





python 实现分步累加
As data scientists, we are always on the look for new data and information to analyze and manipulate. One of the main approaches to find data right now is scraping the web for a particular inquiry.
作为数据科学家,我们一直在寻找新的数据和信息进行分析和处理。 目前查找数据的主要方法之一是抓取特定查询的网络。
When we browse the internet, we come across a massive number of websites, these websites display various data on the browser. If we, for some reason want to use this data for a project or an ML algorithm, we can — but shouldn’t — gather this data manually. So, we will copy the sections we want and paste them in a doc or CSV file.
当我们浏览Internet时,我们会遇到大量网站,这些网站在浏览器上显示各种数据。 如果出于某种原因我们想要将此数据用于项目或ML算法,我们可以(但不应该)手动收集此数据。 因此,我们将复制所需的部分并将其粘贴到doc或CSV文件中。
Needless to say, that will be quite a tedious task. That’s why most data scientists and developers go with web scraping using code. It’s easy to write code to extract data from a 100 webpage than do them by hand.
不用说,这将是一个繁琐的任务。 这就是为什么大多数数据科学家和开发人员都使用代码进行Web抓取的原因。 与手动编写代码相比,编写代码从100个网页提取数据要容易得多。
Web Scraping is the technique used by programmers to automate the process of finding and extracting data from the internet within a relatively short time.
Web Scraping是程序员用来在相对较短的时间内自动从Internet查找和提取数据的过程的技术。
The most important question when it comes to web scraping, is it legal?
关于网页抓取,最重要的问题是合法的吗?
网站抓取合法吗? (Is web scraping legal?)
Short answer, yes.
简短的回答, 是的 。
The more detailed answer, scraping publically available data for non-commercial purposes was announced to be completely legal in late January 2020.
更为详细的答案是,出于非商业目的收集可公开获得的数据在2020年1月下旬宣布是完全合法的。
You might wonder, what does publically available mean?
您可能想知道, 公开可用是什么意思?
Publically available information is the information that anyone can see/ find on the internet without the need for special access. So, information on Wikipedia, social media or Google’s search results are examples of publically available data.
公开信息是任何人都可以在互联网上看到/找到的信息,而无需特殊访问。 因此,有关维基百科,社交媒体或Google搜索结果的信息就是公开可用数据的示例。
Now, social media is somewhat complicated, because there are parts of it that are not publically available, such as when a user sets their information to be private. In this case, this information is illegal to be scraped.
现在,社交媒体有些复杂,因为社交媒体的某些部分是不公开的,例如当用户将其信息设置为私人信息时。 在这种情况下,此信息被非法删除。
One last thing, there’s a difference between publically available and copyrighted. For example, you can scrap YouTube for video titles, but you can’t use the videos for commercial use because they are copyrighted.
最后一件事,公开可用和受版权保护之间有区别。 例如,您可以删除YouTube上的视频标题,但不能将其用于商业用途,因为它们已受版权保护。
如何抓取网页? (How to scrap the web?)
There are different programming languages that you can use to scrape the web, and within every programming language, there are different libraries to achieve the same goal.
您可以使用多种编程语言来抓取Web,并且在每种编程语言中,都有不同的库可以实现相同的目标。
So, what to use?
那么,使用什么呢?
In this article, I will use Python, Requests, and BeautifulSoup to scrap some pages from Wikipedia.
在本文中,我将使用Python , Requests和BeautifulSoup从Wikipedia抓取一些页面。
To scrap and extract any information from the internet, you’ll probably need to go through three stages: Fetching HTML, Obtaining HTML Tree, then Extracting information from the tree.
要从互联网上抓取和提取任何信息,您可能需要经历三个阶段:获取HTML,获取HTML树,然后从树中提取信息。

We will use the Requests library to fetch the HTML code from a specific URL. Then, we will use BeautifulSoup to Parse and Extract the HTML tree, and finally, we will use pure Python to organize the data.
我们将使用Requests库从特定的URL提取HTML代码。 然后,我们将使用BeautifulSoup解析和提取HTML树,最后,我们将使用纯Python来组织数据。
基本HTML (Basic HTML)
Before we get scraping, let’s revise HTML basics quickly. Everything in HTML is defined within tags. The most important tag is <HTML> which means that the text to follow is HTML code.
在抓取之前,让我们快速修改HTML基础。 HTML中的所有内容都在标记中定义。 最重要的标记是<HTML>,这意味着要跟随的文本是HTML代码。
In HTML, each opened tag must be closed. So, at the end of the HTML file, we need a closure tag </HTML>.
在HTML中,必须关闭每个打开的标签。 因此,在HTML文件的末尾,我们需要一个结束标记</ HTML>。
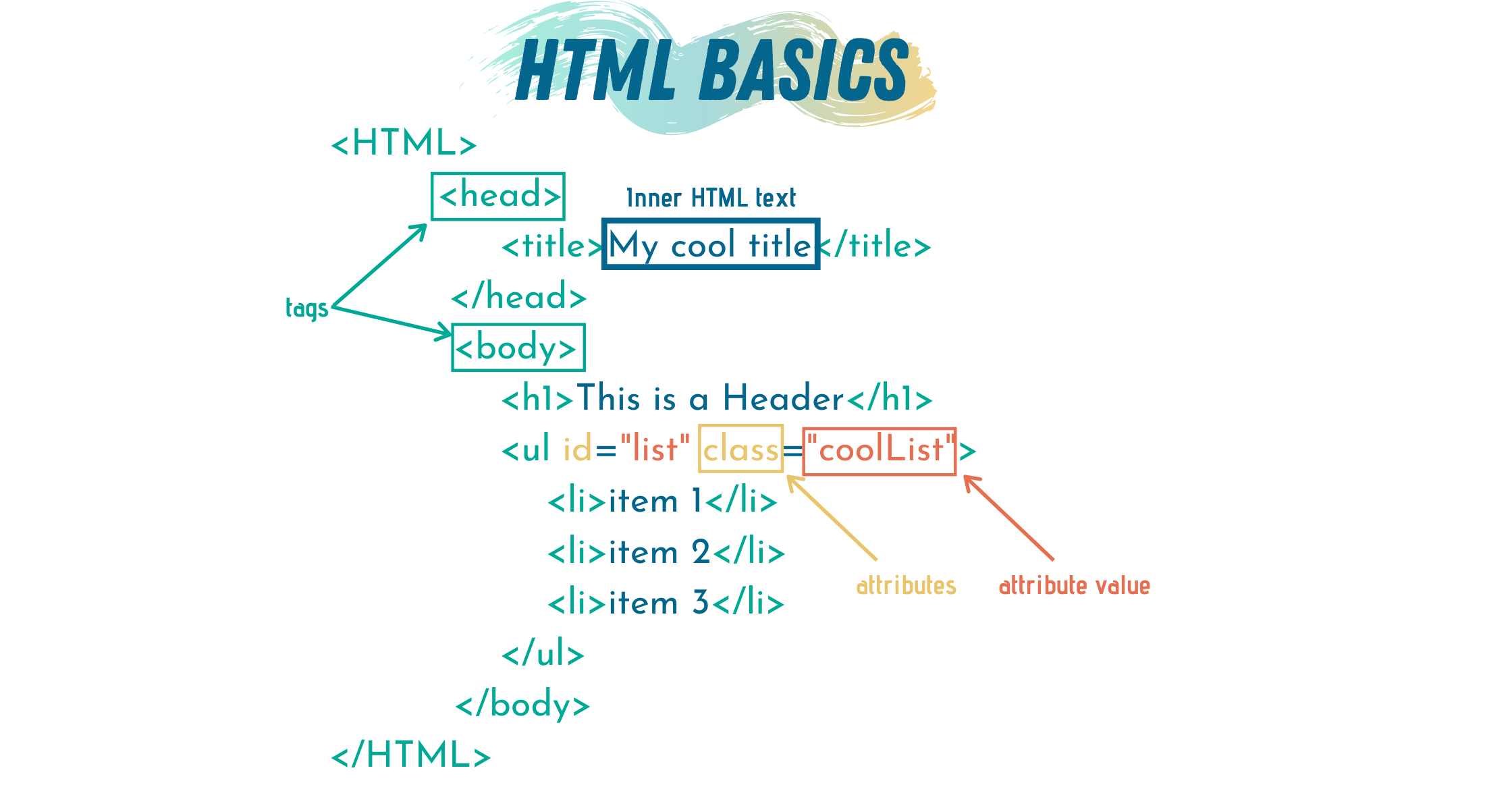
Different tags in HTML means different things. Using a combination of tags, a webpage is represented. Any text enclosed between an open and close tag is called inner HTML text.
HTML中的不同标记意味着不同的含义。 使用标签的组合来表示网页。 包含在打开和关闭标签之间的任何文本都称为内部HTML文本 。
If we have multiple elements with the same tag, we might — actually, always — want to differentiate between them somehow. There are two ways to do that, either through using classes or ids. Ids are unique, which means we can’t have two elements with the same id. Classes, on the other hand, are not. More than one element can have the same class.
如果我们有多个具有相同标签的元素,则我们可能-实际上一直-希望以某种方式区分它们。 有两种方法可以做到这一点,或者通过使用类或ID。 ID是唯一的,这意味着我们不能有两个具有相同ID的元素。 另一方面,类不是。 多个元素可以具有相同的类。
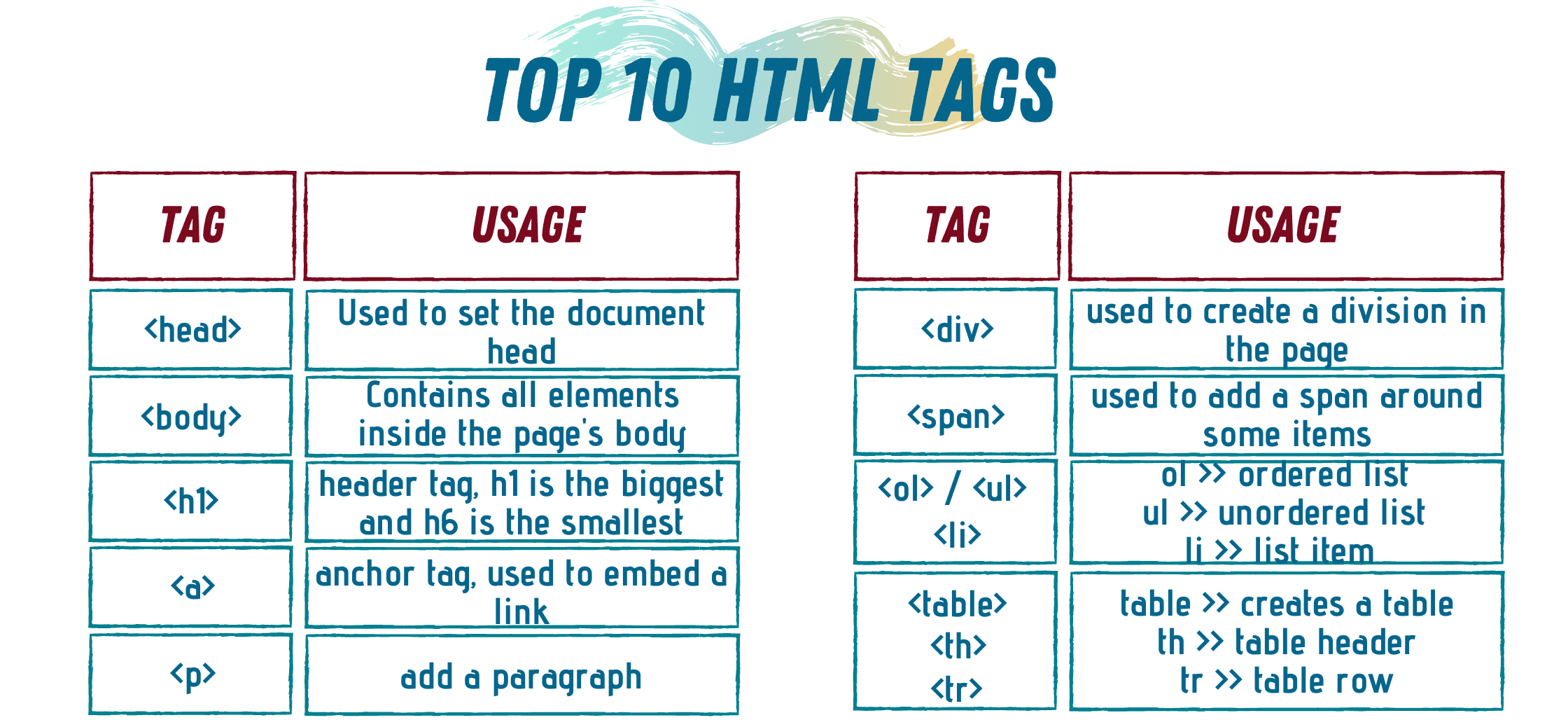
Here are 10 HTML tags you will see a lot when scraping the web.
这是10个HTML标记,在抓取网络时会看到很多。
基本刮 (Basic Scraping)
Awesome, now that we know the basics, let’s start up small and then build up!
太棒了,现在我们已经了解了基础知识,让我们从小处开始,然后逐步建立!
Our first step is to install BeautifulSoup by typing the following in the command line.
我们的第一步是通过在命令行中键入以下内容来安装BeautifulSoup。
pip install bs4To get familiar with scraping basics, we will consider an example HTML code and learn how to use BeautifulSoup to explore it.
为了熟悉抓取的基础知识,我们将考虑一个示例HTML代码,并学习如何使用BeautifulSoup进行探索。
<HTML>
<HEAD>
<TITLE>My cool title</TITLE>
</HEAD>
<BODY>
<H1>This is a Header</H1>
<ul id="list" class="coolList">
<li>item 1</li>
<li>item 2</li>
<li>item 3</li>
</ul>
</BODY>
</HTML>BeautifulSoup doesn’t fetch HTML from the web, it is, however, extremely good at extracting information from an HTML string.
BeautifulSoup不能从Web上获取HTML,但是,它非常擅长从HTML字符串中提取信息。
In order to use the above HTML in Python, we will set it up as a string and then use different BeautifulSoup to explore it.
为了在Python中使用上述HTML,我们将其设置为字符串,然后使用其他BeautifulSoup对其进行探索。
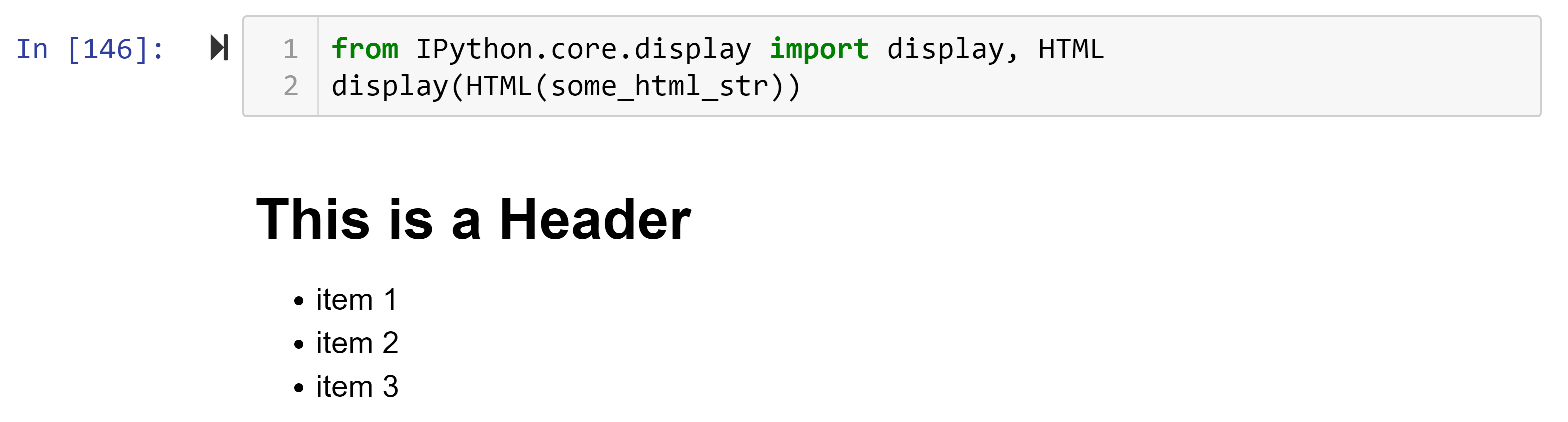
Note: if you’re using Jupyter Notebook to follow this article, you can type the following command to view HTML within the Notebook.
注意:如果您使用Jupyter Notebook跟随本文,则可以键入以下命令以在Notebook中查看HTML。
from IPython.core.display import display, HTML
display(HTML(some_html_str))For example, the above HTML will look something like this:
例如,上面HTML将如下所示:
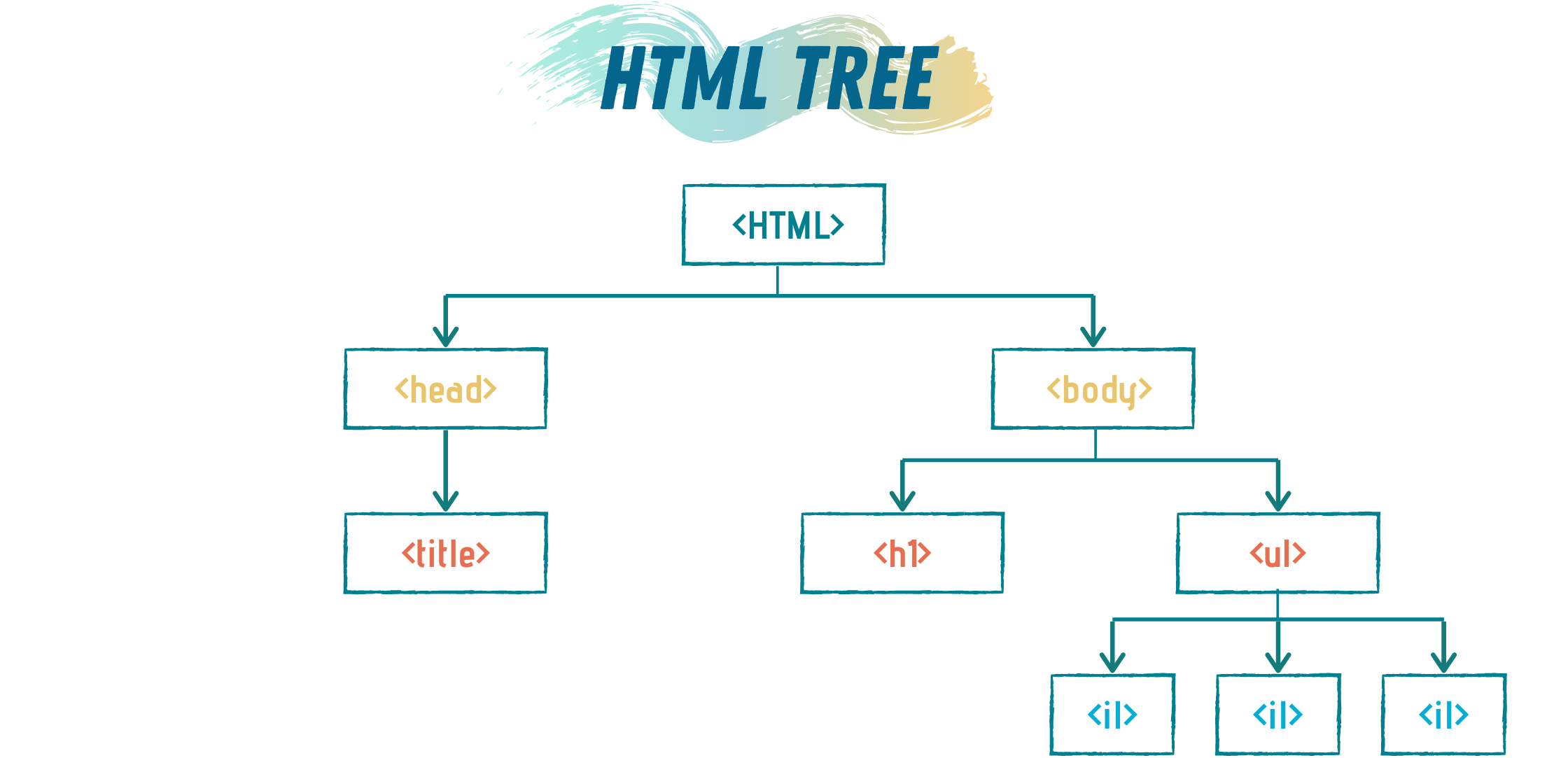
Next, we need to feed this HTML to BeautifulSoup in order to generate the HTML tree. HTML tree is a representation of the different levels of the HTML code, it shows the hierarchy of the code.
接下来,我们需要将此HTML馈送到BeautifulSoup,以便生成HTML树。 HTML树表示HTML代码的不同级别,它显示了代码的层次结构。
The HTML tree of the above code is:
上面代码HTML树为:
To generate the tree, we write
为了生成树,我们写
some_html_str = """
<HTML>
<HEAD>
<TITLE>My cool title</TITLE>
</HEAD><BODY>
<H1>This is a Header</H1>
<ul id="list" class="coolList">
<li>item 1</li>
<li>item 2</li>
<li>item 3</li>
</ul>
</BODY>
</HTML>
"""
#Feed the HTML to BeautifulSoup
soup = bs(some_html_str)The variable soup now has the information extracted from the HTML string. We can use this variable to obtain information from the HTML tree.
现在,变量soup具有从HTML字符串中提取的信息。 我们可以使用此变量从HTML树中获取信息。
BeautifulSoup has many functions that can be used to extract specific aspects of the HTML string. However, two functions are used to most: find and find_all.
BeautifulSoup具有许多功能,可用于提取HTML字符串的特定方面。 但是,大多数情况下使用两个函数: find和find_all.

The function find returns only the first occurrence of the search query, while find_all returns a list of all matches.
函数find仅返回搜索查询的第一个匹配项,而find_all返回所有匹配项的列表。
Say, we are searching for all <h1> headers in the code.
说,我们正在搜索代码中的所有<h1>标头。

As you can see, the find function gave me the <h1> tag. With the tags and all. Often, we only want to extract the inner HTML text. To do that we use .text .
如您所见, find函数给了我<h1>标记。 随着标签和所有。 通常,我们只想提取内部HTML文本。 为此,我们使用.text 。

That was simply because we only have one <h1> tag. But what if we want to look for list items — we have an unordered list with three items in our example — we can’t use find. If we do, we will only get the first item.
那仅仅是因为我们只有一个<h1>标签。 但是,如果我们要查找列表项-我们的示例中有一个包含三个项目的无序列表,该怎么办-我们不能使用find 。 如果这样做,我们只会得到第一项。

To find all the list items, we need to use find_all.
要查找所有列表项,我们需要使用find_all 。

Okay, now that we have a list of items, let’s answer two questions:
好的,现在我们有了项目列表,让我们回答两个问题:
1- How to get the inner HTML of the list items?
1-如何获取列表项的内部HTML?
To obtain the inner text only, we can’t use .text straight away, because now we have a list of elements and not just one. Hence, we need to iterate over the list and obtain the inner HTML of each list item.
只获取内部文本,我们不能立即使用.text,因为现在我们有了元素列表,而不仅仅是一个。 因此,我们需要遍历列表并获取每个列表项的内部HTML。

2- What if we have multiple lists in the code?
2-如果代码中有多个列表怎么办?
If we have more than one list in the code — which is usually the case — we can be precise when searching for elements. In our example, the list has id=’list’ and class=’coolList’. We can use this — both or just one — with the find_all or find functions to be precise and get the information we want.
如果我们在代码中有多个列表(通常是这种情况),则在搜索元素时可以很精确。 在我们的示例中,列表具有id ='list'和class ='coolList'。 我们可以将它(全部或仅一个)与find_all一起使用,或精确find功能并获取所需的信息。

One thing to note here is the return of the find or find_all functions are BeautifulSoup objects and those can be traversed further. So, we can treat them just like the object obtained directly from the HTML string.
这里要注意的一件事是, find或find_all函数的返回值都是BeautifulSoup对象,可以进一步遍历这些对象。 因此,我们可以将它们像直接从HTML字符串获得的对象一样对待。
Complete code for this section:
本节的完整代码:
#Import needed libraries
from bs4 import BeautifulSoup as bs
import requests as rq
#HTML string
some_html_str = """
<HTML>
<HEAD>
<TITLE>My cool title</TITLE>
</HEAD>
<BODY>
<H1>This is a Header</H1>
<ul id="list" class="coolList">
<li>item 1</li>
<li>item 2</li>
<li>item 3</li>
</ul>
</BODY>
</HTML>
"""
soup = bs(some_html_str)
#Get headers
print(soup.find('h1'))
print(soup.find('h1').text)
#Get all list items
inner_text = [item.text for item in soup.find_all('li')]
print(inner_text)
ourList = soup.find(attrs={"class":"coolList", "id":"list"})
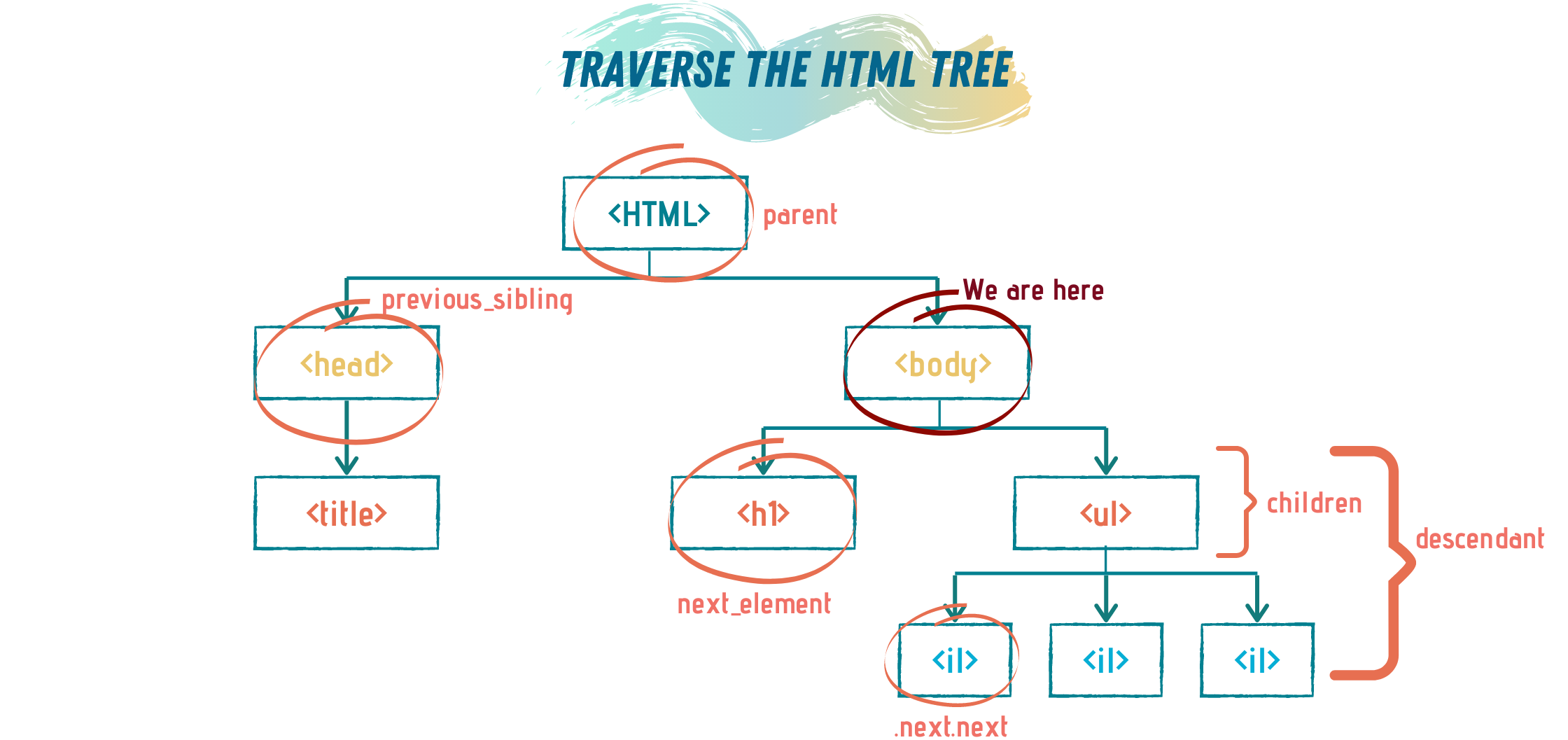
print(ourList.find_all('li'))We can traverse the HTML tree using other BeautifulSoup functions, like children, parent, next, etc.
我们可以使用其他BeautifulSoup功能,如遍历HTML树children , parent , next ,等
抓取一个网页 (Scraping one webpage)
Let’s consider a more realistic example, where we fetch the HTML from a URL and then use BeautifulSoup to extract patterns and data.
让我们考虑一个更现实的示例,其中我们从URL提取HTML,然后使用BeautifulSoup提取模式和数据。
We will start by fetching one webpage. I love coffee, so let’s try fetching the Wikipedia page listing countries by coffee production and then plot the countries using Pygal.
我们将从获取一个网页开始。 我喜欢咖啡,所以让我们尝试获取按咖啡产量列出国家的Wikipedia页面,然后使用Pygal绘制国家。
To fetch the HTML we will use the Requests library and then pass the fetched HTML to BeautifulSoup.
要获取HTML,我们将使用Requests库,然后将获取HTML传递给BeautifulSoup。

If we opened this wiki page, we will find a big table with the countries, and different measures of coffee production. We just want to extract the country name and the coffee production in tons.
如果打开此Wiki页面,我们将找到一张列出了各个国家/地区以及不同的咖啡生产量度的大表。 我们只想提取国家名称和吨咖啡产量。
To extract this information, we need to study the HTML of the page to know what to query. We can just highlight a country name, right-click, and choose inspect.
要提取此信息,我们需要研究页面HTML以了解要查询的内容。 我们可以仅突出显示一个国家名称, 单击鼠标右键 ,然后选择inspect 。
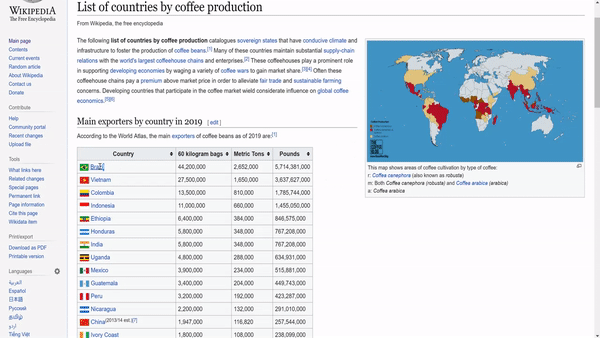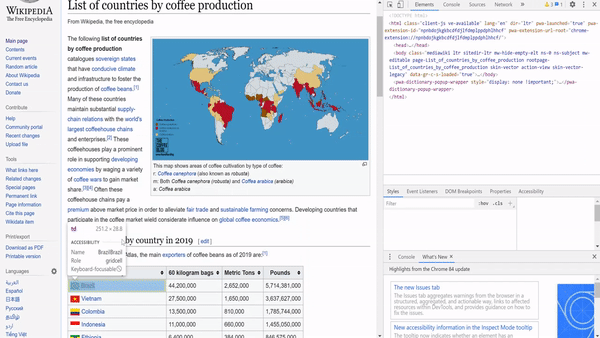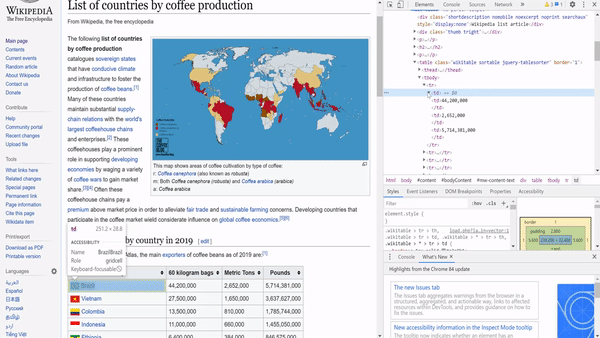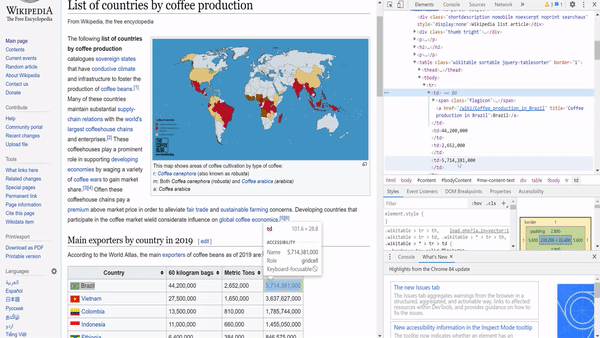
Through inspecting the page, we can see that the country names and the quantity are enclosed within a ‘table’ tag. Since it is the first table on the page, we can just use the find function to extract it.
通过检查页面,我们可以看到国家名称和数量包含在“表格”标签中。 由于它是页面上的第一张表,因此我们可以使用find函数来提取它。
However, extracting the table directly will give us all the table’s content, with the table header — the first row of the table — and the quantity in different measures.
但是,直接提取表格将为我们提供表格的所有内容,包括表格标题(表格的第一行)和数量(采用不同度量)。
So, we need to fine-tune our search. Let’s try it out with the top 10 countries.
因此,我们需要微调搜索。 让我们与前10个国家/地区一起尝试一下。

Notice that to clean up the results, I used string manipulation to extract the information I want.
注意,为了清理结果,我使用了字符串操作来提取所需的信息。
I can use this list to finally plot the top 10 countries using Pygal.
我可以使用此列表最终使用Pygal列出前10个国家/地区。


Complete code for this section:
本节的完整代码:
#Import needed libraries
from bs4 import BeautifulSoup as bs
import requests as rq
import pygal
from IPython.display import display, HTML
#Fetch HTML
url = 'https://en.wikipedia.org/wiki/List_of_countries_by_coffee_production'
#Extract HTMl tree
page = rq.get(url).text
soup = bs(page)
#Find countries and quantiy
table = soup.find('table')
top_10_countries = []
for row in table.find_all('tr')[2:11]:
temp = row.text.replace('\n\n',' ').strip() #obtain only the quantiy in tons
temp_list = temp.split()
top_10_countries.append((temp_list[0],temp_list[2]))
#Plot the top 10 countries
bar_chart = pygal.Bar(height=400)
[bar_chart.add(item[0],int(item[1].replace(',',''))) for item in top_10_countries]
display(HTML(base_html.format(rendered_chart=bar_chart.render(is_unicode=True))))抓取多个网页 (Scraping multiple webpages)
Wow, that was a lot! 😃
哇,好多啊! 😃
But, we yet to write code that scraps different webpages.
但是,我们尚未编写可删除不同网页的代码。
For this section, we will scrap the wiki page with the best 100 books of all time, and then we will categorize these books based on their genre. Trying to see if we can find a relation between the genre and the list — which genre performed best.
在本节中,我们将在Wiki页面上废弃有史以来最好的100本书 ,然后根据这些书籍的类型对其进行分类。 尝试查看我们是否可以找到流派和列表之间的关系-哪种流派表现最好。
The wiki page contains links to each of the 100 books as well as their authors. We want our code to navigate the list, go to the book wiki page, extract info like genre, name, author, and publishing year and then store this info in a Python dictionary — you can store the data in a Pandas frame as well.
Wiki页面包含指向这100本书及其作者的链接。 我们希望我们的代码在列表中导航,转到书籍Wiki页面,提取类型,名称,作者和出版年份等信息,然后将此信息存储在Python字典中-您也可以将数据存储在Pandas框架中。
So, to do this we need a couple of steps:
因此,要做到这一点,我们需要几个步骤:
- Fetch the main URL HTML code. 获取主URL HTML代码。
- Feed that HTML to BeautifulSoup. 将HTML馈送给BeautifulSoup。
- Extract each book from the list and get the wiki link of each book. 从列表中提取每本书,并获得每本书的Wiki链接。
- Obtain data for each book. 获取每本书的数据。
- Get all books data, clean, and plot final results. 获取所有书籍数据,清理并绘制最终结果。
Let’s get started…
让我们开始吧…
Step #1: Fetch main URL HTML code
步骤1:获取主网址HTML代码
url = 'https://en.wikipedia.org/wiki/Time%27s_List_of_the_100_Best_Novels'
page = rq.get(url).textStep #2: Feed that HTML to BeautifulSoup
步骤2:将HTML馈送到BeautifulSoup
soup = bs(page)Step #3: Extract each book from the list and get the wiki link of each book
步骤#3:从清单中提取每本书,并获取每本书的Wiki链接
rows = soup.find('table').find_all('tr')[1:]
books_links = [row.find('a')['href'] for row in rows]
base_url = 'https://en.wikipedia.org'
books_urls = [base_url + link for link in books_links]Step #4: Obtain data for each book
步骤4:获取每本书的数据
This is the most lengthy and important step. We will first consider only one book, assume it’s the first one in the list. If we open the wiki page of the book we will see the different information of the book enclosed in a table on the right side of the screen.
这是最漫长和重要的一步。 我们首先只考虑一本书,假设它是列表中的第一本书。 如果打开该书的Wiki页面,我们将在屏幕右侧的表格中看到该书的不同信息。

Going through the HTML we can see where everything is stored.
通过HTML,我们可以看到所有内容的存储位置。
To make things easier and more efficient, I wrote custom functions to extract different information from the book’s wiki.
为了使事情变得更容易和更有效,我编写了自定义函数以从本书的Wiki中提取不同的信息。
def find_book_name(table):
if table.find('caption'):
name = table.find('caption')
return name.text
def get_author(table):
author_name = table.find(text='Author').next.text
return author_name
def get_genre(table):
if table.find(text='Genre'):
genre = table.find(text='Genre').next.text
else:
genre = table.find(text='Subject').next.next.next.text
return genre
def get_publishing_date(table):
if table.find(text='Publication date'):
date = table.find(text='Publication date').next.text
else:
date = table.find(text='Published').next.text
pattern = re.compile(r'\d{4}')
year = re.findall(pattern, date)[0]
return int(year)
def get_pages_count(table):
pages = table.find(text='Pages').next.text
return int(pages)Now, that we have these cool functions, let’s write a function to use these functions, this will help us with the automation.
现在,我们有了这些很酷的功能,让我们编写一个使用这些功能的功能,这将帮助我们实现自动化。
def get_book_info_robust(book_url):
#To avoid breaking the code
try:
book_soup = parse_wiki_page(book_url)
book_table = book_soup.find('table',class_="infobox vcard")
except:
print(f"Cannot parse table: {book_url}")
return None
book_info = {}
#get info with custom functions
values = ['Author', 'Book Name', 'Genre',
'Publication Year', 'Page Count']
functions = [get_author, find_book_name, get_genre,
get_publishing_date, get_pages_count]
for val, func in zip(values, functions):
try:
book_info[val] = func(book_table)
except:
book_info[val] = None
return book_infoIn this function, I used the try..except formate to avoid crashing if some of the book's info is missing.
在此功能中,我使用了try..except formate来避免在书中某些信息丢失时崩溃。
Step #5: Get all books data, clean, and plot final results
步骤#5:获取所有书籍数据,清理并绘制最终结果
We have all we need to automate the code and run it.
我们拥有自动化代码并运行它所需的全部。
One last thing to note: It is legal to scrap Wikipedia, however, they don’t like it when you scrap more than one page each second. So we will need to add pauses between each fetch to avoid breaking the server.
最后要注意的一件事:废弃Wikipedia是合法的,但是,当您每秒废弃多个页面时,他们不喜欢它。 因此,我们将需要在每次抓取之间添加暂停,以免破坏服务器。
#to add puases
import time
#to store books info
book_info_list = []
#loop first books
for link in books_urls:
#get book info
book_info = get_book_info_robust(link)
#if everything is correct and no error occurs
if book_info:
book_info_list.append(book_info)
#puase a second between each book
time.sleep(1)Data collected! this will take 100 seconds to finish, so feel free to do something else while you wait 😉
收集数据! 这将需要100秒才能完成,因此在您等待时随意做些其他事情😉
Finally, let’s clean the data, get the genre count, and plot the results.
最后,让我们清理数据,获取类型数,然后绘制结果。
#Collect different genres
genres = {}
for book in book_info_list:
book_gen = book['Genre']
if book_gen:
if 'fiction' in book_gen or 'Fiction' in book_gen:
book_gen = 'fiction'
if book_gen not in genres: #count books in each genre
genres[book_gen] = 1
else:
genres[book_gen] += 1
print(genres)
#Plot results
bar_chart = pygal.Bar(height=400)
[bar_chart.add(k,v) for k,v in genres.items()]
display(HTML(base_html.format(rendered_chart=bar_chart.render(is_unicode=True))))And we are done!
我们完成了!
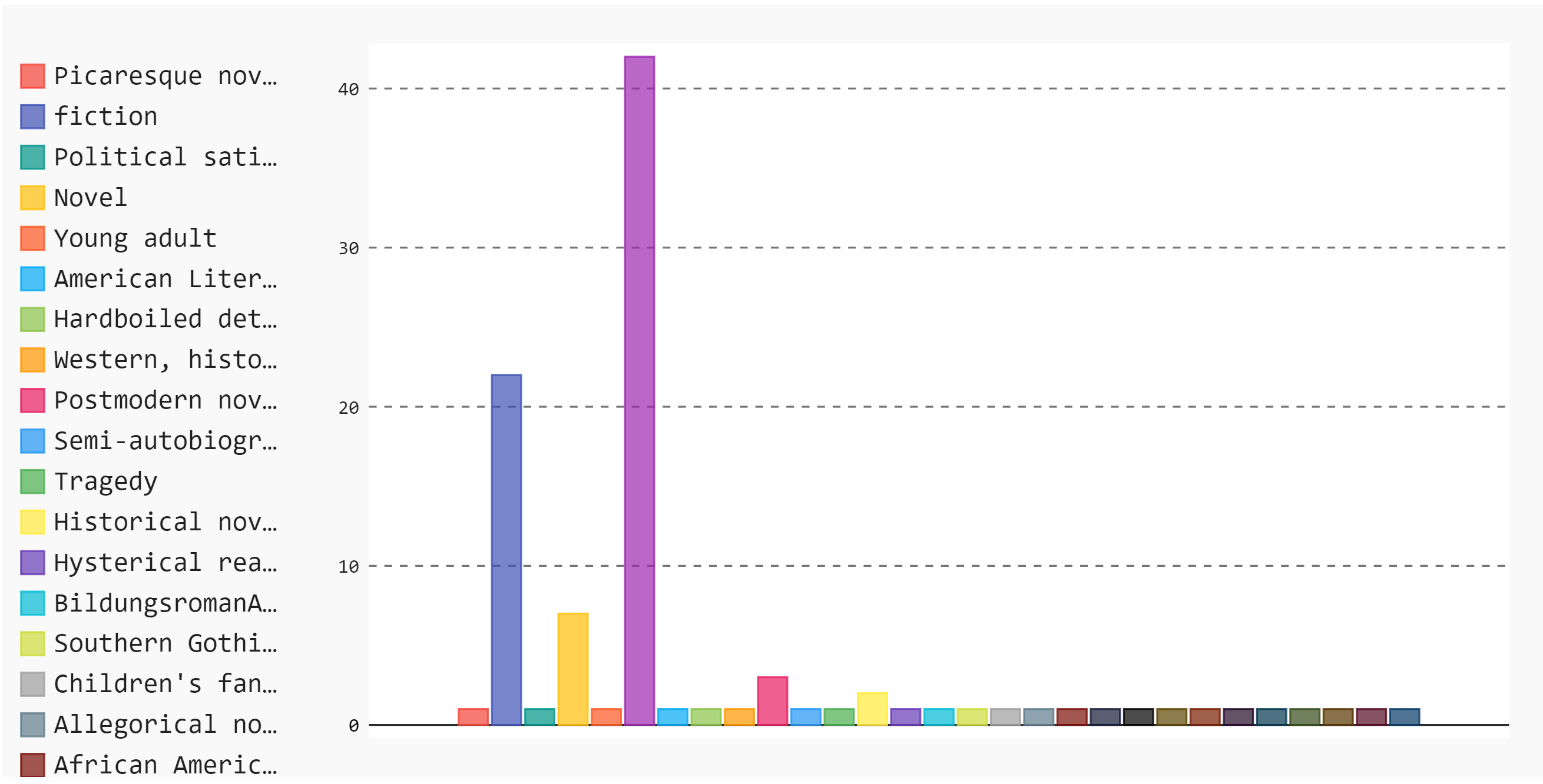
I have to say, collecting data is not always a 100% accurate, as you can see in the plot, the longest bar belongs to the ‘None’ value. Which means one of two things
我不得不说,收集数据并不总是100%准确,正如您在图中所看到的,最长的柱属于“无”值。 这意味着两件事之一
- Either the wiki page didn’t include the book’s genre. 维基页面均未包含该书的体裁。
- Or, the code for that specific book is different than the rest. 或者,该特定书的代码与其他书不同。
That’s why after automating the data collection, we often go through the weird and unusual results and recheck them manually.
这就是为什么在自动执行数据收集后,我们通常会经历怪异和异常的结果并手动重新检查它们。
结论 (Conclusion)
Web scraping is one of the essential skills a data scientist needs. And it can’t be any easier than with using Python, Requests, and BeautifulSoup.
Web抓取是数据科学家需要的基本技能之一。 而且,使用Python,Requests和BeautifulSoup绝非易事。
We can never trust full automation, sometimes we will need to go through the final result a recheck for abnormal information manually.
我们永远不能相信完全自动化,有时我们需要手动检查最终结果,以重新检查异常信息。
The full code for the books section:
书籍部分的完整代码:
#Import needed libraries
from bs4 import BeautifulSoup as bs
import requests as rq
import pygal
import time
#define functions for data collection
def find_book_name(table):
if table.find('caption'):
name = table.find('caption')
return name.text
def get_author(table):
author_name = table.find(text='Author').next.text
return author_name
def get_genre(table):
if table.find(text='Genre'):
genre = table.find(text='Genre').next.text
else:
genre = table.find(text='Subject').next.next.next.text
return genre
def get_publishing_date(table):
if table.find(text='Publication date'):
date = table.find(text='Publication date').next.text
else:
date = table.find(text='Published').next.text
pattern = re.compile(r'\d{4}')
year = re.findall(pattern, date)[0]
return int(year)
def get_pages_count(table):
pages = table.find(text='Pages').next.text
return int(pages)
def get_book_info_robust(book_url):
#To avoid breaking the code
try:
book_soup = parse_wiki_page(book_url)
book_table = book_soup.find('table',class_="infobox vcard")
except:
print(f"Cannot parse table: {book_url}")
return None
book_info = {}
#get info with custom functions
values = ['Author', 'Book Name', 'Genre',
'Publication Year', 'Page Count']
functions = [get_author, find_book_name, get_genre,
get_publishing_date, get_pages_count]
for val, func in zip(values, functions):
try:
book_info[val] = func(book_table)
except:
book_info[val] = None
return book_info
#to store books info
book_info_list = []
#loop first books
for link in books_urls:
#get book info
book_info = get_book_info_robust(link)
#if everything is correct and no error occurs
if book_info:
book_info_list.append(book_info)
#puase a second between each book
time.sleep(1)
#Collect different genres
genres = {}
for book in book_info_list:
book_gen = book['Genre']
if book_gen:
if 'fiction' in book_gen or 'Fiction' in book_gen:
book_gen = 'fiction'
if book_gen not in genres: #count books in each genre
genres[book_gen] = 1
else:
genres[book_gen] += 1
print(genres)
#Plot results
bar_chart = pygal.Bar(height=400)
[bar_chart.add(k,v) for k,v in genres.items()]
display(HTML(base_html.format(rendered_chart=bar_chart.render(is_unicode=True))))翻译自: https://towardsdatascience.com/a-step-by-step-guide-to-web-scraping-in-python-5c4d9cef76e8
python 实现分步累加















 3129
3129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









