





Web scraping is a term used for harvesting data(text, images, URLs …) from a website. Web scraping is becoming more and more popular, as with modern technologies it is getting easier to implement by common people. In this story I will show you just how easy it is. To scrape some data from a website, we will use Python 3 and BeautifulSoup library.
Web抓取是用于从网站收集数据(文本,图像,URL…)的术语。 Web抓取正变得越来越流行,随着现代技术的普及,普通人更容易实现。 在这个故事中,我将向您展示它的简单程度。 为了从网站上抓取一些数据,我们将使用Python 3和BeautifulSoup库。
Python知识先决条件 (Python knowledge prerequisites)
The code we will write is intentionally at beginner python knowledge level, but the absolute minimum knowledge you should have is following:
我们将有意编写的代码是初学者python知识,但是您应该拥有的绝对最低知识是:
Assignments and operators, string data type, methods, logical structures (if, elif, else), for loops, functions, modules, I/O and python package installation.
用于循环,函数,模块,I / O和python软件包安装的赋值和运算符,字符串数据类型,方法,逻辑结构(if,elif,else)。
开始之前 (Before we start)
What you do with the collected data, can be separated into 2 use cases. Personal use or commercial use. Rule of thumb is that as long as it is for your personal use, you can do whatever you want. Commercial use is a bit different and a study of legal implications is strongly recommended. Also, before you start to scrape anything, you should check robots.txt file of a website you want to scrape. The rule is robots.txt should be located at the root directory of the website. For example, you can check robots.txt of Medium at https://www.medium.com/robots.txt.
您对收集的数据所做的操作可以分为两个用例。 个人使用或商业使用。 经验法则是,只要供个人使用,您就可以做任何您想做的事情。 商业用途有些不同,强烈建议研究法律含义。 另外,在开始抓取任何内容之前,应检查要抓取的网站的robots.txt文件。 规则是robots.txt应该位于网站的根目录下。 例如,您可以在https://www.medium.com/robots.txt上检查Medium的robots.txt。
Robots.txt (Robots.txt)
Bellow we have an example of robots.txt file. This example file has 2 groups of rules. First group applies to Googlebot, second group applies to the rest of crawlers. Let's go step by step:
在下面,我们有一个robots.txt文件的示例。 此示例文件有2组规则。 第一组适用于Googlebot,第二组适用于其余的抓取工具。 让我们一步一步走:
User-agent: Googlebot
Disallow: /me/
Disallow: /media/private_file.htmlUser-agent: *
Allow: /
Sitemap: http://www.example.com/sitemap.xmlUser-Agent: Googlebot — This tells us that following Disallow/Allow rules apply to Googlebot web crawler (web crawler — program used for traversing the internet).
用户代理:Googlebot的 - 这告诉我们,以下禁止/允许规则适用于Googlebot网络搜寻器(网络搜寻器-用于遍历Internet的程序)。
Disallow: /me/ — This tells us that Googlebot should not crawl the folder example.com/me/ or any sub-directory.
不允许:/ me / - 这说明Googlebot不应抓取文件夹example.com/me/或任何子目录。
Disallow: /media/private_file.html — This tells us that Googlebot should not access the page example.com/media/private_file.html.
禁止:/media/private_file.html- 这告诉我们Googlebot不应访问example.com/media/private_file.html页面。
User-agent: * — This tells us that following Disallow/Allow rules apply to all web crawlers.
用户代理:* - 这告诉我们以下禁止/允许规则适用于所有Web搜寻器。
Allow: / — This tells us that all other web crawlers can access any page at the site.
允许:/ - 这告诉我们所有其他Web爬网程序都可以访问该站点上的任何页面。
Sitemap: http://www.example.com/sitemap.xml — This tells us where is located a sitemap for the website.
站点地图:http://www.example.com/sitemap.xml — 这告诉我们网站的站点地图在哪里。
网站防御机制 (Website defense mechanisms)
Some websites, especially famous websites, deploy defense mechanisms to deter you from crawling/scraping their website. Mechanisms tend to vary, but some of the most common ones are:
一些网站,尤其是著名的网站,部署了防御机制来阻止您爬行/刮擦其网站。 机制往往各不相同,但一些最常见的机制是:
- Blocking common web scraping user agents — Website can recognize, that you are not using common browser, like Chrome or Mozilla and based on this information, website can block you. 阻止常见的Web抓取用户代理-网站可以识别出您未使用Chrome或Mozilla之类的通用浏览器,并且基于此信息,网站可以阻止您。
- Exceeding a connection quota — If you try to visit the website way too many times in a short span of time, website can block you. 超出连接配额-如果您尝试在短时间内访问网站太多次,则网站可能会阻止您。
- Blocking you based on your behavior — Website can have deployed a behavior tracking algorithm. If you scrape a website, you “directly” click on links or access pages. You do not exhibit human behavior by hoovering around with the mouse etc. 根据您的行为阻止您-网站可以部署行为跟踪算法。 如果您抓取网站,则可以“直接”单击链接或访问页面。 您不会通过鼠标等徘徊来表现人类行为。
- Captcha — Website can ask you to answer a question, which normally only human should be able to answer. The website can have this mechanism deployed when you try to access certain pages of the site. 验证码—网站可以要求您回答一个问题,通常只有人类可以回答。 当您尝试访问网站的某些页面时,可以在网站上部署此机制。
网页抓取目标 (Web scraping target)
In this tutorial, we will target the daily menu of a fictional offline restaurant. That means for the sake of education, we don't have to worry about robots.txt or any defense mechanisms of websites. To do so, download the HTML source code at this link.
在本教程中,我们将针对虚构的离线餐厅的每日菜单。 这意味着出于教育的目的,我们不必担心robots.txt或网站的任何防御机制。 为此,请在此链接下载HTML源代码。
NOTE: There are tons of sites that do this job for you and keep watch on daily menus of restaurants, but for educational purposes, this is viable example of web scraping.
注意:有许多网站可以为您完成这项工作,并时刻注意餐馆的日常菜单,但是出于教育目的,这是可行的网络抓取示例。
编写代码 (Writing the code)
软件包安装 (Installation of packages)
Firstly, you need to install bs4 package which contains BeautifulSoup. BeautifulSoup is a library that contains tools for scraping the html data. Next we need to install lxml package. This package contains lxml parser which is needed for BeautifulSoup. If you have troubles installing lxml, you can use html.parser which does not require any installation.
首先,您需要安装包含BeautifulSoup的bs4软件包。 BeautifulSoup是一个包含用于抓取html数据的工具的库。 接下来,我们需要安装lxml软件包。 该软件包包含BeautifulSoup所需的lxml解析器。 如果在安装lxml时遇到问题,可以使用html.parser ,它不需要任何安装。
导入模块 (Importing the modules)
Now when we have the necessary packages, simply import the BeautifulSoup via bs4 package:
现在,当我们有必要的软件包时,只需通过bs4软件包导入BeautifulSoup:
from bs4 import BeautifulSoup获取源代码 (Getting the source code)
with open("restaurant.html") as file:
html_source_code = file.read()
html_source_parser = BeautifulSoup(html_source_code, "lxml")
get_menu(html_source_parser)In this snippet of code, we get the source code by loading it from the file and saving it as a string object. Then we initiate BeautifulSoup and feed it with source code of the website and parser of our choice. Last thing to do is to call our next function get_menu(), with the initialized BeautifulSoup as a parameter, which will be responsible for data extraction.
在此代码段中,我们通过从文件中加载源代码并将其保存为字符串对象来获取源代码。 然后,我们启动BeautifulSoup并将其提供给网站源代码和我们选择的解析器。 最后要做的是调用我们的下一个函数get_menu() ,将初始化的BeautifulSoup作为参数,它将负责数据提取。
数据提取 (Data extraction)
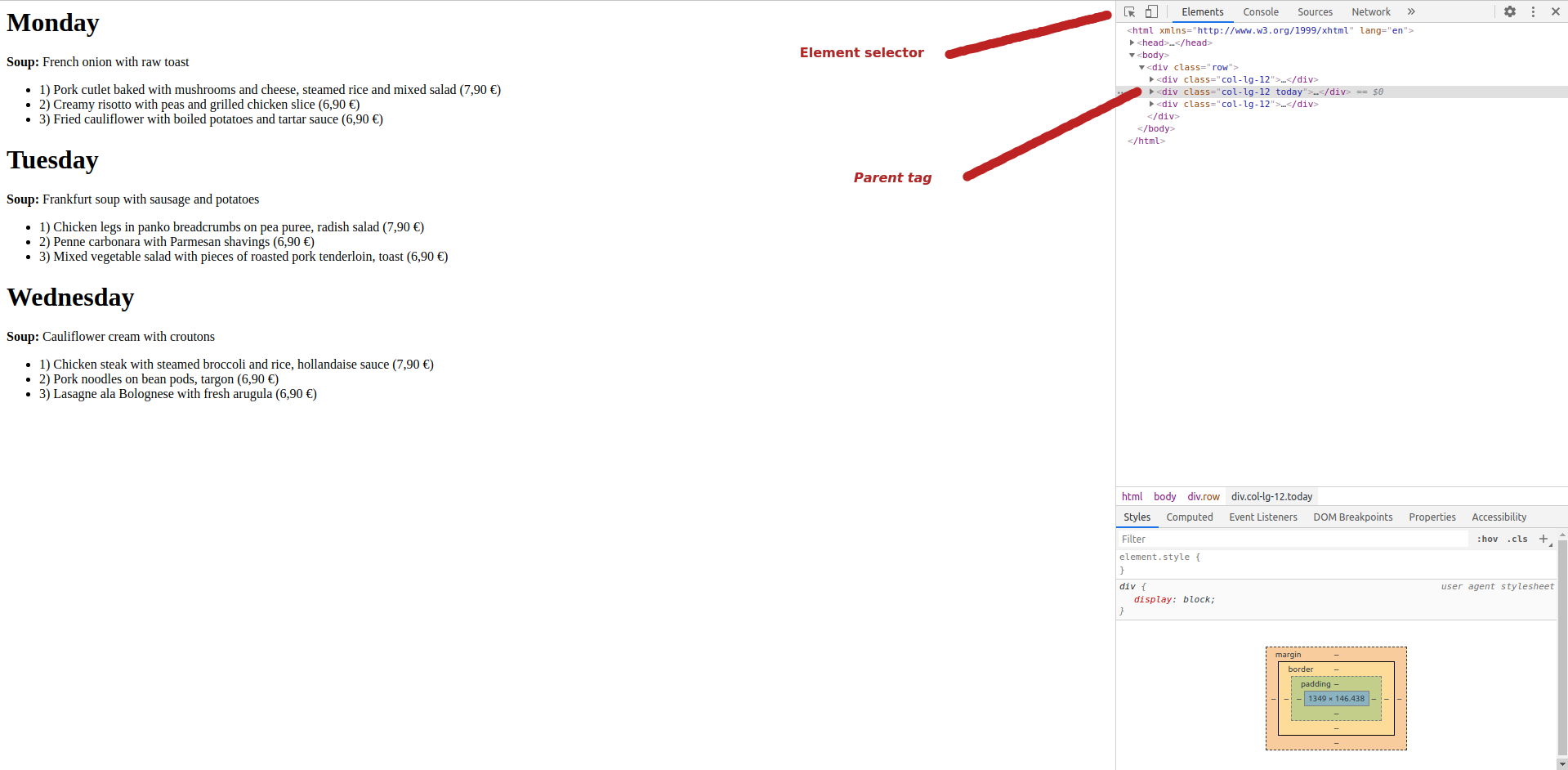
Open the restaurant.html file in Google Chrome browser. We want to scrape what's on the menu today (Let's say today is Tuesday). To get out the data we want, we have to find it in the HTML source code. More precisely, find it under what HTML tag it is hidden. To do so, press Ctrl+Shift+I and element inspector will show up, just as you see on the image above.
在Google Chrome浏览器中打开restaurant.html文件。 我们要抓取今天菜单上的内容(比方说今天是星期二)。 要获取所需的数据,我们必须在HTML源代码中找到它。 更准确地说,在隐藏HTML标签下找到它。 为此,请按Ctrl + Shift + I,将显示元素检查器,就像在上图中看到的一样。
Now click on the element selector and with your mouse, hoover over to the daily menu area for Tuesday. Chrome element selector will highlight various areas as you move with your mouse and show the parent tag of those areas in the html code on the right side of your screen. Once you get to the Tuesday area, click on it. Now, you should see what is the parent HTML tag, which contains the daily menu, on the right side of the screen. The parent tag is <div class=”col-lg-12 today">. Now when we know where to look for the data, let's code.
现在单击元素选择器,然后用鼠标悬停在星期二的每日菜单区域。 Chrome元素选择器将在您移动鼠标时突出显示各个区域,并在屏幕右侧的html代码中显示这些区域的父标记。 到达星期二区域后,单击它。 现在,您应该在屏幕右侧看到什么是父HTML标记,其中包含每日菜单。 父标记是<div class =“ col-lg-12 today”>现在,当我们知道要在哪里寻找数据时,让我们编码。
NOTE: HTML class attribute shadows the name of built in feature of python — python classes. As a result, BeautifulSoup uses “class_” argument for specification of HTML class attribute value.
注意:HTML类属性遮盖了python内置功能的名称-python类。 结果,BeautifulSoup使用“ class_”自变量来指定HTML类属性值。
def get_menu(source_parser):
html_data = source_parser.find("div", class_="col-lg-12 today") if html_data is None:
return None
soup_string = html_data.find("p").get_text()
if soup_string != "":
soup_name = get_food_name(soup_string)
print(soup_name)
html_meals = html_data.find_all("li")
for html_meal in html_meals:
meal_string = html_meal.get_text()
if meal_string != "":
meal_name = get_food_name(meal_string)
meal_price = get_food_price(meal_string)
print(f"{meal_price}\t{meal_name}")
return NoneThe source_parser represents the BeautifulSoup object which supports us with methods to parse the HTML data. BeautifulSoup has 2 methods to use for parsing the data:
source_parser表示BeautifulSoup对象,该对象为我们提供了解析HTML数据的方法。 BeautifulSoup有两种用于解析数据的方法:
BeautifulSoup.find(arguments) which returns the first occurrence matching the arguments as a BeautifulSoup object. If there is no match, method returns None. This is useful when you want to extract something from the site that is hidden under unique tag or attribute.
BeautifulSoup.find(arguments)返回与参数匹配的第一个匹配项,作为BeautifulSoup对象。 如果不匹配,则方法返回None。 当您要从网站中提取隐藏在唯一标记或属性下的内容时,此功能很有用。
BeautifulSoup.find_all(arguments) which returns a list of BeautifulSoup objects. These are all occurrences matching the arguments. If there are no matches, method returns empty list. This is obviously used, when you cannot identify it right away and have to do some more digging before you get to the data you want.
BeautifulSoup.find_all(arguments)返回BeautifulSoup对象的列表。 这些都是与参数匹配的事件。 如果没有匹配项,则方法返回空列表。 很明显,当您无法立即识别它并且必须进行一些进一步的挖掘才能获得所需的数据时,显然可以使用此方法。
We can call find() method in this case, as our <div> tag has unique class attribute value of “col-lg-12 today”. After the call of this method, html_data variable will have the following snippet of HTML code available:
在这种情况下,我们可以调用find()方法 ,因为我们的<div>标记具有唯一的类属性值“ col-lg-12 today”。 调用此方法后, html_data变量将具有以下可用HTML代码段:
<div class="col-lg-12">
<h1>Monday</h1>
<p><strong>Soup: </strong>French onion with raw toast</p>
<ul>
<li>1) Pork cutlet baked with mushrooms and cheese, steamed rice and mixed salad (7,90 €)</li>
<li>2) Creamy risotto with peas and grilled chicken slice (6,90 €)</li>
<li>3) Fried cauliflower with boiled potatoes and tartar sauce (6,90 €)</li>
</ul>
</div>As we can see, soup name can be extracted from tag <p>. This time it is unique HTML tag, so we will use find() method and save it in soup_string as a string object by calling get_text() method of BeautifulSoup object. Extraction of the actual soup_name from the soup_string will be a job for our helper function get_food_name().
如我们所见,可以从标签<p>中提取汤的名称。 这次,它是唯一HTML标记,因此我们将使用find()方法,并通过调用BeautifulSoup object的get_text()方法将其作为字符串对象保存在soup_string中。 从汤字符串中提取实际汤 名称将是我们帮助函数get_food_name()的工作 。
Regarding the menu meals, there are no unique tags or attributes to use. They are all under <li> tags, so we will have to use find_all() method and store the result of method under html_meals. Afterwards, in for loop, we will get the string out of every BeautifulSoup object and extract the names of meals with the helper function get_food_name().
关于菜单餐,没有要使用的唯一标签或属性。 它们都在<li>标记下,因此我们将不得不使用find_all()方法并将该方法的结果存储在html_meals下。 然后,在for循环中,我们将从每个BeautifulSoup对象中获取字符串,并使用辅助函数get_food_name()提取餐食名称。
辅助功能 (Helper functions)
def get_food_name(text):
if text[0] not in "123":
return text[text.index(" ") + 1:]
return text[text.index(" ") + 1: text.index("(") - 1]If the string does not start with the number, we know the string represents a soup name. We want to eliminate unnecessary string “soup: ” so we will return a string starting from the first occurrence of white space.
如果字符串不是以数字开头,则我们知道该字符串代表汤名称。 我们要消除不必要的字符串“ soup:”,因此我们将从第一次出现空白开始返回一个字符串。
Otherwise we know the string represents a meal name. So we will return a string starting from the first occurrence of white space and ending at the index of first occurrence of opening bracket.
否则,我们知道该字符串代表膳食名称。 因此,我们将返回一个字符串,该字符串从第一次出现的空白开始,到在第一次出现的右括号的索引处结束。
def get_food_price(text):
return text[text.index("(") + 1: -1]Pricing applies only to meals and it is at the end of the string inside the brackets. So we simply return a string starting at the first occurrence of opening bracket.
定价仅适用于餐点,位于括号内字符串的结尾。 因此,我们只需返回一个字符串,该字符串始于第一次出现的方括号。
把它放在一起 (Putting it together)
from bs4 import BeautifulSoup
def get_food_price(text):
return text[text.index("(") + 1: -1]
def get_food_name(text):
if text[0] not in "123":
return text[text.index(" ") + 1:]
return text[text.index(" ") + 1: text.index("(") - 1]
def get_menu(source_parser):
html_data = source_parser.find("div", class_="col-lg-12 today")
if html_data is None:
return None
soup_string = html_data.find("p").get_text()
if soup_string != "":
soup_name = get_food_name(soup_string)
print(soup_name)
html_meals = html_data.find_all("li")
for html_meal in html_meals:
meal_string = html_meal.get_text()
if meal_string != "":
meal_name = get_food_name(meal_string)
meal_price = get_food_price(meal_string)
print(f"{meal_price}\t{meal_name}")
return None
with open("restaurant.html") as file:
html_source_code = file.read()
html_source_parser = BeautifulSoup(html_source_code, "lxml")
get_menu(html_source_parser)结论 (Conclusion)
As you can see, all you need is BeautifulSoup library and basic knowledge of python. Even though in this tutorial we are using little snippet of HTML code loaded from a local file, the routine for scraping a data from online websites is exactly the same:
如您所见,您所需要的只是BeautifulSoup库和python的基本知识。 即使在本教程中,我们只使用了很少的从本地文件加载HTML代码片段,但从在线网站抓取数据的例程却完全相同:
- Download the HTML source code. 下载HTML源代码。
- Find under what tags is the data you want. 查找所需的数据在什么标签下。
- Scrape them out of the source code. 从源代码中删除它们。
- Extract the data you want from the strings. 从字符串中提取所需的数据。
I strongly recommend you to play around with BeautifulSoup, as there is a lot more to do with it. Anyways, that's it for the introduction to python web scraping with BeautifulSoup. If you have any questions, feel free to contact me or write down a comment.
我强烈建议您使用BeautifulSoup,因为它还有很多工作要做。 无论如何,这就是使用BeautifulSoup进行python网络抓取的介绍。 如果您有任何疑问,请随时与我联系或写下评论。
翻译自: https://medium.com/@pythonmove/introduction-to-python-web-scraping-with-beautifulsoup-ef345924caae















 2246
2246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









