





静态路由转换成动态路由
相关场景 (Relevant Scenario)
Consider a table with a column with customer names and another column with a comma separated list of items bought. This scenario or structure of data is extremely common when you ask for information from the field. It could be a Deal Id in the first column and a list of Subscriptions in the next. It could be Country in the first and a list of States in the next or Parent Company as key and Child (subsidiary companies) in the next column.
考虑一个表,该表的一列包含客户名称,另一列包含一个用逗号分隔的已购买商品列表。 当您从现场询问信息时,这种情况或数据结构极为普遍。 第一列可能是交易ID,第二列可能是订阅列表。 它可以是第一个国家/地区,下一个是国家/地区列表,下一个列中可以是母公司作为主要子公司,而子公司(子公司)。
To work with the data in any meaningful manner though we do need to separate out the list of comma separated data into individual rows identified by the key element.
为了以任何有意义的方式处理数据,尽管我们确实需要将逗号分隔的数据列表分隔为由key元素标识的各个行。
数据表 (Data table)
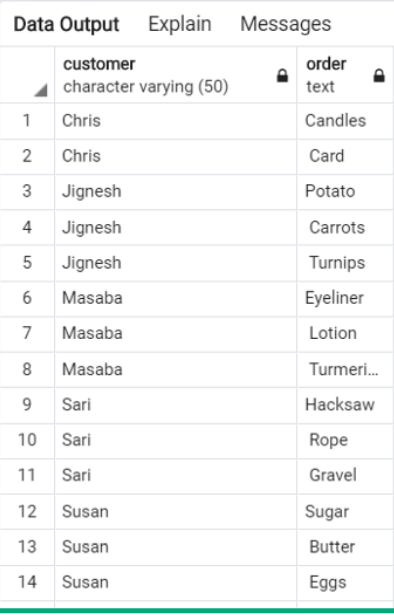
The data we will consider here is a table called ‘checkout’The first column is the name of a customer and the second is a comma separated list of order items. We want to go from the below in Fig 1 to Fig 2.
我们将在此处考虑的数据是一个名为“ checkout”的表。第一列是客户名称,第二列是用逗号分隔的订单项列表。 我们想从图1的下面转到图2。
Fig 1:
图。1:

Fig 2:
图2:
SQL技术 (Technique in SQL)
PostgreSQLIn Postgres we have a couple of options to split and expand the list into rows. One is a combination of converting the value to an array by splitting it along a supplied delimiter and then unnesting it. The second is the less efficient but straightforward method of using regexp_string to_table.
PostgreSQL在Postgres中,我们有两个选项可以将列表拆分和扩展成行。 一种方法是将值沿提供的定界符分割,然后取消嵌套,从而将值转换为数组。 第二种方法是使用regexp_string to_table的效率较低但直接的方法。
Postgres Query 1
select customer,
unnest(string_to_array(orders, ‘,’)) as order
from checkout
order by customer;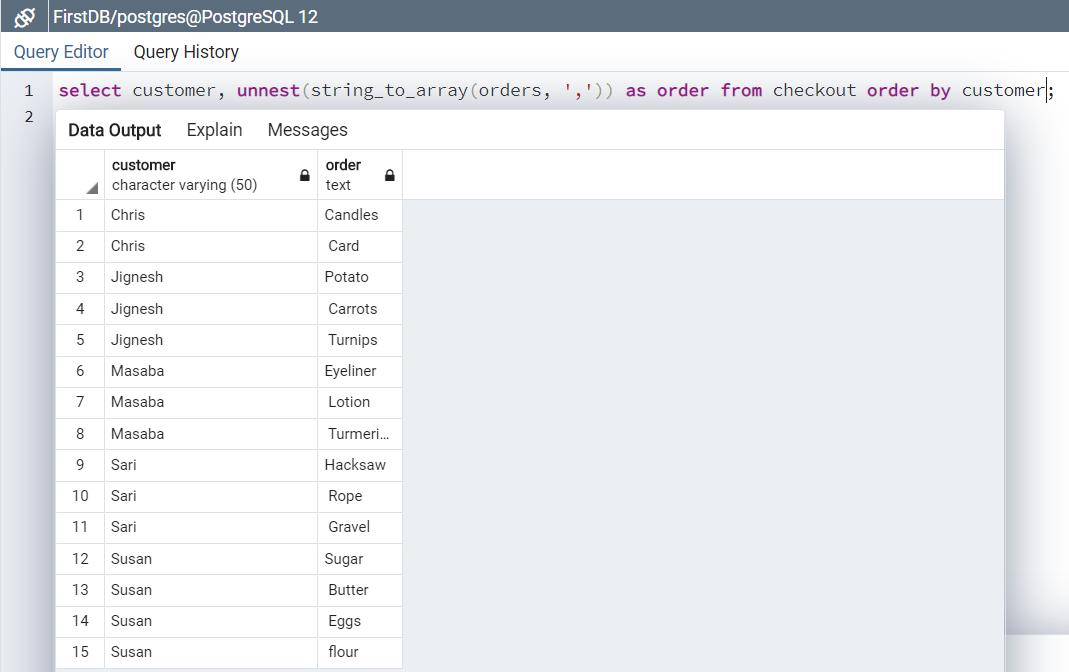
Postgres Query 2
select customer,
regexp_split_to_table(orders, ‘,’) as order
from checkout
order by customer;
While in Postgres these convenient functions make short work of breaking apart the comma separated columns, in Oracle the methodology used is little more complicated but worth understanding since in Power BI we use a similar pattern.
尽管在Postgres中,这些方便的功能使将逗号分隔的列分开的工作很短,但是在Oracle中,使用的方法稍微复杂一些,但值得理解,因为在Power BI中,我们使用了类似的模式。
OracleIn Oracle there are several ways to split a comma separated column into rows as described in the article whose link is provided below, but the one I dissect and explain in detail below uses a pattern of operation that we will also use in Power BI DAX formula:
Oracle在Oracle中,有多种方法可以将逗号分隔的列分成几行,如下面提供链接的文章所述,但是我将在下面进行详细解释并说明一种方法,该方法也将在Power BI DAX中使用式:
The pattern essentially involves:1. Detect the number of items in the comma separated list2. Expand the original table (virtually) by adding on rows to accommodate the newly separated out items.3. Separate out individual items, picking each out from the list and place the against the appropriate key.
该模式实质上涉及: 1.检测以逗号分隔的list2中的项目数。 通过添加行以容纳新分离的项目来(实际上)扩展原始表。3。 分离出单独的项目,从列表中挑选出来,然后将放在适当的键上。
Article with several options provided to split comma separated strings:
文章提供了几个选项来分割逗号分隔的字符串:
Oracle Query
select t.customer,
trim(regexp_substr(t.orders, '[^,]+', 1, lines.column_value))
as "Order"
from checkout t,
table(cast(multiset(
select level from dual
connect by level <=
regexp_count(t.orders, ',')+1
) as sys.odciNumberList
)
)lines
order by customer,
lines.column_value;To understand the query, we will look into the results from breaking the query up. We first get the number of commas in each order for every customer. Adding a 1 to the count of commas gives us the number of orders in each comma separated list.
为了理解查询,我们将研究分解查询的结果。 我们首先获得每个客户在每个订单中的逗号数。 在逗号数上加1可以使我们得到每个逗号分隔列表中的订单数。

We then create a list of number of individual order items for each customer using psuedo-column LEVEL and psuedo-table DUAL. We need to multiply the row for each customer by the number of individual order items and so we generate a series of number of rows required for each customer.
然后,我们使用伪列LEVEL和伪表DUAL为每个客户创建一个单独的订购商品数量的列表。 我们需要将每个客户的行乘以单个订单项的数量,因此我们生成了每个客户所需的一系列行数。
The LEVEL is used to generate a series of numbers as in
LEVEL用于生成一系列数字,如下所示:
select level from dual connect by level < 5;1234
从级别<5; 1234的双连接中选择级别
The 5 seen above will be replaced by the number of order items in each row as we go through every row. This list of LEVEL numbers can be extracted from the column_value of the TABLE created as seen below. We use the built in sys.odciNumberList collection type for convenience.
当我们遍历每行时,上面看到的5将被每行中的订单项数代替。 可以从创建的TABLE的column_value中提取此LEVEL编号列表,如下所示。 为了方便起见,我们使用内置的sys.odciNumberList集合类型。
And so for each customer such as Sari who has three items in her list, there are now three rows and column_value ranging from 1 to 3.
因此,对于每个客户(例如Sari)在列表中有三项,现在有三行,并且column_value的范围是1到3。

Now that we have multiplied each row by the number of order items, we can separate out the items and store each against the customer in a column using reg_substring, which picks out each item from the list using the column_value. We now have our separated out order list with customer name key.
既然我们已经将每一行乘以订单项的数量,我们就可以分离出这些项,并使用reg_substring将这些项针对客户存储在一个列中,后者使用column_value从列表中挑选出每个项。 现在,我们有了带有客户名称关键字的单独订单清单。

熊猫技术 (Technique in Pandas)
We start out with a dataframe created by the output of an SQL statement sent out to the PostGres database where we created the table (see Setup data section below).
我们首先从发送到PostGres数据库SQL语句的输出创建的数据帧开始,在该数据库中创建了表(请参见下面的“设置数据”部分)。


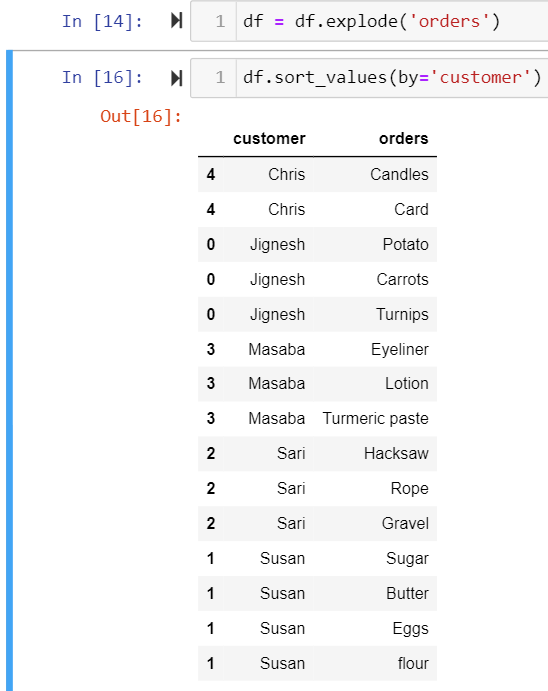
df = df.assign(orderssplit = df['orders'].str.split(',')).drop("orders", axis=1)\
.rename(columns = {"orderssplit": "orders"})The one line command above splits the orders into a list of individual items, drops the comma separated orders column so that it can be replaced by the split of orders column.
上面的单行命令将订单拆分为单个项目的列表,删除逗号分隔的订单列,以便可以将其替换为订单拆分列。
We then “explode” this split column and we are done!!
然后我们“爆炸”该拆分列,我们完成了!
Power BI中的技术 (Technique in Power BI)
Setup details to reuse the data from PostGres has been provided below in the section titles Setup Data.
下面标题为“设置数据”一节中提供了重新使用PostGres数据的设置详细信息。
The pattern used in Power BI DAX is similar to the one described for Oracle database above:
Power BI DAX中使用的模式类似于上述针对Oracle数据库的模式:
The pattern essentially involves:1. Detect the number of items in the comma separated list2. Expand the original table (virtually) by adding on rows to accommodate the new separated out items.3. Separate out individual items, picking each out from the list and place the against the appropriate key
该模式实质上涉及: 1.检测以逗号分隔的list2中的项目数。 通过添加行以容纳新分离出的项来(实际上)扩展原始表。3。 分离出单个项目,从列表中选择每个项目,然后将其放在相应的键上

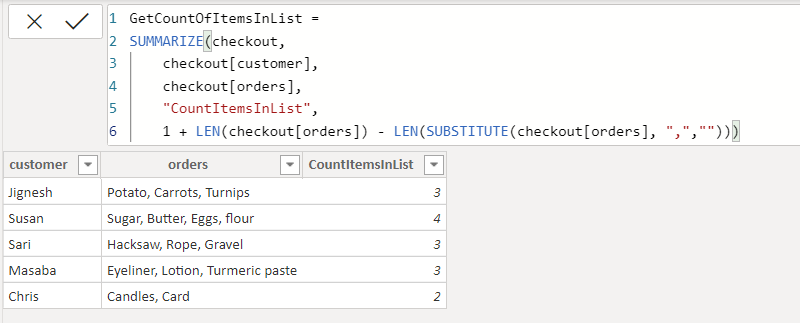
Here, the number of items in each order list is determined by subtracting the length of the comma separated string without the commas from the length of comma separated string. How do we get the string without the commas? We use SUBSTITUTE as seen below:
在此,通过从逗号分隔的字符串的长度中减去不带逗号的逗号分隔的字符串的长度来确定每个订单列表中的项目数。 如何获得不带逗号的字符串? 我们使用SUBSTITUTE,如下所示:
We now need a Dummy table with a column Sequence that can be created using GenerateSeries (DAX) or by importing an excel workbook with a series of whole numbers. How many numbers? As many as you expect to be the number of individual items in the comma separated list, since this table helps ‘expand’ the original query by adding on rows for each item of the list.
现在,我们需要一个Dummy表,该表具有一个Sequence列 ,可以使用GenerateSeries(DAX)或通过导入具有一系列整数的excel工作簿来创建。 有多少个数字? 由于该表通过在列表中的每个项目上添加行来帮助“扩展”原始查询,因此与逗号分隔的列表中的单个项目数一样多。
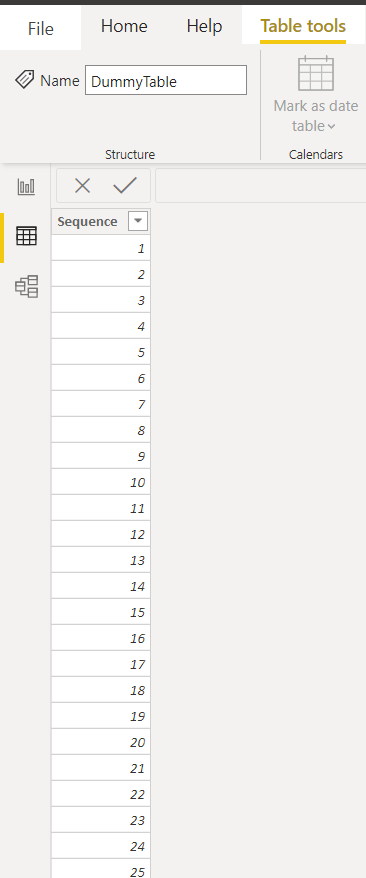
We then create a calculated table using DAX’s CROSSJOIN to join every row in the checkout query to each of the rows in the Dummy table. This multiplies the number of rows in the original query radically but we will trim off the rows we do not need and limit each customer to the number of items soon, by filtering by the number of order items in each row.
然后,我们使用DAX的CROSSJOIN创建一个计算表,以将结帐查询中的每一行连接到Dummy表中的每一行。 这会从根本上乘以原始查询中的行数,但是我们将通过按每行中的订单项数进行过滤,以减少不需要的行数,并将每个客户的商品数限制为不久。

And now for the filtering….
现在进行过滤...。
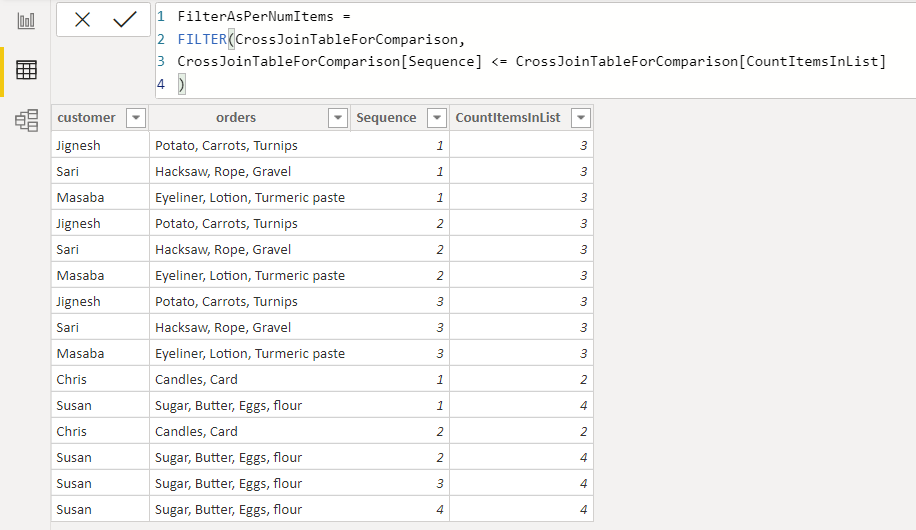
The formula below limits the ‘Sequence’ for each customer to range from 1 to the number of items in their order list. We have now effectively multiplied the number of rows for every customer by the number of items in their list to make room for each item to appear in its own row.
下面的公式将每个客户的“顺序”限制为从1到其订单列表中的项目数。 现在,我们已经有效地将每个客户的行数乘以他们列表中的项目数,以腾出空间让每个项目都出现在自己的行中。
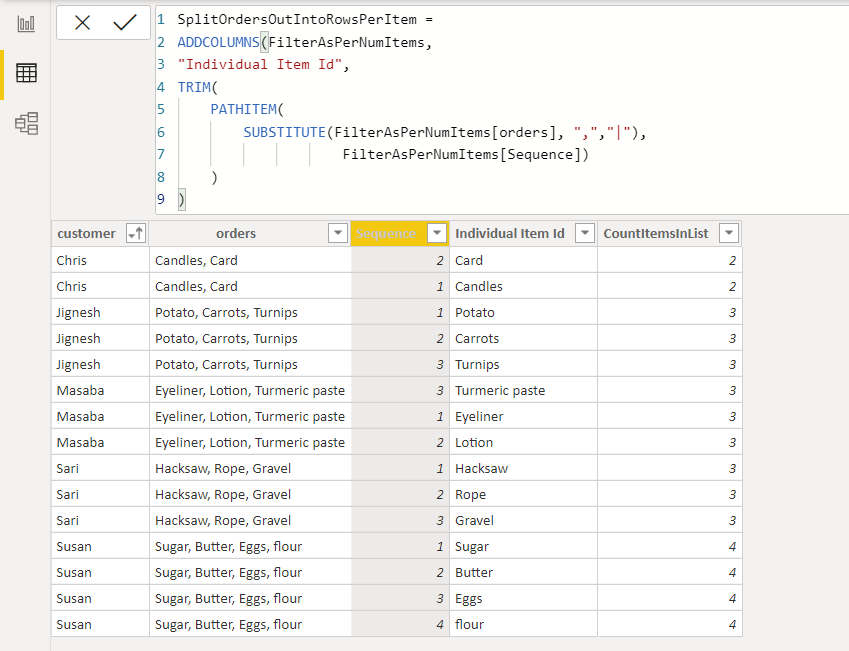
With PATHITEM we pick out each item by specifying the “Sequence” number. And voilà …
使用PATHITEM,我们通过指定“序列”编号来挑选每个项目。 还有...
设定数据 (Setup data)
To reduce effort in duplicating data in each application, I started out with the database. The command used for PostGres were tweaked to create a similar table with data in Oracle. The advantage was that I could then connect to this data from Jupyter Notebook as well as import it into Power BI.
为了减少在每个应用程序中复制数据的工作,我从数据库开始。 对用于PostGres的命令进行了调整,以使用Oracle中的数据创建类似的表。 这样做的好处是我可以从Jupyter Notebook连接到该数据,并将其导入Power BI。
CREATE TABLE public.checkout
(
customer character varying(50) COLLATE pg_catalog.”default”,
orders character varying(200) COLLATE pg_catalog.”default”
)insert into checkout (customer, orders)
values ('Jignesh', 'Potato, Carrots, Turnips');
insert into checkout (customer, orders)
values ('Susan', 'Sugar, Butter, Eggs, flour');
insert into checkout (customer, orders)
values ('Sari', 'Hacksaw, Rope, Gravel')
insert into checkout (customer, orders)
values ('Masaba', 'Eyeliner, Lotion, Turmeric paste')
insert into checkout (customer, orders)
values ('Chris','Candles, Card');To bring this data into a Jupyter notebook:
要将这些数据带入Jupyter笔记本:
import sqlalchemy
sqlalchemy.create_engine('postgresql://<username>:<user pwd>@localhost/<name of database>')%load_ext sql# set up credentials that you will use below
credentials = "postgresql://<username>:<user pwd>@localhost/<name of database>"import pandas as pd
df = pd.read_sql("""
select * from checkout
""", con = credentials)Setting up data in Power BI can be efficiently handled by using Get Data->Postgres SQL
使用Get Data-> Postgres SQL可以有效地处理Power BI中的数据设置
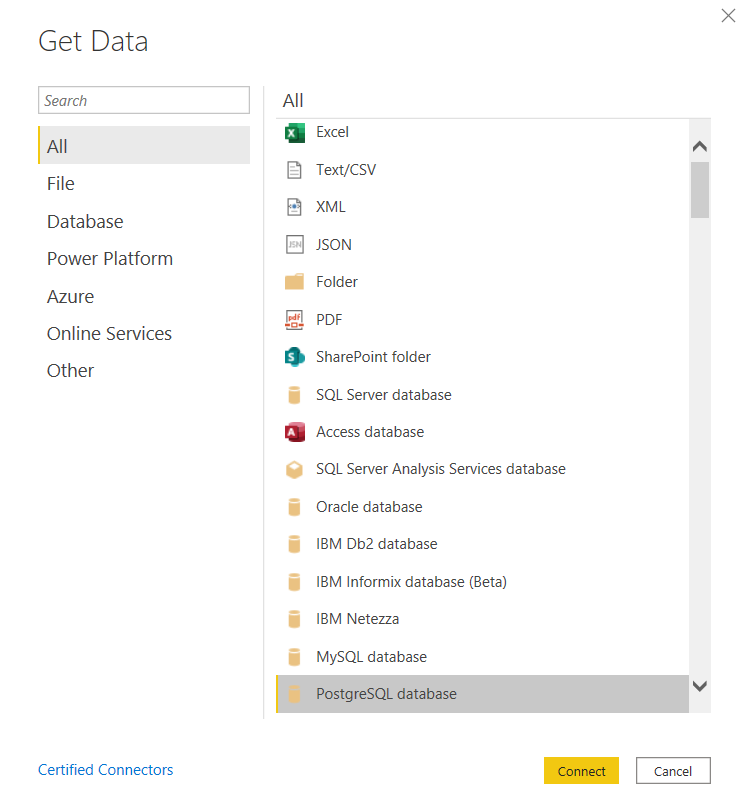
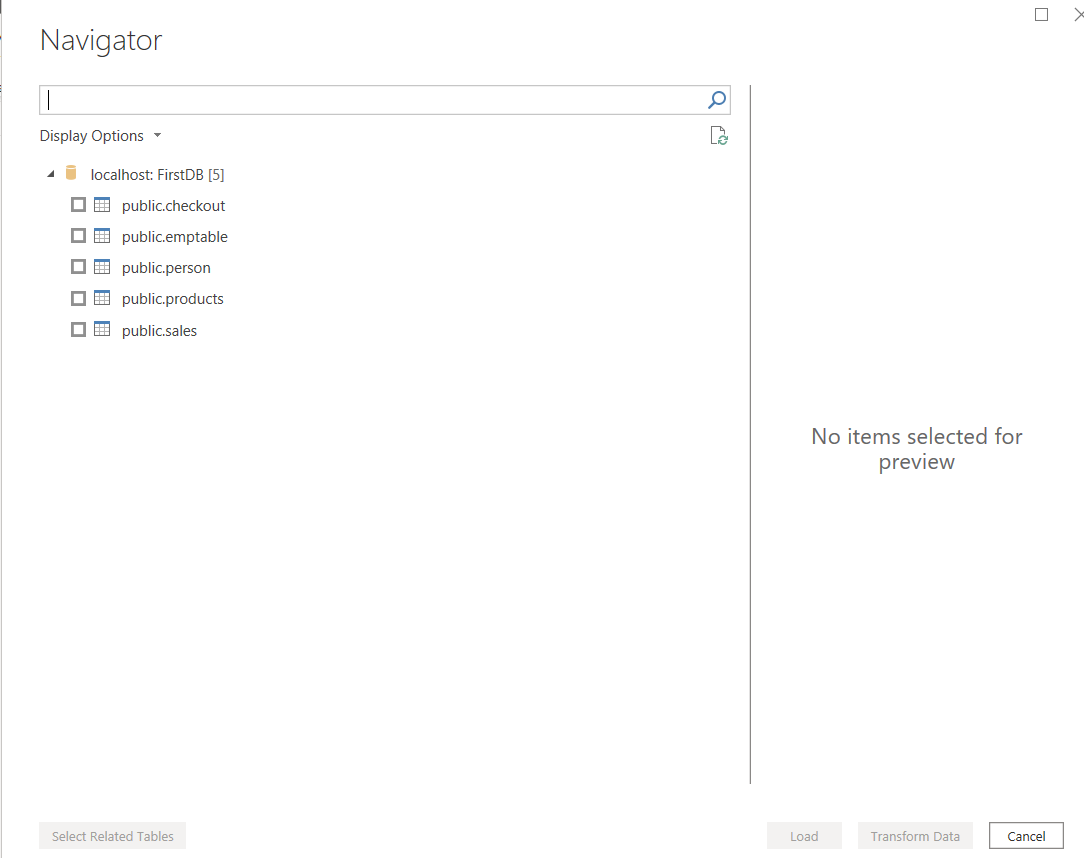
I provided localhost as the server and the database name and was prompted for user name and password after which I was presented with the list of tables in the database. I selected the checkout table for this exercise.
我提供了localhost作为服务器和数据库名称,并提示您输入用户名和密码,然后向我提供数据库中的表列表。 我为此练习选择了结帐表。
翻译自: https://medium.com/@sjtalkar/three-routes-convert-comma-separated-column-to-rows-c17c85079ecf
静态路由转换成动态路由















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









