





An earlier article, Fact-Based AI — Improving on a Knowledge Graph, I provided a vision for Fact-Based Modelling’s future in AI while providing background knowledge to digest. Here we get straight to the facts.
较早的文章“ 基于事实的AI —在知识图上进行改进” ,我为基于事实的建模在AI中的未来提供了一个愿景,同时提供了要消化的背景知识。 在这里,我们直接了解事实。
It has become apparent within AI research that Machine Learning (ML), Deep Learning (ML), and Neural Networks, in general, are not mechanisms that lend themselves readily to “one-shot learning”.
在AI研究中,很明显,机器学习(ML),深度学习(ML)和神经网络通常不是很容易用于“一次性学习”的机制。
Neural Networks, in general, must be trained on large sets of training data resulting in a mechanism which provides a probabilistic result based on live data that approximates the training data set.
通常,必须在大量训练数据集上对神经网络进行训练,以产生一种机制,该机制可以根据逼近训练数据集的实时数据提供概率结果。
Train a suitable neural network on a set of images of a panda, then provide a new image of a panda and the neural network will give a probability of what it believes the new image to be, and hopefully that prediction is ‘a panda’.
在一组熊猫图像上训练合适的神经网络,然后提供熊猫的新图像,该神经网络将给出它认为新图像是什么样的概率,并希望预测是“ 熊猫 ”。
The less training data provided the neural network, no matter how optimised it is in its inner structure, the less chance that it will provide a favourable result. That is, you cannot reliably provide a suitable neural network with the picture of just one panda and expect it to recognise another and different picture of a panda. In general, it cannot learn a concept, or set of rules, in one shot.
提供给神经网络的训练数据越少,无论其内部结构如何优化,提供良好结果的机会就越少。 也就是说,您无法可靠地为仅一个熊猫的图片提供合适的神经网络,并不能期望它识别出另一张熊猫的图片。 通常,它无法一次学习一个概念或一组规则。
This is heavily contrasted with human learning, in which a person can readily grasp and apply knowledge learned, having only been introduced to the problem space once. This is true over a vast domain of problem spaces.
这与人类学习形成了鲜明的对比,在人类学习中,一个人只要被引入问题空间,就可以轻松地掌握和应用所学知识。 在很大范围的问题空间中都是如此。
One-shot learning is a recognised problem for Machine Learning and Deep Learning, and experts in the field are working on ways to overcome that problem. It seems unlikely to me that ML/DL strategies will get to Artificial General Intelligence (AGI) without some form of one-shot learning.
一次性学习是机器学习和深度学习公认的问题,并且该领域的专家正在研究克服该问题的方法。 在我看来,如果不进行某种形式的一次性学习,ML / DL策略就不会进入人工通用智能(AGI) 。
A problem within ML/DL approaches is that data, by way of accumulated weightings, is passed through a network of nodes and where little logic is applied to the data at each node, but rather statistics-based math is applied to the values of the accumulated weightings received by the node. The result of the applied statistical math over input data provides output data graded by probabilities, providing a probabilistic logic over the input data.
ML / DL方法中的一个问题是,数据通过累加权重传递到节点网络中,并且每个节点上的数据很少应用逻辑,而对节点的值应用了基于统计的数学节点接收的累计权重。 对输入数据应用统计数学运算的结果将提供按概率分级的输出数据,从而对输入数据提供概率逻辑。
For example, a self driving car incorporating ML/DL stops at a stop sign because it is statistically a good thing to do; because statistically that is what it has been trained to do.
例如,一辆装有ML / DL的自驾车会在停车标志处停车,因为从统计上讲这是一件好事。 因为从统计学上讲,这就是经过培训的工作。
The problem with some pass-through (or feed-forward) networks based on that strategy is that if a human face statistically has a nose, eyes, mouth, eyebrows and a chin, given a picture of a ‘face’ where an eye is replaced for a nose and vice versa, and the mouth for one of the eyes (and vice versa) the network will classify the image as a face no matter how absurd the proposition. This, because the image still has a nose, eyes, mouth, eyebrows and a chin.
一些基于该策略的直通(或前馈)网络的问题在于,如果一张人脸在统计学上具有鼻子,眼睛,嘴巴,眉毛和下巴,给定一张“脸”的图片,其中替换为鼻子,反之亦然,替换为一只眼睛的嘴(反之亦然),无论命题多么荒唐,网络都会将图像分类为面部。 这是因为图像仍然具有鼻子,眼睛,嘴巴,眉毛和下巴。
Geoffrey Hinton, influential in the rise of neural networks, has realised this problem and is in the process of developing and promoting what he calls Capsule Networks that perform localised logic processing at early stage nodes within a network such that the refined weightings provided to later-stage network nodes are better tuned to provide a more realistic approximation of the classification of input data. The idea is that providing such a network with an absurd picture of a face, the network would not classify the image as a face, because localised logic early in the network requires the parts of the face to be in their anatomically correct place.
影响神经网络兴起的杰弗里·欣顿(Geoffrey Hinton)已经意识到了这个问题,并且正在开发和推广他所谓的胶囊网络(Capsule Networks) ,该胶囊网络在网络中的早期节点上执行本地化逻辑处理,从而将精细的权重提供给以后的用户-阶段网络节点可以更好地进行调整,以提供输入数据分类的更逼真的近似值。 这样做的想法是,为这样的网络提供一张荒诞的脸部照片,该网络不会将图像分类为脸部,因为网络中早期的局部逻辑要求脸部的各个部分在其解剖学上正确的位置。
This gets us no closer to one-shot learning but introduces the concept that network nodes must perform some form of logic beyond statistical math.
这使我们无法一步一步学习,而是引入了一个概念,即网络节点必须执行统计数学以外的某种形式的逻辑。
Another problem with neural networks is that a wide range of problems are not statistical in nature, but require the finesse of predicate logic. To keep this article short, I won’t argue why, but rather simply state that you may as well provide an AI directly with a model rather than trying to statistically train the AI to learn the model. I.e. Just give the AI the model in one-shot.
神经网络的另一个问题是,许多问题本质上不是统计问题,而是需要谓词逻辑的技巧。 为了简短起见,我不会争论为什么,而只是说您可以直接向AI提供模型,而不是尝试对AI进行统计训练以学习模型。 即只要给AI在一次性模型。
Let’s have a look at an example. The following Object-Role Modeling (ORM) diagram provides the details that are required to suitably track and store the booking of seats to watch a film at a cinema.
让我们看一个例子。 以下对象角色建模(ORM)图提供了适当跟踪和存储在电影院看电影的座位预定所需的详细信息。
Instantly recognisable as a graph of data, where the data is the representation of a conceptual model, the information captures a constraint necessary to book seats for a movie:
可以立即识别为数据 图 ,其中数据是概念模型的表示,该信息捕获了预订电影座位所需的约束:
If some Booking has some Seat, thenthat Booking is for some Session that is at some Cinema that contains some Row that contains that Seat
如果某些预定有一些座椅,thenthat预定是对于一些会议是在一些电影,其中包含一些行包含座椅
Such predicate processing is beyond most neural networks because they do not contain predicate logic processing at the node level; but I feel that is where the technology must head for one-shot learning.
这种谓词处理超出了大多数神经网络的范围,因为它们在节点级别不包含谓词逻辑处理。 但是我觉得这是该技术必须一站式学习的地方。
Simplistic feed-forward neural networks just will not cut it when it comes to enforcing rules for models like the one above, however for an AGI such models will be commonplace.
当涉及到上述模型的规则执行时,简单的前馈神经网络不会减少它,但是对于AGI来说,这种模型很普遍。
Localised predicate checking will be required at the node/neuron level, and intra-node.
在节点/神经元级别以及节点内将需要局部谓词检查。
Fact-Based Models stored as ORM models are ideal for storing within the matrix of nodes within a neural network because of their intrinsic graph-based notation, where each node in the graph represents a piece of the logical model it represents.
存储为ORM模型的基于事实的模型非常适合用于存储在神经网络中的节点矩阵中,这是因为它们具有基于图的内在表示法,其中图中的每个节点都代表了它所代表的逻辑模型。
AI solutions based on predicate logic have received negative press in the past. For instance, the Cyc project has been labelled a failure in the past; purportedly because early iterations of Cyc relied exclusively on predicate logic and induction. However, the basic premise that an AGI must be able to process predicate logic is not in question. If AGI is ever to be an amalgam of predicate logic and neural networks, then predicate logic must be stored in its model. It seems that Cycorp have realised this and have started to work with deep learning and fact based reasoning.
过去,基于谓词逻辑的AI解决方案受到负面报道。 例如, Cyc项目在过去曾被标记为失败 ; 据说是因为Cyc的早期迭代完全依赖于谓词逻辑和归纳。 但是,AGI必须能够处理谓词逻辑的基本前提是没有问题的。 如果AGI曾经是谓词逻辑和神经网络的混合物,那么谓词逻辑必须存储在其模型中。 Cycorp似乎已经意识到这一点,并已开始进行深度学习和基于事实的推理工作 。
My research at Viev is geared towards providing the tools to construct fact-based models, the metamodel of which can be incorporated into a new wave of neural networks that incorporate logic processing at the node/neuron level.
我在Viev的研究旨在提供构建基于事实的模型的工具,该模型的元模型可以并入到新的神经网络浪潮中,这些神经网络在节点/神经元级别合并了逻辑处理。
A benefit of using Object-Role Modelling within the logic store of an AI is that in many cases natural language generation is not required. The effort required to generate natural language is significantly reduced because ORM stores facts in natural language in the first place and in a logical structure that is a homomorphism to sentences of a first-order logic.
在AI的逻辑存储中使用对象角色建模的好处是,在许多情况下不需要自然语言生成 。 生成自然语言所需的工作量大大减少了,因为ORM首先将事实存储在自然语言中,并且存储在与一阶逻辑的句子同构的逻辑结构中。
In the example above, an AI responding to a general statement made by Alice, “I booked a seat at the cinema”, can readily identify a/the candidate model of the world that Alice is talking about, and transverse the graph to ask questions such as, “Which session was that for?”, or “How many seats did you book?”, “What film was that for?”, etc with extrapolation of the language already stored in the model.
在上面的示例中,响应Alice的一般声明(“我在电影院预定座位”)的AI可以轻松识别Alice正在谈论的世界的候选模型,并横穿图表提出问题例如,“该预定哪个会议?”或“您预定了多少个座位?”,“该预定什么电影?”等,通过对模型中已经存储的语言进行推断。
在模型内存储数据,以及模型作为数据存储的位置 (Storing data within the model, and where the model is stored as data)
Object-Role Modeling is a type of Fact-Based Modeling and more than storing the meta information about facts, such as that people can book seats at a cinema, ORM can store actual data about those facts.
对象角色建模是一种基于事实的建模 ,它不仅存储有关事实的元信息,例如人们可以在电影院预订座位,ORM可以存储有关这些事实的实际数据。
The same model as represented above, can store the information about Alice having booked a seat at a cinema; as below and where Alice has a Person_Id of 1:
与上述相同的模型可以存储有关爱丽丝已在电影院预订座位的信息; 如下所示,其中Alice的Person_Id为1:
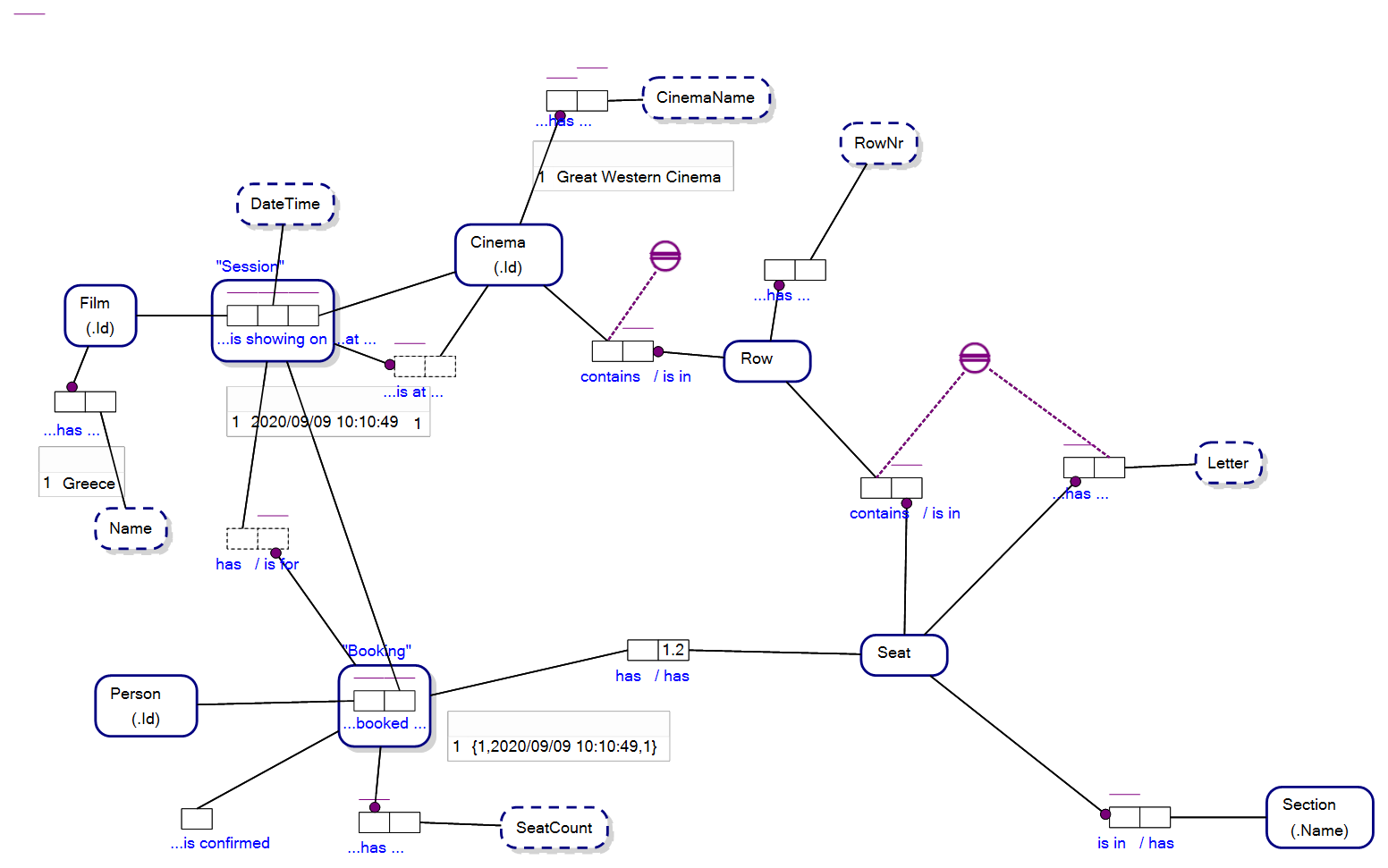
So with Object-Role Modeling at the core of a Fact-Based AI, not only can the model be stored as data, but facts that relate to the model can be stored within the model. The model and the fact data are just data.
因此,以基于事实的AI为核心的对象角色建模,不仅可以将模型存储为数据,而且可以将与模型相关的事实存储在模型中。 模型和事实数据仅是数据。
Neural networks are already a graph of data. Fact-Based AI, in a nutshell, is incorporating models/schemas and their related data as nodes within that graph within a neural network or predicate logic based AI.
神经网络已经是数据图。 简而言之,基于事实的AI将模型/方案及其相关数据合并为神经网络或基于谓词逻辑的AI中该图内的节点。
I hope this has been helpful to AI researchers looking to forge a new path. As time permits I will write more on Fact-Based AI and Object-Role Modeling.
我希望这对寻求开辟新道路的AI研究人员有所帮助。 如果时间允许,我将写更多有关基于事实的AI和对象角色建模的文章。
— — — — — — — — — -
— — — — — — — — — — —
NB The original version of the model expressed in this article is copyright to DataConstellation and is shared under the ActiveFacts project on GitHub: https://github.com/cjheath/activefacts
注意 :本文表达的模型的原始版本是DataConstellation的版权,并在GitHub上的ActiveFacts项目下共享: https : //github.com/cjheath/activefacts
翻译自: https://towardsdatascience.com/fact-based-ai-in-a-nutshell-62a184880e37















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









