





This is part 2 of our views on APIs. If you haven’t read part 1 then why are you still here? Go take a look :)
这是我们对API的观点的第二部分。 如果您还没有阅读第1部分,那您为什么还在这里? 去看看:)
泄漏所有应用程序数据 (Leaking all app data)
APIs generally have access to loads of user data; they are the middleman to the transactions between the client interface and the back-end databases. Things like search functionality or filtering will be done on data that the API receives from a back-end database query, however this should be done server side, not locally on the client with stored or received data as this risks exposing a lot of information.
API通常可以访问用户数据。 它们是客户端接口和后端数据库之间事务的中间人。 诸如搜索功能或过滤之类的操作将在API从后端数据库查询接收的数据上完成,但是,这应该在服务器端完成,而不是在本地使用已存储或接收到的数据进行,因为这样可能会暴露大量信息。
使用客户端过滤 (Using Client-side Filtering)
With this application, there was a call to api.example.com/call/data as a GET request, the response from the server was the entire listing of companies, emails, usernames, user IDs and real names held by the business; perfect for direct social engineering attacks. This data was then locally stored in a file to be used in the search bar to narrow down results based on pattern matching.
在此应用程序中,有一个作为GET请求的对api.example.com/call/data的调用,服务器的响应是公司的完整列表,电子邮件,用户名,用户ID和企业所拥有的真实姓名; 非常适合直接的社会工程攻击。 然后,将这些数据本地存储在文件中,以在搜索栏中使用,以基于模式匹配来缩小结果范围。
The entire data set was stored locally on the device as a cached file.
整个数据集作为缓存文件存储在本地设备上。
As this was a locally cached file, it meant that the data had to be updated frequently, cue numerous GET requests to this /call/data API call over the course of the user journey, all in clear text and without certificate pinning; a major issue.
因为这是一个本地缓存的文件,所以它意味着数据必须经常更新,在用户使用过程中,会在此/ call / data API调用中提示许多GET请求,这些请求均采用明文形式,并且没有证书固定; 一个重大问题。
The idea here is any search term required by the user should be sent as a parameter, the server does the heavy lifting and returns only the specific data required, not everything.
这里的想法是,用户所需的任何搜索词都应作为参数发送,服务器承担繁重的工作,并且仅返回所需的特定数据,而不是所有内容。
- App sends search term as a parameter in either a GET or POST to the back-end to perform the lookup. 应用程序将搜索项作为GET或POST中的参数发送到后端以执行查找。
- The Database performs the searching/filtering on the dataset using a query based on the parameter received by the app, and passes the filtered data back to the Server. 数据库使用基于应用程序接收到的参数的查询对数据集执行搜索/过滤,然后将过滤后的数据传递回服务器。
- The Server then returns this filtered data back to the app which is relevant to the specifics that were requested. 然后,服务器将此过滤后的数据返回给应用程序,该数据与所请求的细节有关。
Admittedly there are some overhead problems to overcome, especially when scaling this up widely, however fundamentally only the data that is specifically searched for would be obtained by the user and not the entirety of the database.
诚然,有一些开销问题需要克服,尤其是在大规模扩展时,但是从根本上讲,用户只能获得专门搜索的数据,而不是整个数据库。
服务器通过响应泄漏应用程序数据 (Server Leaks App Data via Response)
This next application was seemingly fairly robust; the app itself was quite limited so made attack points difficult to obtain, however there were two instances found where the server response back to the application included the details of the entire user base on the platform. The first involved the use of the Cache.db file on iOS devices.
下一个应用程序似乎相当健壮。 该应用程序本身非常有限,因此很难获得攻击点,但是发现有两个实例,其中服务器对应用程序的响应包括平台上整个用户群的详细信息。 第一个涉及在iOS设备上使用Cache.db文件。
The idea of the Cache.db file is that it caches all outgoing requests and incoming responses for the application when used with NSURLSession/NSMutableURLRequest functions, this helps speed up loading times if the same request is repeatedly used, much like the cache for your desktop browser. The downside to this is that if the API shares too much, as in this example, and sends back everything for client-side use, then it is all cached. This file is stored in the app private Library directory, so cannot be browsed on standard stock devices.
Cache.db文件的想法是,当与NSURLSession / NSMutableURLRequest函数一起使用时,它会缓存应用程序的所有传出请求和传入响应,如果重复使用相同的请求,则这有助于加快加载时间,就像桌面缓存一样。浏览器。 不利的一面是,如果该API共享过多(如本例所示),并且将所有内容发送回供客户端使用,则将全部缓存。 此文件存储在应用程序的专用Library目录中,因此无法在标准库存设备上浏览。
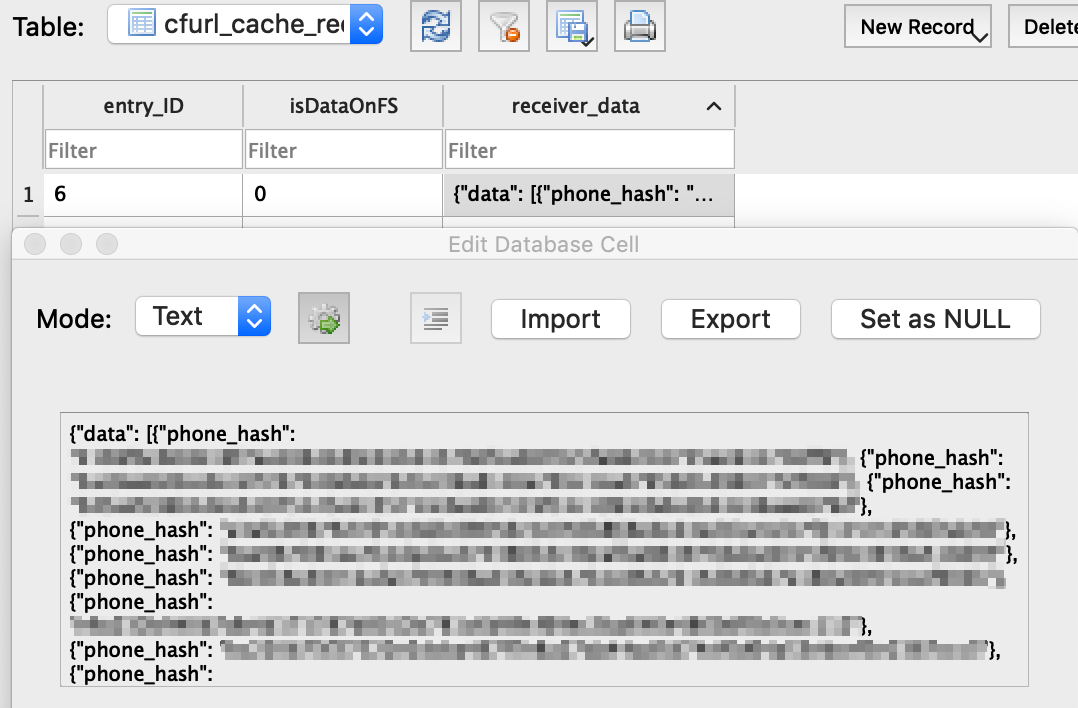
The same API request URLs that were found cached were also found hardcoded in the applications codebase; which after breaking the SSL pinning and utilising an inline proxy tool allowed us to manually call these to obtain the correct headers.
在应用程序代码库中还发现了与找到的相同的API请求URL的硬编码。 在打破SSL固定并利用内联代理工具后,我们便可以手动调用它们以获取正确的标头。
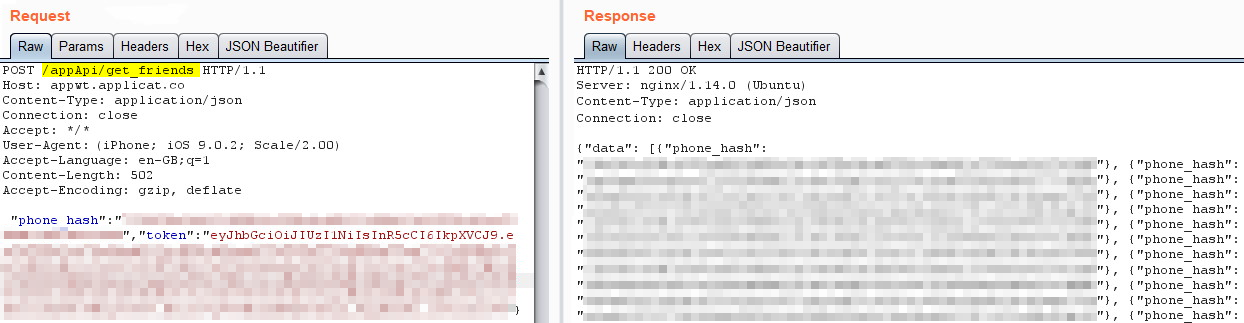
With the correct headers we could then call /appApi/get_friends/ which resulted in a 200 OK response and the full user base details of the application; just like the cache file but no jailbroken device required to access the data this time. Yes it is hashed, but due to the nature of the parameter names, phone_hash, and matching known hashed data with known plaintext, it was simple enough to script a brute force PoC to obtain certain information in plaintext, included names and mobile numbers; enough for further social engineering or smishing.
使用正确的标题后,我们可以调用/ appApi / get_friends / ,这将产生200 OK响应以及该应用程序的完整用户基础详细信息; 就像缓存文件一样,但是这次不需要访问数据的越狱设备。 是的,它是经过哈希处理的,但是由于参数名称phone_hash的性质以及将已知的哈希数据与已知的明文进行匹配的原因,编写暴力破解PoC脚本以获取明文中的某些信息(包括名称和移动号码)非常简单。 足以进行进一步的社会工程或欺骗。
Scripting a simple PoC allowed us to brute force hashes to obtain plaintext.
通过编写简单的PoC脚本,我们可以通过蛮力散列获得纯文本。
和…? (And…?)
In both of these scenarios there was a massive leakage of personal user information, knowing a name, company and application builds information for the attack; knowing either the email address or a mobile number creates the attack vector. As seen here, if the entirety of the dataset is sent back to the client we risk putting a lot of our information, and potentially sensitive user information at risk as this can be intercepted, or obtained from the device itself from cached files.
在这两种情况下,个人用户信息都会大量泄漏,因为他们知道名称,公司和应用程序会为攻击建立信息。 知道电子邮件地址或手机号码会创建攻击媒介。 如此处所示,如果将整个数据集发送回客户端,我们可能会冒充大量信息,并且可能会敏感的用户信息处于危险之中,因为这可以被截获,或者从设备本身从缓存文件中获取。
The user should only be sent data that the specific user role is allowed to view based on a set of permissions and restrictions. The entire response to a call should never to sent to the client, especially not one containing so much sensitive information.
仅应基于一组权限和限制,向用户发送允许特定用户角色查看的数据。 绝不应将对呼叫的整个响应发送给客户端,尤其是其中不应包含太多敏感信息。
通过API行为枚举数据 (Enumeration of Data via API Behaviour)
An enumeration attack is the act of abusing the intended behaviour of the system to obtain something that you didn’t previously have, in this case user data. In this context it involves trying different inputs into certain areas to notice subtle differences in how the app or API responds to valid and invalid data. Once we find the particular nuance to identify the difference between the two, we can increment our starting value to enumerate as much data as possible to gain an awareness of what is stored. We’ll explain this a bit more with some examples.
枚举攻击是指滥用系统的预期行为来获取您以前没有的东西,在这种情况下为用户数据。 在这种情况下,它涉及尝试对某些区域进行不同的输入,以注意到应用程序或API对有效和无效数据的响应方式之间的细微差异。 一旦找到特定的细微差别来识别两者之间的差异,就可以增加起始值来枚举尽可能多的数据,以了解存储的内容。 我们将通过一些示例对此进行更多说明。
Enumeration involves abusing the system to locate small nuances in the result to confirm or deny the presence of certain data.
枚举涉及滥用系统以定位结果中的细微差别,以确认或拒绝某些数据的存在。
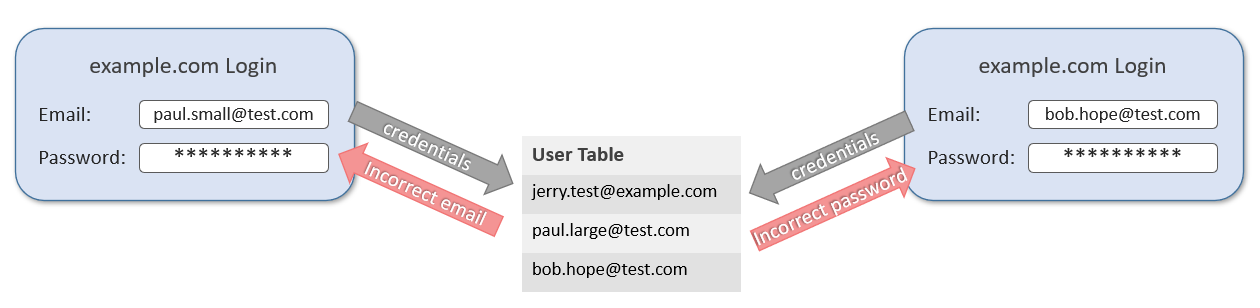
The easiest example here is a login form taking an email and a password. The credentials are then checked against the user table in the database and results with either ‘incorrect email’ if the user doesn’t exist or ‘incorrect password’ if the user does exist but the password is wrong. Although both tell us we are wrong, they imply totally different things and allow us to make assumptions about the presence of data.
这里最简单的示例是一个包含电子邮件和密码的登录表单。 然后凭据对用户表检查数据库和结果与要么如果用户不存在或“密码不正确”如果用户确实存在,但密码是错误的“我ncorrect电子邮件”。 尽管两者都告诉我们我们错了,但它们暗示着完全不同的事物,并允许我们对数据的存在进行假设。
获取忘记的密码 (GET a Forgotten Password)
This issue demonstrates enumeration of users based off their email address using subtle differences in the GET request URL. The idea here was to build up a list of valid users from email addresses. The authentication mechanism here wasn’t as option as responses to both valid and invalid email addresses, and an incorrect password, the error message was always ‘Login failed. Incorrect email or password’, so this didn’t help or provide any indication to which was wrong.
此问题说明了用户使用GET请求URL中的细微差别来基于用户的电子邮件地址进行枚举。 这里的想法是从电子邮件地址建立有效用户列表。 此处的身份验证机制不是对有效和无效电子邮件地址以及错误密码的响应的选项,错误消息始终为'登录失败。 不正确的电子邮件或密码',因此这无济于事或提供任何错误提示。
However, targeting the Forgotten Password form /pass.html, was more interesting. Entering both a valid and an invalid email gave a stock generic error message about password reset being sent.
但是,针对“忘记密码”表单/pass.html ,则更有趣。 输入有效和无效的电子邮件都会发出有关发送密码重置的常规错误消息。

However, the subtle difference here was in the GET request. When entering an email address of a user who did not exist the URL changed to append: pass.html?sent=n
但是,这里的细微差别在于GET请求。 输入不存在的用户的电子邮件地址时,URL更改为追加: pass.html?sent = n
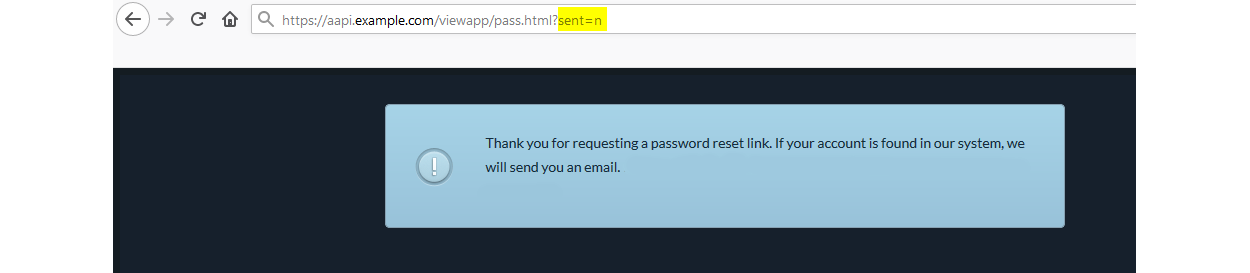
When the email of a user who did exist in the system was entered, this changed to echo out the email and show that the password reset email has been sent; a different string was appended, pass.html?email=bob.hope@test.com&sent=y
当输入系统中确实存在的用户的电子邮件时,将其更改为回显该电子邮件并显示已发送密码重设电子邮件。 附加了另一个字符串pass.html?email=bob.hope@test.com&sent=y
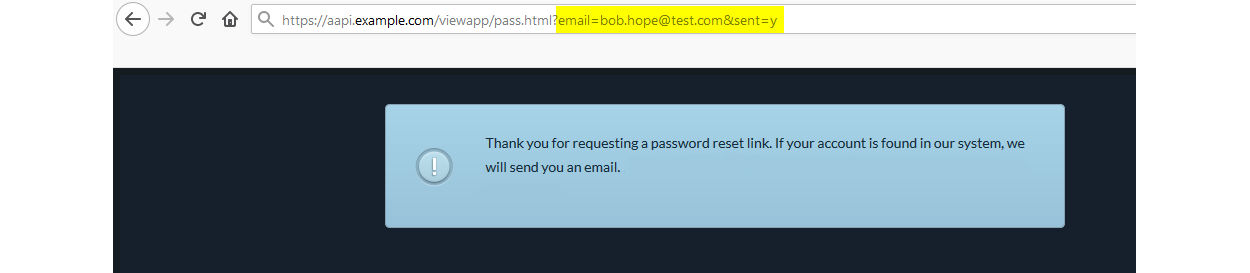
By abusing the change in the URL, it was possible to build up a list of valid users registered on the platform.
通过滥用URL中的更改,可以建立在平台上注册的有效用户的列表。
Using this difference in how the app and API responded to the browser meant it was possible to identify which email address related to a valid user, and from this we can expand the number of attempts to obtain a longer list; this list could then be used for social engineering or phishing for a full credential set. Although browser based enumeration is becoming harder to find, little differences like this are still able to be found and something developers generally overlook, or don’t realise it could be used against them.
利用应用程序和API对浏览器的响应方式上的差异,可以确定与有效用户相关的电子邮件地址,由此我们可以扩大获取更长列表的尝试次数; 然后,此列表可用于社会工程或网络钓鱼,以获得完整的凭据集。 尽管基于浏览器的枚举变得越来越难找到,但是仍然找不到这样的差异,并且开发人员通常会忽略或不意识到可以将其用于它们。
响应状态消息 (Response Status Messages)
Another way to find enumeration is via an inline proxy tool and the responses that are seen via certain API requests. The differences could be a number of different things here such as HTTP status codes, API error messages or custom status messages, but trying different inputs to notice these variances starts to build an image of the behind the scenes working to help figure out what the back-end is expecting.
查找枚举的另一种方法是通过内联代理工具和通过某些API请求看到的响应。 此处的差异可能是许多不同的事物,例如HTTP状态代码,API错误消息或自定义状态消息,但是尝试使用不同的输入来注意到这些差异会开始构建幕后的图像,以帮助找出背后的原因。 -端期待。
The following example shows a few different requests, all to the same API call but with different inputs to test. The format and length of the ID is unknown, and the responses received from the back-end greatly aid in the blind trial and error.
以下示例显示了一些不同的请求,所有请求均针对同一API调用,但具有不同的测试输入。 ID的格式和长度是未知的,并且从后端收到的响应极大地有助于盲目尝试和错误。
In the first request we can see that a customer ID of AAAAAAA* is invalid and the response, despite being 200 OK, provide a negative status for that input. Compared with the request of 1111111*, provides us with a completely different status code. Based on these two different status codes we are now aware of the correct value, and length for customer ID’s; we can continue this attack using brute force enumeration to locate further customer accounts with automated scanning and increasing the value with a step of 1.
在第一个请求中,我们可以看到客户ID AAAAAAA *无效,尽管响应为200 OK,但该输入的状态为否。 与1111111 *的请求相比,为我们提供了完全不同的状态代码。 基于这两个不同的状态代码,我们现在知道了客户ID的正确值和长度; 我们可以使用蛮力枚举继续进行此攻击,以自动扫描查找其他客户帐户,并以1为步长增加价值。
* To get to this stage progressive requests were sent with 4, 5, 6 and 7 characters until the status code changed from input_error to OK.
*到此阶段,将以4、5、6和7个字符发送渐进请求,直到状态代码从input_error更改为OK。
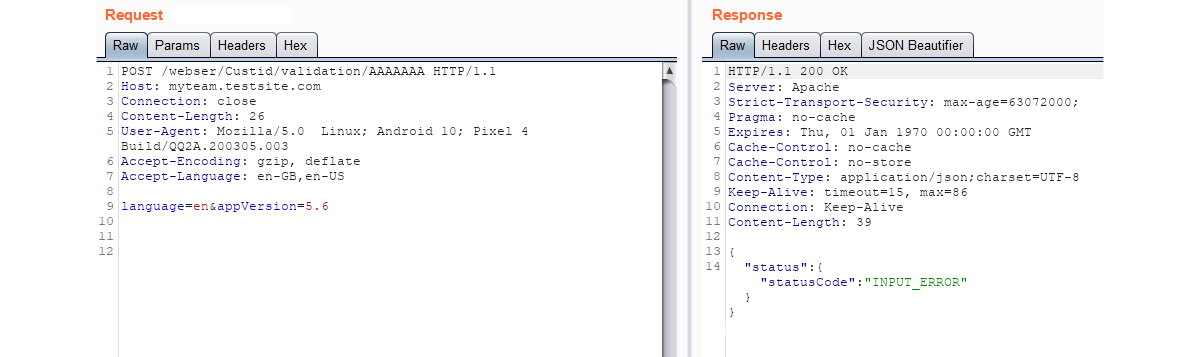
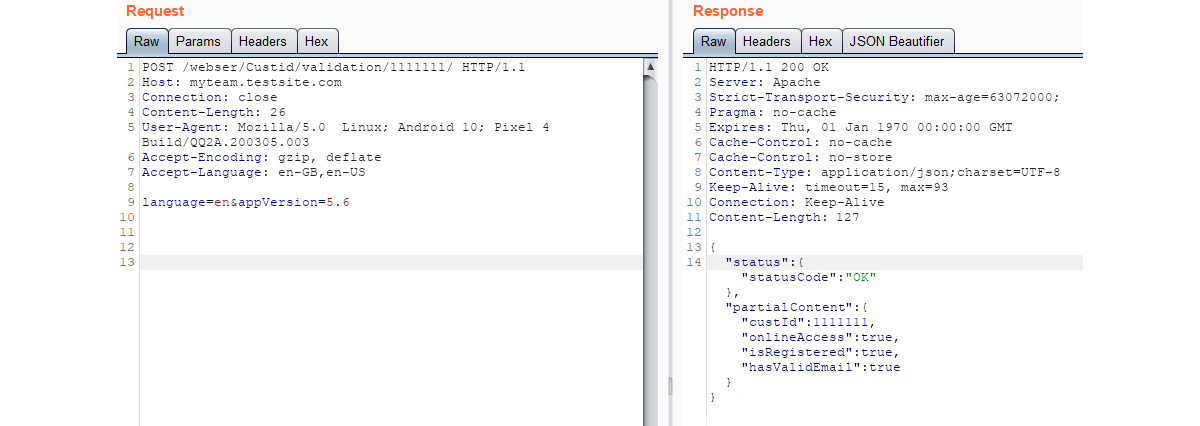
Now we have a valid customer ID, we can progress deeper into the app to investigate the authentication mechanism to perhaps enumerate valid usernames. Once again, we would be looking for subtle differences in the response from the back-end server to aid in our progression through the API.
现在我们有了有效的客户ID,我们可以更深入地进入应用程序以研究身份验证机制,以枚举有效的用户名。 再一次,我们将在后端服务器的响应中寻找细微的差异,以帮助我们逐步通过API。
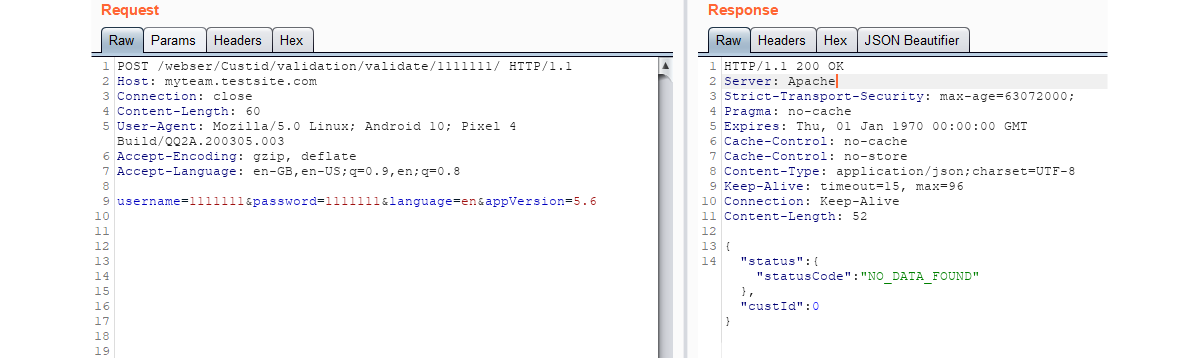
和…? (And…?)
These examples have provided an insight into a couple of the numerous methods that enumeration can be done via APIs. Two totally different techniques were able to be used to an attacker’s advantage to gain knowledge of the users, these techniques were likely not even thought about by the developers. Enumeration isn’t just limited to customer IDs, emails or usernames, it could be any item of data that would be useful for an attacker to have.
这些示例提供了对可以通过API进行枚举的众多方法中的几种的深刻见解。 攻击者可以利用两种完全不同的技术来获取用户的知识,而开发人员甚至可能没有考虑过这些技术。 枚举不仅限于客户ID,电子邮件或用户名,还可以是对攻击者有用的任何数据项。
APIs are now all around us for the majority of today’s technology. However, out of sight, out of mind won’t work here as whether its a security professional, or a mischievous user, these differences in how requests are handled leaves the door ajar.
对于当今的大多数技术而言,API现已遍布我们。 但是,在视线范围内,无论是安全专业人员还是恶作剧的用户,在这里都不会无所事事,处理请求的方式上的这些差异让您感到半开。
Responses from APIs should be generic and not provide any positive or negative outcomes based on any set of data. Custom error codes could also be designated for certain responses which are then documented internally for troubleshooting. The typical end user will never see the API, or any of these return codes, so using certain words or language that allows the inference of how the server reacts can be a great early foothold into your system for those curious enough to be looking.
API的响应应该是通用的,并且不应基于任何数据集提供任何正面或负面的结果。 还可以为某些响应指定自定义错误代码,然后将其内部记录下来以进行故障排除。 典型的最终用户将永远不会看到API或任何这些返回码,因此对于那些好奇的人来说,使用某些可以推断出服务器React方式的单词或语言可能是您系统中的一个重要立足点。
Securing the API and ensuring security is embedded into its development is just as important as implementing a secure web or mobile app. Forgetting to do so, or not understanding the ramifications of not having a secure API may lead to trouble further down the line.
保护API并确保将安全性嵌入到其开发中与实现安全的Web或移动应用程序一样重要。 忘记这样做或不了解没有安全API的后果可能会导致进一步的麻烦。
翻译自: https://medium.com/swlh/a-view-on-apis-from-a-security-professional-part-2-65a3137862f4















 1717
1717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









