





机器学习模型 非线性模型
Introduction
介绍
In this article, I’d like to speak about linear models by introducing you to a real project that I made. The project that you can find in my Github consists of predicting the prices of fiat 500.
在本文中,我想通过向您介绍我所做的真实项目来谈论线性模型。 您可以在我的Github中找到的项目包括预测菲亚特500的价格。
The dataset for my model presents 8 columns as you can see below and 1538 rows.
我的模型的数据集包含8列(如下所示)和1538行。
- model: pop, lounge, sport 模特:流行,休闲,运动
- engine_power: Kw of the engine engine_power:发动机的千瓦
- age_in_days: age of the car in days age_in_days:汽车的使用天数
- km: kilometres of the car km:汽车的公里数
- previous_owners: number of previous owners previous_owners:以前的所有者数
- lat: latitude of the seller (the price of cars in Italy varies from North to South of the country) lat:卖方的纬度(意大利的汽车价格从该国的北部到南部不等)
- lon: longitude of the seller (the price of cars in Italy varies from North to South of the country) lon:卖方的经度(意大利的汽车价格从该国的北部到南部不等)
- price: selling price 价格:售价
During this article, we will see in the first part some concepts about the linear regression, the ridge regression and the lasso regression. Then I will show you the fundamental insights that I found about the dataset I considered and last but not least we will see the preparation and the metrics I used to evaluate the performance of my model.
在本文中,我们将在第一部分中看到有关线性回归,岭回归和套索回归的一些概念。 然后,我将向您展示我对所考虑的数据集的基本见解,最后但并非最不重要的一点是,我们将看到用于评估模型性能的准备工作和度量标准。
Part I: Linear Regression, Ridge Regression and Lasso Regression
第一部分:线性回归,岭回归和套索回归
Linear models are a class of models that make a prediction using a linear function of the input features.
线性模型是使用输入要素的线性函数进行预测的一类模型。
For what concerns regression, as we know the general formula looks like as follows:
对于回归问题,我们知道一般公式如下所示:

As you already know x[0] to x[p] represents the features of a single data point. Instead, m a b are the parameters of the model that are learned and ŷ is the prediction the model makes.
如您所知,x [0]至x [p]表示单个数据点的特征。 取而代之的是,m是一B是被学习的模型的参数,y是预测的模型使。
There are many linear models for regression. The difference between these models is about how the model parameters m and b are learned from the training data and how model complexity can be controlled. We will see three models for regression.
有许多线性模型可用于回归。 这些模型之间的差异在于如何从训练数据中学习模型参数m和b以及如何控制模型复杂性。 我们将看到三种回归模型。
Linear regression (ordinary least squares) → it finds the parameters m and b that minimize the mean squared error between predictions and the true regression targets, y, on the training set. The MSE is the sum of the squared differences between the predictions and the true value. Below how to compute it with scikit-learn.
线性回归(普通最小二乘) →它找到参数m和b ,该参数使训练集上的预测与真实回归目标y之间的均方误差最小。 MSE是预测值与真实值之间平方差的总和。 下面是如何使用scikit-learn计算它。
from sklearn.linear_model import LinearRegression X_train, X_test, y_train, y_test=train_test_split(X, y, random_state=0)lr = LinearRegression()lr.fit(X_train, y_train)print(“lr.coef_: {}”.format(lr.coef_)) print(“lr.intercept_: {}”.format(lr.intercept_))Ridge regression → the formula it uses to make predictions is the same one used for the linear regression. In the ridge regression, the coefficients(m) are chosen for predicting well on the training data but also to fit the additional constraint. We want all entries of m should be close to zero. That means each feature should have a little effect on the outcome as possible(small slope), while still predicting well. This constraint is called regularization which means restricting a model to avoid overfitting. The particular ridge regression regularization is known as L2. Ridge regression is implemented in linear_model.Ridge as you can see below. In particular, by increasing alpha, we move the coefficients toward zero, which decreases training set performance but might help generalization and avoid overfitting.
Ridge回归 →用于进行预测的公式与用于线性回归的公式相同。 在岭回归中,选择系数(m)可以很好地预测训练数据,但也可以拟合附加约束。 我们希望m的所有条目都应接近零。 这意味着每个特征都应该对结果产生尽可能小的影响(小斜率),同时仍能很好地预测。 此约束称为正则化,这意味着限制模型以避免过度拟合。 特定的岭回归正则化称为L2。 Ridge回归在linear_model.Ridge中实现,如下所示。 特别是,通过增加alpha,我们会将系数移向零,这会降低训练集的性能,但可能有助于泛化并避免过度拟合。
from sklearn.linear_model import Ridge ridge = Ridge(alpha=11).fit(X_train, y_train)print(“Training set score: {:.2f}”.format(ridge.score(X_train, y_train))) print(“Test set score: {:.2f}”.format(ridge.score(X_test, y_test)))Lasso regression → an alternative for regularizing is Lasso. As with ridge regression, using the lasso also restricts coefficients to be close to zero, but in a slightly different way, called L1 regularization. The consequence of L1 regularization is that when using the lasso, some coefficients are exactly zero. This means some features are entirely ignored by the model.
拉索回归 →拉索正则化的替代方法。 与ridge回归一样,使用套索也将系数限制为接近零,但方式略有不同,称为L1正则化。 L1正则化的结果是,使用套索时,某些系数正好为零。 这意味着模型将完全忽略某些功能。
from sklearn.linear_model import Lasso lasso = Lasso(alpha=3).fit(X_train, y_train)
print(“Training set score: {:.2f}”.format(lasso.score(X_train, y_train))) print(“Test set score: {:.2f}”.format(lasso.score(X_test, y_test))) print(“Number of features used: {}”.format(np.sum(lasso.coef_ != 0)))Part II: Insights that I found
第二部分:我发现的见解
Before to see the part about the preparation and evaluation of the model, it is useful to take a look at the situation of the dataset.
在查看有关模型准备和评估的部分之前,先了解一下数据集的情况是很有用的。
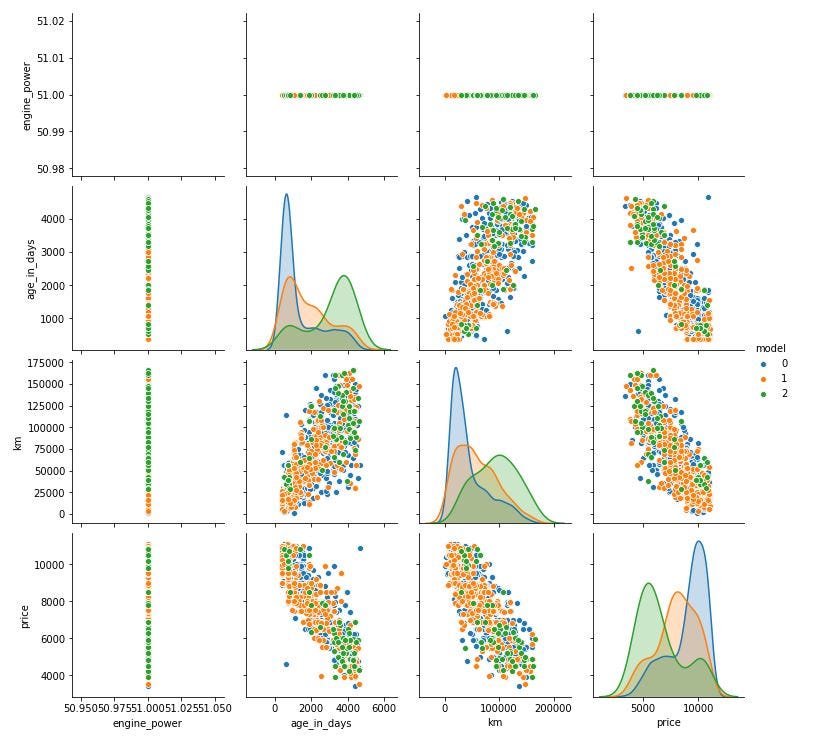
In the below scatter matrix we can observe that there some particular correlations between some features like km, age_in_days and price.
在下面的散点矩阵中,我们可以观察到某些特征(例如km,age_in_days和价格)之间存在某些特定的相关性。
Instead in the following correlation-matrix, we can see very well the result of correlations between the features.
相反,在下面的相关矩阵中,我们可以很好地看到特征之间的相关结果。
In particular, between age_in_days and price or km and price, we have a great correlation.
特别是在age_in_days和价格之间或km和价格之间,我们有很大的相关性。
This is the starting point for constructing our model and know which machine learning model could be fit better.
这是构建我们的模型的起点,并且知道哪种机器学习模型更合适。

Part III: Prepare and evaluate the performance of the model
第三部分:准备和评估模型的性能
To train and test the dataset I used the Linear Regression.
为了训练和测试数据集,我使用了线性回归。
from sklearn.linear_model import LinearRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
lr = LinearRegression()
lr.fit(X_train, y_train)out:
出:
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)In the following table, there are the coefficients for each feature that I considered for my model.
下表列出了我为模型考虑的每个功能的系数。
coef_df = pd.DataFrame(lr.coef_, X.columns, columns=['Coefficient'])
coef_dfout:
出:

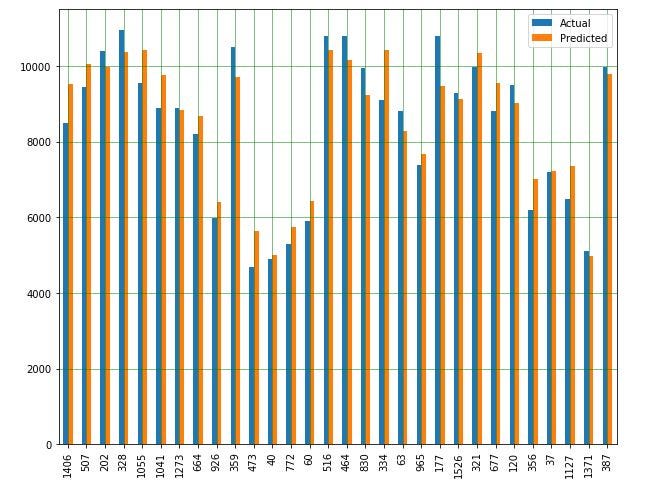
Now, it is time to evaluate the model. In the following graph, characterized by a sample of 30 data points, we can observe the comparison between predicted values and actual values. As we can see our model is pretty good.
现在,该评估模型了。 在以30个数据点为样本的下图中,我们可以观察到预测值与实际值之间的比较。 我们可以看到我们的模型非常好。
The R-squared is a good measure of the ability of the model inputs to explain the variation of the dependent variables. In our case, we have 85%.
R平方可以很好地衡量模型输入解释因变量变化的能力。 就我们而言,我们有85%。
from sklearn.metrics import r2_score round(sklearn.metrics.r2_score(y_test, y_pred), 2)out:
出:
0.85Now I compute the MAE, MSE and the RMSE to have a more precise overview of the performance of the model.
现在,我计算MAE,MSE和RMSE,以更精确地概述模型的性能。
from sklearn import metrics print(‘Mean Absolute Error:’, metrics.mean_absolute_error(y_test, y_pred)) print(‘Mean Squared Error:’, metrics.mean_squared_error(y_test, y_pred))print(‘Root Mean Squared Error:',
np.sqrt(metrics.mean_squared_error(y_test, y_pred)))Finally, by comparing the training set score and the test set score we can see how performative is our model.
最后,通过比较训练集得分和测试集得分,我们可以看到模型的性能如何。
print("Training set score: {:.2f}".format(lr.score(X_train, y_train)))print("Test set score: {:.2f}".format(lr.score(X_test, y_test)))out:
出:
Training set score: 0.83 Test set score: 0.85Conclusion
结论
Linear models are a class of models that are widely used in practice and have been studied extensively in the last few years in particular for machine learning. So, with this article, I hope you have obtained a good starting point in order to improve yourself and create your own Linear model.
线性模型是一类在实践中广泛使用的模型,并且在最近几年中,特别是对于机器学习,已经进行了广泛的研究。 因此,希望本文能够为您提高自己并创建自己的线性模型提供一个良好的起点。
Thanks for reading this. There are some other ways you can keep in touch with me and follow my work:
感谢您阅读本文。 您可以通过其他方法与我保持联系并关注我的工作:
Subscribe to my newsletter.
订阅我的时事通讯。
You can also get in touch via my Telegram group, Data Science for Beginners.
您也可以通过我的电报小组“ 面向初学者的数据科学”来联系 。
机器学习模型 非线性模型
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









