





kibana数据源定义
Discussion around ATT&CK often involves tactics, techniques, procedures, detections, and mitigations, but a significant element is often overlooked: data sources. Data sources for every technique provide valuable context and opportunities to improve your security posture and impact your detection strategy.
关于ATT&CK的讨论通常涉及战术,技术,程序,检测和缓解措施,但经常忽略一个重要因素:数据源。 每种技术的数据源都提供了宝贵的环境和机会,可以改善您的安全状况并影响您的检测策略。
This two-part blog series will outline a new methodology to extend ATT&CK’s current data sources. In this post, we explore the current state of data sources and an initial approach to enhance them through data modeling. We’ll define what an ATT&CK data source object represents and how we can extend it to introduce the concept of data components. In our next post we’ll introduce a methodology to help define new ATT&CK data source objects.
这个分为两部分的博客系列将概述扩展ATT&CK当前数据源的新方法。 在本文中,我们探讨了数据源的当前状态以及通过数据建模来增强数据源的初始方法。 我们将定义ATT&CK数据源对象代表什么,以及如何扩展它以引入数据组件的概念。 在我们的下一篇文章中,我们将介绍一种方法来帮助定义新的ATT&CK数据源对象。
The table below outlines our proposed data source object schema:
下表概述了我们建议的数据源对象架构:

今天在哪里查找数据源 (Where to Find Data Sources Today)
Data sources are featured as part of the (sub)technique object properties:
数据源是(sub)技术对象属性的一部分:

While the current structure only contains the names of the data sources, to understand and effectively apply these data sources, it is necessary to align them with detection technologies, logs, and sensors.
尽管当前结构仅包含数据源的名称,但是要理解和有效地应用这些数据源,必须将它们与检测技术,日志和传感器对齐。
改善ATT&CK中的当前数据源 (Improving the Current Data Sources in ATT&CK)
The MITRE ATT&CK: Design and Philosophy white-paper defines data sources as “information collected by a sensor or logging system that may be used to collect information relevant to identifying the action being performed, sequence of actions, or the results of those actions by an adversary”.
《 MITRE ATT&CK:设计和哲学》白皮书将数据源定义为“由传感器或测井系统收集的信息,可用于收集与识别正在执行的操作,操作序列或操作人员的结果相关的信息。对手”。
ATT&CK’s data sources provide a way to create a relationship between adversary activity and the telemetry collected in a network environment. This makes data sources one of the most vital aspects when developing detection rules for adversary actions mapped to the framework.
ATT&CK的数据源提供了一种在网络环境中创建对手活动与遥测之间建立关系的方法。 在为映射到框架的对手行为制定检测规则时,这使数据源成为最重要的方面之一。
Need some visualizations and audio track to help decipher the relationships between data sources and the number of techniques covered by them? My brother and I recently presented at ATT&CKcon on how you can explore more about data sources metadata and how to use sources to drive successful hunt programs.
需要一些可视化和音频轨道来帮助理解数据源与它们所涵盖的技术之间的关系吗? 我的兄弟和我最近在ATT&CKcon上发表了关于如何探索数据源元数据的更多信息以及如何使用源驱动成功的狩猎计划的演讲。

We categorized a number of ways to improve the current approach to data sources. Many of these are based on community feedback, and we’re interested in your reactions and comments to our proposed upgrades.
我们对改善当前数据源方法的方法进行了分类。 其中许多都是基于社区的反馈,我们对您对我们建议的升级的React和评论感兴趣。
1.开发数据源定义 (1. Develop Data Source Definitions)
Community feedback emphasizes that having definitions for each data source will enhance efficiency while also contributing to data collection strategy development. This will enable ATT&CK users to quickly translate data sources to specific sensors and logs in their environment.
社区反馈强调,对每个数据源都有定义将提高效率,同时也有助于数据收集策略的开发。 这将使ATT&CK用户能够快速将数据源转换为特定传感器并记录其环境中的日志。

2.标准化名称语法 (2. Standardize the Name Syntax)
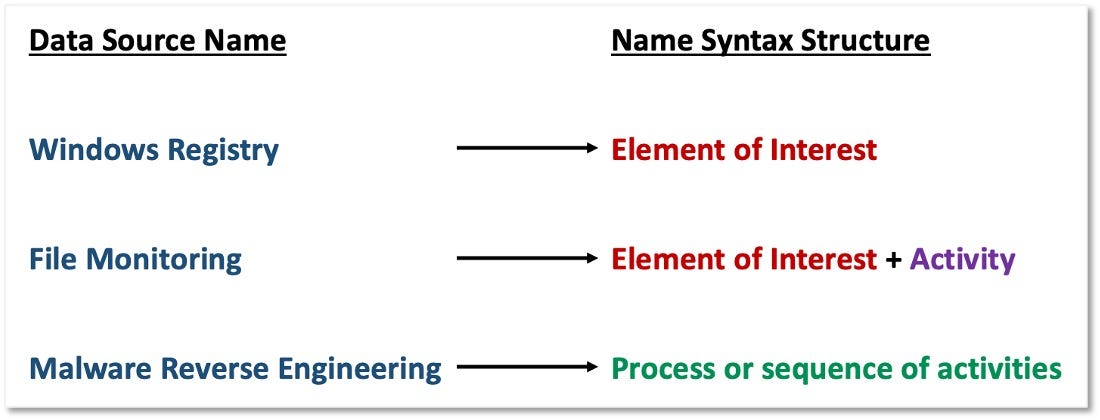
Standardizing the naming convention for data sources is another factor that came up during feedback conversations. As we outline in the image below, data sources can be interpreted differently. For example, some data sources are very specific, e.g., Windows Registry, while others, such as Malware Reverse Engineering, have a wider scope. We propose a consistent naming syntax structure that addresses explicitly defined elements of interest from the data being collected such as files, processes, DLLs, etc.
标准化数据源的命名约定是反馈对话期间出现的另一个因素。 正如我们在下图中所概述的,数据源可以有不同的解释。 例如,某些数据源是非常特定的,例如Windows注册表,而其他数据源(例如,恶意软件逆向工程)的范围更广。 我们提出了一个一致的命名语法结构,该结构可从正在收集的数据(例如文件,进程,DLL等)中解决显式定义的感兴趣的元素。
3.地址冗余和重叠 (3. Address Redundancy and Overlapping)
Another unintended consequence of not having a standard naming structure for data sources is redundancy, which can also lead to overlaps.
数据源没有标准命名结构的另一个意外结果是冗余,这也可能导致重叠。
Example A: Loaded DLLs and DLL monitoring
示例A:加载的DLL和DLL监视
The recommended data sources related to DLLs imply two different detection mechanisms; however, both techniques leverage DLLs being loaded to proxy execution of malicious code. Do we collect “Loaded DLLs” or focus on “DLL Monitoring”? Do we do both? Can they just be one data source?
与DLL相关的推荐数据源暗示了两种不同的检测机制。 但是,这两种技术都利用DLL加载来代理执行恶意代码。 我们是收集“已加载的DLL”还是专注于“ DLL监视”? 我们都做吗? 它们可以只是一个数据源吗?


Example B: Collecting process telemetry
示例B:收集过程遥测
All of the information provided by Process Command-line Parameters, Process use of Network, and Process Monitoring refer to a common element of interest, a process. Do we consider that “Process Command-Line Parameters” could be inside of “Process Monitoring”? Can “Process Use of Network” also cover “Process Monitoring” or could it be an independent data source?
进程命令行参数,网络的进程使用和进程监视所提供的所有信息均指的是所关注的公共元素,即进程 。 我们是否认为“过程命令行参数”可能在“过程监视”内部? “网络的过程使用”是否也可以涵盖“过程监视”,或者它可以是独立的数据源?

Example C: Breaking down or aggregating Windows Event Logs
示例C:分解或汇总Windows事件日志
Finally, data sources such as “Windows Event Logs” have a very broad scope and cover several other data sources. The image below shows some of the data sources that can be grouped under event logs collected from Windows endpoints:
最后,诸如“ Windows事件日志”之类的数据源范围非常广泛,并涵盖了其他几个数据源。 下图显示了一些数据源,可以将这些数据源归类为从Windows端点收集的事件日志:

ATT&CK recommends collecting events from data sources such as PowerShell Logs, Windows Event Reporting, WMI objects, and Windows Registry. However, these could be already covered by “Windows Event Logs” as previously shown. Do we group every Windows data source under “Windows Event Logs” or keep them all as independent data sources?
ATT&CK建议从数据源(例如PowerShell日志,Windows事件报告,WMI对象和Windows注册表)收集事件。 但是,如先前所示,“ Windows事件日志”可能已经涵盖了这些内容。 我们是否将每个Windows数据源归入“ Windows事件日志”下或将它们全部保留为独立的数据源?

4.确保平台一致性 (4. Ensure Platform Consistency)
There are also data sources that, from a technique’s perspective, are linked to platforms where they can’t feasibly be collected. For example, the image below highlights data sources related to the Windows platform such as PowerShell logs and Windows Registry given for techniques that can be also used on other platforms such as macOS and Linux.
从技术的角度来看,还有一些数据源已链接到无法进行可行收集的平台。 例如,下图突出显示了与Windows平台相关的数据源,例如PowerShell日志和Windows注册表,这些数据源提供了也可以在其他平台(例如macOS和Linux)上使用的技术。

This issue has been addressed to a degree by the release of ATT&CK’s sub-techniques. For instance, in the image below you can see a description of the OS Credential Dumping (T1003) technique, the platforms where it can be performed, and the recommended data sources.
ATT&CK的子技术的发布在一定程度上解决了这个问题。 例如,在下面的图像中,您可以查看OS凭据转储(T1003)技术的说明,可以执行此操作的平台以及推荐的数据源。

While the field presentation could still lead us to relate PowerShell logs data source to non-Windows platform, once we start digging deeper into sub-technique details, the association between PowerShell logs and non-Windows platforms disappears.
尽管现场演示仍可以使我们将PowerShell日志数据源与非Windows平台相关联,但是一旦我们开始更深入地研究子技术细节,PowerShell日志与非Windows平台之间的关联就会消失。

Defining the concept of platforms at a data source level would increase the effectiveness of collection. This could be accomplished by upgrading data sources from a simple property or field value to the status of an object in ATT&CK, similar to a (sub)technique.
在数据源级别定义平台的概念将提高收集的有效性。 这可以通过将数据源从简单属性或字段值升级到ATT&CK中的对象状态来完成,类似于(子)技术。
一种提议的更新ATT&CK数据源的方法 (A Proposed Methodology to Update ATT&CK’s Data Sources)
Based on feedback from the ATT&CK community, it made sense to start providing definitions for each ATT&CK data source. However, we realized right away that without a structure and a methodology to describe data sources, definitions would be a challenge. Even though it was simple to describe data sources such as “Process Monitoring”, “File Monitoring”, “Windows Registry” and even “DLL Monitoring”, data source descriptions for “Disk Forensics”, “Detonation Chamber” or “Third Party Application Logs” are more complex.
根据ATT&CK社区的反馈,开始为每个ATT&CK数据源提供定义是有意义的。 但是,我们马上意识到,没有一种描述数据源的结构和方法,定义将是一个挑战。 即使描述诸如“过程监视”,“文件监视”,“ Windows注册表”甚至“ DLL监视”之类的数据源,“磁盘取证”,“引爆室”或“第三方应用程序”的数据源描述非常简单日志”更为复杂。
We ultimately recognized that we needed to apply data concepts that could help us provide more context to each data source in an organized and standardized way. This would allow us to also identify potential relationships among data sources and improve the mapping of adversary actions to data that we collect.
我们最终认识到我们需要应用数据概念,以帮助我们以一种有组织的标准化方式为每个数据源提供更多的上下文。 这也将使我们能够识别数据源之间的潜在关系,并改善对手行动与我们收集的数据之间的映射。
Our methodology for upgrading ATT&CK’s data sources is captured in the following six ideas:
以下六个方面介绍了我们升级ATT&CK数据源的方法:
1.利用数据建模 (1. Leverage Data Modeling)
A data model is a collection of concepts for organizing data elements and standardizing how they relate to one another. If we apply this basic concept to security data sources, we can start identifying core data elements that could be used to describe a data source in a more structured way. Furthermore, this will help us to identify relationships among data sources and enhance the process of capturing TTPs from adversary actions.
数据模型是概念的集合,用于组织数据元素并标准化它们之间的关系。 如果我们将此基本概念应用于安全数据源,则可以开始识别可用于以更结构化的方式描述数据源的核心数据元素。 此外,这将有助于我们识别数据源之间的关系,并增强从敌手行动中捕获TTP的过程。
Here is an initial proposed data model for ATT&CK data sources:
这是ATT&CK数据源的最初建议的数据模型:

Based on this notional model, we can begin to identify relationships between data sources and how they apply to logs and sensors. For example, the image below represents several data elements and relationships identified while working with Sysmon event logs:
基于此概念模型,我们可以开始识别数据源之间的关系以及它们如何应用于日志和传感器。 例如,下面的图像代表在使用Sysmon事件日志时识别出的几个数据元素和关系:

2.通过数据元素定义数据源 (2. Define Data Sources Through Data Elements)
Data modeling enables us to validate data source names and provide a definition for each one in a standardized way. This is accomplished by leveraging the main data elements present in the data we collect.
数据建模使我们能够验证数据源名称,并以标准化方式为每个数据源提供一个定义。 这是通过利用我们收集的数据中存在的主要数据元素来实现的。
We can use the data element to name the data source related to the adversary behavior that we want to collect data about. For example, if an adversary modifies a Windows Registry value, we’ll collect telemetry from the Windows Registry. How the adversary modifies the registry, such as the process or user that performed the action, is additional context we can leverage to help us define the data source.
我们可以使用data元素来命名与我们要收集数据的对手行为有关的数据源。 例如,如果对手修改Windows注册表值,我们将从Windows注册表收集遥测。 对手如何修改注册表(例如执行操作的过程或用户)是我们可以用来帮助我们定义数据源的其他上下文。

We can also group related data elements to provide a general idea of what needs to be collected. For example, we can group the data elements that provide metadata about network traffic and name it Netflow.
我们还可以对相关的数据元素进行分组,以提供有关需要收集哪些内容的一般信息。 例如,我们可以对提供有关网络流量元数据的数据元素进行分组,并将其命名为Netflow。

3.整合数据建模和对手建模 (3. Incorporate Data Modeling and Adversary Modeling)
Leveraging data modeling concepts would also enhance ATT&CK’s current approach to mapping a data source to a technique or sub-technique. Breaking down data sources and standardizing the way data elements relate to each other would allow us to start providing more context around adversary behaviors from a data perspective. ATT&CK users could take those concepts and identify what specific events they need to collect to ensure coverage over a specific adversary action.
利用数据建模概念还可以增强ATT&CK当前将数据源映射到技术或子技术的方法。 分解数据源并标准化数据元素彼此之间的关联方式,将使我们能够从数据角度开始围绕敌人的行为提供更多的背景信息。 ATT&CK用户可以采用这些概念,并确定他们需要收集哪些特定事件,以确保覆盖特定对手行为。
For example, in the image below, we can add more information to the Windows Registry data source by providing some of the data elements that relate to each other to provide more context around the adversary action. We can go from Windows Registry to ( Process — created — Registry Key).
例如,在下面的图像中,我们可以通过提供一些相互关联的数据元素来为Windows注册表数据源添加更多信息,从而提供更多有关攻击行为的上下文。 我们可以从Windows注册表转到(处理-已创建-注册表项)。
This is just one relationship that we can map to the Windows Registry data source. However, this additional information will facilitate a better understanding of the specific data we need to collect.
这只是我们可以映射到Windows注册表数据源的一种关系。 但是,这些附加信息将有助于更好地理解我们需要收集的特定数据。

4.将数据源作为对象集成到ATT&CK (4. Integrate Data Sources into ATT&CK as Objects)
The key components in ATT&CK — tactics, techniques, and groups — are defined as objects. The image below demonstrates how the technique object is represented within the framework.
ATT&CK中的关键组成部分(战术,技术和组)被定义为对象。 下图演示了如何在框架中表示技术对象。

While data sources have always been a property/field object of a technique, it’s time to convert them into objects, with their own corresponding properties.
尽管数据源一直是一种技术的属性/字段对象,但现在该将它们转换为具有其自身相应属性的对象了。
5.展开ATT&CK数据源对象 (5. Expand the ATT&CK Data Source Object)
Once data sources are integrated as objects in the ATT&CK framework, and we establish a structured way to define data sources, we can start identifying additional information or metadata in the form of properties.
一旦将数据源作为对象集成到ATT&CK框架中,并且我们建立了定义数据源的结构化方法,就可以开始以属性的形式识别其他信息或元数据。
The table below outlines some initial properties we propose starting off with:
下表概述了我们建议的一些初始属性:

These initial properties will advance ATT&CK data sources to the next level and open the door to additional information that will facilitate more efficient data collection strategies.
这些初始属性将使ATT&CK数据源更上一层楼,并为获取更多信息提供了方便,这些信息将有助于更有效的数据收集策略。
6.使用数据组件扩展数据源 (6. Extend Data Sources with Data Components)
Our final proposal is to define data components. The relationships we previously discussed between the data elements related to the data sources (e.g., Process, IP, File, Registry) can be grouped together and provide an additional sub-layer of context to data sources. This concept was developed as part of the Open Source Security Event Metadata (OSSEM) project and presented at ATT&CKcon 2018 and 2019. We refer to this concept as Data Components.
我们的最终建议是定义数据组件。 我们先前讨论的与数据源(例如,流程,IP,文件,注册表)相关的数据元素之间的关系可以组合在一起,并为数据源提供上下文的附加子层。 此概念是作为开源安全事件元数据(OSSEM)项目的一部分开发的,并在ATT&CKcon 2018和2019上进行了介绍。我们将此概念称为“ 数据组件” 。
Data Components in action
行动中的数据组件
In the image below, we extended the concept of Process and defined a few data components including Process Creation and Process Network Connection to provide additional context. The outlined method is meant to provide a visualization of how to collect from a Process perspective. These data components were created based on relationships among data elements identified in the available data source telemetry.
在下图中,我们扩展了流程的概念,并定义了一些数据组件,包括流程创建和流程网络连接,以提供其他上下文。 概述的方法旨在从过程角度提供可视化的收集方法。 这些数据组件是根据可用数据源遥测中标识的数据元素之间的关系创建的。

The diagram below maps out how ATT&CK could provide information from the data source to the relationships identified among the data elements that define the data source. It’d then be up to you to determine how best to map those data components and relationships to the specific data you collect.
下图绘制了ATT&CK如何将数据源中的信息提供给定义数据源的数据元素之间的关系。 然后由您决定如何最好地将那些数据组件和关系映射到您收集的特定数据。

下一步是什么 (What’s Next)
In the second post of this two-part series, we’ll explore a methodology to help define new ATT&CK data source objects and how to implement the methodology with current data sources. We will also release the output of our initial analysis, where we applied these data modeling concepts to draft a sample of the new proposed data source objects. In the interim, we appreciate those who contributed to the discussions around data sources and we look forward to your additional feedback.
在这个由两部分组成的系列的第二篇文章中,我们将探讨一种方法来帮助定义新的ATT&CK数据源对象,以及如何使用当前数据源实现该方法。 我们还将发布初始分析的输出,在其中我们将应用这些数据建模概念来草拟新提议的数据源对象的样本。 在此期间,我们感谢那些为围绕数据源的讨论做出贡献的人,并期待您的其他反馈。
©2020 The MITRE Corporation. ALL RIGHTS RESERVED. Approved for public release. Distribution unlimited 20–00841–11.
©2020 MITRE公司。 版权所有。 批准公开发布。 发行数量不受限制20–00841-11。
翻译自: https://medium.com/mitre-attack/defining-attack-data-sources-part-i-4c39e581454f
kibana数据源定义


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









