





 本文介绍了如何利用Horovod进行分布式模型训练,适用于机器学习和深度学习项目,提升模型训练效率。
本文介绍了如何利用Horovod进行分布式模型训练,适用于机器学习和深度学习项目,提升模型训练效率。
horovod使用
Distributed training is a set of techniques for using many GPUs located on many different machines for training your machine learning models. Distributed training is an increasingly common and important deep learning technique, as it enables the training of models too big or too cumbersome to manage on a single machine.
分布式训练是一组技术,用于使用位于许多不同机器上的许多GPU来训练机器学习模型。 分布式训练是一种越来越普遍和重要的深度学习技术,因为它使训练太大或太麻烦而无法在一台机器上管理的模型成为可能。
In a previous article, “Distributed model training in PyTorch using DistributedDataParallel”, I covered distributed training in PyTorch using the native DistributedDataParallel API (if you are unfamiliar with distributed training in general, start there!). This follow-up post discusses distributed training using Uber’s Horovod library. Horovod is a cross-platform distributed training API (supports PyTorch, TensorFlow, Keras, and MXNet) designed for both ease-of-use and performance. Horovod has some really impressive integrations: for example, you can run it within Spark. And it boasts some pretty impressive results:
在上一篇文章“ 使用DistributedDataParallel在PyTorch中进行分布式模型训练 ”中,我介绍了使用本机DistributedDataParallel API在PyTorch中进行分布式训练(如果您通常不熟悉分布式训练,请从这里开始!)。 这篇后续文章讨论了使用Uber的Horovod库进行的分布式培训。 Horovod是一种跨平台的分布式培训API(支持PyTorch,TensorFlow,Keras和MXNet),旨在兼顾易用性和性能。 Horovod具有一些非常令人印象深刻的集成:例如, 您可以在Spark中运行它 。 它拥有一些令人印象深刻的结果:

In this post, I will demonstrate distributed model training using Horovod. We will cover the basics of distributed training, then benchmark a real training script to see the library in action.
在本文中,我将演示如何使用Horovod进行分布式模型训练。 我们将介绍分布式培训的基础知识,然后对真实的培训脚本进行基准测试,以查看实际的库。
Click here to go to our examples GitHub repo so that you can follow along in code.
单击此处转到我们的示例GitHub存储库,以便您可以继续执行代码。
Note that this blog post assumes some familiarity with distributed training. While I provide a quick overview in the next section, if you are unfamiliar with the idea, I recommend first skimming the more detailed overview in my previous post, “Scaling model training in PyTorch using distributed data parallel”.
请注意,此博客文章假定您对分布式培训有所了解。 我将在下一部分中提供快速概述,但是如果您不熟悉该主意,建议您先浏览一下我以前的文章“ 使用分布式数据并行在PyTorch中扩展模型训练 ”中的更详细的概述。
这个怎么运作 (How it works)
Horovod distributes training across GPUs using the data parallelization strategy. In data parallelization, each GPU in the job receives its own independent slice of the data batch, e.g. its own “batch slice”. Each GPU uses this data to independently calculate a gradient update. For example, if you were to use two GPUs and a batch size of 32, one GPU would handle forward and back propagation on the first 16 records, and the second, the last 16. These gradient updates are then synchronized among the GPUs, averaged together, and finally applied to the model.
Horovod使用数据并行化策略在GPU上分配培训。 在数据并行化中,作业中的每个GPU都会接收其自己的数据批处理的独立切片,例如其自己的“批处理切片”。 每个GPU都使用此数据独立计算梯度更新。 例如,如果要使用两个GPU,批处理大小为32,则一个GPU将处理前16条记录的正向传播和向后传播,以及第二条最后16条记录的正向传播。然后,这些梯度更新将在GPU之间平均在一起,最后应用于模型。
Here’s how it works, step-by-step:
逐步操作方法如下:
- Each worker maintains its own copy of the model weights and its own copy of the dataset. 每个工作人员维护自己的模型权重副本和自己的数据集副本。
- Upon receiving the go signal, each worker process draws a disjoint batch from the dataset and computes a gradient for that batch. 收到执行信号后,每个工作进程都会从数据集中提取一个不相交的批次,并计算该批次的梯度。
- The workers use the ring all-reduce algorithm to synchronize their individual gradients, computing the same average gradient on all nodes locally. 工人们使用环全归约算法来同步他们的各个梯度,从而在本地所有节点上计算相同的平均梯度。
- Each worker applies the gradient update to its local copy of the model. 每个工作人员将渐变更新应用于其模型的本地副本。
- The next batch of training begins. 下一批培训开始。
The tricky part is maintaining consistency between the different copies of the model across the different GPUs. If the different model copies somehow end up with different weights, weight updates will become inconsistent and model training will diverge.
棘手的部分是在不同GPU之间维护模型的不同副本之间的一致性。 如果不同的模型以某种方式最终获得不同的权重,则权重更新将变得不一致,并且模型训练将有所不同。
This is achieved using a technique borrowed from the high-performance computing world: the ring all-reduce algorithm. This diagram, taken from Horovod’s launch post, demonstrates how it works:
这是使用从高性能计算世界借来的技术来实现的: 环形全归约算法 。 此图取自Horovod的发布帖子 ,展示了其工作原理:

The ring all-reduce algorithm synchronizes state (in this case tensors) among a set of processes using a well-defined sequence of pairwise message-passing steps. The best part is that this is a well-understood algorithm that’s been in use in the HPC world for a long time — Horovod relies on Open MPI on CPU and NVIDIA NCCL on GPU to do the work under the hood. Facebook’s Gloo is also supported.
环形全归约算法使用定义良好的成对消息传递步骤序列在一组进程之间同步状态(在这种情况下为张量)。 最好的部分是,这是一个在HPC世界中使用了很长时间的易于理解的算法-Horovod依靠CPU上的Open MPI和GPU上的NVIDIA NCCL来进行幕后工作。 也支持Facebook的Gloo 。
训练脚本示例 (An example training script)
The Horovod API is pretty easy-to-use. To better understand how it works, let’s step through the PyTorch demo script included in the horovod GitHub repository (changes with the script are prefaced with a # Horovod comment):
Horovod API非常易于使用。 为了更好地理解它的工作原理,让我们逐步介绍horovod GitHub存储库中包含的PyTorch演示脚本 (对脚本的更改以# Horovod注释开头):
import argparseimport torch.multiprocessing as mpimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torchvision import datasets, transformsimport torch.utils.data.distributedimport horovod.torch as hvd# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--fp16-allreduce', action='store_true', default=False,
help='use fp16 compression during allreduce')
parser.add_argument('--use-adasum', action='store_true', default=False,
help='use adasum algorithm to do reduction')class Net(nn.Module):def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10) def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)return F.log_softmax(x)def train(epoch):
model.train()
# Horovod: set epoch to sampler for shuffling.
train_sampler.set_epoch(epoch)for batch_idx, (data, target) in enumerate(train_loader):if args.cuda:
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()if batch_idx % args.log_interval == 0:
# Horovod: use train_sampler to determine the number of examples in
# this worker's partition.
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_sampler),
100. * batch_idx / len(train_loader), loss.item()))def metric_average(val, name):
tensor = torch.tensor(val)
avg_tensor = hvd.allreduce(tensor, name=name)return avg_tensor.item()def test():
model.eval()
test_loss = 0.
test_accuracy = 0.for data, target in test_loader:if args.cuda:
data, target = data.cuda(), target.cuda()
output = model(data)
# sum up batch loss
test_loss += F.nll_loss(output, target, size_average=False).item()
# get the index of the max log-probability
pred = output.data.max(1, keepdim=True)[1]
test_accuracy += pred.eq(target.data.view_as(pred)).cpu().float().sum() # Horovod: use test_sampler to determine the number of examples in
# this worker's partition.
test_loss /= len(test_sampler)
test_accuracy /= len(test_sampler) # Horovod: average metric values across workers.
test_loss = metric_average(test_loss, 'avg_loss')
test_accuracy = metric_average(test_accuracy, 'avg_accuracy') # Horovod: print output only on first rank.if hvd.rank() == 0:
print('\nTest set: Average loss: {:.4f}, Accuracy: {:.2f}%\n'.format(
test_loss, 100. * test_accuracy))if __name__ == '__main__':
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available() # Horovod: initialize library.
hvd.init()
torch.manual_seed(args.seed) if args.cuda:
# Horovod: pin GPU to local rank.
torch.cuda.set_device(hvd.local_rank())
torch.cuda.manual_seed(args.seed)
# Horovod: limit # of CPU threads to be used per worker.
torch.set_num_threads(1) kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
# When supported, use 'forkserver' to spawn dataloader workers instead of 'fork' to prevent
# issues with Infiniband implementations that are not fork-safeif (kwargs.get('num_workers', 0) > 0 and hasattr(mp, '_supports_context') and
mp._supports_context and 'forkserver' in mp.get_all_start_methods()):
kwargs['multiprocessing_context'] = 'forkserver' train_dataset = \
datasets.MNIST('data-%d' % hvd.rank(), train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
# Horovod: use DistributedSampler to partition the training data.
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, sampler=train_sampler, **kwargs) test_dataset = \
datasets.MNIST('data-%d' % hvd.rank(), train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
# Horovod: use DistributedSampler to partition the test data.
test_sampler = torch.utils.data.distributed.DistributedSampler(
test_dataset, num_replicas=hvd.size(), rank=hvd.rank())
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=args.test_batch_size,
sampler=test_sampler, **kwargs) model = Net() # By default, Adasum doesn't need scaling up learning rate.
lr_scaler = hvd.size() if not args.use_adasum else 1 if args.cuda:
# Move model to GPU.
model.cuda()
# If using GPU Adasum allreduce, scale learning rate by local_size.if args.use_adasum and hvd.nccl_built():
lr_scaler = hvd.local_size() # Horovod: scale learning rate by lr_scaler.
optimizer = optim.SGD(model.parameters(), lr=args.lr * lr_scaler,
momentum=args.momentum) # Horovod: broadcast parameters & optimizer state.
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0) # Horovod: (optional) compression algorithm.
compression = hvd.Compression.fp16 if args.fp16_allreduce else hvd.Compression.none # Horovod: wrap optimizer with DistributedOptimizer.
optimizer = hvd.DistributedOptimizer(optimizer,
named_parameters=model.named_parameters(),
compression=compression,
op=hvd.Adasum if args.use_adasum else hvd.Average) for epoch in range(1, args.epochs + 1):
train(epoch)
test()While the core of this training script is the same as it would be if you were to run it on a single GPU, adapting it to the multi-GPU use case requires a number of adjustments.
虽然此培训脚本的核心与在单个GPU上运行时的脚本相同,但要使其适应多GPU用例,则需要进行许多调整。
Let’s look at what’s changed, starting with the following new initialization code:
让我们看一下更改,从下面的新初始化代码开始:
import horovod.torch as hvd
hvd.init()
torch.manual_seed(args.seed)if args.cuda:
# Horovod: pin GPU to local rank.
torch.cuda.set_device(hvd.local_rank())
torch.cuda.manual_seed(args.seed)After importing the Horovod PyTorch binding using import horovod.torch as hvd we need to call hvd.init() to initialize it. All of the state that horovod manages will be passed into this script inside of this hvd object.
使用import horovod.torch as hvd导入Horovod PyTorch绑定import horovod.torch as hvd我们需要调用hvd.init()进行初始化。 horovod管理的所有状态都将传递到此hvd对象内部的此脚本中。
In this first bit of initialization we see the first of these local variables: hvd.local_rank().
在初始化的第一部分中,我们看到了这些局部变量中的第一个: hvd.local_rank() 。
The local rank is an ID number assigned to each GPU device on a machine, and it ranges from 0 to n — 1, where n is the number of GPUs devices on the machine. Horovod launches one copy of this training script for each GPU on the device, so we use torch.cuda.set_device to instruct PyTorch to run this code on the specific GPU Horovod has assigned this script to.
本地等级是分配给计算机上每个GPU设备的ID号,范围是0到n_1,其中n是计算机上GPU设备的数量。 Horovod为设备上的每个GPU启动了该训练脚本的一个副本,因此我们使用torch.cuda.set_device指示PyTorch在Horovod分配了该脚本的特定GPU上运行此代码。
# Horovod: use DistributedSampler to partition the training data.
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, sampler=train_sampler, **kwargs)The sampler component in DataLoader returns an iterable of indices from the dataset to be drawn. The default sampler in PyTorch is sequential, returning the sequence 0, 1, 2, …, n. Horovod overrides this behavior with its DistributedSampler, which handles partitioning the dataset across machines. DistributedSampler itself takes two parameters as input: hvd.size() (the total number of GPUs, e.g. 16) and hvd.rank() (the ID assigned to this device from the overall list, e.g. 0…15).
DataLoader的采样器组件从要绘制的数据集中返回可迭代的索引。 PyTorch中的默认采样器是顺序的,返回序列0, 1, 2, …, n 。 Horovod使用其DistributedSampler覆盖了此行为,该DistributedSampler处理跨计算机的数据集分区。 DistributedSampler本身接受两个参数作为输入: hvd.size() (GPU的总数,例如16)和hvd.rank() (从总体列表中分配给该设备的ID,例如0…15)。
Note that the sampler also needs to know the current epoch. train calls train_sampler.set_epoch(epoch) on every training loop to achieve this.
请注意,采样器还需要知道当前epoch 。 train在每个训练循环上调用train_sampler.set_epoch(epoch)来实现此目的。
# By default, Adasum doesn't need scaling up learning rate.
lr_scaler = hvd.size() if not args.use_adasum else 1if args.cuda:
# Move model to GPU.
model.cuda()
# If using GPU Adasum allreduce, scale learning rate by local_size.if args.use_adasum and hvd.nccl_built():
lr_scaler = hvd.local_size()# Horovod: scale learning rate by lr_scaler.
optimizer = optim.SGD(model.parameters(), lr=args.lr * lr_scaler,
momentum=args.momentum)Horovod simultaneously trains as many batches as you have GPUs, and the gradient update that is made gets applied to the average of all of these different batch gradients. This means that we can speed up training by multiplying our base learning rate by the number of devices, hvd.size().
Horovod同时训练与您拥有GPU一样多的批次,并且将进行的梯度更新应用于所有这些不同批次梯度的平均值。 这意味着我们可以通过将基本学习率乘以设备数量hvd.size()来加快培训速度。
If you are using the Adasum learning rate scheduler, an advanced scheduler specifically designed for distributed training, there are some special rules to follow. See here in the Horovod docs for details.
如果您使用的是Adasum学习率调度程序,这是专门为分布式培训设计的高级调度程序,则需要遵循一些特殊规则。 有关详细信息,请参见Horovod文档中的此处 。
# Horovod: broadcast parameters & optimizer state.
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0)This training script uses default random initialization for the model weights. Each GPU initializes these random weights separately, so unless we synchronize the initialized weights between machines the training will diverge.
该训练脚本对模型权重使用默认的随机初始化。 每个GPU分别初始化这些随机权重,因此,除非我们在机器之间同步初始化的权重,否则训练会有所不同。
The device with the rank of 0 typically has special significance in Horovod: it is the device responsible for this synchronization. These two API calls broadcast the model state from this “root” machine to the other machines in the list, ensuring that they are in sync. Non-root device training scripts will block on this operation until Horovod has performed the sync.
等级为0的设备在Horovod中通常具有特殊的意义:它是负责此同步的设备。 这两个API调用将模型状态从该“根”计算机广播到列表中的其他计算机,以确保它们是同步的。 非root设备培训脚本将阻止此操作,直到Horovod执行同步。
# Horovod: wrap optimizer with DistributedOptimizer.
optimizer = hvd.DistributedOptimizer(
optimizer,
named_parameters=model.named_parameters(),
compression=compression,
op=hvd.Adasum if args.use_adasum else hvd.Average
)This is where the magic happens. ✨ The Horovod DistributedOptimizer wrapper takes the optimizer (SGD in this case) as input, delegates gradient computation to it, averages gradients using all-reduce or all-gather, then applies those averaged gradients across all devices.
这就是魔术发生的地方。 Hor Horovod DistributedOptimizer包装器将优化器(在本例中为SGD)作为输入,将梯度计算委托给它,使用all-reduce或all-gather来平均梯度,然后将这些平均梯度应用于所有设备。
def metric_average(val, name):
tensor = torch.tensor(val)
avg_tensor = hvd.allreduce(tensor, name=name)return avg_tensor.item()# ...later...def test():
# Horovod: average metric values across workers.
test_loss = metric_average(test_loss, 'avg_loss')
test_accuracy = metric_average(test_accuracy, 'avg_accuracy') # Horovod: print output only on first rank.if hvd.rank() == 0:
print('\nTest set: Average loss: {:.4f}, Accuracy: {:.2f}%\n'.format(
test_loss, 100. * test_accuracy))In the single-machine case, to log the value of a metric we would simply ask for a vector, perform some computation on it, and print it.
在单机情况下,要记录指标的值,我们只需索要一个向量,对其进行一些计算,然后打印出来。
In the multi-machine case things are more complicated. We need each script’s local copy of the value of the metric, and then we would need to average these values to get its cluster mean. hvd.allreduce returns the average of the local copies of a named vector. If an average is not appropriate, you can use the similar hvd.allgather method to collect the vectors into a local list instead, so that you can reduce the values needed.
在多机情况下,情况更加复杂。 我们需要每个脚本的度量值的本地副本,然后我们需要对这些值取平均值以得到其聚类平均值。 hvd.allreduce返回命名向量的本地副本的平均值。 如果平均值不适当,则可以使用类似的hvd.allgather方法将向量收集到本地列表中,以便减少所需的值。
For clarity in the logs, we log the results in test() on the root machine (hvd.rank() == 0) only.
为了使日志更清晰,我们仅将结果记录在根计算机上的test() ( hvd.rank() == 0 )。
开展全方位训练工作 (Launching a horovod training job)
With our “horovod-ified” training script in tow, we are ready to launch our distributed training job.
有了我们的“ horvodified”培训脚本,我们就可以开始我们的分布式培训工作。
Horovod training scripts are not launched as Python scripts. E.g. you cannot use python train.py to run this training script. Instead, Horovod launches using a special CLI command, horovodrun:
Horovod培训脚本未作为Python脚本启动。 例如,您不能使用python train.py运行此培训脚本。 相反,采用特殊的CLI命令Horovod发布会, horovodrun :
$ horovodrun -np 4 -H localhost:4 python train.pyThis example command launches four separate processes running this training script (-np 4). Horovod handles parameterizing all of the variables that need to be aware of the current process’s position in the Horovod cluster, like hvd.local_rank() and hvd.size(), for you.
此示例命令启动运行此训练脚本( -np 4 )的四个单独的进程。 Horovod为您处理所有需要了解当前进程在Horovod集群中的位置的变量的参数化,例如hvd.local_rank()和hvd.size() 。
Without this bit of indirection, you would have to write this process configuration code directly into the training script. For example, parallelizing a model training job using the DistributedDataParallel strategy built into PyTorch requires including something like this in the training script:
如果没有这种间接性,您将不得不将此流程配置代码直接写入培训脚本中。 例如,使用内置在PyTorch中的DistributedDataParallel策略并行化模型训练作业,需要在训练脚本中包含以下内容:
if __name__=="__main__":
mp.spawn(
train, args=(NUM_EPOCHS, WORLD_SIZE),
nprocs=WORLD_SIZE, join=True
)This is really nice because it means you don’t have to deal with initialization code like this yourself — Horovod uses the arguments you pass to horovodrun to figure out how to do it for you, saving you tons of time and energy otherwise spent writing process management boilerplate code.
这真的很好,因为它意味着您不必自己处理初始化代码-Horovod使用传递给horovodrun的参数来找出如何为您执行此操作,从而节省了大量的时间和精力,而这些花费在编写过程上管理样板代码。
Note that this training script launches four processes, all running on the local machine (localhost:4). This is an appropriate setup for a machine with four GPUs attached, such as a p3.8xlarge or a g4dn.12xlarge (four V100s or four T4s) on AWS. To set up a multi-machine distributed training run, you will need to do a little bit more work. The host where horovodrun is executed must be able to SSH to all other hosts without any prompts. Assuming this is the case, you will then be able to execute your training job like so:
请注意,此训练脚本将启动四个进程,所有进程均在本地计算机( localhost:4 )上运行。 对于连接了四个GPU的机器,例如在AWS上的p3.8xlarge或g4dn.12xlarge (四个V100或四个T4),这是一个合适的设置。 要设置多机分布式培训运行,您需要做更多的工作。 执行horovodrun的主机必须能够在没有任何提示的情况下SSH到所有其他主机。 假设是这种情况,那么您将能够像这样执行培训工作:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py基准测试 (Benchmarks)
To benchmark distributed model training performance I trained a DeepLabV3-ResNet 101 model (via Torch Hub) on the PASCAL VOC 2012 dataset (from torchvision datasets) for 20 epochs.
为了对分布式模型训练性能进行基准测试,我在PASCAL VOC 2012数据集(来自torchvision 数据集 )上训练了DeepepV3-ResNet 101模型(通过Torch Hub ), torchvision 20个时期。
I did so using the Spell API. (One of 😉) the great things about the Spell API is that we have built-in support for multi-machine training using Horovod. We handle the network discovery for you: assuming your script is properly configured, you can easily run a training job on as many machines as you’d like with a spell run CLI command looking something like this:
我这样做是使用Spell API的 。 (😉之一)关于Spell API的伟大之处在于,我们内置了对使用Horovod进行多机培训的支持。 我们为您处理网络发现:假设您的脚本已正确配置,则可以使用如下所示的拼写运行CLI命令轻松地在任意数量的计算机上运行训练作业:
$ spell run --machine-type v100 \
--github-url https://github.com/spellrun/spell-deeplab-voc-2012.git \
--tensorboard-dir /spell/tensorboards/model_4/ \
--distributed 8 \
"python models/4_pytorch_distributed_horovod.pyI launched five different training runs total:
我总共进行了五次不同的训练:
A benchmark run on a lone V100 (a
p3.2xlargeon AWS)在单独的V100上运行基准测试(在AWS上为
p3.2xlarge)One run on the V100x4 (
p3.8xlarge) and V100x8 (p3.16xlarge) GPU servers, respectively. Training was parallelized using Horovod in local mode (--distributed 1). Since the GPUs are all attached to the same machine, network overhead should be minimal.一种分别在V100x4(
p3.8xlarge)和V100x8(p3.16xlarge)GPU服务器上运行。 使用Horovod在本地模式下将培训并行化(--distributed 1)。 由于所有GPU都连接到同一台机器,因此网络开销应该最小。One run on 4x single-V100 and 8x single-V100 instances, respectively. In this case, the GPUs are located on different machines, requiring network round trips between machines in the cluster.
一个分别在4x single-V100和8x single-V100实例上运行。 在这种情况下,GPU位于不同的计算机上,需要集群中计算机之间的网络往返。
The results are not definitive by any means, but should nevertheless give you a sense of the time savings distributed training nets you.
结果决不是绝对的,但仍然应该使您了解节省时间的分布式培训网络。
First, here are the times for the single-machine runs:
首先,这是单机运行的时间:
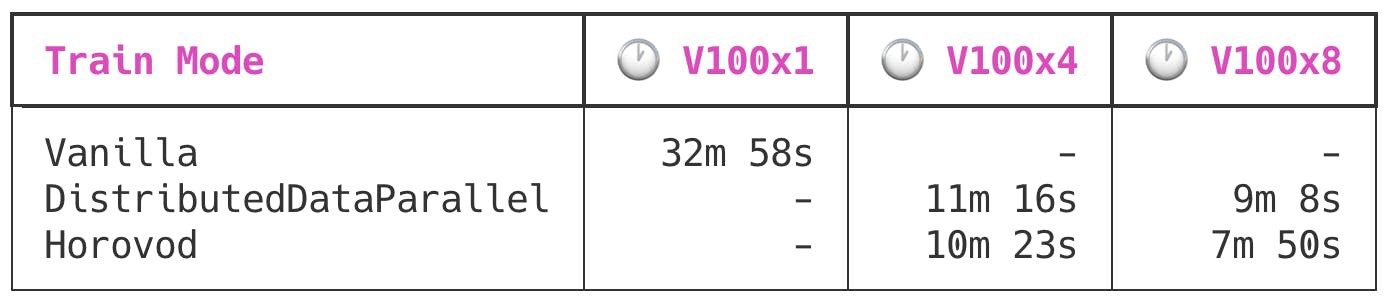
In this table, Vanilla is a single-GPU training job, DistributedDataParallel is the PyTorch-native data parallel API (to learn more, see “Distributed model training in PyTorch using DistributedDataParallel”), and Horovod is Horovod’s PyTorch binding.
在此表中,Vanilla是单GPU培训工作, DistributedDataParallel是PyTorch本地数据并行API(有关更多信息,请参阅“ 使用DistributedDataParallel在PyTorch中进行分布式模型训练 ”),而Horovod是Horovod的PyTorch绑定。
You can clearly see the diminishing returns on multi-GPU training. Increasing compute power by 4x resulted in a ~3x improvement in training time, but doubling that compute further to 8x is only about a 33 percent improvement.
您可以清楚地看到多GPU培训的收益递减。 将计算能力提高4倍,可将训练时间缩短约3倍,但将计算能力提高一倍至8倍,则只能提高33%。
Horovod is notably faster than native PyTorch data parallel, saving about a minute in training time on both machines. Nice!
Horovod明显比并行PyTorch数据并行快,在两台机器上节省了大约一分钟的培训时间。 真好!
Next, let’s look at multi-machine training times. This introduces network round trips between machines, which slows things down:
接下来,让我们看一下多机训练时间。 这引入了机器之间的网络往返,从而减慢了速度:
结论 (Conclusion)
In this article we discussed distributed training and data parallelization, learned about the Horovod API, and applied it to a real model to get some time saves.
在本文中,我们讨论了分布式训练和数据并行化,了解了Horovod API,并将其应用于实际模型以节省时间。
To learn more about the distributed training API I recommend browsing the Horovod docs. If you found this post informative, you may enjoy some of our other posts on the Spell blog:
要了解有关分布式培训API的更多信息,建议浏览Horovod文档 。 如果您发现此信息有用,则可以在Spell博客上享受我们的其他一些信息:
翻译自: https://towardsdatascience.com/distributed-model-training-with-horovod-88e3ff947d27
horovod使用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









