





python 数据框缺失值
介绍 (Introduction)
In the last article we went through on how to find the missing values. This link has the details on the how to find missing values in the data frame. https://medium.com/@kallepalliravi/python-finding-missing-values-in-a-data-frame-3030aaf0e4fd
在上一篇文章中,我们探讨了如何找到缺失的值。 该链接包含有关如何在数据框中查找缺失值的详细信息。 https://medium.com/@kallepalliravi/python-finding-missing-values-in-a-data-frame-3030aaf0e4fd
Now that you have identified all the missing values, what to do with these missing values? In this article we will go over on how to handle missing data in a data frame.
现在,您已经确定了所有缺失值,如何处理这些缺失值? 在本文中,我们将探讨如何处理数据帧中的丢失数据。
There are multiple ways of handling missing data and this varies case by case. There is no universal best way in dealing with the missing data. Use your best judgement and explore different options to determine which method is best for your data set.
有多种处理丢失数据的方法,具体情况视情况而定。 没有通用的最佳方法来处理丢失的数据。 根据您的最佳判断,探索不同的选项,以确定哪种方法最适合您的数据集。
Deleting all rows/columns with missing data: This can be used when you have rows/columns where majority of the data is missing. When you are deleting rows/columns you might be losing some valuable information and lead to biased models. So analyze your data before deleting and check if there is any particular reason for missing data.
删除所有缺少数据的行/列 :当您缺少大部分数据的行/列时,可以使用此方法。 当您删除行/列时,您可能会丢失一些有价值的信息,并导致模型有偏差。 因此,请在删除数据之前分析您的数据,并检查是否有任何特殊原因导致数据丢失。
Imputing data: This is by far the most common way used to handle missing data. In this method you impute a value where data is missing. Imputing data can introduce bias into the datasets. Imputation can be done multiple ways.
估算数据 :这是迄今为止处理缺失数据的最常用方法。 在此方法中,您将在缺少数据的地方估算一个值。 估算数据可能会使数据集产生偏差。 插补可以通过多种方式完成。
a. You can impute mean, median or mode values of a column into the missing values in a column.
一个。 您可以将一列的均值,中位数或众数值插入一列的缺失值中。
b. You use predictive algorithms to impute missing values.
b。 您可以使用预测算法来估算缺失值。
c. For categorical variables you can label missing data as a category.
C。 对于分类变量,可以将缺少的数据标记为类别。
For this exercise we will use the Seattle Airbnb data set which can be found in the below link. https://www.kaggle.com/airbnb/seattle?select=listings.csv
在本练习中,我们将使用Seattle Airbnb数据集,该数据集可在下面的链接中找到。 https://www.kaggle.com/airbnb/seattle?select=listings.csv
Load the data and find the missing values.
加载数据并找到缺少的值。
The details of this steps can be found in the previous post under the below link. https://medium.com/@kallepalliravi/python-finding-missing-values-in-a-data-frame-3030aaf0e4fd
有关此步骤的详细信息,请参见上一篇文章的以下链接。 https://medium.com/@kallepalliravi/python-finding-missing-values-in-a-data-frame-3030aaf0e4fd
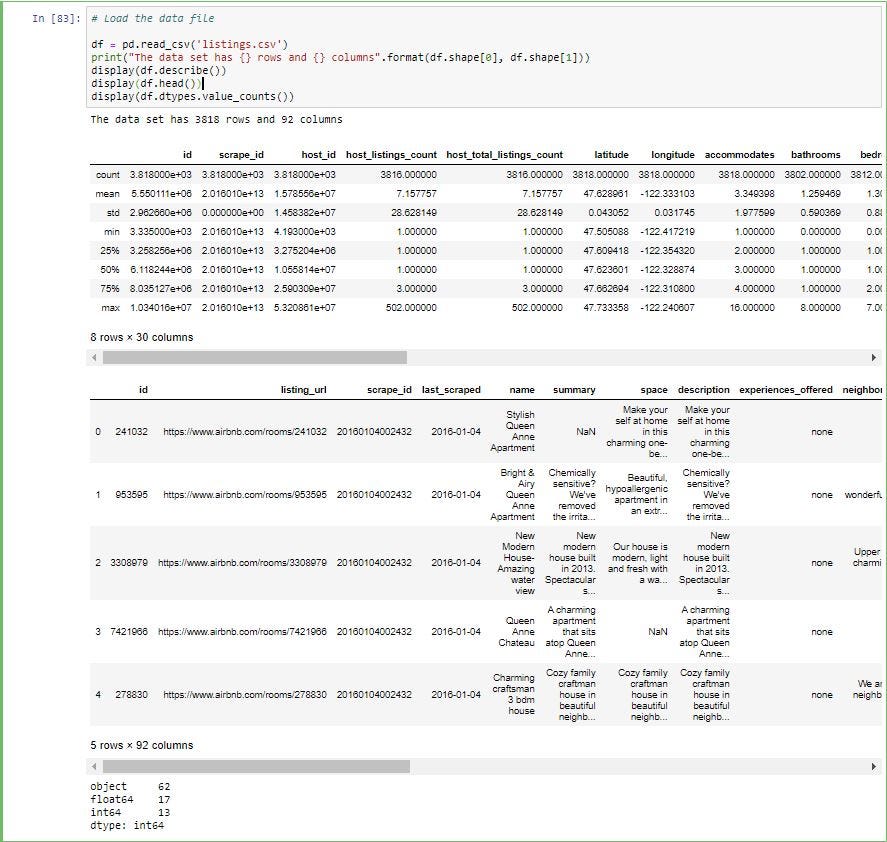
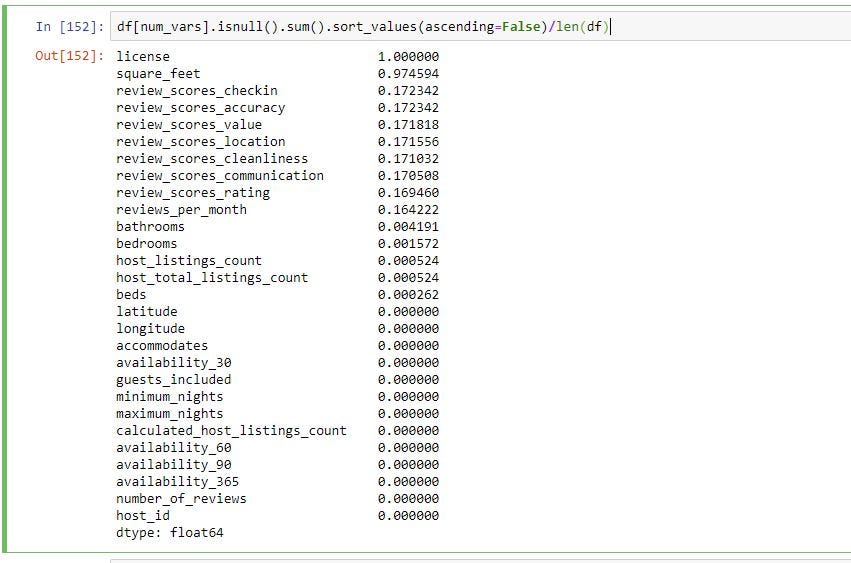
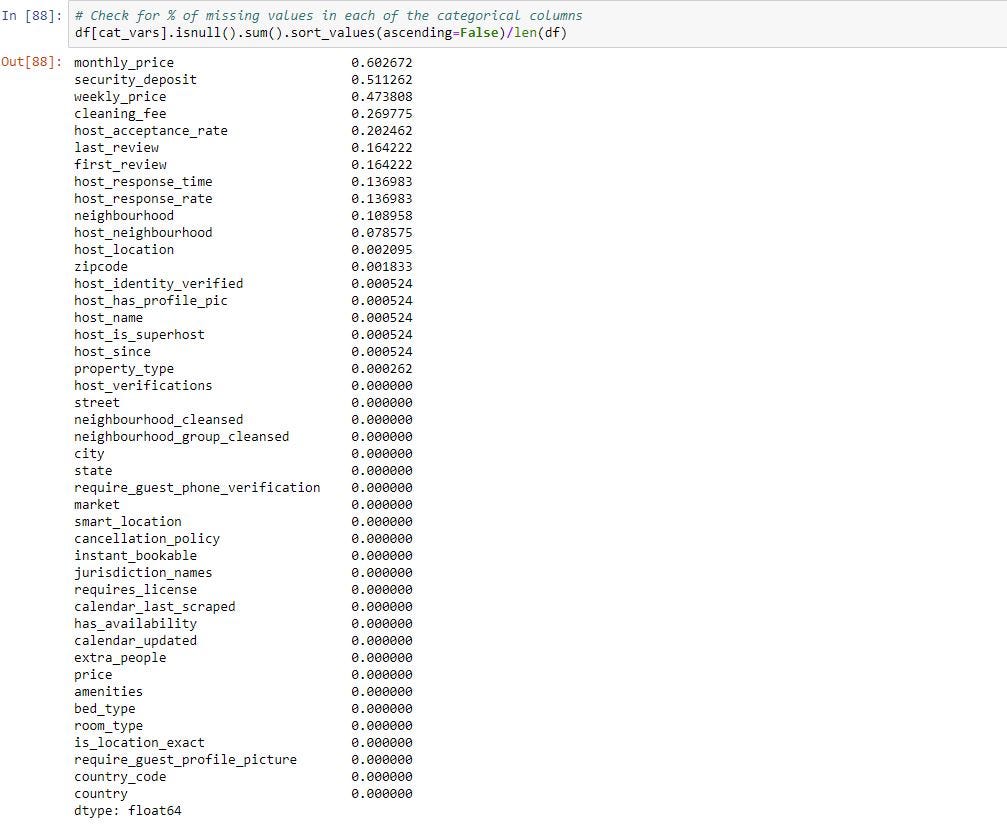
1.删除缺少数据的行/列: (1. Deleting rows/columns with missing data:)
Deleting Specific rows/columns
删除特定的行/列
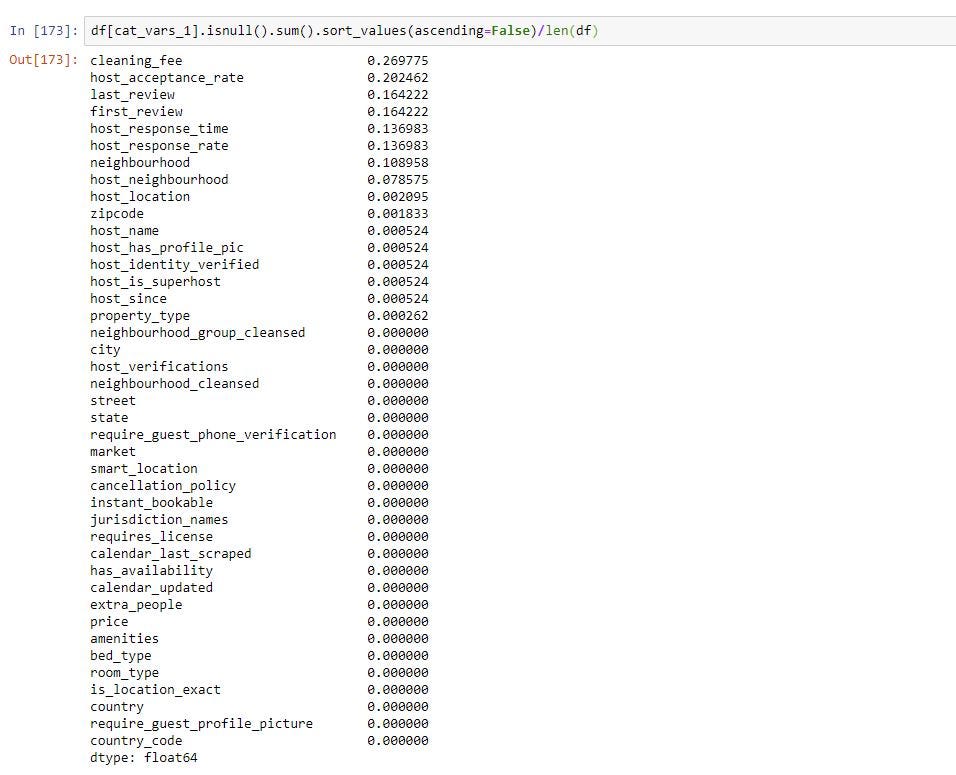
From the above you can see that 100% of the values in license column and 97% of the square_feet column are missing data in numerical columns.
从上面可以看到,许可证列中的100%的值和square_feet列中的97%的值在数字列中丢失。
60% of the values in monthly_price, 51% of values in security_deposit and 47% of values in weekly_price are missing data
缺少数据的month_price中的值的60%,security_deposit中的51%的值和weekly_price中的47%的值
Lets try deleting these 5 columns.
让我们尝试删除这5列。
Pandas drop function can be used to delete rows and columns. Full details of this function can be found in the below https://pandas.pydata.org/pandasdocs/stable/reference/api/pandas.DataFrame.drop.html
熊猫拖放功能可用于删除行和列。 可以在下面的https://pandas.pydata.org/pandasdocs/stable/reference/api/pandas.DataFrame.drop.html中找到此功能的完整详细信息。
All columns which should be deleted should be included in columns parameter. axis =1 represents column, axis=0 represent rows. In the case we are telling to delete all columns specified in the columns parameter.
应该删除的所有列都应包含在columns参数中。 轴= 1代表列,轴= 0代表行。 在这种情况下,我们告诉您删除columns参数中指定的所有列。

As you can see below now you do not have columns which have been deleted.
如下所示,您现在没有已删除的列。
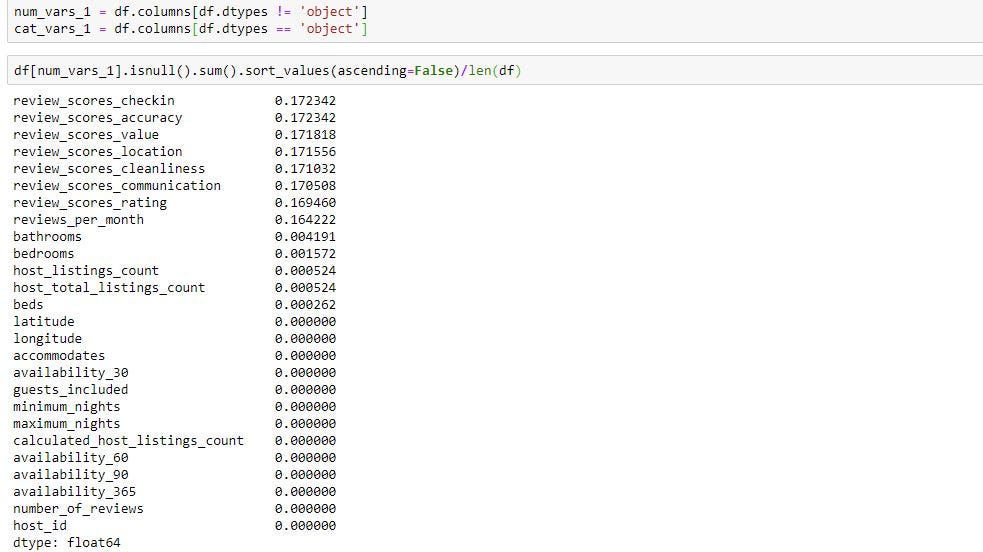
Deleting rows/columns with NA
用NA删除行/列
If you want to delete rows/columns with NA we can use dropna function in pandas. Details of this function can be found in the below link. https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dropna.html
如果您想使用NA删除行/列,我们可以在熊猫中使用dropna函数。 可以在下面的链接中找到此功能的详细信息。 https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dropna.html
dropna function has multiple parameters, the 3 main ones are
dropna函数有多个参数,其中三个主要参数是
- how : this has 2 options “any” or “all”. If you set to “any” even if one value has NA in row or column it will delete those columns. If you set to “all” only if all the values in rows/columns have NA deletion will happen. 方式:这有2个选项“任何”或“全部”。 如果您设置为“ any”,即使一个值在行或列中具有NA,它将删除这些列。 如果仅将行/列中的所有值都具有NA删除,则设置为“所有”。
- axis : this can be set to 0 or 1. If 0 then drops rows with NA values, if 1 then drops columns with NA values. axis:可以将其设置为0或1。如果为0,则删除具有NA值的行,如果为1,则删除具有NA值的列。
- subset: if you want the operation to be performed only on certain columns then mention the column name int he subset. If subset is not define then the operation is performed on all the columns. 子集:如果您希望仅对某些列执行操作,请在子集中提及列名。 如果未定义子集,则对所有列执行该操作。

2.估算数据 (2. Imputing Data)
With imputing you are trying to assign a value through inference from the values to which it contributes. In this case you are assigning a value in the place of a missing value by using different methods on the feature which has missing value. Methods can as simple as assigning mean, median, mode of the column to the missing values or you can use machine learning techniques to predict the missing values. Imputation methods can be different for numerical and categorical variables.
使用插补时,您试图通过推断贡献值来分配一个值。 在这种情况下,您可以通过对具有缺失值的要素使用不同的方法来为缺失值分配一个值。 方法可以简单到为缺失值分配列的均值,中位数,众数模式,也可以使用机器学习技术来预测缺失值。 数值和分类变量的插补方法可能不同。
Imputation for Numerical values:
数值的估算:
With numerical columns the most common approach to impute data is by imputing mean, median or mode of the column in place of the missing values.
对于数字列,最常用的估算数据方法是通过估算列的均值,中位数或众数来代替缺失值。
To do that we will write a function to fill na with mean/median/mode and then apply that function to all the columns.
为此,我们将编写一个用均值/中位数/众数填充na的函数,然后将该函数应用于所有列。
In the below i am showing a example to fill the missing data with the mean of the column.
在下面的示例中,我展示了使用列的平均值填充缺失数据的示例。
fill_mean function iterates through each column in the data frame and fill’s na with the column mean.
fill_mean函数遍历数据帧中的每一列,并用列均值填充na。
You can then use apply() function to apply fill_mean function on one column or multiple columns in a data frame.
然后,您可以使用apply()函数将fill_mean函数应用于数据框中的一列或多列。
This example shows using mean, you can use median() and mode() function in place of mean() if you want to impute median or mode of the column .
此示例显示了使用均值,如果要对列的中值或众数进行插值,则可以使用mean()和mode()函数代替mean()。

Imputation for Categorical values:
分类值的插补:
For categorical variables clearly you cannot use mean or median for imputation. But we can use mode which is use the most frequently used value or the one other way is to missing data as category by itself.
显然,对于分类变量,您不能使用均值或中位数进行插补。 但是我们可以使用使用最常用值的模式,或者另一种方法是单独丢失数据作为类别。
Since i have already went through on how to impute most frequently value, in this step i will show how make a missing data as a category. This is very straight forward, you just replace NA with “missing data” category. Missing data will be one of the levels in each categorical variable.
由于我已经介绍了如何估算最频繁的值,因此在这一步中,我将说明如何将缺失的数据作为类别。 这很简单,您只需将NA替换为“缺少数据”类别。 丢失的数据将是每个分类变量中的级别之一。

Imputation using a model to predict missing values:
使用模型进行插补以预测缺失值:
One more option is to use model to predict missing values. To perform this task you can IterativeImputer from sklearn library. You can find details on this in the below link
另一种选择是使用模型来预测缺失值。 要执行此任务,您可以从sklearn库中获取IterativeImputer。 您可以在以下链接中找到详细信息
https://scikit-learn.org/stable/modules/generated/sklearn.impute.IterativeImputer.html
https://scikit-learn.org/stable/modules/generation/sklearn.impute.IterativeImputer.html
Iterative imputer considers features with missing values and develops a model as function of other features. It then estimates the missing value and imputes those values.
迭代冲刺者会考虑具有缺失值的要素,并根据其他要素开发模型。 然后,它估计缺失值并估算这些值。
It does it in a iterative manner, meaning it will take a 1st feature with missing values which it considers as response variable and considers all the other features as input variables. Using these input variables it will estimate the values for the missing values in the response variable. In the next step it will consider the 2nd feature with missing values as response variable and use all the other features as input variables and estimate missing values. This process will continue until all the features with missing values are addressed.
它以迭代方式进行,这意味着它将采用第一个具有缺失值的特征,将其视为响应变量,并将所有其他特征视为输入变量。 使用这些输入变量,它将估计响应变量中缺少的值的值。 在下一步中,它将把具有缺失值的第二个特征视为响应变量,并将所有其他特征用作输入变量并估计缺失值。 此过程将继续进行,直到解决所有缺少值的功能。
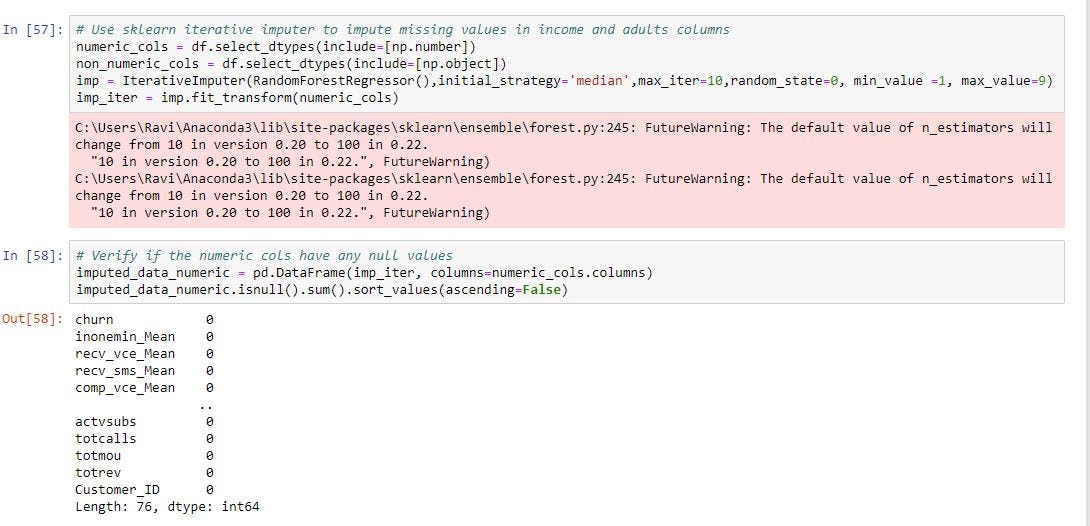
In the below example i am using Random forest in the imputer to estimate the missing values and fitting the imputer to a data frame.
在下面的示例中,我将在嵌入式计算机中使用随机森林来估计缺失值,并将嵌入式计算机拟合到数据帧。
结论: (Conclusion:)
In this article we went through on how to handle the missing values in a data frame.
在本文中,我们探讨了如何处理数据框中的缺失值。
- Delete the rows/columns with missing values 删除缺少值的行/列
- Imputing the missing values with statistic like mean, mean or mode. 用均值,均值或众数等统计数据来估算缺失值。
- For categorical variables making missing data as a category. 对于类别变量,将缺少的数据作为类别。
- Using Iterative Imputer develop a model to predict missing values in each of the features. 使用Iterative Imputer开发一个模型来预测每个功能部件中的缺失值。
翻译自: https://medium.com/analytics-vidhya/python-handling-missing-values-in-a-data-frame-4156dac4399
python 数据框缺失值














 5625
5625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









