





如何建立搜索引擎
This article outlines one of the most important search algorithms used today and demonstrates how to implement it in Python in just a few lines of code.
本文概述了当今使用的最重要的搜索算法之一,并演示了如何仅用几行代码就可以在Python中实现它。
搜索的价值 (The value of search)
The ability to search data is something we take for granted. Modern search engines are now so sophisticated that most of our searches ‘just work’. In fact, we often only notice a search on a website or app when it does not perform. Our expectations in this space have never been higher.
搜索数据的能力是我们理所当然的。 现在,现代搜索引擎非常复杂,以至于我们的大多数搜索“都行得通”。 实际上,我们通常只会在网站或应用无法执行搜索时才会注意到该搜索。 我们对这个领域的期望从未如此高。
The intelligence of search engines has been increasing for a very simple reason, the value that an effective search tool can bring to a business is enormous; a key piece of intellectual property. Often a search bar is the main interface between customers and the business. A good search engine can, therefore, create a competitive advantage by delivering an improved user experience.
搜索引擎的智能一直在增加,原因很简单,有效的搜索工具可以为企业带来巨大的价值。 关键的知识产权。 搜索栏通常是客户和企业之间的主要界面。 因此,好的搜索引擎可以通过提供改进的用户体验来创造竞争优势。
MckKinsey estimated that this value, aggregated globally, amounted to $780Bn a year in 2009. This would put the value of each search performed at $0.50[1]. Of course, this value has no doubt increased substantially since 2009…
麦肯锡(MckKinsey)估计,2009年,全球每年的价值总计为7800亿美元。这使得每次搜索的价值为0.50美元[1]。 当然,自2009年以来,这一价值无疑已大幅提高。
With this in mind, you would be forgiven that creating a modern search engine would be out of reach of most development teams, requiring huge resources and complex algorithms. However, somewhat surprisingly, a large number of enterprise business search engines are actually powered by very simple and intuitive rules which can be easily implemented using open source software.
考虑到这一点,您会原谅创建现代搜索引擎对于大多数开发团队来说是遥不可及的,这需要大量的资源和复杂的算法。 但是,令人惊讶的是,实际上,许多企业业务搜索引擎由非常简单直观的规则提供支持,可以使用开源软件轻松实现这些规则。
For example, Uber, Udemy Slack and Shopify (along with 3,000 other business and organisations [2]) all use Elasticsearch. This search engine was powered by incredibly simple term-frequency, inverse document frequency (or tf-idf) word scores up until 2016.[3] (For more details on what this is, I have written about tf-idf here and here).
例如,Uber,Udemy Slack和Shopify(以及3,000个其他企业和组织[2])都使用Elasticsearch。 该搜索引擎由令人难以置信的简单词频,反文档频度 (或tf-idf)单词得分提供支持,直到2016年。[3] (有关这是什么的更多详细信息,我在这里和这里已经写过关于tf-idf的信息 )。
After this point, it switched to the more sophisticated (but still very simple) BM25 which is still used today. This is also the algorithm implemented within Azure Cognitive Search[4].
此后,它切换到了今天仍在使用的更复杂(但仍然非常简单)的BM25。 这也是Azure认知搜索中实现的算法[4]。
BM25:您从未听说过的最重要的算法 (BM25: the most important algorithm you have never heard of)
So what is BM25? It stands for ‘Best match 25’ (the other 24 attempts were clearly not very successful). It was released in 1994 at the third Text Retrieval Conference, yes there really was a conference dedicated to text retrieval…
那么什么是BM25? 它代表“最佳比赛25”(其他24次尝试显然不是很成功)。 它于1994年在第三次文本检索会议上发布 ,是的,确实有一个专门针对文本检索的会议…
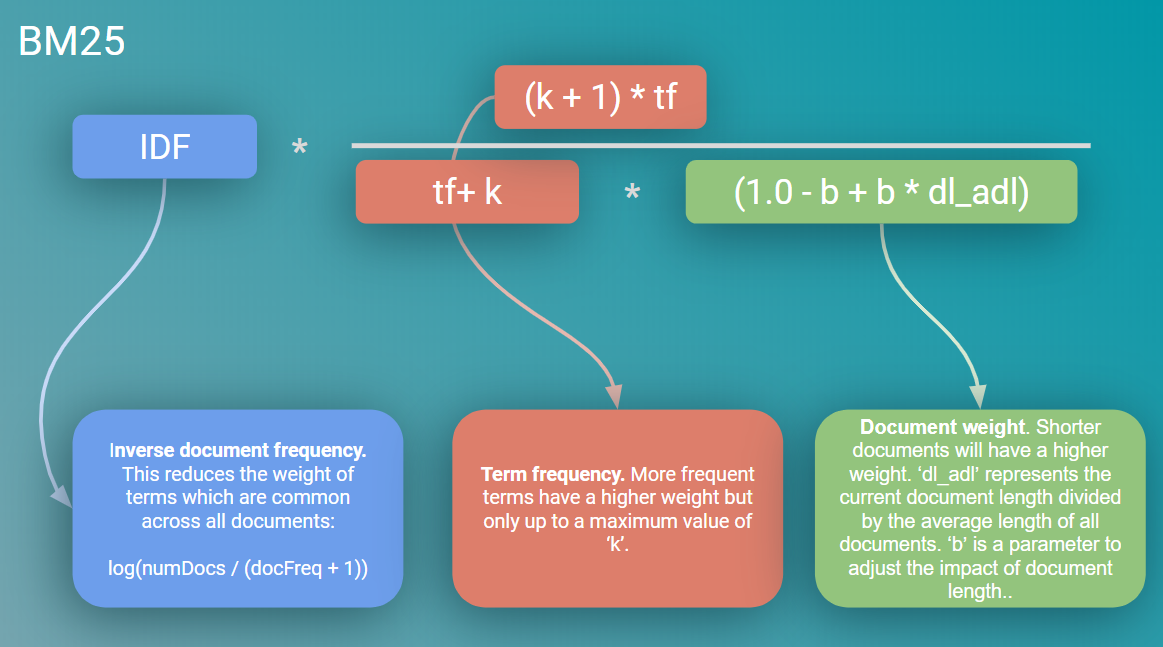
It is probably best thought of as tf-idf ‘on steroids’, implementing two key refinements:
最好将其视为“类固醇上的tf-idf”,它实现了两个关键改进:
Term frequency saturation. BM25 provides diminishing returns for the number of terms matched against documents. This is fairly intuitive, if you looking to search for a specific term which is very common in documents then there should become a point where the number of occurrences of this term become less useful to the search.
术语频率饱和 。 BM25提供与文档匹配的条款数量递减的回报。 这是非常直观的,如果您要搜索在文档中非常常见的特定术语,那么应该出现一个问题,即该术语的出现次数对搜索没有太大用处。
Document length. BM25 considers document length in the matching process. Again, this is intuitive; if a shorter article contains the same number of terms that match as a longer article, then the shorter article is likely to be more relevant.
文件长度。 BM25在匹配过程中考虑文档长度。 再次,这很直观; 如果较短的文章包含与较长的文章匹配的相同数量的术语,则较短的文章可能更相关。
These refinements also introduce two hyper-parameters to adjust the impact of these items on the ranking function. ‘k’ to tune the impact of term saturation and ‘b’ to tune document length.
这些改进还引入了两个超参数,以调整这些项目对排名功能的影响。 “ k”用于调整术语饱和度的影响,“ b”用于调整文档长度。
Bringing this all together, BM25 is calculated as:
综上所述,BM25的计算公式为:
实施BM25,一个可行的例子 (Implementing BM25, a worked example)
Implementing BM25 is incredibly simple. Thanks to the rank-bm25 Python library this can be achieved in a handful of lines of code.
实施BM25非常简单。 多亏了rank-bm25 Python库,这可以用几行代码来实现。
In our example, we are going to create a search engine to query contract notices that have been published by UK public sector organisations.
在我们的示例中,我们将创建一个搜索引擎来查询由英国公共部门组织发布的合同通知。
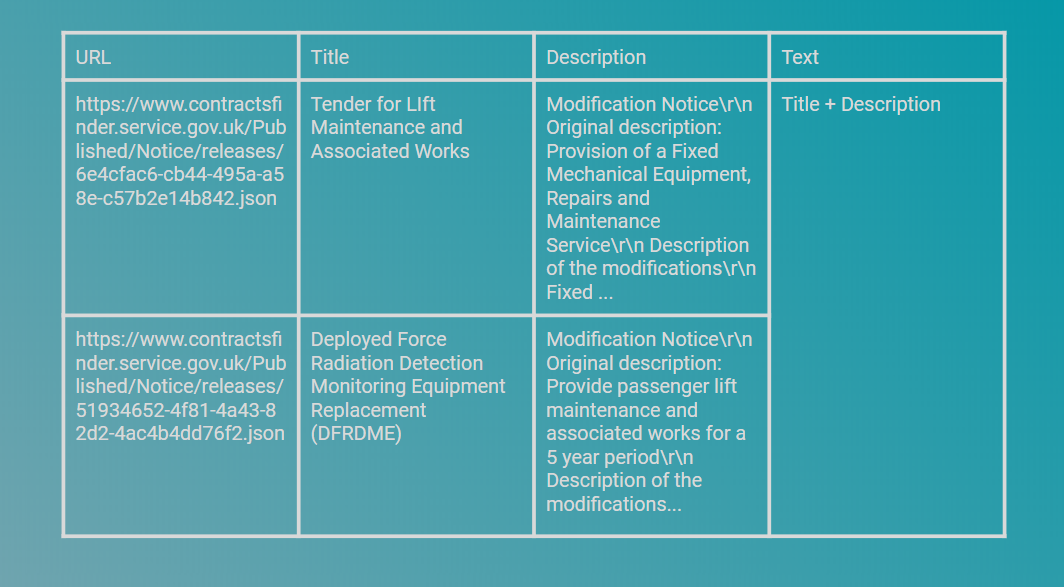
Our starting point is a dateset which contains the title of a contract notice, the description along with the link to the notice itself. To keep things simple, we have combined the title and description together to create the ‘text’ column in the dataset. It is this column that we will use to search. There are 50,000 documents which we want to search across:
我们的出发点是一个日期集,其中包含合同通知书的标题,说明以及通知书本身的链接。 为了简单起见,我们将标题和描述结合在一起以在数据集中创建“文本”列。 我们将使用此列进行搜索。 我们要搜索50,000个文档:
A link to the data and the code can be found at the bottom of this article.
可以在本文底部找到数据和代码的链接。
The first step in this exercise is to extract all the words within the ‘text’ column of this dataset to create a ‘list of lists’ consisting of each document and the words within them. This is known as tokenization and can be handled by the excellent spaCy library:
此练习的第一步是提取此数据集的“文本”列中的所有单词,以创建一个“列表列表”,其中包括每个文档及其中的单词。 这被称为标记化,可以通过出色的spaCy库进行处理:
import spacy
from rank_bm25 import BM25Okapi
from tqdm import tqdm
nlp = spacy.load("en_core_web_sm")text_list = df.text.str.lower().values
tok_text=[] # for our tokenised corpus#Tokenising using SpaCy:
for doc in tqdm(nlp.pipe(text_list, disable=["tagger", "parser","ner"])):
tok = [t.text for t in doc if t.is_alpha]
tok_text.append(tok)Building a BM25 index can be done in a single line of code:
建立BM25索引可以用单行代码完成:
bm25 = BM25Okapi(tok_text)Querying this index just requires a search input which has also been tokenized:
查询该索引仅需要搜索输入,该输入也已被标记化:
query = "Flood Defence"tokenized_query = query.lower().split(" ")import timet0 = time.time()
results = bm25.get_top_n(tokenized_query, df.text.values, n=3)
t1 = time.time()print(f'Searched 50,000 records in {round(t1-t0,3) } seconds \n')for i in results:
print(i)This returns the following top 3 results that are clearly highly relevant to the search query of ‘Flood Defence’:
这将返回以下与搜索“防洪”高度相关的前3个结果:
Searched 50,000 records in 0.061 seconds:Forge Island Flood Defence and Public Realm Works Award of Flood defence and public realm works along the canal embankment at Forge Island, Market Street, Rotherham as part of the Rotherham Renaissance Flood Alleviation Scheme. Flood defence maintenance works for Lewisham and Southwark College **AWARD** Following RfQ NCG contracted with T Gunning for Flood defence maintenance works for Lewisham and Southwark College Freckleton St Byrom Street River Walls Freckleton St Byrom Street River Walls, Strengthening of existing river wall parapets to provide flood defence measuresWe could fine-tune the values for ‘k’ and ‘b’ based on the expected preferences of the users performing the searches, however the defaults of k=1.5 and b=0.75 seem to work well here.
我们可以根据执行搜索的用户的期望偏好来微调“ k”和“ b”的值,但是默认设置k = 1.5和b = 0.75在这里似乎很好。
在结束时 (In closing)
Hopefully this example highlights how simple it is to implement a robust full text search in Python. This could easily be used to power a simple web app or a smart document search tool. There is also significant scope to improve the performance of this further , which may form the topic of a future post!
希望该示例突出显示在Python中实现健壮的全文本搜索有多么简单。 这可以轻松地用于驱动简单的Web应用程序或智能文档搜索工具。 还有很大的空间可以进一步改善此性能,这可能会成为将来帖子的主题!
The code and data to this article can be found in this Colab notebook.
可在此Colab笔记本中找到本文的代码和数据。
[1] McKinsey review of web search: https://www.mckinsey.com/~/media/mckinsey/dotcom/client_service/High%20Tech/PDFs/Impact_of_Internet_technologies_search_final2.aspx
[1]麦肯锡网络搜索评论: https : //www.mckinsey.com/~/media/mckinsey/dotcom/client_service/High%20Tech/PDFs/Impact_of_Internet_technologies_search_final2.aspx
[2] According to StackShare, August 2020.
[3] BM25 became the default search from Elasticsearch v5.0 onward: https://www.elastic.co/blog/elasticsearch-5-0-0-released
[3] BM25从Elasticsearch v5.0开始成为默认搜索: https : //www.elastic.co/blog/elasticsearch-5-0-0-released
[4] https://docs.microsoft.com/en-us/azure/search/index-ranking-similarity
[4] https://docs.microsoft.com/zh-CN/azure/search/index-ranking-similarity
翻译自: https://towardsdatascience.com/how-to-build-a-search-engine-9f8ffa405eac
如何建立搜索引擎















 1270
1270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









