





sql 预先
介绍 (Introduction)
According to The Presto Foundation, Presto (aka PrestoDB), not to be confused with PrestoSQL, is an open-source, distributed, ANSI SQL compliant query engine. Presto is designed to run interactive ad-hoc analytic queries against data sources of all sizes ranging from gigabytes to petabytes. Presto is used in production at an immense scale by many well-known organizations, including Facebook, Twitter, Uber, Alibaba, Airbnb, Netflix, Pinterest, Atlassian, Nasdaq, and more.
根据Presto Foundation的 说法 , 不要与PrestoSQL混淆的 Presto( 又名PrestoDB )是一种开源,分布式,符合ANSI SQL的查询引擎。 Presto旨在对从千兆字节到PB大小在内的各种大小的数据源运行交互式即席分析查询。 普雷斯托在生产中许多知名机构,包括用于在一个巨大规模的Facebook , Twitter的 , 尤伯杯 , 阿里巴巴 , 制作的Airbnb , Netflix的 , Pinterest , Atlassian的 , 纳斯达克 ,和更多 。
In the following post, we will gain a better understanding of Presto’s ability to execute federated queries, which join multiple disparate data sources without having to move the data. Additionally, we will explore Apache Hive, the Hive Metastore, Hive partitioned tables, and the Apache Parquet file format.
在下面的文章中,我们将更好地了解Presto执行联合查询的能力,该联合查询可以连接多个不同的数据源而无需移动数据。 此外,我们还将探索Apache Hive,Hive Metastore,Hive分区表以及Apache Parquet文件格式。
在AWS上的Presto (Presto on AWS)
There are several options for Presto on AWS. AWS recommends Amazon EMR and Amazon Athena. Presto comes pre-installed on EMR 5.0.0 and later. The Athena query engine is a derivation of Presto 0.172 and does not support all of Presto’s native features. However, Athena has many comparable features and deep integrations with other AWS services. If you need full, fine-grain control, you could deploy and manage Presto, yourself, on Amazon EC2, Amazon ECS, or Amazon EKS. Lastly, you may decide to purchase a Presto distribution with commercial support from an AWS Partner, such as Ahana or Starburst. If your organization needs 24x7x365 production-grade support from experienced Presto engineers, this is an excellent choice.
AWS上的Presto有多个选项。 AWS建议使用Amazon EMR和Amazon Athena 。 Presto已预先安装在EMR 5.0.0及更高版本上。 Athena查询引擎是Presto 0.172的派生产品, 并不支持 Presto的所有本机功能。 但是,Athena具有许多可比较的功能,并且与其他AWS服务进行了深度集成。 如果需要完全细粒度的控制,则可以自己在Amazon EC2,Amazon ECS或Amazon EKS上部署和管理Presto。 最后,您可以决定在AWS合作伙伴(例如Ahana或Starburst)的 商业支持下购买Presto发行版。 如果您的组织需要经验丰富的Presto工程师提供24x7x365生产级支持,这是一个绝佳的选择。
联合查询 (Federated Queries)
In a modern Enterprise, it is rare to find all data living in a monolithic datastore. Given the multitude of available data sources, internal and external to an organization, and the growing number of purpose-built databases, analytics engines must be able to join and aggregate data across many sources efficiently. AWS defines a federated query as a capability that ‘enables data analysts, engineers, and data scientists to execute SQL queries across data stored in relational, non-relational, object, and custom data sources.’
在现代企业中,很少会发现所有数据都位于一个整体的数据存储中。 鉴于组织内部和外部的大量可用数据源,以及专用数据库的数量不断增加,分析引擎必须能够有效地跨多个源合并和聚合数据。 AWS将联合查询定义为一种功能,该功能使数据分析师,工程师和数据科学家能够对存储在关系,非关系,对象和自定义数据源中的数据执行SQL查询。 '
Presto allows querying data where it lives, including Apache Hive, Thrift, Kafka, Kudu, and Cassandra, Elasticsearch, and MongoDB. In fact, there are currently 24 different Presto data source connectors available. With Presto, we can write queries that join multiple disparate data sources, without moving the data. Below is a simple example of a Presto federated query statement that correlates a customer’s credit rating with their age and gender. The query federates two different data sources, a PostgreSQL database table, postgresql.public.customer, and an Apache Hive Metastore table, hive.default.customer_demographics, whose underlying data resides in Amazon S3.
Presto允许查询数据所在的位置,包括Apache Hive , Thrift , Kafka , Kudu和Cassandra , Elasticsearch和MongoDB 。 实际上,目前有24种不同的Presto 数据源连接器可用。 使用Presto,我们可以编写连接多个不同数据源的查询,而无需移动数据。 以下是Presto联邦查询语句的一个简单示例,该语句将客户的信用等级与其年龄和性别相关联。 该查询联合了两个不同的数据源:PostgreSQL数据库表postgresql.public.customer和Apache Hive Metastore表hive.default.customer_demographics ,其基础数据位于Amazon S3中。
阿哈那 (Ahana)
The Linux Foundation’s Presto Foundation member, Ahana, was founded as the first company focused on bringing PrestoDB-based ad hoc analytics offerings to market and working to foster growth and evangelize the Presto community. Ahana’s mission is to simplify ad hoc analytics for organizations of all shapes and sizes. Ahana has been successful in raising seed funding, led by GV (formerly Google Ventures). Ahana’s founders have a wealth of previous experience in tech companies, including Alluxio, Kinetica, Couchbase, IBM, Apple, Splunk, and Teradata.
Linux基金会的Presto基金会成员Ahana成立,是第一家致力于将基于PrestoDB的即席分析产品推向市场并致力于促进Presto社区发展和推广的公司。 Ahana的使命是简化各种规模和规模的组织的临时分析。 Ahana在GV ( 前Google Ventures )的领导下成功筹集了种子资金 。 Ahana的创始人在技术公司(包括Alluxio,Kinetica,Couchbase,IBM,Apple,Splunk和Teradata)中拥有丰富的经验。
PrestoDB沙箱 (PrestoDB Sandbox)
This post will use Ahana’s PrestoDB Sandbox, an Amazon Linux 2, AMI-based solution available on AWS Marketplace, to execute Presto federated queries.
这篇文章将使用Ahana的PrestoDB Sandbox (可在AWS Marketplace上使用的基于Amazon Linux 2,基于AMI的解决方案)执行Presto联合查询。

Ahana’s PrestoDB Sandbox AMI allows you to easily get started with Presto to query data wherever your data resides. This AMI configures a single EC2 instance Sandbox to be both the Presto Coordinator and a Presto Worker. It comes with an Apache Hive Metastore backed by PostgreSQL bundled in. In addition, the following catalogs are bundled in to try, test, and prototype with Presto:
利用Ahana的PrestoDB Sandbox AMI,您可以轻松地开始使用Presto来查询数据所在的数据。 此AMI将单个EC2实例沙箱配置为Presto 协调器和Presto 工作器 。 它附带捆绑了由PostgreSQL支持的Apache Hive Metastore。此外,捆绑了以下目录以使用Presto进行尝试,测试和原型制作:
- JMX: useful for monitoring and debugging Presto JMX:对监控和调试Presto非常有用
- Memory: stores data and metadata in RAM, which is discarded when Presto restarts 内存:将数据和元数据存储在RAM中,在Presto重新启动时将被丢弃
TPC-DS: provides a set of schemas to support the TPC Benchmark DS
TPC-DS:提供一组模式以支持TPC Benchmark DS
TPC-H: provides a set of schemas to support the TPC Benchmark H
TPC-H:提供一组模式以支持TPC Benchmark H
阿帕奇蜂巢 (Apache Hive)
In this demonstration, we will use Apache Hive and an Apache Hive Metastore backed by PostgreSQL. Apache Hive is data warehouse software that facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. The structure can be projected onto data already in storage. A command-line tool and JDBC driver are provided to connect users to Hive. The Metastore provides two essential features of a data warehouse: data abstraction and data discovery. Hive accomplishes both features by providing a metadata repository that is tightly integrated with the Hive query processing system so that data and metadata are in sync.
在此演示中,我们将使用Apache Hive和PostgreSQL支持的Apache Hive Metastore 。 Apache Hive是一种数据仓库软件,可帮助使用SQL读取,写入和管理驻留在分布式存储中的大型数据集。 该结构可以投影到已经存储的数据上。 提供了命令行工具和JDBC驱动程序以将用户连接到Hive。 Metastore提供了数据仓库的两个基本功能:数据抽象和数据发现。 Hive通过提供与Hive查询处理系统紧密集成的元数据存储库来实现这两个功能,从而使数据和元数据保持同步。
入门 (Getting Started)
To get started creating federated queries with Presto, we first need to create and configure our AWS environment, as shown below.
要开始使用Presto创建联合查询,我们首先需要创建和配置我们的AWS环境,如下所示。

订阅Ahana的PrestoDB沙箱 (Subscribe to Ahana’s PrestoDB Sandbox)
To start, subscribe to Ahana’s PrestoDB Sandbox on AWS Marketplace. Make sure you are aware of the costs involved. The AWS current pricing for the default, Linux-based r5.xlarge on-demand EC2 instance hosted in US East (N. Virginia) is USD 0.252 per hour. For the demonstration, since performance is not an issue, you could try a smaller EC2 instance, such as r5.large instance costs USD 0.126 per hour.
首先,在AWS Marketplace上订阅Ahana的PrestoDB Sandbox 。 确保您了解所涉及的费用。 在美国东部(弗吉尼亚北部)托管的默认的基于Linux的默认r5.xlarge EC2实例的AWS 当前价格为每小时0.252美元。 在演示中,由于性能不是问题,您可以尝试使用较小的EC2实例,例如r5.large实例每小时的费用为0.126美元。

The configuration process will lead you through the creation of an EC2 instance based on Ahana’s PrestoDB Sandbox AMI.
配置过程将引导您基于Ahana的PrestoDB Sandbox AMI创建EC2实例。

I chose to create the EC2 instance in my default VPC. Part of the demonstration includes connecting to Presto locally using JDBC. Therefore, it was also necessary to include a public IP address for the EC2 instance. If you chose to do so, I strongly recommend limiting the required ports 22 and 8080 in the instance’s Security Group to just your IP address (a /32 CIDR block).
我选择在默认VPC中创建EC2实例。 演示的一部分包括使用JDBC在本地连接到Presto。 因此,还必须为EC2实例包括一个公共IP地址。 如果选择这样做,我强烈建议您将实例的安全组中所需的端口22和8080限制为仅您的IP地址( /32 CIDR块)。

Lastly, we need to assign an IAM Role to the EC2 instance, which has access to Amazon S3. I assigned the AWS managed policy, AmazonS3FullAccess, to the EC2’s IAM Role.
最后,我们需要为可以访问Amazon S3的EC2实例分配一个IAM角色。 我将AWS托管策略AmazonS3FullAccess分配给了EC2的IAM角色。

AWS managed policy to the Role
AWS managed policy to the Role附加
AWS managed policy to the Role
Part of the configuration also asks for a key pair. You can use an existing key or create a new key for the demo. For reference in future commands, I am using a key named ahana-presto and my key path of ~/.ssh/ahana-presto.pem. Be sure to update the commands to match your own key’s name and location.
部分配置还要求提供密钥对 。 您可以使用现有密钥或为演示创建新密钥。 为了在将来的命令中提供参考,我正在使用名为ahana-presto密钥以及~/.ssh/ahana-presto.pem密钥路径。 确保更新命令以匹配您自己的密钥的名称和位置。

Once complete, instructions for using the PrestoDB Sandbox EC2 are provided.
完成后,将提供使用PrestoDB Sandbox EC2的说明。



You can view the running EC2 instance, containing Presto, from the web-based AWS EC2 Management Console. Make sure to note the public IPv4 address or the public IPv4 DNS address as this value will be required during the demo.
您可以从基于Web的AWS EC2管理控制台中查看包含Presto的运行中EC2实例。 请确保记下公共IPv4地址或公共IPv4 DNS地址,因为在演示过程中将需要此值。

AWS CloudFormation (AWS CloudFormation)
We will use Amazon RDS for PostgreSQL and Amazon S3 as additional data sources for Presto. Included in the project files on GitHub is an AWS CloudFormation template, cloudformation/presto_ahana_demo.yaml. The template creates a single RDS for PostgreSQL instance in the default VPC and an encrypted Amazon S3 bucket.
我们将使用PostgreSQL和Amazon S3的 Amazon RDS作为Presto的其他数据源。 GitHub上的项目文件中包含一个AWS cloudformation/presto_ahana_demo.yaml模板cloudformation/presto_ahana_demo.yaml 。 该模板在默认VPC和加密的Amazon S3存储桶中为PostgreSQL实例创建单个RDS。
AWSTemplateFormatVersion: "2010-09-09"
Description: "This template deploys a RDS PostgreSQL database and an Amazon S3 bucket"
Parameters:
DBInstanceIdentifier:
Type: String
Default: "ahana-prestodb-demo"
DBEngine:
Type: String
Default: "postgres"
DBEngineVersion:
Type: String
Default: "12.3"
DBAvailabilityZone:
Type: String
Default: "us-east-1f"
DBInstanceClass:
Type: String
Default: "db.t3.medium"
DBStorageType:
Type: String
Default: "gp2"
DBAllocatedStorage:
Type: Number
Default: 20
DBName:
Type: String
Default: "shipping"
DBUser:
Type: String
Default: "presto"
DBPassword:
Type: String
Default: "5up3r53cr3tPa55w0rd"
# NoEcho: True
Resources:
MasterDatabase:
Type: AWS::RDS::DBInstance
Properties:
DBInstanceIdentifier:
Ref: DBInstanceIdentifier
DBName:
Ref: DBName
AllocatedStorage:
Ref: DBAllocatedStorage
DBInstanceClass:
Ref: DBInstanceClass
StorageType:
Ref: DBStorageType
Engine:
Ref: DBEngine
EngineVersion:
Ref: DBEngineVersion
MasterUsername:
Ref: DBUser
MasterUserPassword:
Ref: DBPassword
AvailabilityZone: !Ref DBAvailabilityZone
PubliclyAccessible: true
Tags:
- Key: Project
Value: "Demo of RDS PostgreSQL"
DataBucket:
DeletionPolicy: Retain
Type: AWS::S3::Bucket
Properties:
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
Outputs:
Endpoint:
Description: "Endpoint of RDS PostgreSQL database"
Value: !GetAtt MasterDatabase.Endpoint.Address
Port:
Description: "Port of RDS PostgreSQL database"
Value: !GetAtt MasterDatabase.Endpoint.Port
JdbcConnString:
Description: "JDBC connection string of RDS PostgreSQL database"
Value: !Join
- ""
- - "jdbc:postgresql://"
- !GetAtt MasterDatabase.Endpoint.Address
- ":"
- !GetAtt MasterDatabase.Endpoint.Port
- "/"
- !Ref DBName
- "?user="
- !Ref DBUser
- "&password="
- !Ref DBPassword
Bucket:
Description: "Name of Amazon S3 data bucket"
Value: !Ref DataBucketAll the source code for this post is on GitHub. Use the following command to git clone a local copy of the project.
这篇文章的所有源代码都在GitHub上 。 使用以下命令git clone项目的本地副本。
git clone \
–branch master –single-branch –depth 1 –no-tags \https://github.com/garystafford/presto-aws-federated-queries.gitTo create the AWS CloudFormation stack from the template, cloudformation/rds_s3.yaml, execute the following aws cloudformation command. Make sure you change the DBAvailabilityZone parameter value (shown in bold) to match the AWS Availability Zone in which your Ahana PrestoDB Sandbox EC2 instance was created. In my case, us-east-1f.
要从模板cloudformation/rds_s3.yaml创建AWS cloudformation/rds_s3.yaml ,请执行以下aws cloudformation命令。 确保更改DBAvailabilityZone参数值( 以粗体显示 )以匹配在其中创建Ahana PrestoDB Sandbox EC2实例的AWS可用区。 以我为例, us-east-1f 。
aws cloudformation create-stack \
--stack-name ahana-prestodb-demo \
--template-body file://cloudformation/presto_ahana_demo.yaml \
--parameters ParameterKey=DBAvailabilityZone,ParameterValue=us-east-1fTo ensure the RDS for PostgreSQL database instance can be accessed by Presto running on the Ahana PrestoDB Sandbox EC2, manually add the PrestoDB Sandbox EC2’s Security Group to port 5432 within the database instance’s VPC Security Group’s Inbound rules. I have also added my own IP to port 5432, which enables me to connect to the RDS instance directly from my IDE using JDBC.
为确保运行在Ahana PrestoDB Sandbox EC2上的Presto可以访问PostgreSQL数据库实例的RDS,请手动将PrestoDB Sandbox EC2的安全组添加到数据库实例的VPC安全组的入站规则中的端口5432 。 我还向端口5432添加了自己的IP,这使我可以使用JDBC从我的IDE直接连接到RDS实例。

The AWS CloudFormation stack’s Outputs tab includes a set of values, including the JDBC connection string for the new RDS for PostgreSQL instance, JdbcConnString, and the Amazon S3 bucket’s name, Bucket. All these values will be required during the demonstration.
AWS CloudFormation堆栈的“输出”选项卡包含一组值,包括新的RDS for PostgreSQL实例的JDBC连接字符串JdbcConnString以及Amazon S3存储桶的名称Bucket 。 在演示过程中将需要所有这些值。

准备PrestoDB沙箱 (Preparing the PrestoDB Sandbox)
There are a few steps we need to take to properly prepare the PrestoDB Sandbox EC2 for our demonstration. First, use your PrestoDB Sandbox EC2 SSH key to scp the properties and sql directories to the Presto EC2 instance. First, you will need to set the EC2_ENDPOINT value (shown in bold) to your EC2’s public IPv4 address or public IPv4 DNS value. You can hardcode the value or use the aws ec2 API command is shown below to retrieve the value programmatically.
我们需要采取一些步骤来为我们的演示正确准备PrestoDB Sandbox EC2。 首先,使用PrestoDB Sandbox EC2 SSH密钥将properties和sql目录scp到Presto EC2实例。 首先,您需要将EC2_ENDPOINT值( 以粗体显示 )设置为EC2的公共IPv4地址或公共IPv4 DNS值。 您可以对值进行硬编码,也可以使用下面显示的aws ec2 API命令以编程方式检索该值。
# on local workstation
EC2_ENDPOINT=$(aws ec2 describe-instances \
--filters "Name=product-code,Values=ejee5zzmv4tc5o3tr1uul6kg2" \
"Name=product-code.type,Values=marketplace" \
--query "Reservations[*].Instances[*].{Instance:PublicDnsName}" \
--output text)scp -i "~/.ssh/ahana-presto.pem" \
-r properties/ sql/ \
ec2-user@${EC2_ENDPOINT}:~/ssh -i "~/.ssh/ahana-presto.pem" ec2-user@${EC2_ENDPOINT}设置环境变量 (Set Environment Variables)
Next, we need to set several environment variables. First, replace the DATA_BUCKET and POSTGRES_HOST values below (shown in bold) to match your environment. The PGPASSWORD value should be correct unless you changed it in the CloudFormation template. Then, execute the command to add the variables to your .bash_profile file.
接下来,我们需要设置几个环境变量。 首先,替换下面的DATA_BUCKET和POSTGRES_HOST值( 以粗体显示 )以匹配您的环境。 PGPASSWORD值应该正确,除非您在CloudFormation模板中对其进行了更改。 然后,执行命令以将变量添加到您的.bash_profile文件中。
echo """
export DATA_BUCKET=prestodb-demo-databucket-CHANGE_ME
export POSTGRES_HOST=presto-demo.CHANGE_ME.us-east-1.rds.amazonaws.comexport PGPASSWORD=5up3r53cr3tPa55w0rd
export JAVA_HOME=/usr
export HADOOP_HOME=/home/ec2-user/hadoop
export HADOOP_CLASSPATH=$HADOOP_HOME/share/hadoop/tools/lib/*
export HIVE_HOME=/home/ec2-user/hive
export PATH=$HIVE_HOME/bin:$HADOOP_HOME/bin:$PATH
""" >>~/.bash_profileOptionally, I suggest updating the EC2 instance with available updates and install your favorite tools, likehtop, to monitor the EC2 performance.
(可选)我建议使用可用更新来更新EC2实例,并安装您喜欢的工具,例如htop ,以监视EC2性能。
yes | sudo yum update
yes | sudo yum install htop
Before further configuration for the demonstration, let’s review a few aspects of the Ahana PrestoDB EC2 instance. There are several applications pre-installed on the instance, including Java, Presto, Hadoop, PostgreSQL, and Hive. Versions shown are current as of early September 2020.
在进一步配置演示之前,让我们回顾一下Ahana PrestoDB EC2实例的几个方面。 实例上预安装了几个应用程序,包括Java,Presto,Hadoop,PostgreSQL和Hive。 显示的版本为2020年9月上旬的最新版本。
java -version
# openjdk version "1.8.0_252"
# OpenJDK Runtime Environment (build 1.8.0_252-b09)
# OpenJDK 64-Bit Server VM (build 25.252-b09, mixed mode)hadoop version
# Hadoop 2.9.2postgres --version
# postgres (PostgreSQL) 9.2.24psql --version
# psql (PostgreSQL) 9.2.24hive --version
# Hive 2.3.7presto-cli --version
# Presto CLI 0.235-cb21100The Presto configuration files are in the /etc/presto/ directory. The Hive configuration files are in the ~/hive/conf/ directory. Here are a few commands you can use to gain a better understanding of their configurations.
Presto配置文件位于/etc/presto/目录中。 Hive配置文件位于~/hive/conf/目录中。 您可以使用以下命令来更好地了解其配置。
ls /etc/presto/cat /etc/presto/jvm.config
cat /etc/presto/config.properties
cat /etc/presto/node.properties# installed and configured catalogs
ls /etc/presto/catalog/cat ~/hive/conf/hive-site.xml配置Presto (Configure Presto)
To configure Presto, we need to create and copy a new Presto postgresql catalog properties file for the newly created RDS for PostgreSQL instance. Modify the properties/rds_postgresql.properties file, replacing the value, connection-url (shown in bold), with your own JDBC connection string, shown in the CloudFormation Outputs tab.
要配置Presto,我们需要为新创建的PostgreSQL实例RDS创建并复制一个新的Presto postgresql 目录属性文件 。 修改properties/rds_postgresql.properties文件,用您自己的JDBC连接字符串(显示在CloudFormation输出选项卡中)替换值connection-url ( 以粗体显示 )。
connector.name=postgresql
connection-url=jdbc:postgresql://presto-demo.abcdefg12345.us-east-1.rds.amazonaws.com:5432/shipping
connection-user=presto
connection-password=5up3r53cr3tPa55w0rdMove the rds_postgresql.properties file to its correct location using sudo.
使用sudo将rds_postgresql.properties文件移动到正确的位置。
sudo mv properties/rds_postgresql.properties /etc/presto/catalog/We also need to modify the existing Hive catalog properties file, which will allow us to write to non-managed Hive tables from Presto.
我们还需要修改现有的Hive目录属性文件,这将使我们能够从Presto写入非托管Hive表。
connector.name=hive-hadoop2
hive.metastore.uri=thrift://localhost:9083hive.non-managed-table-writes-enabled=trueThe following command will overwrite the existing hive.properties file with the modified version containing the new property.
以下命令将使用包含新属性的修改后的版本覆盖现有的hive.properties文件。
sudo mv properties/hive.properties |
/etc/presto/catalog/hive.propertiesTo finalize the configuration of the catalog properties files, we need to restart Presto. The easiest way is to reboot the EC2 instance, then SSH back into the instance. Since our environment variables are in the .bash_profile file, they will survive a restart and logging back into the EC2 instance.
要完成目录属性文件的配置,我们需要重新启动Presto。 最简单的方法是重新启动EC2实例,然后通过SSH重新登录到该实例。 由于我们的环境变量位于.bash_profile file ,因此它们将在重新启动并重新登录到EC2实例后幸免。
sudo reboot将表添加到Apache Hive Metastore (Add Tables to Apache Hive Metastore)
We will use RDS for PostgreSQL and Apache Hive Metastore/Amazon S3 as additional data sources for our federated queries. The Ahana PrestoDB Sandbox instance comes pre-configured with Apache Hive and an Apache Hive Metastore, backed by PostgreSQL (a separate PostgreSQL 9.x instance pre-installed on the EC2).
我们将针对PostgreSQL和Apache Hive Metastore / Amazon S3使用RDS作为联合查询的其他数据源。 Ahana PrestoDB Sandbox实例预先配置有Apache Hive和Apache Hive Metastore,并由PostgreSQL支持( 在EC2上预安装了一个单独的PostgreSQL 9.x实例 )。
The Sandbox’s instance of Presto comes pre-configured with schemas for the TPC Benchmark DS (TPC-DS). We will create identical tables in our Apache Hive Metastore, which correspond to three external tables in the TPC-DS data source’s sf1 schema: tpcds.sf1.customer, tpcds.sf1.customer_address, and tpcds.sf1.customer_demographics. A Hive external table describes the metadata/schema on external files. External table files can be accessed and managed by processes outside of Hive. As an example, here is the SQL statement that creates the external customer table in the Hive Metastore and whose data will be stored in the S3 bucket.
沙盒的Presto实例预先配置了TPC Benchmark DS (TPC-DS)的架构。 我们将在Apache Hive Metastore中创建相同的表,这些表对应于TPC-DS数据源的sf1模式中的三个外部表: tpcds.sf1.customer , tpcds.sf1.customer_address和tpcds.sf1.customer_demographics 。 Hive 外部表描述了外部文件上的元数据/架构。 外部表文件可以由Hive外部的进程访问和管理。 例如,以下是在Hive Metastore中创建外部customer表SQL语句,其数据将存储在S3存储桶中。
CREATE EXTERNAL TABLE IF NOT EXISTS `customer`(
`c_customer_sk` bigint,
`c_customer_id` char(16),
`c_current_cdemo_sk` bigint,
`c_current_hdemo_sk` bigint,
`c_current_addr_sk` bigint,
`c_first_shipto_date_sk` bigint,
`c_first_sales_date_sk` bigint,
`c_salutation` char(10),
`c_first_name` char(20),
`c_last_name` char(30),
`c_preferred_cust_flag` char(1),
`c_birth_day` integer,
`c_birth_month` integer,
`c_birth_year` integer,
`c_birth_country` char(20),
`c_login` char(13),
`c_email_address` char(50),
`c_last_review_date_sk` bigint)
STORED AS PARQUET
LOCATION
's3a://prestodb-demo-databucket-CHANGE_ME/customer'
TBLPROPERTIES ('parquet.compression'='SNAPPY');The threeCREATE EXTERNAL TABLE SQL statements are included in the sql/ directory: sql/hive_customer.sql, sql/hive_customer_address.sql, and sql/hive_customer_demographics.sql. The bucket name (shown in bold above), needs to be manually updated to your own bucket name in all three files before continuing.
sql/目录中包含三个CREATE EXTERNAL TABLE SQL语句: sql/hive_customer.sql , sql/hive_customer_address.sql和sql/hive_customer_demographics.sql 。 存储桶名称( 上面的粗体显示 )需要在所有三个文件中手动更新为您自己的存储桶名称,然后才能继续。
Next, run the following hive commands to create the external tables in the Hive Metastore within the existing default schema/database.
接下来,运行以下hive命令以在现有default架构/数据库内的Hive Metastore中创建外部表。
hive --database default -f sql/hive_customer.sql
hive --database default -f sql/hive_customer_address.sql
hive --database default -f sql/hive_customer_demographics.sqlTo confirm the tables were created successfully, we could use a variety of hive commands.
为了确认表已成功创建,我们可以使用各种hive命令。
hive --database default -e "SHOW TABLES;"
hive --database default -e "DESCRIBE FORMATTED customer;"
hive --database default -e "SELECT * FROM customer LIMIT 5;"
Alternatively, you can also create the external table interactively from within Hive, using the hive command to access the CLI. Copy and paste the contents of the SQL files to the hive CLI. To exit hive use quit;.
另外,您还可以使用hive命令访问CLI,从Hive内部以交互方式创建外部表。 将SQL文件的内容复制并粘贴到hive CLI。 要退出蜂巢,请使用quit; 。

Amazon S3数据源设置 (Amazon S3 Data Source Setup)
With the external tables created, we will now select all the data from each of the three tables in the TPC-DS data source and insert that data into the equivalent Hive tables. The physical data will be written to Amazon S3 as highly-efficient, columnar storage format, SNAPPY-compressed Apache Parquet files. Execute the following commands. I will explain why the customer_address table statements are a bit different, next.
创建外部表后,我们现在将从TPC-DS数据源的三个表中的每个表中选择所有数据,并将该数据插入等效的Hive表中。 物理数据将被写入到Amazon S3为高效率的,柱状的存储格式, SNAPPY -compressed Apache的镶木文件。 执行以下命令。 接下来,我将解释为什么customer_address表语句有些不同。
# inserts 100,000 rows
presto-cli --execute """
INSERT INTO hive.default.customer
SELECT * FROM tpcds.sf1.customer;
"""# inserts 50,000 rows across 52 partitions
presto-cli --execute """
INSERT INTO hive.default.customer_address
SELECT ca_address_sk, ca_address_id, ca_street_number,
ca_street_name, ca_street_type, ca_suite_number,
ca_city, ca_county, ca_zip, ca_country, ca_gmt_offset,
ca_location_type, ca_state
FROM tpcds.sf1.customer_address
ORDER BY ca_address_sk;
"""# add new partitions in metastore
hive -e "MSCK REPAIR TABLE default.customer_address;"# inserts 1,920,800 rows
presto-cli --execute """
INSERT INTO hive.default.customer_demographics
SELECT * FROM tpcds.sf1.customer_demographics;
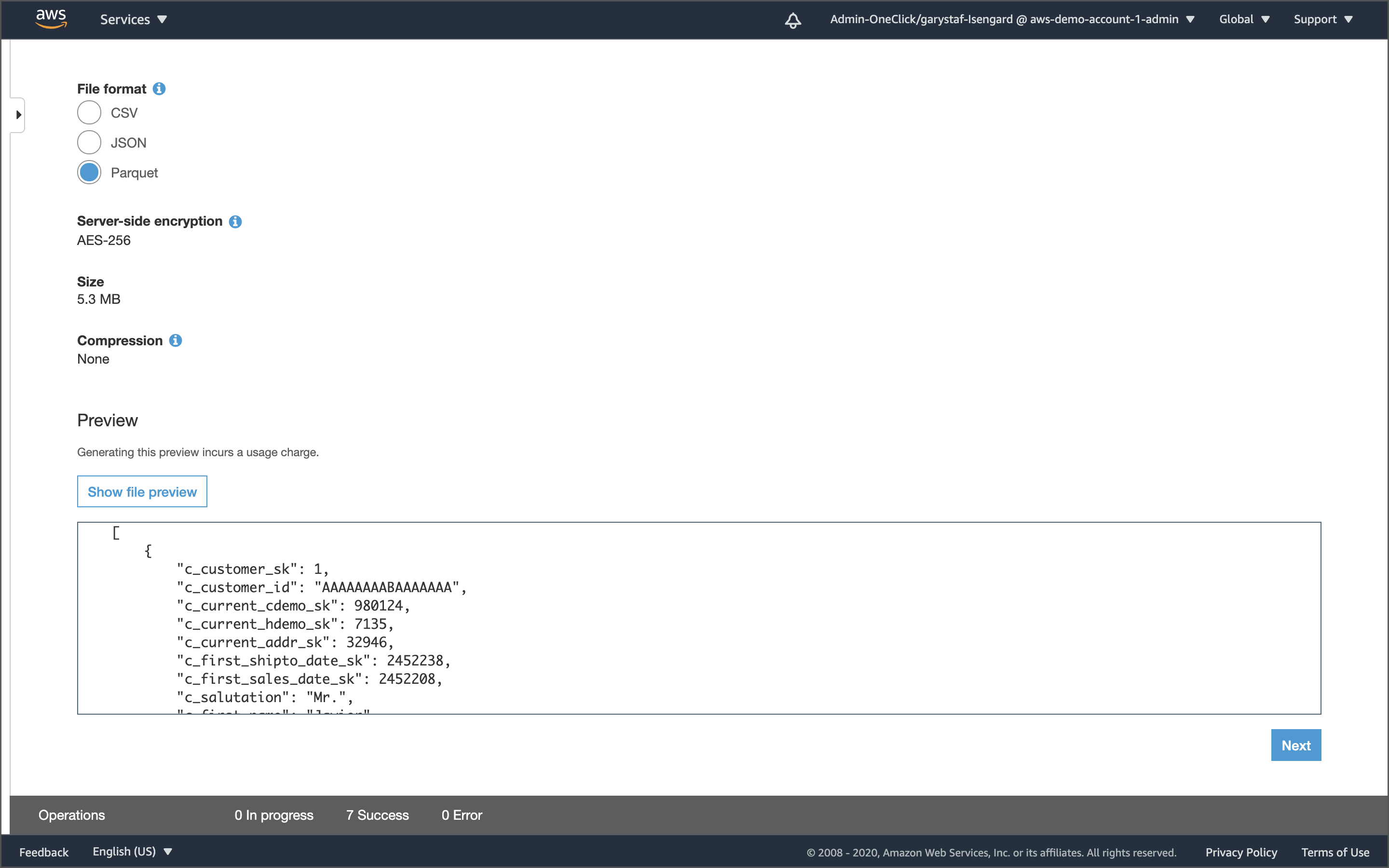
"""Confirm the data has been loaded into the correct S3 bucket locations and is in Parquet-format using the AWS Management Console or AWS CLI. Rest assured, the Parquet-format data is SNAPPY-compressed even though the S3 console incorrectly displays Compression as None. You can easily confirm the compression codec with a utility like parquet-tools.
使用AWS管理控制台或AWS CLI确认数据已加载到正确的S3存储桶位置并为Parquet格式。 请放心,即使S3控制台错误地将Compression显示为None ,Parquet格式的数据也被SNAPPY压缩。 您可以使用parquet-tools之类的实用工具轻松确认压缩编解码器。

分区表 (Partitioned Tables)
The customer_address table is unique in that it has been partitioned by the ca_state column. Partitioned tables are created using the PARTITIONED BY clause.
customer_address表是唯一的,因为它已被ca_state列分区。 使用PARTITIONED BY子句创建分区表 。
CREATE EXTERNAL TABLE `customer_address`(
`ca_address_sk` bigint,
`ca_address_id` char(16),
`ca_street_number` char(10),
`ca_street_name` char(60),
`ca_street_type` char(15),
`ca_suite_number` char(10),
`ca_city` varchar(60),
`ca_county` varchar(30),
`ca_zip` char(10),
`ca_country` char(20),
`ca_gmt_offset` double precision,
`ca_location_type` char(20)
)PARTITIONED BY (`ca_state` char(2))STORED AS PARQUET
LOCATION
's3a://prestodb-demo-databucket-CHANGE_ME/customer'
TBLPROPERTIES ('parquet.compression'='SNAPPY');According to Apache Hive, a table can have one or more partition columns and a separate data directory is created for each distinct value combination in the partition columns. Since the data for the Hive tables are stored in Amazon S3, that means that when the data is written to the customer_address table, it is automatically separated into different S3 key prefixes based on the state. The data is physically “partitioned”.
根据Apache Hive的介绍 ,一个表可以具有一个或多个分区列,并为分区列中的每个不同值组合创建一个单独的数据目录。 由于Hive表的数据存储在Amazon S3中,这意味着当数据写入到customer_address表时,它会根据状态自动分成不同的S3键前缀。 数据在物理上是“分区的”。

Whenever add new partitions in S3, we need to run the MSCK REPAIR TABLE command to add that table’s new partitions to the Hive Metastore.
每当在S3中添加新分区时,我们都需要运行MSCK REPAIR TABLE命令以将该表的新分区添加到Hive Metastore中。
hive -e "MSCK REPAIR TABLE default.customer_address;"In SQL, a predicate is a condition expression that evaluates to a Boolean value, either true or false. Defining the partitions aligned with the attributes that are frequently used in the conditions/filters (predicates) of the queries can significantly increase query efficiency. When we execute a query that uses an equality comparison condition, such as ca_state = 'TN', partitioning means the query will only work with a slice of the data in the corresponding ca_state=TN prefix key. There are 50,000 rows of data in the customer_address table, but only 1,418 rows (2.8% of the total data) in the ca_state=TN partition. With the additional advantage of Parquet format with SNAPPY compression, partitioning can significantly reduce query execution time.
在SQL中, 谓词是条件表达式,其结果为布尔值,即true或false。 定义与查询条件/过滤器(谓词)中经常使用的属性对齐的分区可以显着提高查询效率。 当我们执行使用相等性比较条件的查询(例如ca_state = 'TN' ,分区意味着该查询将仅使用对应的ca_state=TN前缀键中的一部分数据。 customer_address表中有50,000行数据,而ca_state=TN分区中只有1,418行(占总数据的2.8%)。 利用具有SNAPPY压缩功能的Parquet格式的其他优势,分区可以显着减少查询执行时间。
将数据添加到RDS for PostgreSQL实例 (Adding Data to RDS for PostgreSQL Instance)
For the demonstration, we will also replicate the schema and data of the tpcds.sf1.customer_address table to the new RDS for PostgreSQL instance’s shipping database.
为了演示,我们还将复制tpcds.sf1.customer_address表的架构和数据到PostgreSQL实例的shipping数据库的新RDS。
CREATE TABLE customer_address (
ca_address_sk bigint,
ca_address_id char(16),
ca_street_number char(10),
ca_street_name char(60),
ca_street_type char(15),
ca_suite_number char(10),
ca_city varchar(60),
ca_county varchar(30),
ca_state char(2),
ca_zip char(10),
ca_country char(20),
ca_gmt_offset double precision,
ca_location_type char(20)
);Like Hive and Presto, we can create the table programmatically from the command line or interactively; I prefer the programmatic approach. Use the following psql command, we can create the customer_address table in the public schema of the shipping database.
与Hive和Presto一样,我们可以从命令行以编程方式或以交互方式创建表; 我更喜欢程序化方法。 使用以下psql命令,我们可以在shipping数据库的public模式中创建customer_address表。
psql -h ${POSTGRES_HOST} -p 5432 -d shipping -U presto \
-f sql/postgres_customer_address.sqlNow, to insert the data into the new PostgreSQL table, run the following presto-cli command.
现在,要将数据插入到新的PostgreSQL表中,请运行以下presto-cli命令。
# inserts 50,000 rows
presto-cli --execute """
INSERT INTO rds_postgresql.public.customer_address
SELECT * FROM tpcds.sf1.customer_address;
"""To confirm that the data was imported properly, we can use a variety of commands.
为了确认数据已正确导入,我们可以使用多种命令。
-- Should be 50000 rows in table
psql -h ${POSTGRES_HOST} -p 5432 -d shipping -U presto \
-c "SELECT COUNT(*) FROM customer_address;"psql -h ${POSTGRES_HOST} -p 5432 -d shipping -U presto \
-c "SELECT * FROM customer_address LIMIT 5;"Alternatively, you could use the PostgreSQL client interactively by copying and pasting the contents of the sql/postgres_customer_address.sql file to the psql command prompt. To interact with PostgreSQL from the psql command prompt, use the following command.
另外,您可以通过将sql/postgres_customer_address.sql文件的内容复制并粘贴到psql命令提示符下来交互使用PostgreSQL客户端。 要从psql命令提示符与PostgreSQL交互,请使用以下命令。
psql -h ${POSTGRES_HOST} -p 5432 -d shipping -U prestoUse the \dt command to list the PostgreSQL tables and the \q command to exit the PostgreSQL client. We now have all the new data sources created and configured for Presto!
使用\dt命令列出PostgreSQL表,并使用\q命令退出PostgreSQL客户端。 现在,我们为Presto!创建并配置了所有新数据源!
与Presto互动 (Interacting with Presto)
Presto provides a web interface for monitoring and managing queries. The interface provides dashboard-like insights into the Presto Cluster and queries running on the cluster. The Presto UI is available on port 8080 using the public IPv4 address or the public IPv4 DNS.
Presto提供了一个用于监视和管理查询的Web界面。 该界面提供了类似于仪表板的洞察力,可了解Presto群集以及在群集上运行的查询。 使用公共IPv4地址或公共IPv4 DNS,可在端口8080使用Presto UI。

There are several ways to interact with Presto, via the PrestoDB Sandbox. The post will demonstrate how to execute ad-hoc queries against Presto from an IDE using a JDBC connection and the Presto CLI. Other options include running queries against Presto from Java and Python applications, Tableau, or Apache Spark/PySpark.
通过PrestoDB沙盒,有几种与Presto进行交互的方法。 这篇文章将演示如何使用JDBC连接和Presto CLI从IDE对Presto执行临时查询。 其他选项包括从Java和Python应用程序, Tableau或Apache Spark / PySpark对Presto运行查询。
Below, we see a query being run against Presto from JetBrains PyCharm, using a Java Database Connectivity (JDBC) connection. The advantage of using an IDE like JetBrains is having a single visual interface, including all the project files, multiple JDBC configurations, output results, and the ability to run multiple ad hoc queries.
在下面,我们看到使用Java数据库连接(JDBC)连接从JetBrains PyCharm针对Presto运行查询。 使用像JetBrains这样的IDE的优点是具有单个可视界面,包括所有项目文件,多个JDBC配置,输出结果以及运行多个临时查询的能力。

Below, we see an example of configuring the Presto Data Source using the JDBC connection string, supplied in the CloudFormation stack Outputs tab.
在下面,我们看到一个示例,该示例使用CloudFormation堆栈的Outputs选项卡中提供的JDBC连接字符串配置Presto数据源。

Make sure to download and use the latest Presto JDBC driver JAR.
确保下载并使用最新的Presto JDBC驱动程序JAR。

With JetBrains’ IDEs, we can even limit the databases/schemas displayed by the Data Source. This is helpful when we have multiple Presto catalogs configured, but we are only interested in certain data sources.
使用JetBrains的IDE,我们甚至可以限制数据源显示的数据库/方案。 当我们配置了多个Presto目录时,这很有用,但是我们仅对某些数据源感兴趣。

We can also run queries using the Presto CLI, three different ways. We can pass a SQL statement to the Presto CLI, pass a file containing a SQL statement to the Presto CLI, or work interactively from the Presto CLI. Below, we see a query being run, interactively from the Presto CLI.
我们还可以使用Presto CLI通过三种不同的方式运行查询。 我们可以将SQL语句传递给Presto CLI,将包含SQL语句的文件传递给Presto CLI,或从Presto CLI进行交互工作。 在下面,我们看到了从Presto CLI以交互方式运行的查询。

As the query is running, we can observe the live Presto query statistics (not very user friendly in my terminal).
当查询运行时,我们可以观察实时的Presto查询统计信息( 在我的终端中不是非常用户友好 )。

And finally, the view the query results.
最后,查看查询结果。

联合查询 (Federated Queries)
The example queries used in the demonstration and included in the project were mainly extracted from the scholarly article, Why You Should Run TPC-DS: A Workload Analysis, available as a PDF on the tpc.org website. I have modified the SQL queries to work with Presto.
演示中使用的并包含在项目中的示例查询主要摘自学术文章《 为什么要运行TPC-DS:工作量分析》 (可在tpc.org网站上以PDF 形式获得) 。 我已经修改了SQL查询以与Presto一起使用。
In the first example, we will run the three versions of the same basic query statement. Version 1 of the query is not a federated query; it only queries a single data source. Version 2 of the query queries two different data sources. Finally, version 3 of the query queries three different data sources. Each of the three versions of the SQL statement should return the same results — 93 rows of data.
在第一个示例中,我们将运行同一基本查询语句的三个版本。 该查询的版本1不是联合查询。 它仅查询单个数据源。 查询的版本2查询两个不同的数据源。 最后,查询的版本3查询三个不同的数据源。 这三个版本SQL语句应返回相同的结果-93行数据。
版本1:单一数据源 (Version 1: Single Data Source)
The first version of the query statement, sql/presto_query2.sql, is not a federated query. Each of the query’s four tables (catalog_returns, date_dim, customer, and customer_address) reference the TPC-DS data source, which came pre-installed with the PrestoDB Sandbox. Note table references on lines 11–13 and 41–42 are all associated with the tpcds.sf1 schema.
查询语句的第一个版本sql/presto_query2.sql不是联合查询。 该查询的四个表( catalog_returns , date_dim , customer和customer_address )中的每个表都引用了预存储在PrestoDB Sandbox中的TPC-DS数据源。 注意行11–13和41–42上的表引用均与tpcds.sf1模式相关联。
-- Modified version of
-- Figure 7: Reporting Query (Query 40)
-- http://www.tpc.org/tpcds/presentations/tpcds_workload_analysis.pdf
WITH customer_total_return AS (
SELECT
cr_returning_customer_sk AS ctr_cust_sk,
ca_state AS ctr_state,
sum(cr_return_amt_inc_tax) AS ctr_return
FROM
catalog_returns,
date_dim,
customer_address
WHERE
cr_returned_date_sk = d_date_sk
AND d_year = 1998
AND cr_returning_addr_sk = ca_address_sk
GROUP BY
cr_returning_customer_sk,
ca_state
)
SELECT
c_customer_id,
c_salutation,
c_first_name,
c_last_name,
ca_street_number,
ca_street_name,
ca_street_type,
ca_suite_number,
ca_city,
ca_county,
ca_state,
ca_zip,
ca_country,
ca_gmt_offset,
ca_location_type,
ctr_return
FROM
customer_total_return ctr1,
customer_address,
customer
WHERE
ctr1.ctr_return > (
SELECT
avg(ctr_return) * 1.2
FROM
customer_total_return ctr2
WHERE
ctr1.ctr_state = ctr2.ctr_state)
AND ca_address_sk = c_current_addr_sk
AND ca_state = 'TN'
AND ctr1.ctr_cust_sk = c_customer_sk
ORDER BY
c_customer_id,
c_salutation,
c_first_name,
c_last_name,
ca_street_number,
ca_street_name,
ca_street_type,
ca_suite_number,
ca_city,
ca_county,
ca_state,
ca_zip,
ca_country,
ca_gmt_offset,
ca_location_type,
ctr_return;We will run each query non-interactively using the presto-cli. We will choose the sf1 (scale factor of 1) tpcds schema. According to Presto, every unit in the scale factor (sf1, sf10, sf100) corresponds to a gigabyte of data.
我们将使用presto-cli非交互地运行每个查询。 我们将选择sf1 (比例因子为1) tpcds模式。 根据Presto ,比例因子( sf1 , sf10 , sf100 )中的每个单位都对应一个千兆字节的数据。
presto-cli \
--catalog tpcds \
--schema sf1 \
--file sql/presto_query2.sql \
--output-format ALIGNED \
--client-tags "presto_query2"Below, we see the query results in the presto-cli.
在下面,我们在presto-cli看到查询结果。
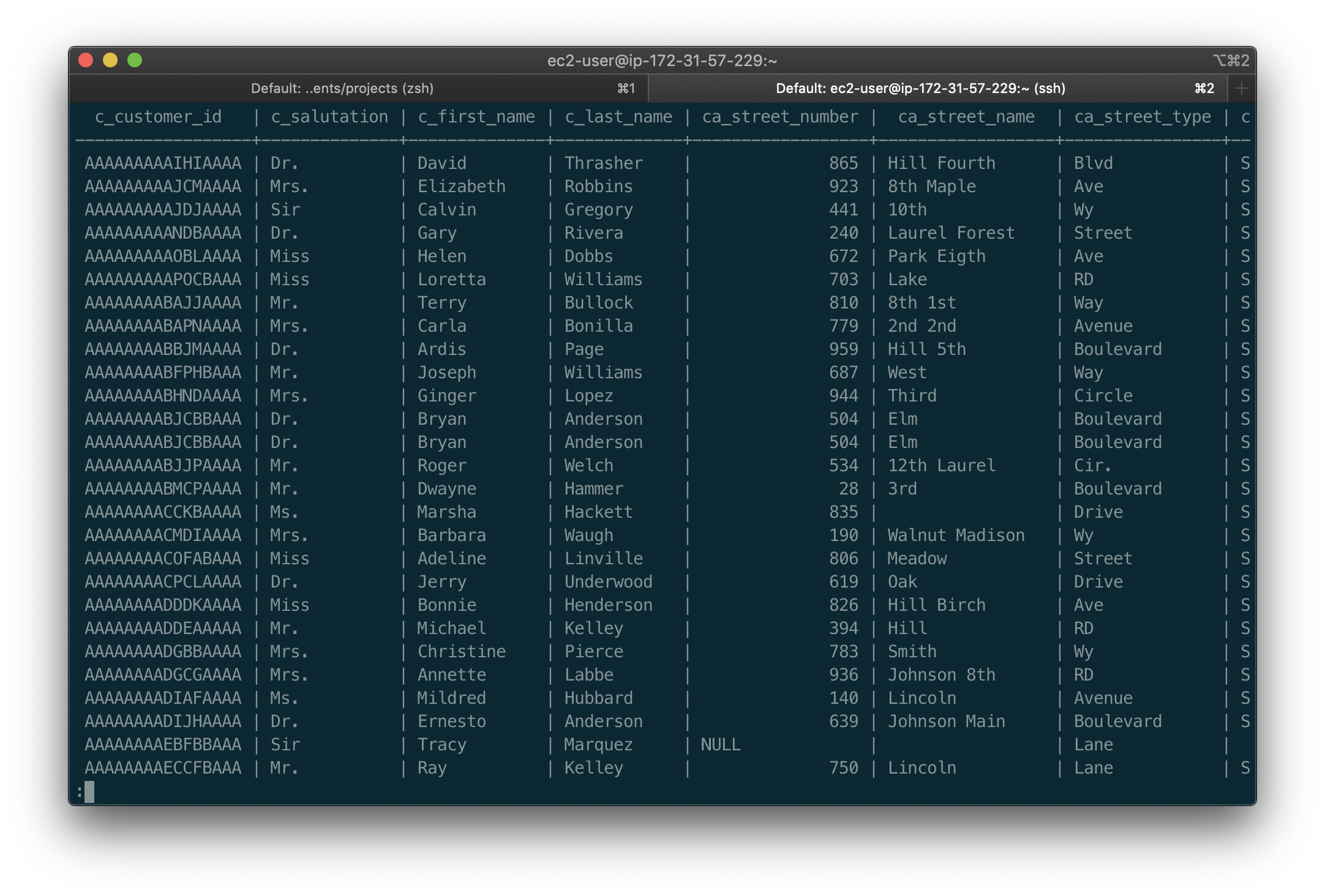
Below, we see the first query running in Presto’s web interface.
在下面,我们看到在Presto的Web界面中运行的第一个查询。

Below, we see the first query’s results detailed in Presto’s web interface.
在下面,我们在Presto的Web界面中看到了第一个查询的结果。

版本2:两个数据源 (Version 2: Two Data Sources)
In the second version of the query statement, sql/presto_query2_federated_v1.sql, two of the tables (catalog_returns and date_dim) reference the TPC-DS data source. The other two tables (customer and customer_address) now reference the Apache Hive Metastore for their schema and underlying data in Amazon S3. Note table references on lines 11 and 12, as opposed to lines 13, 41, and 42.
在查询语句的第二版sql/presto_query2_federated_v1.sql ,两个表( catalog_returns和date_dim )引用了TPC-DS数据源。 现在,其他两个表( customer和customer_address )引用了Apache Hive Metastore,以了解其架构和Amazon S3中的基础数据。 注意表参考第11和12行,与第13、41和42行相反。
-- Modified version of
-- Figure 7: Reporting Query (Query 40)
-- http://www.tpc.org/tpcds/presentations/tpcds_workload_analysis.pdf
WITH customer_total_return AS (
SELECT
cr_returning_customer_sk AS ctr_cust_sk,
ca_state AS ctr_state,
sum(cr_return_amt_inc_tax) AS ctr_return
FROM
tpcds.sf1.catalog_returns,
tpcds.sf1.date_dim,
hive.default.customer_address
WHERE
cr_returned_date_sk = d_date_sk
AND d_year = 1998
AND cr_returning_addr_sk = ca_address_sk
GROUP BY
cr_returning_customer_sk,
ca_state
)
SELECT
c_customer_id,
c_salutation,
c_first_name,
c_last_name,
ca_street_number,
ca_street_name,
ca_street_type,
ca_suite_number,
ca_city,
ca_county,
ca_state,
ca_zip,
ca_country,
ca_gmt_offset,
ca_location_type,
ctr_return
FROM
customer_total_return ctr1,
hive.default.customer_address,
hive.default.customer
WHERE
ctr1.ctr_return > (
SELECT
avg(ctr_return) * 1.2
FROM
customer_total_return ctr2
WHERE
ctr1.ctr_state = ctr2.ctr_state)
AND ca_address_sk = c_current_addr_sk
AND ca_state = 'TN'
AND ctr1.ctr_cust_sk = c_customer_sk
ORDER BY
c_customer_id,
c_salutation,
c_first_name,
c_last_name,
ca_street_number,
ca_street_name,
ca_street_type,
ca_suite_number,
ca_city,
ca_county,
ca_state,
ca_zip,
ca_country,
ca_gmt_offset,
ca_location_type,
ctr_return;Again, run the query using the presto-cli.
同样,使用presto-cli运行查询。
presto-cli \
--catalog tpcds \
--schema sf1 \
--file sql/
--output-format ALIGNED \
--client-tags "Below, we see the second query’s results detailed in Presto’s web interface.
在下面,我们在Presto的Web界面中详细查看了第二个查询的结果。
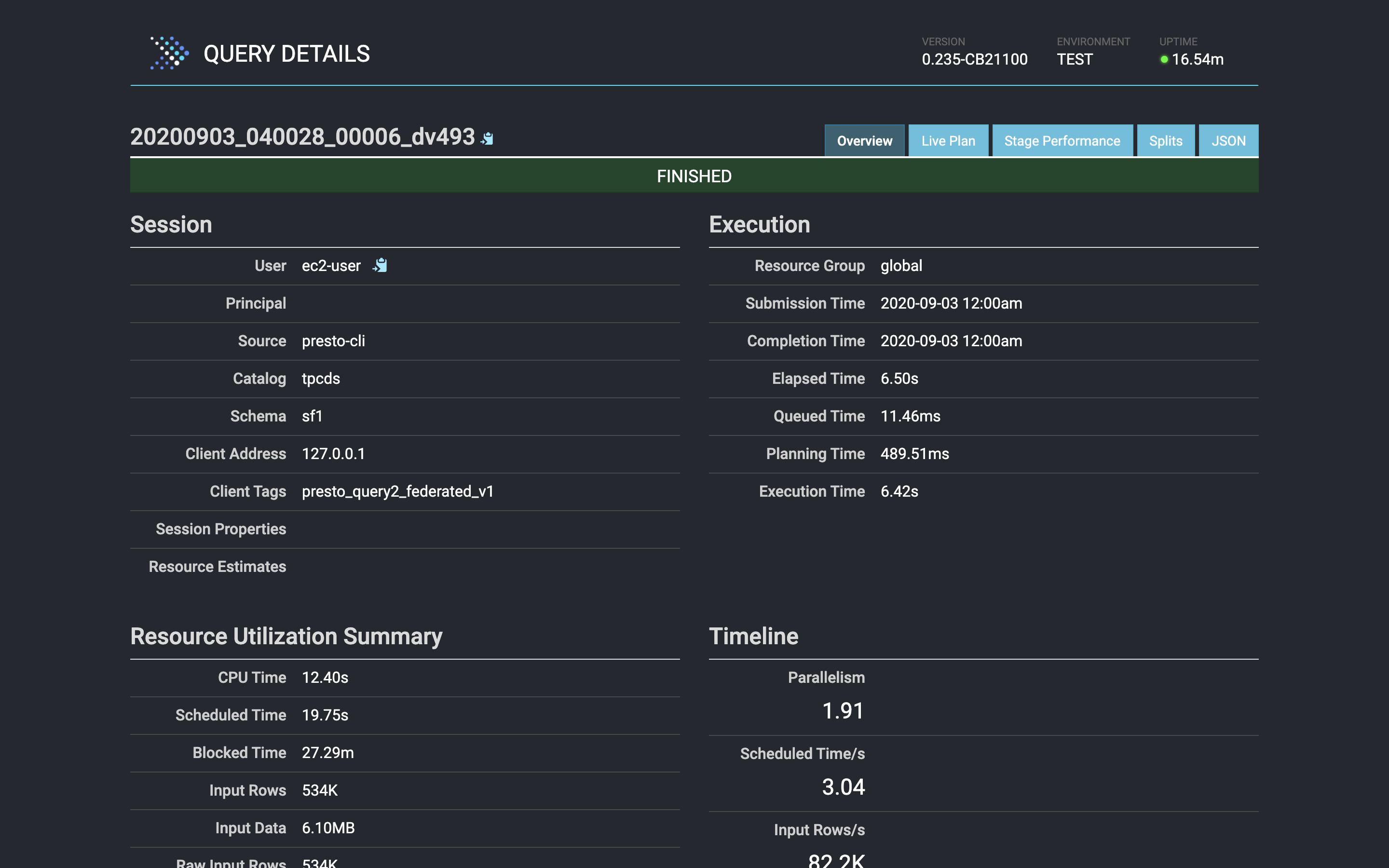
Even though the data is in two separate and physically different data sources, we can easily query it as though it were all in the same place.
即使数据位于两个单独且物理上不同的数据源中,我们也可以轻松地查询它们,就像它们都在同一位置一样。
版本3:三个数据源 (Version 3: Three Data Sources)
In the third version of the query statement, sql/presto_query2_federated_v2.sql, two of the tables (catalog_returns and date_dim) reference the TPC-DS data source. One of the tables (hive.default.customer) references the Apache Hive Metastore. The fourth table (rds_postgresql.public.customer_address) references the new RDS for PostgreSQL database instance. The underlying data is in Amazon S3. Note table references on lines 11 and 12, and on lines 13 and 41, as opposed to line 42.
在查询语句的sql/presto_query2_federated_v2.sql ,其中两个表( catalog_returns和date_dim )引用了TPC-DS数据源。 其中一个表( hive.default.customer )引用了Apache Hive Metastore。 第四个表( rds_postgresql.public.customer_address )引用了新的RDS for PostgreSQL数据库实例。 基础数据位于Amazon S3中。 与第42行相对,第11和12行以及第13和41行的注释表引用。
-- Modified version of
-- Figure 7: Reporting Query (Query 40)
-- http://www.tpc.org/tpcds/presentations/tpcds_workload_analysis.pdf
WITH customer_total_return AS (
SELECT
cr_returning_customer_sk AS ctr_cust_sk,
ca_state AS ctr_state,
sum(cr_return_amt_inc_tax) AS ctr_return
FROM
tpcds.sf1.catalog_returns,
tpcds.sf1.date_dim,
rds_postgresql.public.customer_address
WHERE
cr_returned_date_sk = d_date_sk
AND d_year = 1998
AND cr_returning_addr_sk = ca_address_sk
GROUP BY
cr_returning_customer_sk,
ca_state
)
SELECT
c_customer_id,
c_salutation,
c_first_name,
c_last_name,
ca_street_number,
ca_street_name,
ca_street_type,
ca_suite_number,
ca_city,
ca_county,
ca_state,
ca_zip,
ca_country,
ca_gmt_offset,
ca_location_type,
ctr_return
FROM
customer_total_return ctr1,
rds_postgresql.public.customer_address,
hive.default.customer
WHERE
ctr1.ctr_return > (
SELECT
avg(ctr_return) * 1.2
FROM
customer_total_return ctr2
WHERE
ctr1.ctr_state = ctr2.ctr_state)
AND ca_address_sk = c_current_addr_sk
AND ca_state = 'TN'
AND ctr1.ctr_cust_sk = c_customer_sk
ORDER BY
c_customer_id,
c_salutation,
c_first_name,
c_last_name,
ca_street_number,
ca_street_name,
ca_street_type,
ca_suite_number,
ca_city,
ca_county,
ca_state,
ca_zip,
ca_country,
ca_gmt_offset,
ca_location_type,
ctr_return;Again, we have run the query using the presto-cli.
再次,我们使用presto-cli运行查询。
presto-cli \
--catalog tpcds \
--schema sf1 \
--file sql/presto_query2_federated_v2.sql \
--output-format ALIGNED \
--client-tags "presto_query2_federated_v2"Below, we see the third query’s results detailed in Presto’s web interface.
在下面,我们在Presto的Web界面中看到了第三个查询的结果。
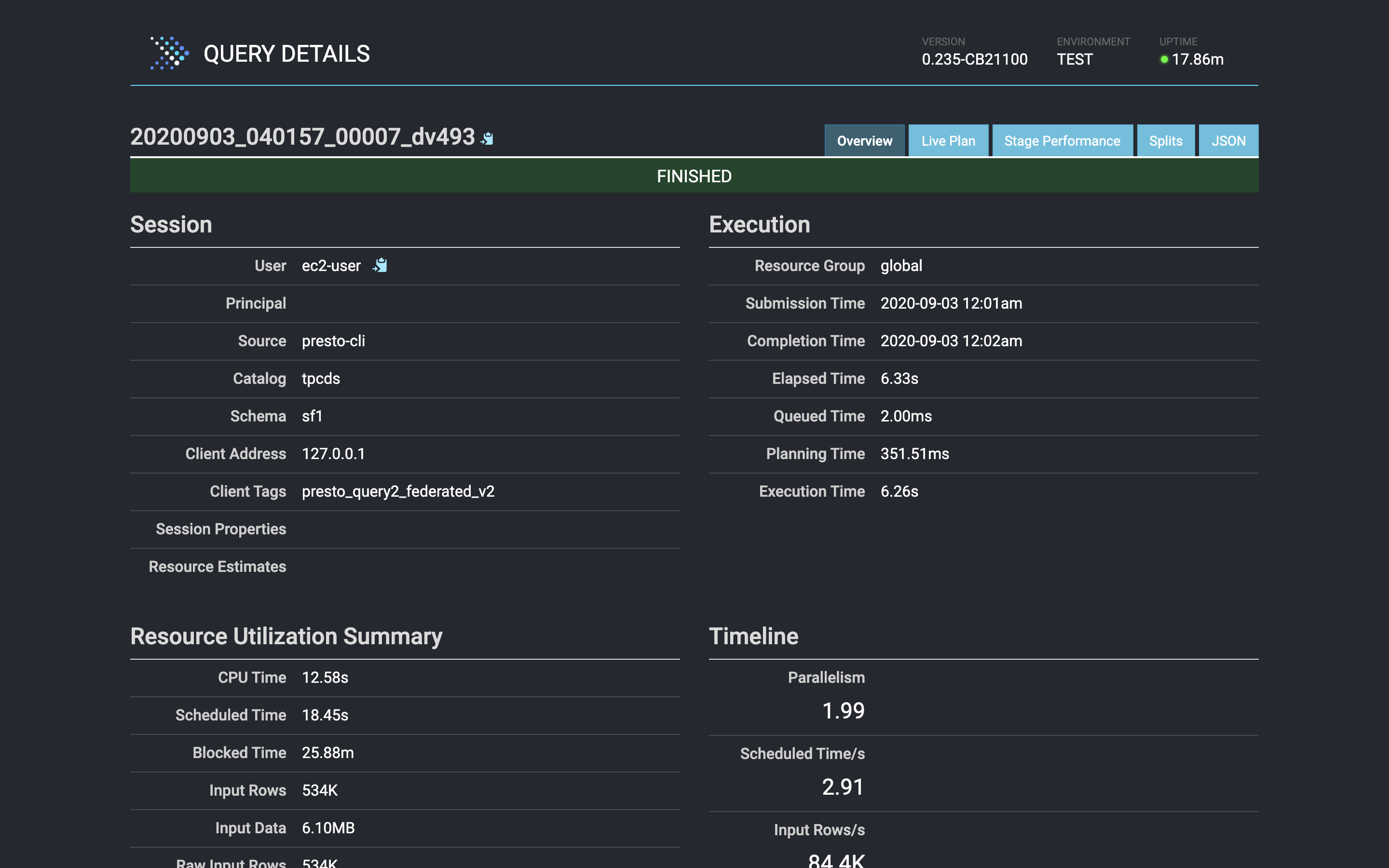
Again, even though the data is in three separate and physically different data sources, we can easily query it as though it were all in the same place.
同样,即使数据位于三个独立且物理上不同的数据源中,我们也可以轻松地查询它们,就像它们都在同一位置一样。
其他查询示例 (Additional Query Examples)
The project contains several additional query statements, which I have extracted from Why You Should Run TPC-DS: A Workload Analysis and modified work with Presto and federate across multiple data sources.
该项目包含几个其他查询语句,这些语句是我从“ 为什么应该运行TPC-DS:工作量分析”中提取的,并使用Presto进行了修改,并跨多个数据源进行了联合。
# non-federated
presto-cli \
--catalog tpcds \
--schema sf1 \
--file sql/presto_query1.sql \
--output-format ALIGNED \
--client-tags "presto_query1"# federated - two sources
presto-cli \
--catalog tpcds \
--schema sf1 \
--file sql/presto_query1_federated.sql \
--output-format ALIGNED \
--client-tags "presto_query1_federated"
# non-federated
presto-cli \
--catalog tpcds \
--schema sf1 \
--file sql/presto_query4.sql \
--output-format ALIGNED \
--client-tags "presto_query4"# federated - three sources
presto-cli \
--catalog tpcds \
--schema sf1 \
--file sql/presto_query4_federated.sql \
--output-format ALIGNED \
--client-tags "presto_query4_federated"
# non-federated
presto-cli \
--catalog tpcds \
--schema sf1 \
--file sql/presto_query5.sql \
--output-format ALIGNED \
--client-tags "presto_query5"结论 (Conclusion)
In this post, we gained a better understanding of Presto using Ahana’s PrestoDB Sandbox product from AWS Marketplace. We learned how Presto queries data where it lives, including Apache Hive, Thrift, Kafka, Kudu, and Cassandra, Elasticsearch, MongoDB, etc. We also learned about Apache Hive and the Apache Hive Metastore, Apache Parquet file format, and how and why to partition Hive data in Amazon S3. Most importantly, we learned how to write federated queries that join multiple disparate data sources without having to move the data into a single monolithic data store.
在本文中,我们使用了来自AWS Marketplace的Ahana的PrestoDB Sandbox产品对Presto有了更好的了解。 我们了解了Presto如何查询数据存放的位置,包括Apache Hive,Thrift,Kafka,Kudu和Cassandra,Elasticsearch,MongoDB等。我们还了解了Apache Hive和Apache Hive Metastore,Apache Parquet文件格式以及如何以及为什么在Amazon S3中对Hive数据进行分区。 最重要的是,我们学习了如何编写联合查询,这些查询将多个不同的数据源连接在一起,而不必将数据移至单个整体数据存储中。
This blog represents my own viewpoints and not of my employer, Amazon Web Services.
该博客代表了我自己的观点,而不代表我的雇主Amazon Web Services。
翻译自: https://towardsdatascience.com/presto-federated-queries-e8f06db95c29
sql 预先















 8308
8308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









