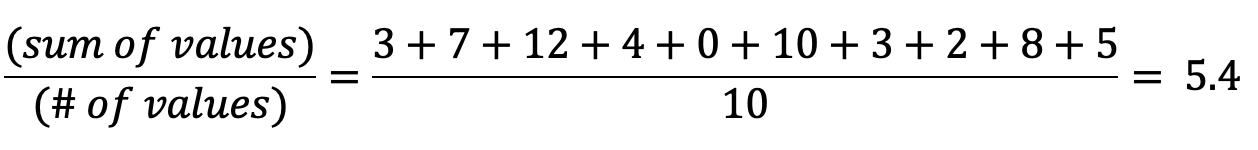
中位数 (Median)
List your values in ascending (or descending) order. The median is the point that divides the data in half. If there are two middle numbers, the median is the mean of these. In our example:
以升序(或降序)列出您的值。 中位数是将数据分成两半的点。 如果有两个中间数字,则中位数是这些数字的平均值。 在我们的示例中:
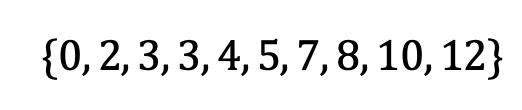
The median is 4.5.
中位数为4.5。
模式 (Mode)
The mode is the most frequent value(s) in your dataset. In our example, the mode is 3.
模式是数据集中最频繁的值。 在我们的示例中,模式为3。
方差 (Variance)
The variance measures the spread of a dataset with respect to the mean. To calculate the variance, subtract the mean from each value. Square each difference. Finally, calculate the mean of those resulting numbers. In our example:
方差衡量数据集相对于均值的分布。 要计算方差,请从每个值中减去平均值。 平方每个差异。 最后,计算这些结果数字的平均值。 在我们的示例中:

标准偏差 (Standard deviation)
The standard deviation measures overall spread and is calculated by taking the square root of the variance. In our example:
标准差用于衡量总体价差,并通过求出方差的平方根来计算。 在我们的示例中:
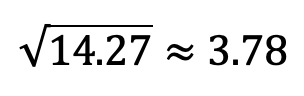
Other descriptive statistics include skewness, kurtosis, and quartiles.
其他描述性统计数据包括偏度 , 峰度和四分位数 。
概率分布 (Probability distributions)
A probability distribution is a function that gives the probability of occurrence for every possible outcome of an experiment. If you’re picturing a bell curve, you’re on the right track. It shows, at a glance, how the values of a random variable are dispersed. Random variables, and therefore distributions, can be either discrete or continuous.
概率分布是一种函数,它给出实验每个可能结果的出现概率。 如果您正在绘制钟形曲线,那您就走对了。 乍一看,它显示了如何分散随机变量的值。 随机变量及其分布可以是离散的也可以是连续的。
离散的 (Discrete)
John is a baseball player who has a 50% random chance of hitting the ball each time it is pitched to him. Let’s throw John three pitches and see how many times he hits the ball. Here is a list of all the possible outcomes:
约翰是一名棒球运动员,每次向他投球时,都有50%的随机击球机会。 让我们向约翰投三个球,看看他有多少次击球。 以下是所有可能结果的列表:

Let X be our random variable, the number of times John gets a hit in the three-pitch experiment. The probability of John getting n hits is represented by P(X= n). So, X can be 0, 1, 2, or 3. If all eight of the above outcomes are equally likely, we have:
令X为我们的随机变量,即约翰在三音高实验中被击中的次数。 约翰获得n次点击的概率由P(X = n)表示。 因此,X可以为0、1、2或3。如果上述所有八个结果均具有相同的可能性,则我们有:
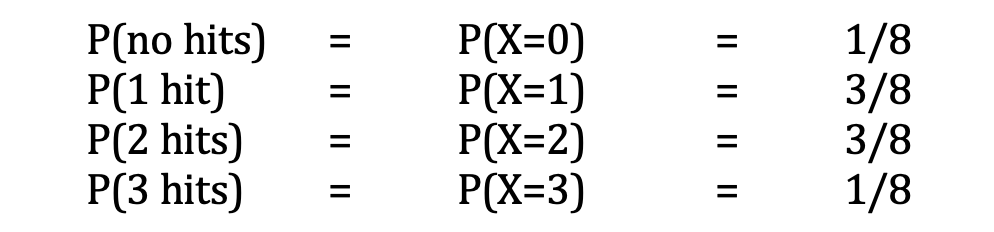
Replace P with f and we’ve got our probability function! Let’s graph it.
用f代替P,我们就有了概率函数! 让我们来画一下。
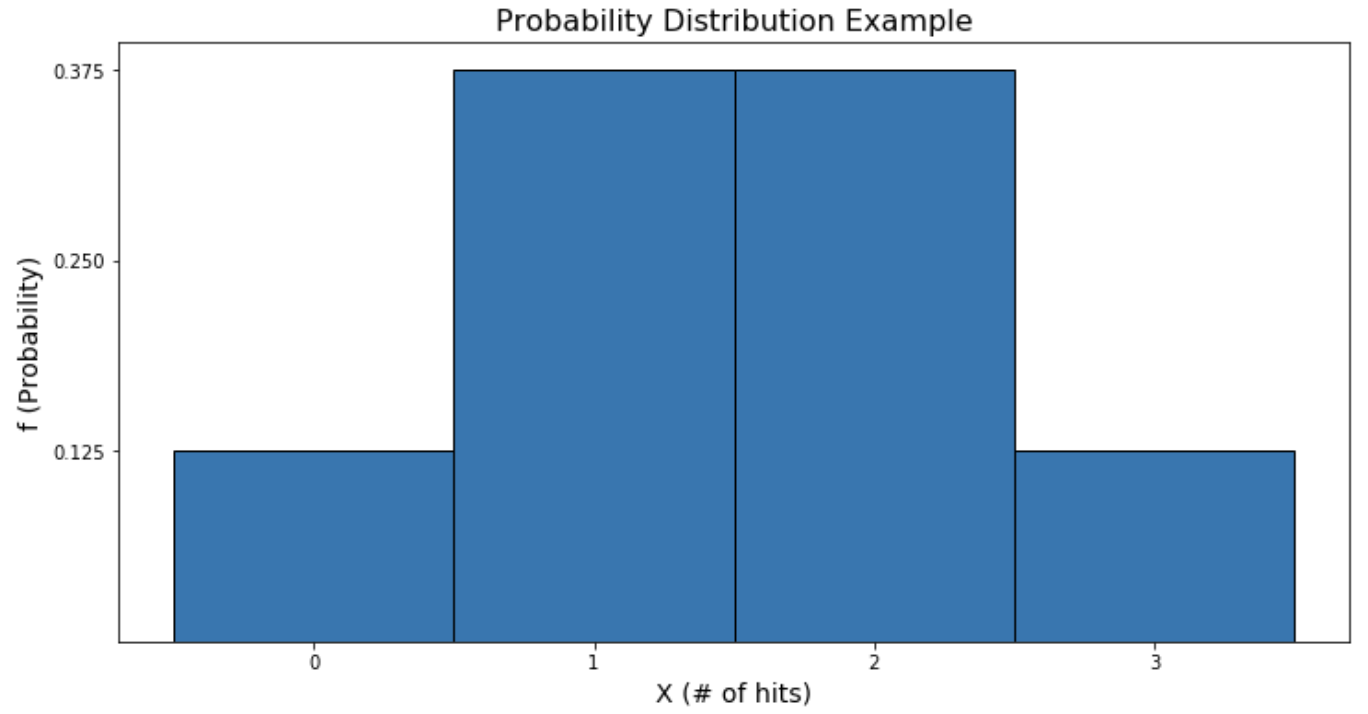
From the graph, we see that it is more likely for John to get 1 or 2 hits than it is for him to get 0 or 3, because the graph is taller for those values of X. Common discrete distributions include Bernoulli, binomial, and Poisson.
从图中可以看出,John获得1或2次命中的可能性比获得0或3次命中的可能性更大,因为对于X的那些值,图表更高。 常见的离散分布包括伯努利 , 二项式和泊松 。
连续 (Continuous)
The continuous case follows naturally from the discrete case. Instead of counting hits, our random variable could be the time the baseball is in the air. Rather than just one, two, or three seconds, we can have values like 3.45 seconds or 6.98457 seconds.
连续情况自然而然地来自离散情况。 除了计算命中率外,我们的随机变量可能是棒球播出的时间。 我们可以将值设置为3.45秒或6.98457秒,而不只是一秒,两秒或三秒。
We’re talking about a set of infinitely many possibilities. Other examples of continuous variables are height, time, and temperature. Common continuous distributions include normal, exponential, and Chi-squared.
我们正在谈论一系列无限的可能性。 连续变量的其他示例是高度,时间和温度。 常见的连续分布包括正态 , 指数和卡方 。
降维 (Dimensionality reduction)
If you have too many input variables or your data are computationally unwieldy, you may turn to dimensionality reduction. This is the process of projecting high-dimensional data into a lower-dimensional space, but it is important to be mindful not to lose important features of the original dataset.
如果输入变量太多或数据计算笨拙,则可以转向降维。 这是将高维数据投影到低维空间中的过程,但是请务必注意不要丢失原始数据集的重要特征。
For example, suppose you are trying to determine what factors best predict whether or not your favorite basketball team will win their game tonight. You may collect data such as their win percentage, who they’re playing, where they’re playing, who their starting forward is, what he ate for dinner, and what color shoe the coach is wearing.
例如,假设您正在尝试确定哪些因素可以最好地预测您最喜欢的篮球队今晚能否赢得比赛。 您可能会收集数据,例如他们的获胜百分比,他们在踢球,在哪里踢球,他们的前锋是谁,他吃晚饭的时间以及教练穿什么颜色的鞋子。
You might suspect that certain of these features are more correlated to winning than others. Dimensionality reduction could allow us to confidently drop information that will not contribute as meaningfully to the prediction while retaining features with the most predictive value.
您可能会怀疑其中某些功能比其他功能与获胜的相关性更高。 降维可以使我们放心地删除不会对预测做出有意义贡献的信息,同时保留具有最大预测价值的特征。
Principal Component Analysis (PCA) is a popular way to do this, and it works by exaggerating the variance of new combinations of features, called principal components. These new combinations are projections of the original data points into a new space — still the same dimension — where the variation is played up.
主成分分析(PCA)是一种流行的方法,它通过夸大称为主成分的要素的新组合的方差来工作。 这些新组合是原始数据点到新空间(仍是相同维度)的投影,其中会显示变化。
The general idea is that of these new components, those with the least variation can be most safely dropped. Dropping a single component will reduce the original dimensionality by one, dropping two components will reduce it by two, and so on.
通常的想法是,对于这些新组件,可以最安全地删除那些变化最小的组件。 删除单个组件将使原始尺寸减小一倍,删除两个组件将使尺寸减小两个,依此类推。
If you want to read more, here’s an entire article dedicated to PCA:
如果您想了解更多信息,请参阅整篇有关PCA的文章:
欠采样和过采样 (Under-sampling and Over-sampling)
A collective set of observations is called the “sample”, and the way that the set was collected is called “sampling”. In a classification situation where you need minority and majority classes to be equally represented, under- or over-sampling may be useful. Under-sampling the majority class or over-sampling the minority class can help even out an unbalanced dataset.
收集的一组观测值称为“样本”,而收集观测值的方式称为“采样”。 在需要平等代表少数派和多数派的分类情况下,欠采样或过采样可能会有用。 对多数类别进行欠采样或对少数类别进行过度采样可以帮助均衡不平衡的数据集。
Random over-sampling (alternatively, random under-sampling) involves randomly selecting and duplicating observations in the minority class (or randomly selecting and deleting observations in the majority class).
随机过采样(或者,随机欠采样)涉及在少数类中随机选择和复制观测值(或在多数类中随机选择和删除观测值)。
This is easy to implement, but you should proceed with caution: over-sampling weights the observations that are duplicated, which can heavily influence results if they were not unbiased, to begin with. Similarly, under-sampling runs the risk of deleting key observations.
这很容易实现,但是您应谨慎行事:对采样重复的观测值进行过采样加权,如果不加偏见,可能会严重影响结果。 同样,采样不足会带来删除关键观测值的风险。
One way to over-sample the minority class is the Synthetic Minority Over-sampling Technique (SMOTE). This creates (synthetic) minority class observations by creating new combinations of existing observations. For each observation in the minority class, SMOTE calculates its k nearest neighbors; that is, it finds the k minority class observations that are most like the observation.
少数群体过采样的一种方法是综合少数群体过采样技术(SMOTE) 。 这通过创建现有观测值的新组合来创建(综合)少数群体观测值。 对于少数群体类别中的每个观察, SMOTE会计算其k个最近的邻居; 也就是说,它找到最类似于该观测值的k个少数群体观测值。
Viewing observations as vectors, it creates random linear combinations by weighting any of the k nearest neighbors by a random number between 0 and 1 and adding it to the original vector.
通过将观察结果视为向量,它可以通过用0到1之间的随机数对k个最近邻居中的任何一个加权,并将其添加到原始向量中来创建随机线性组合。
One way to under-sample of the majority class is with cluster centroids. Similar in theory to SMOTE, it replaces groups of vectors by the centroid of their k nearest neighbors cluster.
多数类样本不足的一种方法是使用聚类质心。 从理论上讲,与SMOTE相似,它用k个最近邻居簇的质心代替向量组。
贝叶斯统计 (Bayesian statistics)
When it comes to statistical inference, there are two main schools of thought: frequentist statistics and Bayesian statistics. Frequentist statistics allows us to do meaningful work, but there are cases where it falls short. Bayesian statistics does well when you have reason to believe that your data may not be a good representation of what you expect to observe in the future.
在统计推断方面,主要有两种思想流派:常客统计和贝叶斯统计。 频繁的统计数据使我们能够进行有意义的工作,但是在某些情况下,它的工作还不够。 当您有理由相信您的数据可能无法很好地表示您希望将来观察到的数据时,贝叶斯统计量会很好。
This allows you to incorporate your own knowledge into your calculations, rather than solely relying on your sample. It also allows you to update your thoughts about the future after new data come in.
这使您可以将自己的知识整合到计算中,而不仅仅是依靠样本。 它还可以让您在收到新数据后更新对未来的看法。
Consider an example: Team A and Team B have played each other 10 times, and Team A has won 9 of those times. If the teams are playing each other tonight, and I ask you who you think will win, you’d probably say Team A! What if I also told you that Team B has bribed tonight’s referees? Well, then you might guess that Team B will win.
来看一个例子: A队和B队互相比赛10次,A队赢得9次。 如果今晚两队互相比赛,我问你认为谁会赢,你可能会说A队! 如果我还告诉您B队贿赂了今晚的裁判怎么办? 好吧,那您可能会猜猜B队会赢。
Bayesian statistics allows you to incorporate this extra information into your calculations, while frequentist statistics focuses solely on the 9 out of 10 win percentage.
贝叶斯统计允许您将这些额外的信息纳入您的计算中,而常客统计则仅关注10个获胜百分比中的9个。
Bayes’ Theorem is the key:
贝叶斯定理是关键:

The conditional probability of H given E, written P( H| E), represents the probability of H occurring given that E also occurs (or has occurred). In our example, H is the hypothesis that Team B will win, and E is the evidence that I gave you about Team B bribing the referees.
给定E的H的条件概率,写为P( H | E ),表示在E也出现(或已经发生)的情况下H发生的概率。 在我们的示例中, H是B队获胜的假设, E是我为您提供的有关B队贿赂裁判的证据。
P( H) is the frequentist probability, 10%. P( E| H) is the probability that what I told you about the bribe is true, given that Team B wins. (If Team B wins tonight, would you believe what I told you?)
P( H )是频繁出现概率,为10%。 P( E | H )是在B队获胜的情况下我告诉您的贿赂真实的概率。 (如果B队今晚获胜,您会相信我说的话吗?)
Finally, P( E) is the probability that Team B has in fact bribed the referees. Am I a trustworthy source of information? You can see that this approach incorporates more information than just the outcomes of the two teams’ previous 10 match-ups.
最后,P( E )是B队实际上贿赂裁判的概率。 我是值得信赖的信息来源吗? 您会看到,这种方法不仅包含了两支球队之前10场比赛的结果,还包含了更多信息。
And that’s it for today. Let’s wrap things up in the next section.
就是今天。 让我们在下一节中总结一下。
你走之前 (Before you go)
Learning these 5 concepts won’t make you a master of statistics or data science — but it is a great place to start if you can’t understand the basic flow of a data science project.
学习这5个概念并不能使您掌握统计学或数据科学知识,但是如果您不了解数据科学项目的基本流程,那么这是一个很好的起点。
If it still sounds like something advanced, my recommendation is to start small. Here’s the best introductory statistics book voted by me and many others:
如果听起来还有些高级,我的建议是从小做起。 这是我和其他许多人投票选出的最好的入门统计书:
And we’re done — thanks for reading.
我们已经完成了-感谢您的阅读。
Originally published at https://www.betterdatascience.com on August 29, 2020.
最初于 2020年8月29日 在 https://www.betterdatascience.com 上 发布 。
php 数据表每月统计数据















 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









