





pinot
One of the primary advantages of using Pinot is its pluggable architecture. The plugins make it easy to add support for any third-party system which can be an execution framework, a filesystem, or input format.
使用Pinot的主要优点之一是可插拔的体系结构 。 插件使添加对任何第三方系统的支持变得容易,这些第三方系统可以是执行框架,文件系统或输入格式。
In this tutorial, we will use three such plugins to easily ingest data and push it to our Pinot cluster. The plugins we will be using are -
在本教程中,我们将使用三个这样的插件轻松提取数据并将其推送到我们的Pinot集群。 我们将使用的插件是-
pinot-batch-ingestion-sparkpinot-batch-ingestion-sparkpinot-s3pinot-s3pinot-parquetpinot-parquet
You can check out Batch Ingestion, File systems, and Input formats for all the available plugins.
您可以查看所有可用插件的Batch Ingestion , File systems和Input格式 。
建立 (Setup)
We are using the following tools and frameworks for this tutorial -
我们在本教程中使用以下工具和框架-
Apache Spark 2.2.3 (Although any spark 2.X should work)
Apache Spark 2.2.3 (尽管任何spark 2.X都可以使用)

输入数据 (Input Data)
We need to get input data to ingest first. For our demo, we’ll just create some small Parquet files and upload them to our S3 bucket. The easiest way is to create CSV files and then convert them to Parquet. CSV makes it human-readable and thus easier to modify the input in case of some failure in our demo. We will call this file students.csv
我们需要首先获取输入数据。 对于我们的演示,我们将只创建一些小的Parquet文件并将其上传到我们的S3存储桶。 最简单的方法是创建CSV文件,然后将它们转换为Parquet。 CSV使其易于阅读,因此在演示中出现某些故障时可以更轻松地修改输入。 我们称这个文件为students.csv
Now, we’ll create Parquet files from the above CSV file using Spark. Since this is a small program, we will be using the Spark shell instead of writing a full-fledged Spark code.
现在,我们将使用Spark从上述CSV文件创建Parquet文件。 由于这是一个小程序,因此我们将使用Spark Shell,而不是编写完整的Spark代码。
The .parquet files can now be found in /path/to/batch_input directory. You can now upload this directory to S3 either using their UI or running the following command
.parquet文件现在可以在/path/to/batch_input目录中找到。 现在,您可以使用用户界面或运行以下命令将此目录上传到S3
aws s3 cp /path/to/batch_input s3://my-bucket/batch-input/ --recursive创建架构和表 (Create Schema and Table)
We need to create a table to query the data that will be ingested. All tables in Pinot are associated with a schema. You can check out Table configuration and Schema configuration for more details on creating configurations.
我们需要创建一个表来查询将被摄取的数据。 Pinot中的所有表都与模式关联。 您可以检出表配置和模式配置,以获取有关创建配置的更多详细信息。
For our demo, we will have the following schema and table configs
对于我们的演示,我们将具有以下架构和表配置
We can now upload these configurations to Pinot and create an empty table. We will be using pinot-admin.sh CLI for this purpose.
现在我们可以将这些配置上传到Pinot并创建一个空表。 为此,我们将使用pinot-admin.sh CLI。
pinot-admin.sh AddTable -tableConfigFile /path/to/student_table.json -schemaFile /path/to/student_schema.json -controllerHost localhost -controllerPort 9000 -execYou can check out Command-Line Interface (CLI) for all the available commands.
您可以检出所有可用命令的命令行界面(CLI) 。
Our table will now be available in the Pinot data explorer
我们的表格现在将在Pinot数据浏览器中可用
提取数据 (Ingest Data)
Now that our data is available in S3 as well as we have the Tables in Pinot, we can start the process of ingesting the data. Data ingestion in Pinot involves the following steps -
现在我们的数据在S3中可用,并且在黑皮诺中有表格,我们可以开始提取数据的过程。 Pinot中的数据提取涉及以下步骤-
- Read data and generate compressed segment files from input 读取数据并从输入生成压缩的段文件
- Upload the compressed segment files to the output location 将压缩的段文件上传到输出位置
- Push the location of the segment files to the controller 将段文件的位置推送到控制器
Once the location is available to the controller, it can notify the servers to download the segment files and populate the tables.
控制器可以使用该位置后,它可以通知服务器下载段文件并填充表。
The above steps can be performed using any distributed executor of your choice such as Hadoop, Spark, Flink, etc. For this demo, we will be using Apache Spark to execute the steps.
可以使用您选择的任何分布式执行器(例如Hadoop,Spark,Flink等)执行以上步骤。对于本演示,我们将使用Apache Spark执行这些步骤。
Pinot provides runners for Spark out of the box. So as a user, you don’t need to write a single line of code. You can write runners for any other executor using our provided interfaces.
Pinot开箱即用地为Spark提供了运行程序。 因此,作为用户,您无需编写任何代码。 您可以使用我们提供的界面为其他执行程序编写运行程序。
First, we will create a job spec configuration file for our data ingestion process.
首先,我们将为我们的数据提取过程创建一个作业规范配置文件。
In the job spec, we have kept the execution framework as spark and configured the appropriate runners for each of our steps. We also need a temporary stagingDir for our spark job. This directory is cleaned up after our job has executed.
在工作规范中,我们将执行框架保持为spark并为我们的每个步骤配置了合适的运行器。 我们还需要一个临时的stagingDir来完成我们的火花工作。 执行我们的作业后,将清理此目录。
We also provide the S3 Filesystem and Parquet reader implementation in the config to use. You can refer Ingestion Job Spec for a complete list of configurations.
我们还在配置中提供了S3 Filesystem和Parquet阅读器实现以供使用。 您可以参考“ 提取作业规范”以获取配置的完整列表。
We can now run our Spark job to execute all the steps and populate data in Pinot.
现在,我们可以运行Spark作业来执行所有步骤,并在Pinot中填充数据。
In the command, we have included the JARs of all the required plugins in the Spark’s driver classpath. In practice, you only need to do this if you get a ClassNotFoundException.
在命令中,我们将所有必需插件的JAR包含在Spark的driver classpath 。 实际上,仅当您收到ClassNotFoundException时才需要这样做。
Voila! Now our data is successfully ingested. Let’s try to query it from Pinot’s broker.
瞧! 现在,我们的数据已成功提取。 让我们尝试从Pinot的经纪人那里查询它。
bin/pinot-admin.sh PostQuery -brokerHost localhost -brokerPort 8000 -queryType sql -query "SELECT * FROM students LIMIT 10"If everything went right, you should receive the following output
如果一切正常,您应该收到以下输出
You can also view the results in the Data explorer UI.
您也可以在数据资源管理器UI中查看结果。
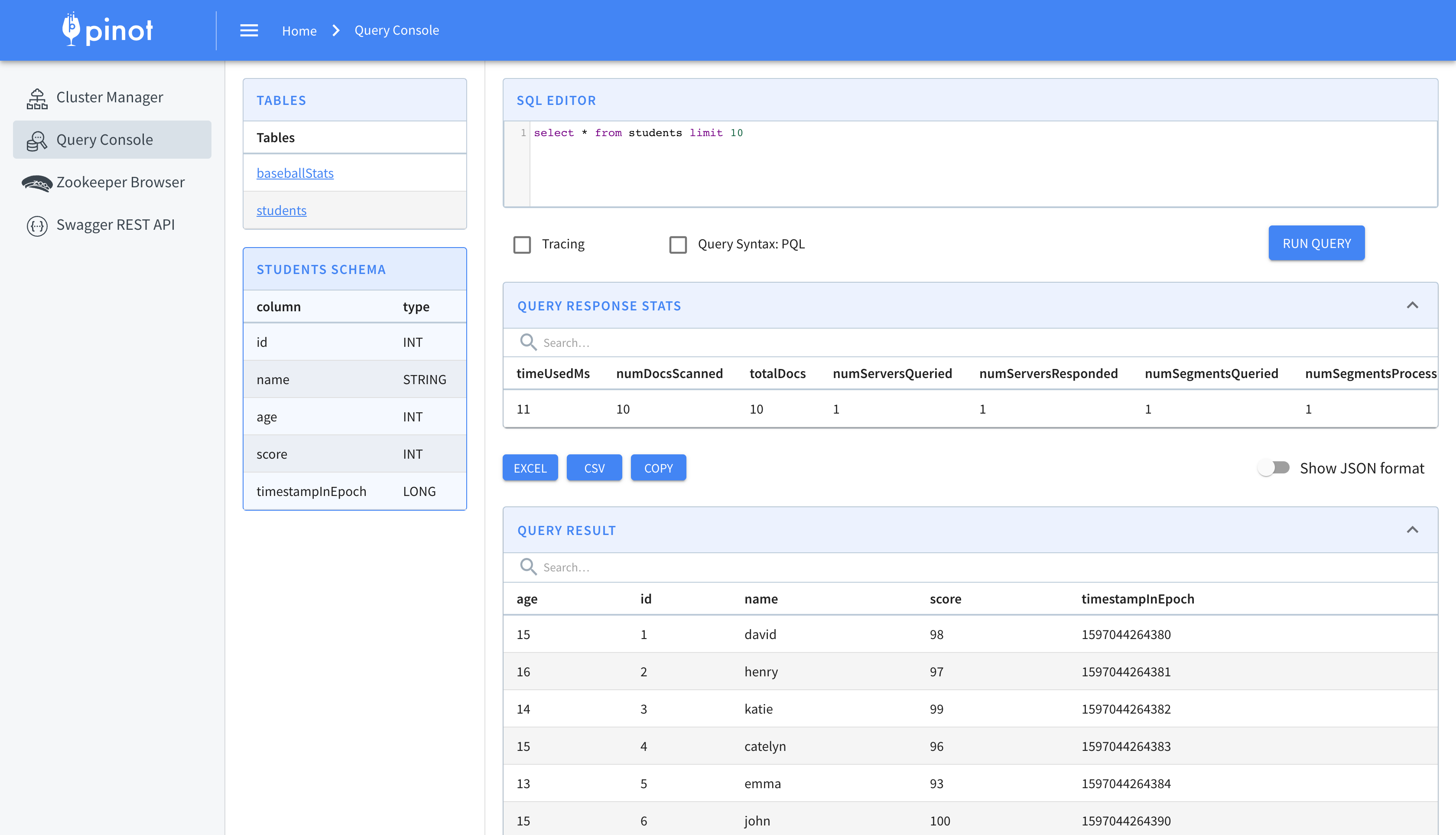
Pinot’s powerful pluggable architecture allowed us to successfully ingest parquet records from S3 with just a few configurations. The process described in this article is highly-scalable and can be used to ingest billions of records with minimal latency.
Pinot强大的可插拔体系结构使我们仅需少量配置即可成功地从S3提取实木复合地板记录。 本文中描述的过程是高度可伸缩的,可用于以最小的延迟获取数十亿条记录。
You can check out Pinot on the official website. Refer to our documentation to get started with the setup and in the case of any issues, the community is there to help on the official slack channel.
您可以在官方网站上查看Pinot。 请参阅我们的文档以开始设置,如果有任何问题,社区可以在官方的松弛频道上为您提供帮助。
pinot















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









